改进的灰色GM(1,1)预测模型
2015-12-23谢锦彪欧毓毅
谢锦彪,欧毓毅,凌 捷
(广东工业大学 计算机学院,广东 广州510006)
0 引 言
GM(1,1)模型[1-3]本身的预测公式存在局限性[4],且对于高增长序列的预测精度不高,有许多学者对其进行了改进[5-9],这些改进主要是单一地改进模型的背景值或初始(值)条件,或者同时改进模型的背景值和初始条件。近几年研究的重点逐步偏向于同时改进背景值和初始条件,但是模型的模拟精度和预测精度还有待进一步提高。
本文在文献 [10]优化传统GM(1,1)模型的背景值构造公式的基础上,进一步优化背景值的计算公式,并基于最小二乘法原理对预测初始条件进行改进,将背景值的改进和最优初始条件的选择结合在一起,以文献 [5,10]共同使用的低增长序列x(0)(k)=e-ak(k=1,2,3,4,5)以及文献 [10]中高增长序列为例进行模拟分析实验,提出的预测模型比文献 [5,10]具有更高的模拟精度以及预测精度。
1 经典GM(1,1)预测模型及缺陷分析
1.1 经典GM(1,1)模型
设非负序列X(0)= {x(0)(k),k=1,2,3…n}为原始序列。
(1)对原始序列X(0)作一次累加生成序列X(1)= (x(1)(1),x(1)(2),…,x(1)(n))。即:X(1)(k)=(i)(k=1,2,…,n);
(2)建模。由X(1)得到GM(1,1)模型的背景值Z(1)= {z(1)(k),k=1,2,3…n},其中Z(1)(k)=μ (x(1)(k)+x(1)(k-1))(k=2,3,…,n),一般μ取0.5。将白化方程+ax(1)=b 离散化,由微分变差分,得到GM(1,1)的灰微分方程如下所示
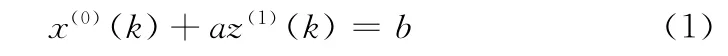
(3)求解发展系数a和灰色作用量b。按照最小二乘法原理解式 (1)可得参数a和b。其中则可得式 (2)

(4)建立预测公式。累加序列X(1)的预测公式为:(k+1)=*e-ak+,其中k=0,1,…,n-1;令C =则x.(1)(k +1)=Ce-ak+,其中C 为待定常数;由初始条件(1)=x(1)(1)=x(0)(1),有C =x(0)(1)-,故

根据式 (3)累减可得原始序列X(0)的预测值:(k+1)=(x(0)(1)-)(1-ea)e-ak,(k=1,2,…,n-1),且(1)=x(0)(1)。
1.2 GM(1,1)模型的缺陷分析
GM(1,1)模型对白化方程的两边在 [k-1,k]对t积分,化简可得再由式 (1)可得(1,1)模型背景值的构造误差[11]主要因为用Z(1)(k)=0.5(x(1)(k)+x(1)(k-1))代替了即用图1中的梯形abcd面积代替了X(1)(t)在区间 [k-1,k]与t轴围成的面积,从而导致了误差△S。当数据为高增长序列时,误差就比较大。再者,GM(1,1)模型解白化方程时,其假设条件是原始数据序列的第一点值等于预测数据序列的第一点值,即(1)=x(0)(1),得到的拟合曲线必定经过 (1,x(0)(1))。但是按照最小二乘法原理可知,拟合的曲线未必经过原始数列的第一点。

图1 背景值构造公式误差
2 背景值的优化
从模型的预测公式可以看出,模拟和预测的精度取决于发展系数a和灰色作用量b,而a,b的求解取决于背景值。文献 [10]在对背景值的优化过程中,在区间 [k-1,k]上对白化方程两边求积分,设x(1)(t)=BeAt,并记但是对比假设的x(1)(t)的表达式和GM(1,1)的一般过程中的x.(1)(k +1)=Ce-ak+表达式可以发现文献 [10]在假设过程中做了简化,忽略了常数项,这在一定程度上影响了背景值的逼近效果,从而影响模型的模拟和预测精度。为了避免由此引起的误差,在其假设的基础上设x(1)(t)=BeAt+p,x(0)(t)=beAt。
记

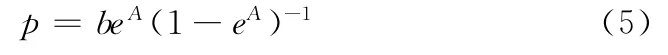
又因为

得

且

将式 (6)、式 (7)代入式 (5)可得

由式 (4)及假设条件x(1)(t)=BeAt+p 可得z(1)(k)=[x(1)(k)-x(1)(k-1)]+p,由于一次累加序列X(1)累减后有x(0)(k)=x(1)(k)-x(1)(k-1),故

将式 (7)、式 (9)代入式 (10)可得新的背景值计算公式

其中 (k=2,3,…,n)。
3 预测初值的优化

由以上公式并根据实际意义可知,离差平方和S最小时,其对G 的导数为零,故可以解得

4 实验与结果分析
根据以上改进的结果,由式 (2)、式 (11)、式 (12)、式 (13)即可得到本文提出的GM(1,1)模型,记为新模型。记文献 [5]改进的模型为模型1;记文献 [10]改进的模型为模型2。本文实验仍然采用文献 [5,10]共同使用的例子,以x(0)(k)=e-ak(k=1,2,3,4,5)并分别取-a=0.1、0.2、0.4、0.5、0.6、0.8、1.0、1.5、2.0、2.1、2.5、3.0,得到原始序列如下所示:

以上各式,k=1,2,…,6。
为更清楚表示改进后的结果,新模型得出的数据小数点后保留的位数以文献 [5,10]中相应的数据小数点后保留的位数为参考。
实验1:按照模型1 使用的数据,取-a=0.1、0.2、0.4、0.6、0.8、1.0、1.5、2.0、2.5、3.0。比较模型1与新模型取不同发展系数时模拟数据与原始数据的平均相对误差和平均绝对误差。两种模型的模拟精度对比结果见表1。
从表1可以看出,-a从0.1到0.4,新模型的平均相对误差整体在增加,-a>0.6以后,相对误差在逐渐减小,但是新模型的平均绝对误差以及平均相对误差都要小于模型1,从表1对比的结果可以得出新模型比模型1具有更好的模拟效果。

表1 新模型与模型1模拟精度比较
实验2:按照模型2 使用的数据,取-a=0.1,0.5,1.0,2.1。比较模型2与新模型取不同发展系数时模拟数据与原始数据的平均相对误差S以及k=6时的预测精度。两种模型的模拟精度对比结果见表2。k=6时,模型2和新模型得出的模拟值序列以及对应的相对误差分别为X模型2,X新,S模型2,S新,两种模型的预测精度对比结果见表3。

表2 新模型与模型2模拟精度比较
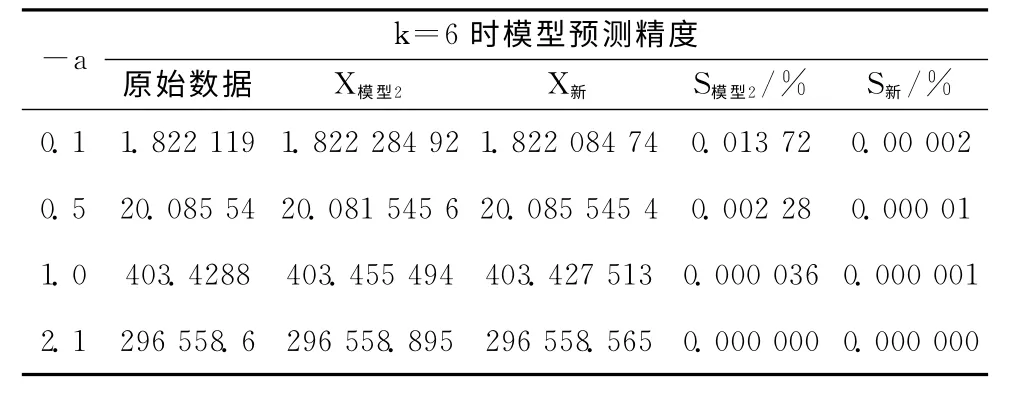
表3 新模型与模型2预测精度比较
通过表2的数据可以看出,无论是发展系数小还是发展系数比较大时,新模型的模拟精度始终高于模型2的模拟精度,而且随着模拟精度的提高,新模型的预测精度也同样高于模型2的预测精度,两种模型预测精度的对比结果见表3。
实验3:取模型1的高增长序列的前5个数据预测后2个数据。原始序列 X(0)= (2.718,7.389,20.086,54.598,148.41,403.43,1096.6)。由序列的前5个数据并结合本文提出的改进模型,得到时间响应函数如下

模型1和新模型关于此高增长序列的模拟精度以及预测精度对比结果见表4,其中S为平均相对误差。
由表4可以清晰地看出,对于高增长的序列,新模型的模拟和预测精度都比模型1有显著的提高。

表4 高增长序列模拟精度及预测精度比较
5 结束语
本文提出了一种改进的GM(1,1)预测模型,进一步地优化了预测模型的背景值构造公式并改进了模型初始值参数的选取策略。分别以低增长序列和高增长序列为例进行了模拟分析实验,实验结果表明,改进的模型同时适用于低增长序列和高增长序列建模,不管是在发展系数较小时还是当发展系数超过经典GM(1,1)方法的适用范围(-2,2)时,都具有很高的模拟精度和预测精度。
[1]Wang Zi,Dang Yaoguo.Research on carbon emission prediction in Jiangsu Province based on an improved GM (1,1)model[C]//IEEE International Conference on Grey Systems and Intelligent Services,2013:93-97.
[2]XIE Weiguo,SHI Huaji.Demand forecasting with GM(1,1)optimized by game theory in supply chain [J].Computer Engineering and Applications,2013,49 (9):243-246 (in Chinese).[谢伟国,施化吉.博弈改进的GM(1,1)在供应链需求预测中的应用 [J].计算机工程与应用,2013,49 (9):243-246.]
[3]SUN Qiang,WANG Qiuping.Water supply quantity forecast of Xi’an via combination rough sets with GM(1,N)model[J].Computer Engineering and Applications,2013,49 (11):237-240 (in Chinese). [孙强,王秋萍.融合粗糙集和灰色GM(1,N)的西安市供水量预测 [J].计算机工程与应用,2013,49 (11):237-240.]
[4]YU Huafeng,CHEN Pengyu.Based on pattern search method optimized GM(1,1)model[J].Statistics and Decision,2010(7):154-155 (in Chinese).[俞华锋,陈鹏宇.基于模式搜索法优化的GM(1,1)模型 [J].统计与决策,2010 (7):154-155.]
[5]HU Yanbing,CHEN Yongming,ZHAO Yue,et al.Iterative optimal background value of GM(1,1)model[J].Statistics and Decision,2013 (21):34-36 (in Chinese). [胡炎丙,陈勇明,赵月,等.迭代优化背景值的GM(1,1)模型改进[J].统计与决策,2013 (21):34-36.]
[6]XU Huafeng,FANG Zhigeng.GM(1,1)model with optimization winterization equation [J].Mathematics in Practice and Theory,2011,41 (7):163-167 (in Chinese).[徐华锋,方志耕.优化白化方程的GM(1,1)模型 [J].数学的实践与认识,2011,41 (7):163-167.]
[7]LI Weihua,WANG Shujuan.The initial value based optimization GM(1,1)model in dam deformation monitoring [J].Guangdong Water Resources and Hydropower,2010 (8):40-42 (in Chinese). [李卫华,王淑娟.基于优化初始值的GM(1,1)模型在大坝变形监测中的应用 [J].广东水利水电,2010 (8):40-42.]
[8]LI Wei.GM(1,1)model with optimal parameters[J].Computer Engineering and Applications,2011,47 (14):25-27(in Chinese).[李蔚.参数最优化的GM(1,1)模型 [J].计算机工程与应用,2011,47 (14):25-27.]
[9]ZHANG Bing,XI Guiquan.GM(1,1)model optimization based on the background value and boundary value correction[J].Systems Engineering Theory and Practice,2013,33(3):682-688 (in Chinese).[张彬,西桂权.基于背景值和边值修正的GM(1,1)模型优化 [J].系统工程理论与实践,2013,33 (3):682-688.]
[10]LUO Gongzhi,CUI Jie,XIE Naiming.A new improved method of grey GM(1,1)model[J].Statistics and Decision,2008 (22):11-13 (in Chinese). [骆公志,崔杰,谢乃明.灰色GM(1,1)模型新的改进方法 [J].统计与决策,2008(22):11-13.]
[11]WANG Zhengxin,DANG Yaoguo,LIU Sifeng.An optimal GM(1,1)based on the discrete function with exponential law[J].Systems Engineering Theory and Practice,2008 (2):61-67 (in Chinese).[王正新,党耀国,刘思峰.基于离散指数函数优化的GM(1,1)模型 [J].系统工程理论与实践,2008 (2):61-67.]
