人工智能技术的电子商务虚假评论者检测
2022-02-26王颖,王盼
王 颖,王 盼
(西安交通工程学院人文与管理学院,陕西 西安 710300)
网络技术纵深发展对人类社会的进步发挥着巨大作用,电子商务是当前网络应用技术对人类社会行为模式改变与促进最显著的特征之一[1]。电子商务最显著的优势体现在开放性与全球性上[2],消费者利用电子商务平台均可通过最小化的成本获取最大化的满足度。消费者在购买所需商品过程中往往会参考其他消费者对该商品的评论作出消费决策[3],但当前电子商务平台中存在部分虚假评论者为获取相关利益给予商品虚假评论误导消费者的现象[4]。部分商家与虚假评论者达成金钱交易,使其对自己的商品给予夸张的积极评论提升自己商品的好评度,或对同类型商品给予消极评论降低其信誉度。虚假评论者的这些行为不利于电子商务平台商品竞争的公平性,同时也给消费者带来经济上的损失,长此以往严重影响电子商务平台的发展[5]。
随着计算机技术的发展,人工智能技术成为当前科技领域中的宠儿,其综合计算机、数理逻辑、控制理论等多领域知识,基于机器语言与深度学习通过模拟、拓展人类智能思维理论完成机器认知与数据分析的功能[6]。人工智能技术在各领域中的普遍应用标志着人类由此迈进新的信息时代。统计学习理论中的支持向量机SVM能避开依据人数定理且样本无穷大的传统统计学推断,并能较好地解决小样本、非线性、过学习、维数灾难和局部极小等问题,具有很强的泛化能力。人工智能技术中的D-S证据理论属于不确定推理算法[7],与贝叶斯概率论相比,其满足条件更低,能够直接处理不确定信息。将二者结合后应用于电子商务虚假评论者检测中,提出基于人工智能技术的电子商务虚假评论者检测方法,使待识目标的不确定性下降,能有效地提高目标的识别能力,完成更准确的虚假评论者检测。
1 人工智能技术的电子商务虚假评论者检测方法
1.1 电子商务评论信息采集
研究采用分布式评论信息采集系统采集电子商务评论信息,如图1所示。图1中抓取机在试件触发器控制下从网络中采集电子商务平台在线商品信息,预处理模块针对采集到的商品信息进行统一资源定位器(URL,uniform resoure locator)链接,初始化商品采集周期、当前评论量以及最近一次评论时间等参数,调度模块管理商品URL,基于采集周期调整模块的采集周期设定将商品URL放置在待采集队列内。根据商品URL排序利用分布式增量抓取模块和Hbase模块分别对电子商务平台商品评论信息进行增量式采集与增量式存储[8]。通过该系统可以对电子商务评论信息实时垂直搜索,实时跟踪新的评论信息,根据评论信息确定评论者。
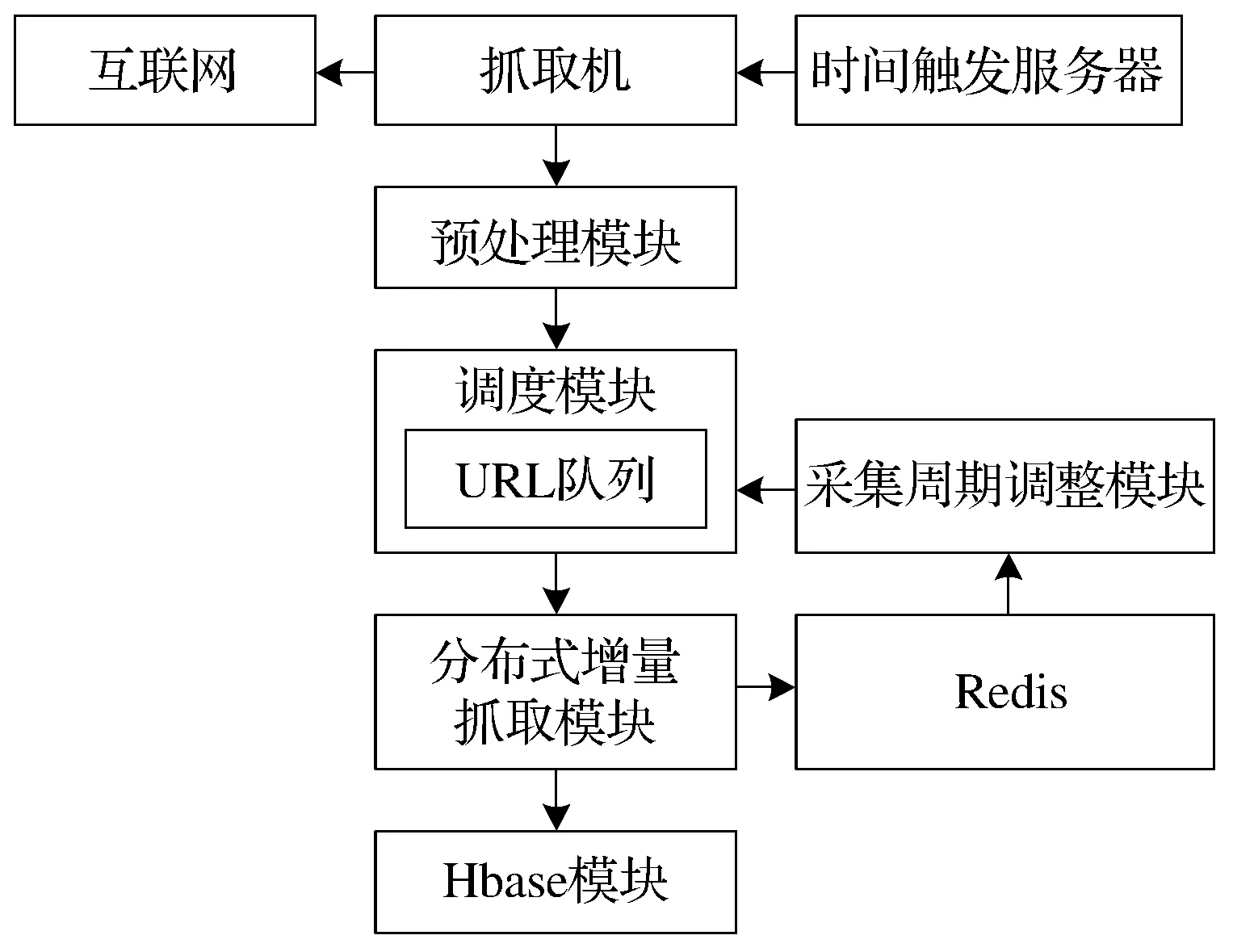
图1 分布式评论信息采集系统Fig.1 Collection system of distributed comment information
1.2 评论者特征识别
基于上述电子商务评论信息采集结果,分析评论者r评论内容情感特征、商品关注特征[9],以此为依据进行电子商务虚假评论者检测。
(1) 评论内容情感特征 评论者评价内容情感特征可通过属性词包含率、第一人称代词使用率、情感词使用率、平均评分差异度、与初始评论的时间间隔、初次评论与末次评论时间间隔进行描述[10]。
① 属性词包含率。虚假评论者对商品的评价是虚构的,因此评论内容中商品具体属性描述较少。由此定义评论内容全部词汇q(rp)中商品属性词s(rp)包含率越低,该评论者为虚假评论者的概率越高,公式描述为
② 第一人称代词使用率。第一人称代词可在评论内容中突出评论者,提升评论的真实性。由此定义评论内容全部词汇q(rp)中第一人称代词d(rp)使用率越高,该评论者为虚假评论者的概率越高,公式描述为
③ 情感词使用率。消费者评论内容中情感表达线性度体现其商品使用感受,虚假评论者通常未实际使用商品。由此定义评论内容全部词汇q(rp)中,情感词w(rp)使用率越低,该评论者为虚假评论者的概率越高,公式描述为
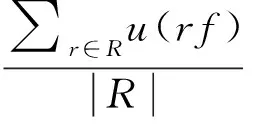
⑤ 初始评论间隔。虚假评论者往往会在早期对商品进行评价以此来误导消费者。由此定义评论者评论时间t(rt)距离商品初始评论时间f(rt)间隔越短,该用户为虚假评论者的概率越高,公式描述为
其中:ε=180,表示设定的时间间隔阈值。
⑥初次评论与末次评论时间间隔。虚假评论者通常流连于不同电子商务平台之间,在同一电子商务平台中发表评论的频率较低。由此定义评论者初次评论时间tc(rt)与末次评论时间tm(rt)间隔越长,该用户为虚假评论者的概率越高,公式描述为
其中:δ=90,表示设定的时间间隔阈值。
(2) 商品关注特征 评论者在电子商务商品评论内包含的商品类别、商家及品牌数量能够描述其对于电子商务产品的特殊关注特征,同时也能够描述虚假评论者的职责范围。评论者对商品的关注特征可通过商品类别包含率、品牌数量包含率与商家数量包含率描述[11]。
① 商品类别包含率。虚假评论者与真实评论者相比较,其评论中的商品类别局限于小范围内。由此定义商品评论者的全部评论中包含商品类别的评论数量c(rp),商品的全部评论数量为C(rp),前者与后者的比值越低,该评论者为虚假评论者的概率越高,公式描述为
② 品牌数量包含率。高品的虚假评论者与真实评论者相比较,其评论中的品牌数量通常较少。因此商品评论者的全部评论中包含品牌数量h(rp)与商品的全部评论数量H(rp)的比值越低,该评论者为虚假评论者的概率越高,公式描述为
③ 商家数量包含率。虚假评论者与真实评论者相比较,其评论中的商家数量也较少。由此定义商品的全部评论中包含商家数量b(rp)与全部评论数量B(rp)的比值越低,该评论者为虚假评论者的概率越高,公式描述为
1.3 虚假评论者检测
在目标识别级融合中,D-S证据理论采用信任函数而不是概率作为度量,在无需知道先验概率的情况下,进行不确定性推理。评论者评论内容情感特征和商品关注特征可作为评论者身份检测的证据[12],基于这些证据,采用D-S证据理论进行虚假评论者检测。
用ζ表示虚拟空间,其特征为穷举、存在边界、互斥,以其作为检测结构,2ζ表示其全部子集集合。利用D-S证据理论算法,根据证据合成原理确定评论者是否为虚假评论者。
检测结构定义:ζ={r1,r2}表示检测结构是由检测结果中真实评论者r1和虚假评论者r2共同组成的集合,2ζ表示为2ζ={φ,{r1},{r2},{r1,r2}}。
Mass函数定义:Mass函数表示人们对目标假设的可信程度的推理,是一种人的判断,这种判定受各种因素的影响,不同的思想会构成不同的Mass函数,因此根据已知的信息以一定条件自动生成函数可以排除个人主观因素带来的误差,结果相对客观[13-15]。
检测结构ζ的Mass函数可表示为
v∶2ζ→[0,1],
由于D-S理论具有不确定性,获取有效的Mass函数从而确定信任函数是该理论应用于实际的关键。
多源信息融合(即多传感器融合)的关键是对具有相似或不同特征模式的多源信息进行处理,以获得具有相关和集成特性的融合信息。决策级融合是三级融合的最终结果,D-S证据理论作为决策级融合常用的方法之一,因其基本概率赋值(BPA)对决策结果的影响很大,现有的BPA方法主要依赖主观经验,其实用效果不是很好。支持向量机因具有良好的理论基础和分类效果,与D-S证据理论相结合后可以构造合理有效的BPA,从而得到更高、更稳定的识别率。
SVM的性能主要取决于2个因素:①核函数的选择;②惩罚因子的选择。研究中,以评论者评论内容情感特征和商品关注特征这2个证据理论作为SVM的惩罚因子,共同决定最后结果。
假设评论者各特征相互独立,则v1和v2可分别表示评论者评论内容情感特征和商品关注特征的Mass函数。利用支持向量机模型获取赞同度,vi(r1)、vi(r2)和vi(ζ)分别为第i个Mass函数中真实评论者、虚假评论者和不确定的赞同度。
Mass函数Dempster合成原则定义,针对∀J⊆ζ,v1和v2的合成原则如下:
g=∑J1∩J2≠φv1(J1)v2(J2)=
1-∑J1∩J2=φv1(J1)v2(J2),
其中:g和J分别表示归一化因子和评论者数量;∑J1∩J2=φv1(J1)v2(J2)=1-g和⊕分别表示特征对立水平和特征组合算子,J1,J2⊆2ζ。
虚假评论者检测过程:
(1) 构建检测结构ζ={r1,r2};
(2) 根据评论者特征构建不同Mass函数,构建2个特征的支持向量机模型为
(1)
其中:Pn(w)表示给定w时的概率密度函数,在式(1)的基础上,利用sigmoid函数将支持向量机模型的无阈值输出转换为后验概率输出,得到各Mass函数的基本概率分配,分别为
将应其用于Mass函数合成;
(3) 根据基本概率分配合成2个Mass函数,获取合成Mass函数下真实评论者、虚假评论者和不确定的赞同度;
(4) 根据表1中的检测标准,确定虚假评论者。

表1 检测标准Table 1 Test standard
2 仿真测试
为测试基于人工智能技术的电子商务虚假评论者检测方法的应用性能,对其进行仿真测试。由于电子商务平台评论信息采集与检测过程包含海量数据信息,因此仿真平台选取Storm平台,在该平台中构建包含4个虚拟节点的Storm集群。各虚拟节点均采用免费的Ubuntn19.04操作系统,CPU与内存分别为intel i5-7400LGA 1151 14 nm 3.0 GGHz和8 GB,Storm组件采用Nimbus绩效管理软件和Supervisor管理维护软件。同时在本地利用ECSHOP独立网店系统构建一个虚拟电子商务平台为研究目标,并设定评论者为2 000个,其中真实评论者与虚假评论者数量相等。在该仿真环境下,验证研究方法的检测性能。
2.1 评论者信息采集
单位时间内数据处理规模可通过吞吐量描述。在仿真环境中,采用研究提出的方法采集目标中的评论信息,确定评论者。对比不同虚拟节点数量下全部商品评论信息采集过程花费的时间,验证研究所提方法的吞吐量,结果见表2和表3。不同虚拟节点数量下的采集过程重复10次,取均值。
由表2和表3可知,当节点数量为1时,研究所提
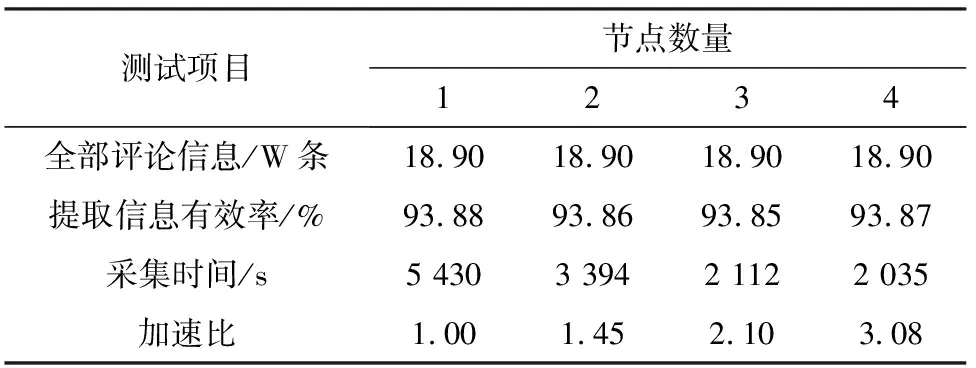
表2 传统方法的集群吞吐量测试结果Table 2 Test results of cluster throughout by conrentional method

表3 研究所提方法的集群吞吐量测试结果Table 3 Test results of cluster throughput by reseorch method
方法在采集全部评论信息过程中所花费的时间远少于采用传统方法采集信息所花费的时间,且随着节点数量的提升,研究所提方法采集评论信息的加速比也呈现上升趋势,上升速度高于传统方法,说明该方法的可扩展性较好。若研究目标扩大,可提升节点数量来提升此方法效率。
2.2 虚假评论者检测
(1) 支持向量机模型准确率测试 研究所提方法检测过程中支持向量机模型准确率直接影响单特征条件下虚假评论者检测的不确定度,模型准确率越低,最终检测结果准确率越低。设定支持向量机模型具有不同的惩罚因子与核函数,对比研究所提方法中支持向量机模型准确率随着评论者数量提升所产生的变化,结果如图2所示。
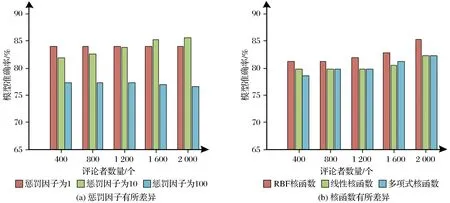
图2 支持向量机模型准确率测试Fig.2 Accuracy test of support vector machine model
图2(a)中设定惩罚因子分别为1、10和100,图2(b)中设定核函数分别为线性核函数、RBF核函数和多项式核函数。由图2得到,研究方法中支持向量机模型准确率随着评论者数量的提升整体上表现出上升状态。
图2(a)中3个不同惩罚因子条件下,支持向量机模型准确率呈现不同状态,其中惩罚因子为10时,模型准确率上升状态最显著,虽然在评论者数量较少时其准确率略低于惩罚因子1,但当评论者数量提升至1 300个左右时,其模型准确率已经超过其他2个惩罚因子。因此研究所提方法将支持向量机模型惩罚因子设定为10,图2(b)结果是在其基础上得到的。
图2(b)中3个不同核函数条件下,支持向量机模型准确率呈现不同程度的上升状态,其中RBF核函数条件下模型准确率上升状态最显著,因此支持向量机模型采用RBF核函数,该核函数下评论者特征中评论内容情感特征和商品关注特征准确率分别达到96.28%和95.52%。
(2) 虚假评论者检测结果 利用支持向量机模型得到各Mass函数的基本概率分配后融合各Mass函数,得到真实评论者、虚假评论者和不确定的赞同度,设定y1和y2分别为0.1和0.2,得到虚假评论者检测结果,其中部分检测结果如表4、表5所列。
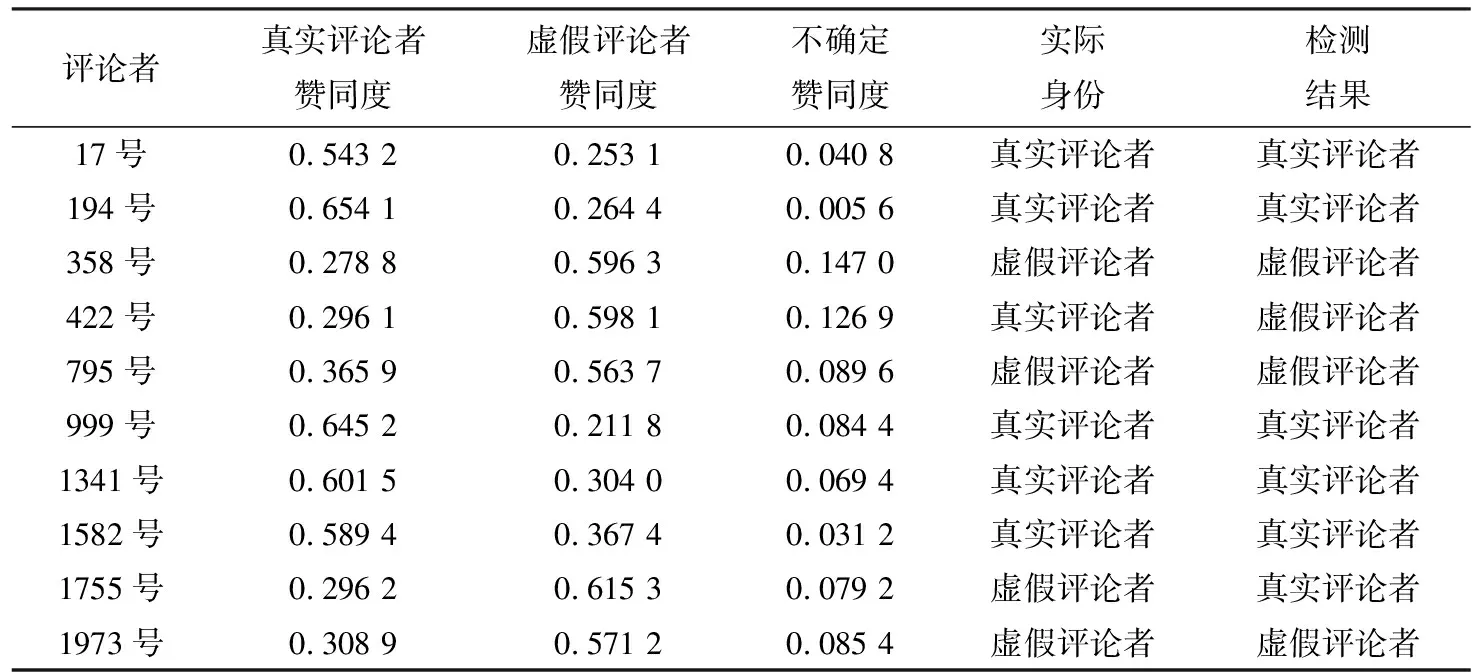
表4 采用传统方法检测得到的部分结果Table 4 Partial results tested by conventional method

表5 采用研究所提方法检测得到的部分结果Table 5 Partial results tested by research method
由表4、表5可知,采用两种方法进行虚假评论者检测时,均呈现出虚假评论者赞同度随着真实评论者赞同度的升高而降低的趋势,且不确定赞同度随虚假评论者赞同度升高而升高。但采用传统方法在选取的部分研究对象中,检测的准确度为80%,而采用研究所提方法在选取的部分研究对象中,检测的准确度为100%,表明研究所提方法能够更加准确检测电子商务平台中的虚假评论者。
3 结语
研究提出基于人工智能技术的电子商务虚假评论者检测方法,通过设计分布式评论信息采集系统来确定评论者;从评论内容情感特征、商品关注特征两方面分析评论者特征;构建D-S证据理论算法的检测结构,利用支持向量机模型确定真实评论者、虚假评论者和不确定的赞同度,完成虚假评论者检测。结果显示,该方法具有接近100%的准确度,能有效实现虚拟评论者的检测。在后续优化过程可主要针对评论者特征分析进行详细全面的研究,通过增加评论者特征项,提升检测结果的准确率。
