基于D-S证据理论的电子商务虚假评论者检测
2018-11-15张文宇张彬彬
张文宇,岳 昆,张彬彬
(云南大学 信息学院,昆明 650500)
1 引 言
在亚马逊中国、京东商城和淘宝网等电子商务网站中,消费者可以通过评论与评分表达他们对商品的使用感受和对商家服务的满意度.不同于传统实体购物,商品评论成为了消费者和商家了解产品质量和服务最为重要的信息来源.通常,与仅有小部分正面评论的产品相比,拥有绝大部分正面评论的产品更受消费者欢迎;如果一件产品包含正面评价较多,则可大大增加消费者的购买欲望[1],消费者在线评论的价值已得到消费者和在线零售商的公认[2].部分商家为提高自身信誉或贬低竞争对手开始通过雇佣评论者甚至亲自去充当评论者书写虚假评论误导潜在消费者,这些评论者通常给予正面评论夸大商品的品质,通过负面评论诋毁商家的信誉.互联网中这类发表不真实、具有欺骗性的评论者被称为虚假评论者[3],虚假评论者的存在,干扰了商品描述的真实性及推荐系统的准确性,也损害了电子商务平台的健康运行与良性发展.因此,如何对评论者信息数据进行分析、进而识别出虚假评论者,有重要现实意义.
不同于真实评论者,虚假评论者的动机主要是推销和诋毁,故虚假评论者本身的行为特征和真实评论者有较大区别.现有虚假评论者识别方法主要从消费者某种单一行为入手进行分析,未从不同的视角对评论者的行为进行观察,只能发现评论者的单一作弊行为而遗漏了其它潜在的作弊行为.表1给出了一个真实的虚假评论者示例,其作弊行为不仅体现在给予所评论商品全五星好评,而且体现在评论都集中在某一天、评论内容完全相同、评论目标集中在同一家商店的书籍等.当发现评论者的多种异常行为时,我们更加容易判断其身份是虚假评论者,因此,本文在多种行为特征下对评论者身份进行分析.一方面,评论者的每一种行为特征对评论者身份的影响都具有不确定性,如何在不同的观测空间中准确衡量这种不确定性,是提高虚假评论者识别率的前提.另一方面,如何有效综合考虑影响评论者身份的多个因素,也是亟待解决的问题.因此,本文考虑衡量各层面因素的不确定性及这些因素对虚假评论者识别的综合影响,在以上两个角度识别虚假评论者.
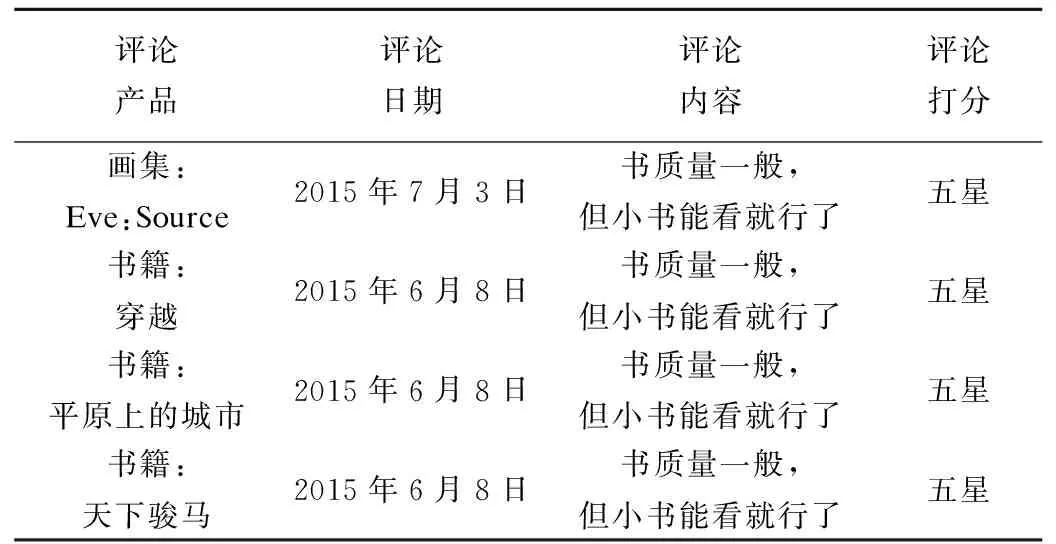
表1 一个真实的虚假评论者
为了提高商品信誉度或宣传竞争对手商品的缺点,虚假评论者往往会做出复制观点、重复评论、评分极端、评论交易日期集中、夸大商品质量等举措,意图让好评或差评成为目标商家商品的主流舆论,进而误导消费者判断.真实评论者会根据需求购买自己所需商品,不像虚假评论者那样反复对同一网店的固定产品进行评论评分,购买行为呈现出随机性.同时,虚假评论者账户的职能在于完成商家给定的任务,和其他评论者之间往往没有交流行为,也没有正常的社交网络.综上,在现有电商体系下,我们对此两类评论者的行为动机进行分析,认为评论者自身的行为不仅表现在其评价行为,而且表现在对商品的关注行为和与其他评论者之间的交流行为,通过这三类不同特征来综合描述评论者所呈现的行为.
证据理论(又称D-S证据理论)是一种由Dempster提出、Shafer进一步完善的不精确推理理论,在解决不确定信息的表示和融合方面有其独特优势[4],被广泛应用于数据融合、故障诊断及风险评估等领域[5-9].证据理论首先将描述系统的不确定信息转化为证据,然后利用Dempster组合规则进行证据融合.本文基于D-S证据理论的基本思想,无需假设各影响因素不确定性和完备性,以评论者的评价行为、评论者对商品的关注行为、评论者的交流行为特征作为对虚假评论者检测的“证据”,构建虚假评论者识别框架,讨论基于以上三类特征的虚假评论者发现方法.
支持向量机(SVM,Support Vector Machine)是机器学习领域内的有监督学习模型,通常用来进行模式识别、分类及回归分析[10-12].SVM分类本质是寻找一个软间隔超平面,通过正则化求解,使样本点到超平面的距离之和最大.当样本集线性不可分时,通过选择核函数将样本映射到核函数隐式定义的特征空间.本文提出通过多个维度对评论者评价行为、评论者对商品的关注行为、评论者交流行为分别进行衡量,基于三种行为特征建立不同的SVM模型,利用SVM处理小样本及多维数据的优势对单特征模式下评论者的作弊行为进行探讨.进一步,本文参考Platt引入sigmoid函数拟合后验概率值[13],将SVM的无阈值输出转化为关于真实评论者和虚假评论者的后验概率输出,为证据融合奠定基础.
我们在单特征SVM模型的基础上定义了相应的概率赋值函数,利用证据组合规则得到不同证据对最终评论者身份判定的联合影响.一方面,SVM的错误率表示不能确定将目标评论者样本准确进行分类的概率,与证据理论中的不确定信息相吻合,可以将其视为融合决策中的不确定信息.另一方面,我们通过评论者后验概率输出结合SVM的准确率得到最终关于真实评论者和虚假评论者的信度值.
最后,建立在亚马逊中国电商用户数据集之上的实验结果表明,本文所提出的方法准确有效.
2 相关工作
评论图模型构建和虚假评论者检测方面, Wang等[14]分析了评论者、 评论以及被评商店三者之间的交互关系, 通过构建包含这三种因素的评论图对虚假评论者进行挖掘和检测. Liang等[15]通过构造多边图来迭代计算评论者的不真实度检测虚假评论者. Lu等[16]通过构建包含用户特征及评论特征的评论因素图并通过信息传递算法同时检测虚假评论和虚假评论者. Rayana等[17]通过构建用户、 商品、 评论间的关系图来发现Yelp网站上存在的虚假评论人和虚假评论. 以上方法只考虑了评论图中各节点之间的制约关系, 没有考虑评论图之外的因素, 并且评论图的构建局限于某一特定商品或者商家, 未能从评论者的所有评论购买信息出发去发现评论者作弊行为.
基于异常行为的虚假评论者检测方面,Lim[3]等基于用户对单一商品多次相近评分、用户对于单独品牌上的产品群给予过高或过低评分、用户在某些产品上的评分跟其他用户评分偏离很大、用户对刚上架的商品进行评分的等四种评分行为提出四种检测模型.Mukherjee等[18]提出构建隐变量贝叶斯模型进行虚假评论者检测,将用户评论特征定义为隐变量,借助EM算法进行参数学习并利用吉布斯采样进行推理.Xue等[19]通过构建信任感知模型得出每个用户的可信度打分来识别虚假评论者.Ye等[20]通过监控不同时间片下用户的突发行为和异常行为来发现用户的作弊行为.Fei[21]等通过构建隐马尔可夫模型发现用户的评论、打分的异常变化.以上基于异常行为的虚假评论者检测方法,从单一的角度去检测虚假评论者,但近年来虚假评论者作弊方式呈现出多样化趋势并且隐藏性越来越高,当发现评论者不存在某种作弊行为时,并不代表该评论者不采用其他作弊手段.
基于集体作弊的虚假评论者检测研究方面,Xie等[22]通过检测不同时间窗口下商品评论数量变化、评分变化以及只发一条评论的评论者所占比例变化来发现集体作弊的现象.Choo等[23]从作弊者之间非正常的相互促进联系行为和情感分析入手挖掘作弊联盟.Yang等[24]借助作者主题模型得到每一个用户的兴趣概述,通过构造用户兴趣向量、计算余弦相似度来检测作弊团体.Ye等[25]提出一种无监督可度量的方法来检测网络中的集体作弊团体.以上方法可以发现可疑的集体作弊团体,但是当一个评论者团体很可疑时,并不能肯定其中的每一个评论者都是作弊者,进而很难判断其发表的评论时是否为虚假评论.
这些虚假评论者检测方法为本文的研究提供了参考,但针对多特征行为模式下虚假评论者的检测还需进一步探索.
3 评论者相关行为定义
3.1 评论者属性
为了描述评论者评价行为、评论者对商品的关注行为、评论者交流行为这三类用户特征,本文采用多个维度刻画每一个特征.对于某个评论者,评论者属性如表2所示.
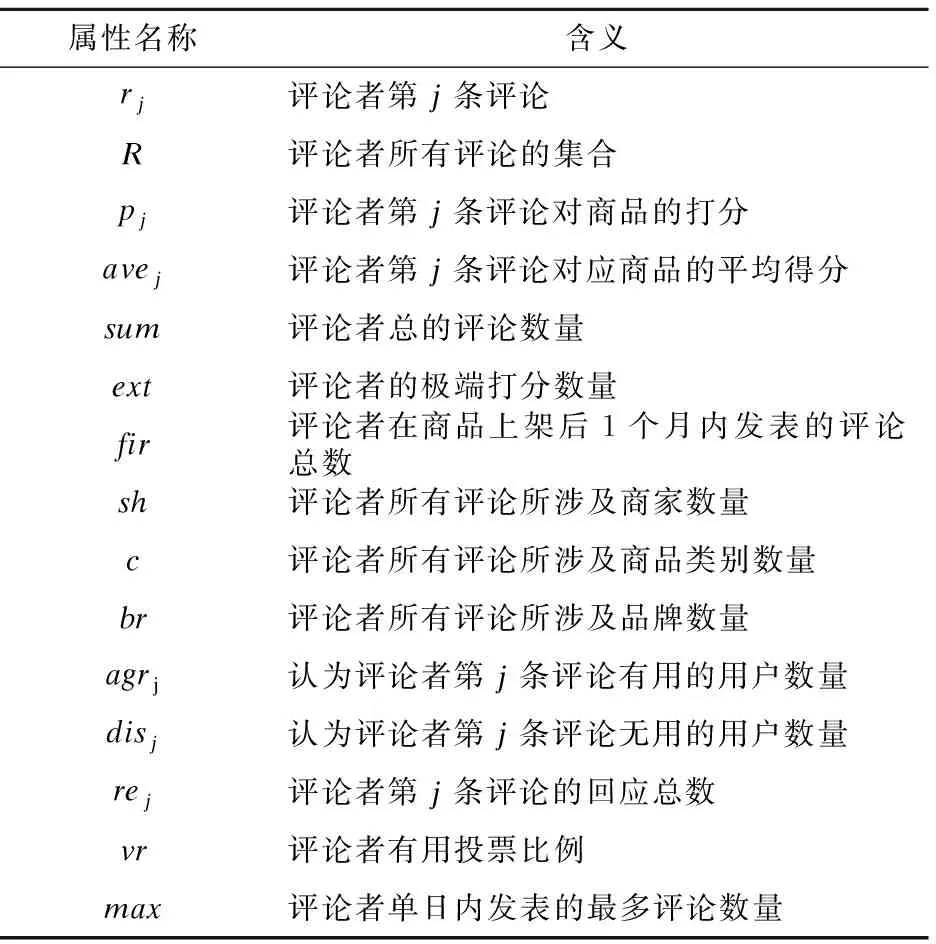
表2 评论者属性表示
3.2 评论者评价行为特征
虚假评论者往往会批量复制粘贴正常用户的好评或差评对目标产品进行评价,打分呈现极端性,集中在1星和5星,且评论往往集中在某一天.因此,本文从以下5个维度描述虚假评论者的评价行为特征:评论者打分的极端性、评论内容的相似性、评价的早期性、评论的集中性和打分的偏差性.
1)评论者打分的极端性.打分往往能反映出用户对商品的偏好和内心对商品真实评价,当一个用户总是给出最高分五星或最低分一星打分时,那么这个用户的偏好存在问题,其身份就很可疑.用极端打分数量占评论数量的比例来描述打分的极端性:
(1)
2)评价内容的相似性.虚假评论者往往会选择复制抄袭先前用户的好评并将其应用到自己的多数评论中,当一个评论者的多数评论内容相似,那么很可能是虚假评论者在批量复制评论.利用评论内容余弦相似度的最大值描述评论内容的相似性[26]:
S2=max{cosin(ri,rj),i≠j)
(2)
3)评价的早期性.当一个用户往往在商品刚上架后不久发表评论,为商品后来销售起到了促进作用,那么用户身份就很可疑.用商品上架后一个月内发表评论占评论者所有评论的比例描述评价的早期性:
(3)
4)评论的集中性.不同于真实评论者在随机时间内进行评论,虚假评论者往往在某一天内完成虚假评论的任务.用单日内发表的最多评论占总评论的比例描述评论的集中性:
(4)
5)打分的偏差性.虚假评论者对产品的描述往往和产品的真实质量不符,对商品的打分和商品所得的平均分有明显出入.电子商务平台中一般最高评分为五星,最低评分为一星,用商品打分和商品得分之差的平均偏差比例描述打分的偏差性:
(5)
3.3 评论者对商品的关注特征
和正常评论者相比,虚假评论者评价的商品类别、品牌数量和商家局限在小范围内,平均单条评论涉及的商品类别数量、商家数量、品牌数量可以反映评论者对商品的特殊关注特征和虚假评论者的任务目标范围.用评论所涉及商品类别数量占所有评论的比例描述商品类别涉及率,评论所涉及商家数量占所有评论的比例描述商家涉及率,用评论所涉及品牌数量占所有评论的比例描述品牌涉及率:
(6)
(7)
(8)
3.4 评论者的交流行为
虚假评论者往往得不到其他用户的认可,也不会与正常评论者有交流,没有正常的社交网络,对于其他用户的提问他们不会提供反馈咨询,也不会提供有价值的信息或有帮助的投票.本文采用用户有用投票比例、用户平均每条评论被回应数量、用户所有评论认可度的平均值三个维度来描述该特征:
S9=vr
(9)
(10)
(11)
4 虚假评论者识别模型的构建
4.1 基于D-S证据理论的虚假评论者识别框架
评论者的评价行为、评论者对商品的关注行为、评论者的交流行为从不同的侧面构成了评论者身份判断的“证据”.给定一个有限、互斥、穷举的假设空间Θ,称其为识别框架(Frame of Discernment),考虑Θ的幂集,即Θ的所有子集构成的集合,记为2Θ.如前所述,本文基于D-S证据理论,通过证据融合规则判断评论者身份,下面首先给出相关定义.
定义1(辨识框架)将评论者身份可能的判定结果中真实评论者(T)和虚假评论者(F)构成的集合定义为辨识框架,记为Θ={T,F},Θ的幂集为2Θ={Ø ,{T},{F},{T,F}}.
定义2(mass函数)函数m:2Θ→[0,1]称为Θ上的mass函数,若评论者的评价行为、评论者的对商品的关注行为、评论者和其他评论者交流行为相互独立,m1为评论者评价特征的mass函数,m2为评论者对商品关注特征的mass函数,m3为用户和其他用户交流特征的mass函数.mi(T)表示第i个mass函数中对真实评论者的支持度,mi(F)表示第个mass函数中对虚假评论者的支持度,mi(Θ)表示第i个mass函数中关于不确定的支持度.
D-S证据理论中,Dempster证据组合规则组合两个mass函数产生一个新的mass函数,表示初始可能冲突的证据间的一致意见,集合的交集表达了公共证据元素.Dempster证据组合规则的基本思想在于对多源不确定证据进行融合形成最终关于辨识框架的mass函数值,证据存在冲突时,通过归一化因子k进行可信度标准化修正.根据其基本思想,定义3给出三种特征下mass函数的合成规则.
定义3(mass函数合成规则)对于∀N⊆Θ,评论者识别框架Θ上的3个mass函数m1、m2和m3的Dempster合成规则为:
(m1⊕m2⊕m3)(N)
(12)
其中,
k=∑N1∩N2∩N3≠φm1(N1)m2(N2)m3(N3)
=1-∑N1∩N2∩N3=φm1(N1)m2(N2)m3(N3)
1-k即∑N1∩N2∩N3=φm1(N1)m2(N2)m3(N3),反映了有关评论者证据的冲突程度,⨁为证据组合算子,N1,N2,N3⊆2Θ.
根据定义1,辨识框架为Θ={虚假评论者,真实评论者};根据定义2,将评论者本身呈现的三类特征作为证据体构建基本概率分配函数;根据定义3,得到证据融合后的mass函数.在得到证据融合后关于虚假评论者和真实评论者的信度及不确定度量mi(Θ)后,我们辨识出评论者的身份,对评论者身份的最终判定遵循以下规则:
1)具有最大信度的类是目标类;
2)目标类与其他类的信度差值必须大于阈值θ1;
3)目标类信度必须大于不确定信度指派值;
4)不确定信度指派值必须小于阈值θ2.
4.2 基于Sigmoid函数的基本概率分配
为得到不同mass函数下的基本概率分配,需要度量单特征下评论者为真实评论者和评论者为虚假评论者的可能性以及无法识别的可能性,对于来自三种不同特征空间的评论者样本集,本文首先建立评论者单特征下三个不同的SVM检测模型,实现三个基于不同特征下的决策函数.对单特征下评论者检测的准确率进行测试,利用错误率衡量不确定信息,进而参考Platt提出的利用sigmoid函数实现关于虚假评论者和真实评论者的后验概率输出,结合SVM的准确率去衡量样本关于真实评论者和虚假评论者的基本概率分配.
我们将评论者评价特征量化为五维向量x1=(s1,s2,s3,s4,s5),对商品关注行为和交流行为分别量化为三维向量x2=(s6,s7,s8)、x3=(s9,s10,s11).对于来自不同特征空间的向量样本,我们训练三个行为特征下不同的SVM模型,训练后带有核函数的标准的SVM无阈值输出为:
f(x)=h(x)+b
(13)
h(x)=∑xi∈svαiyik(xi,x)
(14)
其中,αi为拉格朗日乘子,k(xi,x)为选定的核函数,sv是支持向量集.
SVM决策分类函数为:
y=sgn(f(x))=sgn(∑xi∈svαiyik(xi,x)+b)
(15)
当y=1时,判断该评论者为真实评论者,当y=-1时,判断该评论者为虚假评论者.
然而,f(x)和y都不是评论者后验概率输出,我们引入参数A和B,利用sigmoid-fitting方法将无阈值输出f(x)转化为后验概率.待检测评论者是真实评论者的概率为:
(16)
待检测评论者为虚假评论者的概率为:
(17)
我们通过极大似然估计的方法计算A和B:
(18)
其中,pl=pA,B(fl)
其中,m为训练集中的样本数,N+为样本中真实评论者的数量,N-为样本中虚假评论者的数量,yl是样本的标签.
对三个不同行为特征下的SVM分类器,在完成评论者样本集的训练过程后,根据式(18)得到最优参数Ai、Bi(i=1,2,3),并基于公式(16)和公式(17)得出后验概率pi和1-pi.因此,结合SVM的识别准确率qi对mass函数值定义为:
mi(T)=qipi
(19)
mi(F)=qi(1-pi)
(20)
mi(Θ)=1-qi
(21)
将用户的三种行为特征作为三个证据体,根据公式(19)、(20)、(21)得出每一证据体关于真实评论者和虚假评论者的基本可信度m1(T)、m1(F)、m2(T)、m2(F)、m3(T)、m3(F)及相关不确定性m1(Θ)、m2(Θ)、m3(Θ).
4.3 基于虚假评论者识别框架下mass函数值获取算法
针对评论者行为特征信息,基于4.1节、4.2节中的方法计算用户特征数据对其身份的联合影响,进行证据融合,在预处理后的评论者属性特征值的基础上得到评论者识别框架下的信度值.
算法1.
输入:待检测的评论者集合U及每个评论者特征向量x1,x2,x3
输出:每一位评论者在识别框架下的mass函数值t.m(T)、t.m(F)、t.m(Θ)(t∈U)
变量:A1、A2、A3、B1、B2、B3:后验概率输出函数的参数值
q1、q2、q3:SVM的准确率
步骤:
begin
for eacht∈Udo
fori=1 to 3 do
根据公式(13)得到t.fi(x);
根据公式(16)sigmoid函数输出其属于真实评论者的概率t.pi(T);
t.pi(F)←1-t.pi(T);
t.mi(T)←t.pi(T)*qi;
/*结合SVM的准确率ri计算单特征下关于真实评论者的信度*/
t.mi(F)←t.pi(F)*qi;
/*计算单特征下关于虚假评论者的信度*/
t.mi(Θ)←1-qi;
/*利用SVM的错误率表示不确定性*/
end for
t,k←1-∑N1∩N2∩N3=φt.m1(N1)*t.m2(N2)*t.m3(N3);
t,mr←∑N1∩N2∩N3=Tt.m1(N1)*t.m2(N2)*t.m3(N3)/t.k;
t,mF←∑N1∩N2∩N3=Ft.m1(N1)*t.m2(N2)*t.m3(N3)/t.k;
t,mθ←∑N1∩N2∩N3=θt.m1(N1)*t.m2(N2)*t.m3(N3)/t.k;
end for
return 所有t.mT、t.mF、t.mΘ
end
不难看出,算法1的执行代价主要取决于单特征下证据支持度的获取及证据融合.其中,单特征下证据支持度的获取执行一个常数次循环,证据融合依次执行计算规范化因子及3个mass函数基于识别框架下的证据融合,若有n个评论者,算法1的时间复杂度为O(n).
5 实验结果
为了评判虚假评论者识别方法的准确性,我们从亚马逊官网共计爬取了4000个用户的完整信息,请三位有五年以上网上购物经验的硕士作为标记人对样本集进行标记,并制订了五条虚假评论者鉴别规则:1)评论总在商品上架后不久发表且评论日期呈现集中化趋势;2)极端好评与极端差评占绝大多数且常与平均打分出入很大;3)评论内容相似度很高且存在抄袭他人评论的现象;4)评论局限于个别商家并且反复对此商家的商品给予好评或差评;5)发表评论较多但与其他评论者不存在互动行为.当评论者的行为符合以上两点或者两点以上的描述时,评论者身份很可疑.最终人工标记结果见表3,其中“”表示和主对角线相对称单元格数值相同.
本文通过计算Kappa值[27]对三位标记者标记结果的一致性进行检验,Kappa值越高,说明标记结果的一致性越高.三位标记者之间的Kappa值分别为0.79、0.89和0.87,人工标记结果具有很高可信度.当评论者被两个及以上专家标记为虚假评论者时,视其为虚假评论者.实验环境如下:Intel(R)Core(TM)i7-6700HQ 2.6GHZ处理器,8GB内存,Windows10(64位)操作系统,使用MatlabR2016a作为实验平台.
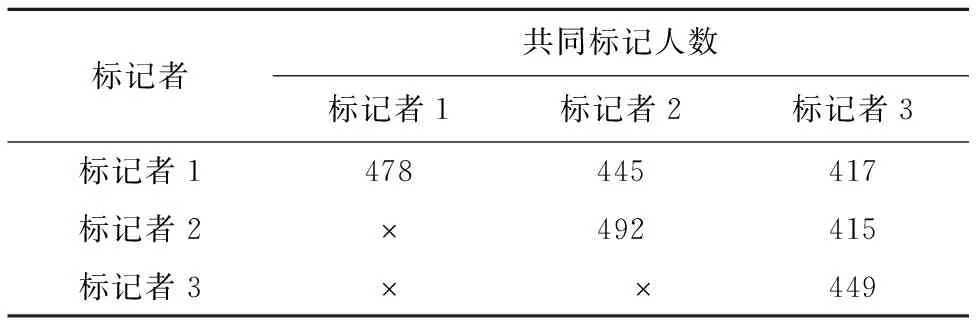
表3 专家标记虚假评论者结果
5.1 SVM准确率测试
由于s10取值范围不为[0,1],我们首先对s10取值进行[0,1]归一化处理.不同惩罚因子与核函数的选取会构建不同的分类超平面,进而影响到SVM准确率.SVM准确率越低,说明单特征下评论者识别的不确定性越高,进而会增大证据融合后不确定性的mass函数值、降低最终判断决策的准确率.因此,我们对不同数量样本集下SVM模型进行测试,测试SVM的准确率随着样本数量增加的变化趋势;同时,选取不同的核函数和惩罚因子,测试不同参数选取对SVM准确率的影响.我们以评论者评价行为构建SVM为例,选取RBF核函数为典型代表,将训练样本分为5个子集,采取交叉验证[28]的方式对SVM进行训练,即每次以其中一个子集作为测试集,将其他四个子集作为训练集,整个过程进行不重复循环直至每个子集都作为测试集被预测一次,最后取5次结果准确率的平均值去衡量SVM准确率.惩罚因子c分别选取为0.1、1、10、100、1000.实验结果如图1所示.同时,我们固定惩罚因子为100,选取线性核函数、多项式核函数、RBF核函数及sigmoid核函数作为测试对象,对这些核函数下SVM的准确率进行测试,测试结果如图2所示.
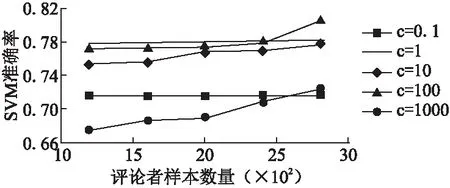
图1 不同惩罚因子下RBF核函数SVM模型准确率
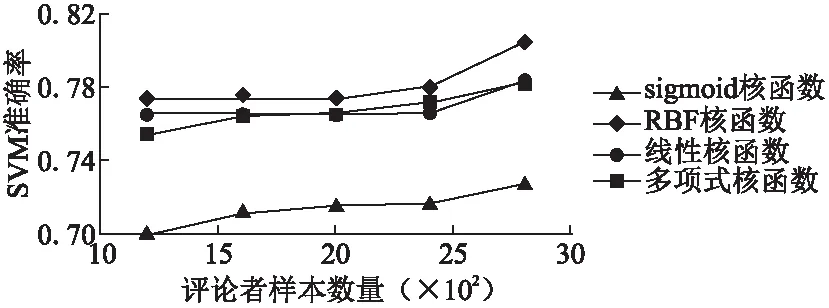
图2 惩罚因子为100时测得不同核函数下SVM准确率
根据图1和图2的测试结果,可得出随着训练样本数量递增,SVM准确率大体呈上升趋势.sigmoid核函数分类效果明显不如其他三类核函数,同时,当惩罚因子过大或过小时,都会降低SVM的准确率,进而大大增加证据理论模型中评论者识别的不确定性.因此,选择合适的惩罚因子和核函数才能使模型的识别效果达到最佳.为避免惩罚因子选择不当对实验结果的影响,我们其取值范围设置为[2-7,210],步距为0.1,测得最高准确率如表4所示.根据表4结果,我们选取RBF核函数作为最终三个SVM模型的核函数.
5.2 不同方法下虚假评论者识别比较
根据表4选取最优准确率对应的SVM模型作为单一特征模型,将SVM的无阈值输出通过sigmoid函数得到在各个证据体下的证据支持度,进而进行证据融合,对得到的融合后的证据支持度依据判别规则对评论者身份进行判定并统计准确率.部分样本的证据融合结果如表5和表6所示,根据实际情况,我们取θ1=0.05,θ2=0.1.

表4 不同核函数下的最高准确率
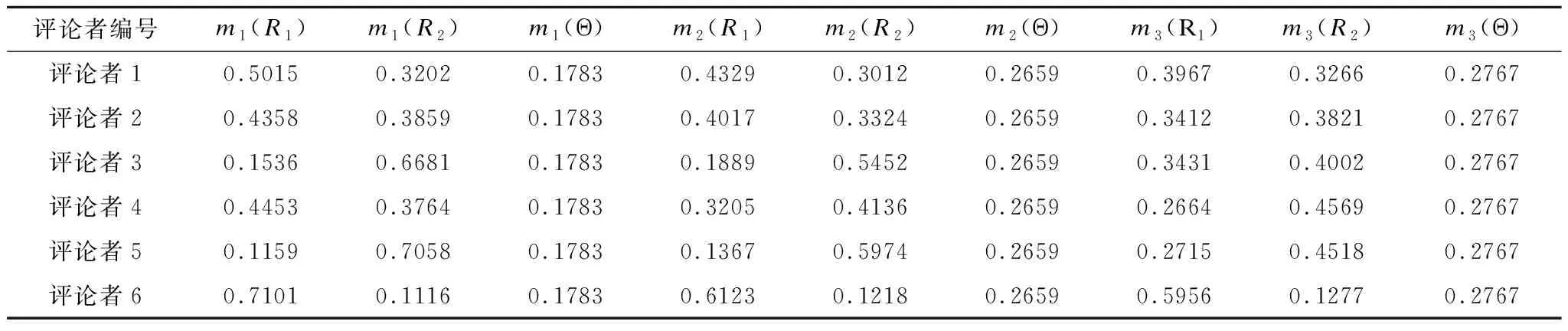
表5 初始不同评论特征下的证据支持度
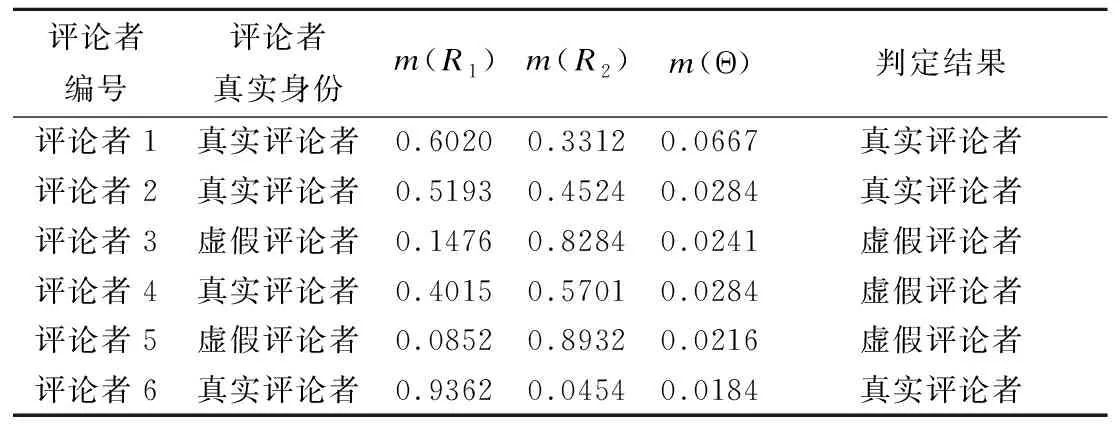
表6 D-S证据融合后的证据支持度
根据最终实验结果,证据理论模型对评论者的预测准确率达提高到了87.76%,相对于其它单特征下评论者识别效果有明显提升.根据表4可以看出,其他三类检测方法中,基于评论者对商品关注行为特征的检测效果最差,大概为70%,而基于评论者的评价行为检测效果优于另外两种.在单特征下评论者身份无法识别时,比如评论者2,可以通过证据融合的方式对其身份进行识别.因此,证据理论模型提高了评论者识别的准度,也使识别的不确定性大大降低.
为了验证模型的合理性,我们重新输入标记者新标记的1000个真实评论者和1000个虚假评论者作为样本统计准确率和召回率,测试所得虚假评论者识别准确率、虚假评论者识别召回率、真实评论者识别准确率、真实评论者识别召回率如表7所示,可以看出,基于证据融合方法的准确率和召回率都要高于其他三种单一特征下的识别方法.
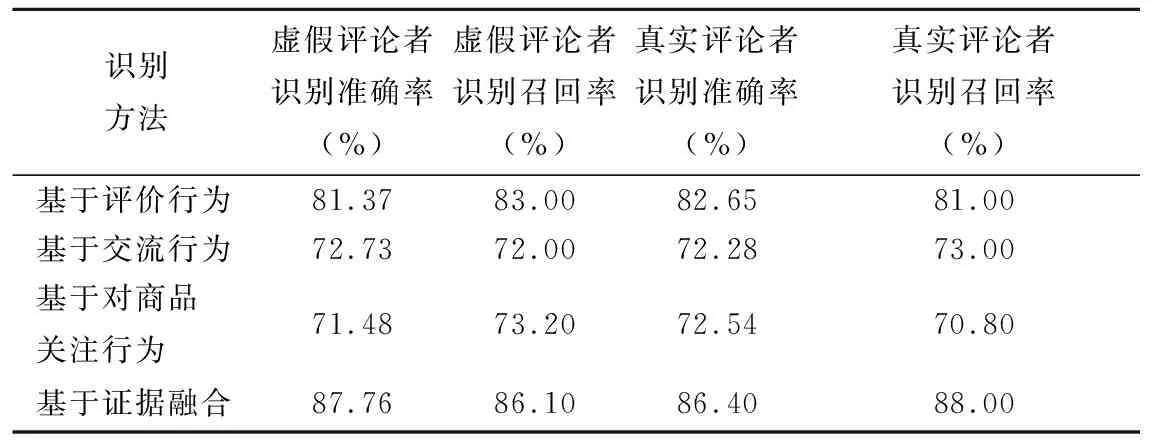
表7 基于不同方法的识别准确率及召回率
同时基于前文提到的11种评论者属性维度,我们利用Native Bayes、Logistic Regression和Decision Tree 3种有监督机器学习模型进行了对比实验,实验结果如表8所示.
可以看出,相比较于其他方法,证据融合的虚假评论者识别准确率提高了4%-9%,识别召回率提高了3%-8%,F1值提高了0.03-0.08.因此,证据融合方法在虚假评论者识别上优于其他三种传统方法.

表8 四种方法的实验结果对比
最后,在算法1得到mass函数值的基础上,我们将评论者按虚假评论者证据支持度由大到小排序,以被标记者标记的次数将评论者分为3、2、1、0这4个级别,以10为排列位置间隔,计算前k(k=10,20,30,…,100)位置排列的NDCG值[29],NDCG值越高,说明排序结果越科学.同样,在单一行为模式检测下,我们按虚假评论者后验概率值大小由高至低进行排序,对NDCG值进行计算,实验结果如图3所示.随着排列位置的后移,四种排序方法得到的NDCG值都趋于稳定,其中,基于证据融合进行排序比其他排序方式提高了2%-4%,明显优于其他排序,相反,基于评论者交流特征和基于对商品关注特征的排序并不是很好的排序方法.因此,基于虚假评论者证据支持度进行排序对虚假评论者有更好的区分度,能更准确地找出潜在的虚假评论者.
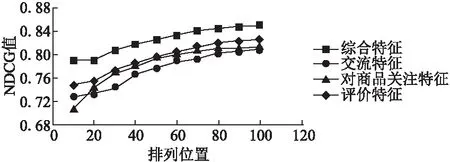
图3 不同排序方法下的NDCG值
6 总 语
本文从解决虚假评论者识别问题出发, 分析了评论者评价行为在内的三种行为模式, 以多个维度对评论者行为特征进行描述, 并基于用户行为证据融合构建D-S证据理论模型. 本文提出的方法和思路, 利用影响用户身份各因素的不确定性和它们之间的相互关系, 从评论者的评价行为特征、 评论者对商品的关注特征、 评论者的交流行为特征三个全面的角度综合考虑对评论者的身份进行检测. 建立在真实数据上的实验结果表明, 本文提出的方法结合多种作弊模式并进行证据融合, 可准确、 快速地检测评论者身份, 避免了单个特征指标在解决虚假评论者检测问题上的不足, 能够帮助人们快速发现电子商务网站中存在虚假评论者、 虚假评论及低信誉商家, 进而对商品质量有更清晰的了解. 文献[3]从用户打分行为角度对虚假评论者进行分析, 列出了一些虚假评论者检测的可行指标. 文献[20]基于不同时间片下评论数量和平均打分的变化发现虚假评论和虚假评论者. 相比于文献[3]和文献[20], 我们更加系统全面地从不同角度分析了评论者行为, 同时更进一步对模型性能进行了测试. 相对于文献[15]76%和文献[21]83.7%的识别准确率, 我们87%的识别准确率取得了一定的提升. 然而, 本文的方法不适合对作弊团体中只发表个别评论的虚假评论者进行检测. 今后将从集体作弊的角度分析, 去发现危害性更大、 隐蔽性更强的虚假评论者团体.
