基于评论关系图的垃圾评论者检测研究
2015-12-29林秀娇魏晶晶廖祥文
林秀娇,魏晶晶,刘 月,廖祥文
(1.福州大学数学与计算机科学学院,福建福州 350116;2.福建省网络计算与智能信息处理重点实验室,福建福州 350116;3.福建江夏学院电子信息科学学院,福建福州 350116)
0 引言
随着电子商务的高速发展,越来越多的用户会在购买产品后发表自己对产品、商店服务等评论信息.这些信息对潜在用户和商店是一个很重要的资源.但是有一些用户为了提升或者诋毁某一产品或某一类产品的声誉,发表不真实的、有欺骗性质的垃圾评论,这些评论可能会误导潜在消费者;同时还可能干扰评论意见挖掘和情感分析系统的分析[1].因此,对产品垃圾评论的识别很有必要.
目前,国内外针对产品垃圾评论识别展开了很多的研究,并且取得了一定的成果.但是大部分工作集中在文本相似[1-3]、语言特征[4]、评论者行为[5-6]和评分模式[5-7]等方面,这些方法只能识别重复的垃圾评论或是写重复评论的垃圾评论者,对于其他类型则无法检测.为此,本研究提出构造评论者、评论和商店以及回复者的评论关系图,利用四者的关系计算评论者可信度来检测产品垃圾评论者.
1 相关工作
1.1 垃圾评论文本的检测
2007年Jindal等[1-3]首次提出垃圾评论这个概念,把它分为三种类型:untruthful opinion,reviews on brands only,non-reviews,然后采用logistic回归建立机器学习模型来识别三种类型的垃圾评论.Lai等[4]提出一种基于unigram模型的识别方法,利用句法分析和英文格式上的特征作为分类特征.Ott等[8]将垃圾评论的识别看成一个二元分类问题.除此之外,文献[7,9-10]也利用垃圾评论文本内容检测垃圾评论.
上述方法需要对文本内容有深度理解和观点抽取.但垃圾评论者为能成功误导消费者,会使自己的评论看起来与正常评论区别不大甚至没有区别[11],因此利用评论文本来识别垃圾评论会比较困难.
1.2 垃圾评论者的检测
这类检测方法的基本思想是:垃圾评论者发表的评论多为垃圾评论.Lim等[5]和邱云飞等[6]利用用户行为来检测垃圾评论者.Liu等[12]通过研究“非期望规则”来识别垃圾评论者.但是这些方法只能检测某种特定的垃圾评论者,如写重复评论的产品垃圾评论者.Liu等[13-14]认为产品垃圾评论不只是个人的行为,而是一种团体活动,他们结合评论组特征与单个评论者特征建立三个交叉模型识别垃圾评论者.Xie等[15-16]利用时间序列检测垃圾评论者.Li等[17]把垃圾评论者检测和垃圾评论检测两者结合起来,但该方法仍然需要抽取评论文本内容.Wang等[18]利用评论者、评论和商店三者之间的关系检测垃圾评论者,不仅避开了对文本内容深度理解和观点的抽取,而且还能检测出写非重复垃圾评论的垃圾评论者.但是他们尚未加入回复者对评论的影响,对于有越多可信度高的回复者认为有用的评论,有理由相信该评论的真实度会更高.因此,本研究提出构造评论者、评论、商店以及回复者的评论关系图,利用四者之间的关系计算评论者可信度检测垃圾评论者.
2 基于回复者特征的垃圾评论者检测模型
为了检测垃圾评论者,用带有箭头的实线将评论者与其评论及所在商店相连.如果一条评论有其他评论者(回复者)对其回复,则用带有箭头的虚线将回复者与评论相连,形成评论关系图,如图1所示.

图1 评论关系图Fig.1 Review graph
2.1 问题定义
由图1可以看出,评论者与其评论有关联,因此判断一个评论者是否为垃圾评论者,可以观察该评论者的评论是否真实.假设一个评论者的可信度与其所有评论的真实度的总和Hr有关系.图1中的评论者用R={r1,r2,…,rn}表示,T(r)={T(r1),T(r2),T(rn)}表示评论者r的可信度,K是评论者可信度的上界,nr是评论者r的评论总数量,αir是评论者r的第i个评论.则问题定义为:

为了方便计算,将T(r)的值归一化到[-1,1],则评论者的可信度为:

其中:

明确评论者可信度T(r)的求解方法后,需要求得公式中的另一个参数H(v).
2.2 评论真实度度量
用户在判断一条评论是否真实可信,一般会从以下三个方面进行考虑:①了解商店是否可靠.对于可靠的商店,用户会相信其评论是真实可信的,而对于声誉差的商店,用户一般会怀疑其评论的真实性.②观察该评论的周围评论,即同一家商店一定时间内Δt的其他评论.如果周围评论都认为产品是好的,则用户会相信该产品是好的;反之,用户会怀疑该产品的质量.③观察这条评论的回复者,如果越多可信度高的回复者认为评论有用,则认为评论的真实度越高.反之,用户会觉得该评论不真实.基于以上三方面考虑,评论真实度模型有三个影响因素,即商店的可靠性、周围评论的一致性分数以及回复者的回复分数.因此,将评论v的真实度定义为:
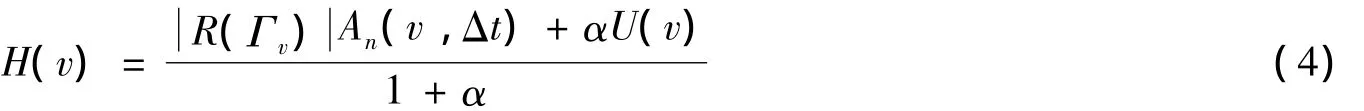
H(v)的值在[-1,1].其中:α是参数,取值为0.3、0.5、0.7、1.0、1.5、2.0;An(v,Δt)是周围评论的一致性分数;R(Γv)是商店Γv的可靠性分数;Γv是评论v评论的商店id;U(v)是评论v的回复分数.
2.2.1 周围评论的一致性分数估计
把评论v的所有周围评论的集合记为Sv,即:

其中:tv是评论v的评论时间.对于Sv中任意两条评论i、j,如果这两条评论关于同一家商店的同一产品的观点相似,则认为这两条评论是一致的.由于观点挖掘需要的代价大,假设两条评论关于同一家商店有相似的评分,则认为这两条评论对这家商店有相似的观点.
因此,根据假设,如果

其中:ψv是评论v的评分;δ是一个给定的边界(本文的评分有5个等级,δ取值为1),则表示一致评论.现把 Sv划分为两个集合,Sv,a和 Sv,d,定义如下:

同时,考虑评论者的可信度分数.评论者可信度越高,其评论越真实,即使它的周围评论和它不一致,因为周围评论可能都是不可信评论者写的.类似地,一条评论和周围的评论都一致也有可能是不真实的,因为周围评论有可能都是垃圾评论者写的.因此,定义评论v在一定时间内的周围评论的一致性分数为:
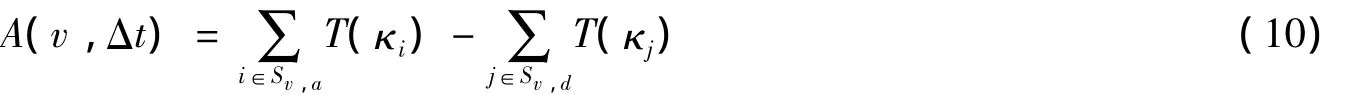
其中:κv是评论v的作者id,Δt取发表这条评论时间的前后3个月.对周围的一致性分数归一化到[-1,1]后得到:

2.2.2 商店的可靠性计算
如果一个商店有更多可信度高的评论者写正面的评论,则认为这家商店更可靠.反之,则认为这家商店更不可靠.因此定义商店s的可靠性为:

其中:

R(s)的值在[-1,1];vs是商店s的评论集合;u是评分系统的中间值,故u取3.
2.2.3 回复分数估算
回复者对评论的回复可反应其他人对这条评论的认可程度,从而间接反应出评论的书写者是否可信.如果一条评论有越多的可信度高的回复者对其回复,并且认为这条评论有用,则这条评论的真实度越高.反之,则认为这条评论不真实.
依据回复者的可信度将回复者分为可信回复者和不可信回复者.根据不可信评论者的大部分评论是不可信的,假设不可信回复者的回复是不可信的.在计算回复分数时只考虑可信回复者(回复者的可信度大于零)的回复对评论的影响.同时,在计算回复分数时不考虑评论者自己对自己评论的回复,因为这可能只是评论者对自己评论的补充.
因此,定义评论v的回复分数为:
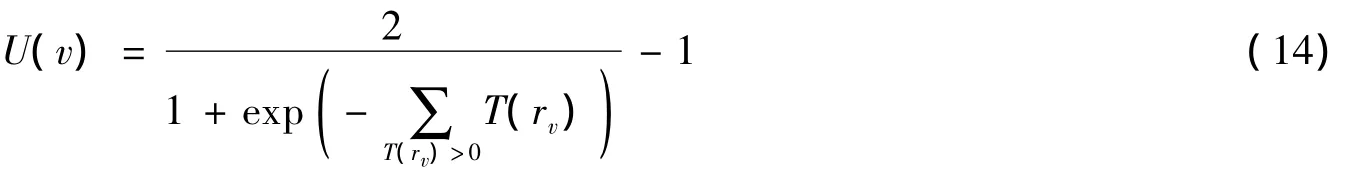
U(v)的值在[-1,1].其中,rv是评论者r认为评论v有用的回复者.
2.2.4 迭代算法
采用迭代算法求解评论者可信度分数,依据文献[8],本文的迭代次数为5,具体算法步骤如下:
输入:商店 s={s1,s2,…,st},评论v={v1,v2,…,vk},评论者r={r1,r2,…,rn},时间窗口Δt,评论相似阈值δ.
输出:评论者可信度T(r),评论真实度H(v),商店可靠性R(s).
Step1:初始化商店可靠性R(s)=1,评论者可信度T(r)=1,评分中间值u=3;
Step2:根据初始值计算评论的周围分数An(v,Δt)以及回复分数U(v);
Step8:重复迭代上述步骤,当第i次迭代和第i+1次迭代得到的评论者可信度的向量ξi和ξi+1满足:1 -cos(ξi,ξi+1)< 5 ×10-4时,迭代结束.
3 实验结果与分析
3.1 数据集构造
使用文献[6]提供的亚马逊网站的评论作为实验数据集.根据得到的数据集,假设同一个品牌的商品为同一家商店出售.
数据集分为评论数据集和回复数据集.对数据集先进行预处理:①删除在评论数据集中没有评论的回复者.②删除重复的回复评论.③删除评论者对自己的回复.经过预处理后得到的数据集如表1所示.

表1 预处理后的数据集Tab.1 The dataset after preprocessing
3.2 实验结果分析
为了检验模型的合理性和有效性,首先用本文算法识别出前100个高度可疑的垃圾评论者作为候选垃圾评论者,然后对这100个候选垃圾评论者进行人工(3个标记人)标注,识别过程中标记人是独立的.根据大多数投票原则,一个评论者如果同时被2个或2个以上的标记人标记,则认为该评论者是垃圾评论者.根据最终人工标记的结果,采用准确率(precision)来评估方法的好坏.
式(4)中的α 取值为0.3、0.5、0.7、1.0、1.5、2.0.由于篇幅限制,这里只列出实验效果最好的(α =0.5)人工标记结果,如表2所示.

表2 人工标记结果Tab.2 Human evaluation result (个)
表2显示了人工标记的一致性.例如,由算法检测的前100个可疑垃圾评论者中,标记人1认为其中48个可疑垃圾评论者为真实的垃圾评论者,标记人2与标记人1有36个可疑垃圾评论者一致认为是真实的垃圾评论者,而标记人3与标记人1有35个可疑垃圾评论者一致认为是真实的垃圾评论者.
为了验证本文方法的合理性和有效性,设计了回复分数前后的对比实验.实验结果显示,当回复分数中的 α 取值为0.3、0.5、0.7、1.0、1.5、2.0时,准确率分别为44%、45%、43%、44%、42%、41%,与基准的准确率41%相比都有提高或持平.可以看出,当α>1之后,准确率的提升空间逐渐减小,这说明回复分数对评论真实度有影响,但是其影响力度与商店的可靠性和周围评论的一致性对评论真实度的影响力度相比较小,所需要的权值也应该更小.
通过实验证明,回复分数对评论的真实度有影响,能够提高垃圾评论者识别的准确率.例如,正常的评论者“kanghui35”在基准实验下,他的可信度分数为-0.550 420,被认为是可疑的垃圾评论者.而加入回复数后“kanghui35”的可信度分数为0.145 761,可信度分数提高了,被正确识别.
虽然加入回复分数之后的准确率提高了,但是提高的幅度不大,即使在α=0.5实验效果最好的情况下与基准的准确率相比只提高了4个百分点,总的准确率还有较大的提升空间.影响准确率的原因可能是:首先,由于回复的数据集较少,一些真实可靠的评论并未得到可信度高的回复者回复;其次,回复分数中参数α对实验结果有一定的影响,需要继续对α进行优化,降低其对结果产生的误差,提高识别精度;另外,还可能是因为一些垃圾评论者的特征指标尚未被考虑,无法识别更多的垃圾评论者.以上三种可能有待于之后的进一步细致研究.
致谢:感谢邱云飞,王建坤等为本文提供的亚马逊网站的评论数据集.
