适应性阈值优化的微博消息索引模式
2015-12-23李卫平
张 莉,李卫平
(1.郑州成功财经学院 信息工程系,河南 郑州451200;2.武汉理工大学 信息工程学院,湖北 武汉430070;3.铁道警察学院 公安技术系,河南 郑州450053)
0 引 言
传统的搜索引擎通过网络爬虫收集到海量的网页信息,然后通过预先排序的方式响应用户的搜索请求,这种方式不能满足用户对实时信息的搜索请求[1],其不能对用户刚刚发布的微博信息进行检索。在大规模的微博系统中,系统每秒钟需要处理成千上万条状态更新,因此为用户提供实时的搜索服务是一项极具挑战的事情[2]。为了使每条用户消息都能够被检索,需要对每条消息实时地建立索引,并同时提供高效的基于关键字的搜索服务[3]。在索引的建立和维护中,由于消息到达的频率非常高,因此实时性和高效性是相互矛盾的,必须加以权衡。
微博实时搜索的另一个挑战是缺少有效的微博消息排名算法。例如,当某公司刚刚发布一个新产品后,用户A想通过微博搜索附近专卖店的排队购买情况,而搜索返回的大都是该产品的广告等无用信息。现有的微博搜索大都基于信息的发布时间,因此最新的消息总是排在前面。由于缺少适当的排名算法,微博搜索很难满足用户的各种不同类型的实时搜索需求。
为了降低排名算法的开销,本文提出了一种高效的适应性微博信息索引方法。根据微博消息的转发和回复等信息将消息组合成树形结构,通过对树形结构进行分析,将消息聚类成若干话题,在内存中维护活跃的话题,并据此更改倒排索引的结构。
1 相关工作
1.1 部分索引与视图实体化
在数据库系统中,对数据建立索引结构可以加快数据处理过程,然而现有的索引方法主要用于基于相似性的KNN 搜索。例如,iDistance索引方法[4]不能高效的应对大量的插入操作,因而不能直接应用于微博消息的索引。部分索引方法[5]只对部分查询概率高的数据进行索引,因而能应对大量的数据插入操作。学者[6]采用统计模型监测用户的查询分布,并根据查询的分布情况动态的调整索引结构。另一研究者[7]应用分布式哈希表对罕见的数据建立部分索引结构,而对常见的数据应用泛洪搜索方法。
视图实体化的基本原理与部分索引技术相似。文献[9,10]讨论了如何在多维数据库和数据仓库系统中适应性地对视图进行调整。文献 [11,12]提出的代价模型可以动态的选取数据的视图并进行实例化。Silberstein A等[13]应用适应性视图实例化策略来减小流注入系统的开销。本文提出的一种索引方法的基本思想与上述方法相似,其差别在于本文只对查询必要的数据进行实时索引,而对其它数据通过批处理的方式进行处理。
1.2 微博搜索
Google和Twitter都有自己的实时搜索引擎。Google通过Web爬虫适应性地抓取微博数据,而Twitter通过现有的Lucene技术提供搜索服务。这两个系统都将用户的查询看作是连续的查询操作,并实时地对查询结果进行更新。然而,搜索引擎的排名函数仅仅考虑时间维度,因此搜索结果按照时间进行排序。通过对微博系统中的用户行为进行分析,Java等[14]和Teevan等[1]分别提出了复杂的排名算法。由于大多数的排名算法都很复杂,执行效率低并且占用大量的资源,只能通过离线的方式进行处理。为了解决这一问题,Sankaranarayanan等[15]过滤掉微博中的噪音数据,并且将相似的消息聚类成话题。这种方法通过对相同话题中的消息进行排名,从而大大减小了排名所用的计算开销。本文根据微博消息的转发和回复等信息将消息组合成树形结构,通过对树形结构进行分析,将消息聚类成若干话题。为了降低排名算法的开销,本文在内存中维护活跃的话题,并据此更改倒排索引的结构。
2 系统结构
2.1 数据表示与编码
在微博社会网络中,用户通过好友关系 (如关注与被关注)构成一个社会图Gu=(U,E),其中U 为系统中的用户集合,E 为用户之间的好友关系。
除了社会图以外,微博中消息之间的转发与回复关系构成了消息关系图。图1是简单的微博消息关系,其中每个节点表示一条消息,消息之间的有向边表示消息之间的转发与回复关系。用户A 发布了一条消息 (根节点),此后用户B,C和D 分别转发或回复了该条消息。微博消息之间的关系图是一个树形结构,本文应用该树形结构表示一个话题。搜索时,将该话题包含的树形结构进行组合,作为结果一起返回给用户。

图1 简单的微博消息关系
由于维护话题树的开销很高,本文不显示的对其进行维护,而是树中的每条消息进行编码。给定消息ti,通过各自的时间戳 (消息进入系统的时间)对节点ti的子节点进行排序。如果节点ti的编码是x,节点tj是ti的第k 个子节点,那么tj的编码是x-k,例如节点D 是节点A 的第3个子节点,其编码为0-2(编码计数从0开始)。通过该编码方式可以很容易地将树的编码重构成树。
2.2 系统设计
本文采用倒排索引的方式用于数据的查询。当新的消息进入系统时,索引程序决定是否对其建立索引结构。为了快速的建立和维护索引结构,内存中保存数据的统计信息,数据库中保存着微博数据 (tweets)及其倒排索引。当指定关键字查询时,倒排索引返回包含关键字的消息(tweets)列表T。图2给出了倒排索引的索引结构。索引的每条记录保存着消息的标示符TID (区分不同的消息),排名值U-PageRank,词频TF,树的标示符TID,以及消息的时间戳time。TID 是消息组成的话题的根节点的标示符。包含相同关键字的消息组成一个链表,其中最近插入的消息在链表的头部。

图2 倒排索引结构
为了方便排序过程,系统还包含微博消息的数据表。其元数据结构包括所属话题树的根节点 (TID),父节点(RID),时间戳 (time),子节点个数 (count),话题树的编码 (coding),作者的标示符 (UID)和pointer。当消息在索引文件中时,pointer为空,当消息写回日志时,pointer指向日志的偏移地址。为了支持对消息和用户标示符的检索,采用B+树对TID 和UID 进行索引。除了消息数据表,系统还包含日志文件用于记录那些没有被索引的消息。数据表中包含的消息是有选择性的,即重要的消息。噪音数据周期性的被写入日志文件的末端,后台的批处理索引过程会定期扫描日志文件以便对噪音数据进行索引。
为了支持微博消息的实时索引及搜索,在内存中保存部分重要的信息,如关键字阈值,候选话题链表和流行话题链表。关键字阈值记录了最近流行的查询的统计信息。候选话题链表维护着新近话题的相关信息。流行话题链表维护着用户广为讨论的话题。基于上述信息,可以快速地将新消息区分为重要消息和噪音消息,据此采用不同的索引策略。此外,基于内存中的数据结构,可以结合时间戳,流行性和相似性实时地响应用户的查询操作。
3 基于内容和排名的索引模式
本文基于微博消息的内容及消息相对于查询的排名来对消息进行索引。将新消息与流行查询集合相匹配,并按照该消息在查询结果中的排名决定是实时索引还是进行后台的批处理索引。为了提高搜索结果的质量,本文的排名算法综合考虑从消息的PageRank值,话题的流行性以及消息和查询之间的相似性。
3.1 微博消息分类
由于微博消息内容短,消息本身含有的信息量非常少,本文采用基于查询的分类方法。本文假设用户只关心检索结果的Top-k项,该假设在文献 [8]中得到了验证。其中62%的用户访问了第一个返回页面中的一项,并且超过90%的用户在浏览了3个页面后就停止浏览行为。
定义1 微博消息分类:给定消息t和用户查询集合Q ,在查询函数F 下,如果-qi∈Q,并且t是qi的前Top-k项结果,那么t是重要消息。否则,t是噪音消息。
为了返回查询集合Q 中查询的Top-k项结果,只需要对重要消息进行索引,而噪音消息可通过批处理方法周期性的索引。这种方法可以降低索引频繁更新带来的开销。
对于不同的查询集合Q,分类结果是不同的。理想情况下,当包Q 含所有查询时,该分类对每个查询都得到准确的结果。然而这种方法的索引维护代价高,可通过部分索引的方法在准确性和效率上进行折中。研究表明,社会现象事实上服从Zipf定律,即80%的用户请求可以用20%的常用查询来表达。因此,可以在查询集合Q 中维护部分常用的查询,以此来降低索引维护的开销。假设第n 个查询出现的概率为

式中:α和β——Zipf分布的参数。令s为每秒提交的查询的个数,那么第n个查询的时间间隔的期望是

式 (2)表明,在t(n)秒之后,第n个查询被提交到系统的概率很高。如果系统进行批处理索引的周期是t′,那么只有当t(n)<t′时,才将第n个查询加入到Q 。这种方法的直观解释是:不需要对频繁的查询进行频繁的索引更新。
为了估计查询分布,在磁盘上保存一个查询日志。当某查询第一次进入系统时,将其视为非频繁的查询,并在下一次批处理索引更新时进行更新。通过对查询日志进行分析来建立一个查询柱状图,并用Zipf分布模拟其分布情况。基于式 (2),将频繁查询加入到Q。
假设微博消息集合为T,用F(qi,tj)表示消息tj∈T给定查询qi∈Q 下的排名值。
定义2 支配集:给定消息集合T,查询q,以及消息t∈T,t的与q 相关的支配集包含比t的排名值更高的那些消息,即

计算消息t的支配集的最直接方法是对Q 中所有的查询计算支配集。这种方法需要对整个消息集合进行扫描,为了解决上述问题,本文提出了相应的优化方法。
3.2 Top-k阈值优化
在自然语言中,单词服从Zipf定律[16],即每个单词在文本中出现的概率是固定的。在给定查询下,重要消息的个数随着时间的推移趋于稳定值。
定理1 令每个关键字在微博消息集合中出现的概率是固定的,并且微博消息以稳定的速率进入系统。如果查询qi有m 个结果 (m K),那么qi的Top-k个结果的方差随着K 的增大而减小。
证明:系统含有n 条消息,并且有m 条消息包含关键字,K <m ≤n。假设消息在数据集中是随机分布的,通过对消息的排名值进行排序得到列表{t1,t2,…,tn},第K 条消息排在位置x 的概率为

那么,Top-k个结果的数学期望是

式中:score(i)——第i个消息的排名值。于是该问题转化为顺序统计问题。基于文献 [4]给出的上界,当m 足够大时,对于大的K 值可以得到E(K)近似值。
定理1与本文的分类方法相对应。对每一个查询q∈Q,保持这一个Top-k阈值,所有查询的Top-k阈值组成了阈值表Tθ。Tθ(q)返回查询q的Top-k个结果的阈值。
引理1 对于消息t,如果F(qi,t)<Tθ(qi),那么t在此刻的支配集含有的元素个数大于K 。
证明:如果F(qi,t)<Tθ(qi),那么t的排名值小于当前第K 个结果的排名值。于是,排名值大于t的消息的个数大于K 。
定理2 对于消息t,如果对所有的qi∈Q,都满足F(qi,t)<Tθ(qi)并且F(qi,t)随着时间而减小,那么t是噪音消息。
证明:由于F(qi,t)随着时间为减小,那么消息t不再是查询qi的查询结果。因为t不再是所有查询的查询结果,那么t是噪音消息。
定理2要求排名函数F(qi,t)随着时间而减小。为了保持热点话题及其发展倾向,本文的排名方法F(qi,t)在一小部分热点话题中会存在部分的凸起,但是整体趋势是下降的。
4 实验设计与结果分析
本节通过实验对提出的索引模式的性能进行了验证。实验采用的数据集为Twitter数据集,该数据集的详细信息见文献 [17]。在实验中,用数据集的前10天的数据作为启动数据对系统进行初始化 (包括建立Top-k阈值,统计话题的流行性),并用最后10 天的数据测试系统的性能。在关键字的提取过程中,提取了前10天的所有关键字,并删除了无意义的虚词以及频率低的关键字,最后得到大约5千个关键字。在查询过程中,查询包含的关键字随机生成,并且查询关键字的个数服从Zipf分布。其中查询的60%包含一个关键字,30%包含两个关键字,10%包含3 个及以上的关键字。所有的实验重复10次,并取所有结果的平均值。在实验中,将本文提出的tweets索引模式记为TI。
4.1 索引适应性分析
实验分析了适应性索引模式对系统性能的影响。图3显示了实时进行索引的消息数量的百分比。如果查询结果只返回top-10项,那么可以对超过80%的消息进行剪枝,并应用离线批处理进行索引。由于只需要对部分消息实时进行索引,因此可以大大提高索引的性能。图4对比了TI索引与完全索引的索引时间对比。在TI中,索引的开销与消息的个数近似成正比,并且其时间远远低于完全索引方法。
为了测试适应性索引是否损失了查询结果的准确性,本文令查询准确性为,其中R 为完全索引返回的结果集,R′为TI方法返回的结果集。对比结果如图5所示。其中,Constant Threshold方法查询处理的Top-k阈值不动态变化,而Adaptive Threshold 方法 的Top-k阈值根据新消息不断地更新。从图5 中可以看出,适应性索引的准确性要高于Top-k阈值不变的索引方法。

图3 TI索引方法的适应性分析

图4 索引时间对比
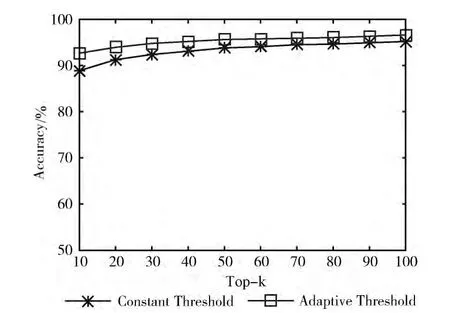
图5 索引的准确性对比
图6展示了索引的准确性相对于时间的变化情况。由于Constant Threshold方法从来不对阈值进行更新,所以其准确性逐渐降低。而Adaptive Threshold方法的阈值随着查询不断地进行更新,所以其准确性相对平稳。图7展示了Adaptive Threshold方法的tweets消息索引的百分比随着时间的变化。从图中可以看出,适应性阈值索引方法性能比较稳定,并且不依赖于K 的选取。
4.2 查询性能分析
由于适应性阈值索引方法采用查询结果更新阈值,其

图6 准确性随着日期的变化

图7 索引的百分比随着日期的变化
开销非常小,本文采用该方法作为tweets的索引方法TI,并将其与完全基于时间的查询TimeBased相对比,结果如图8所示。TI的性能分为排名开销TIRank和搜索时的读操作开销TIRead两部分。图中x轴表示查询命中的消息的个数,y轴表示查询所用的时间。由于对每一个关键字其倒排索引的规模与包含的消息个数成正比,因此TI的搜索时间也随着增加。在后续的研究工作中,将采用并行化的方式来提高TI索引模式的性能。
4.3 内存开销

图8 索引的查询性能对比
为了支持适应性索引模式,本文在内存中维护了相应的数据结构。实验最后分析了适应性索引模式的内存开销,结果如图9所示。TreesInOct为数据集中2009年9月总共包含的树的个数,Active Trees为本文在内存中维护的树的个数。从图中可以看出,随着时间的推移,Active Trees的个数虽然上升,但是上升的很缓慢,其明显小于TreesInOct,并且不到TreesInOct的20%。这再一次表明了Zipf定律的适用性,即大多数查询请求可以用一小部分查询来表示。

图9 索引的内存开销对比
5 结束语
由于微博消息更新速度快,含有的信息量少,传统的搜索引擎不能满足用户对微博实时消息的搜索。为了响应用户对实时消息的搜索,本文在部分索引技术的基础上提出了一种适应性的微博消息索引模式。根据微博消息的转发和回复等信息将消息组合成树形结构,通过对树形结构进行分析,将消息聚类成若干话题,在内存中维护活跃的话题,并据此更改倒排索引的结构。Twitter数据集实验结果表明,本文提出的一种适应性索引模式大大降低了微博数据索引时的时间和空间开销,并且其性能随着时间的推移比较稳定。适应性索引模式增加了索引动态维护的开销,其响应时间要高于完全基于时间的消息检索。本文未来的工作将通过并行化进一步降低查询响应的时间,从而实现微博消息的实时准确检索。
[1]Teevan J,Ramage D,Morris MR.TwitterSearch:A comparison of microblog search and Web search [C]//Proceedings of the 4th ACM International Conference on Web Search and Data Mining,2011:35-44.
[2]LIAN Jie,ZHOU Xin,CAO Wei,et al.Sina microblog data retrieval[J].Jtsinghua Univ (Sci & Tech),2011,51(10):1300-1305 (in Chinese).[廉捷,周欣,曹伟,等.新浪微博数据挖掘方案 [J].清华大学学报 (自然科学版),2011,51 (10):1300-1305.]
[3]Efron M.Information search and retrieval in microblogs [J].Journal of the American Society for Information Science and Technology,2011,62 (6):996-1008.
[4]Agarwal A,Xie B,Vovsha I,et al.Sentiment analysis of twitter data[C]//Proceedings of the Workshop on Languages in Social Media.Association for Computational Linguistics,2011:30-38.
[5]Chen C,Li F,Ooi BC,et al.Ti:An efficient indexing mechanism for real-time search on tweets [C]//Proceedings of ACM SIGMOD International Conference on Management of data,2011:649-660.
[6]Zhao X,Jiang J,He J,et al.Topical keyphrase extraction from twitter[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics,2011:379-388.
[7]Leskovec J,Backstrom L,Kleinberg J.Meme-tracking and the dynamics of the news cycle[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2009:497-506.
[8]Wu S,Li J,Ooi BC,et al.Just-in-time query retrieval over partially indexed data on structured P2Poverlays [C]//Proceedings of ACM SIGMOD International Conference on Management of Data,2008:279-290.
[9]Budak C,Abbadi AEL.Information diffusion in social net-works:Observing and influencing societal interests[J].PVLDB,2010,4 (12):1-5.
[10]Gaonkar S,Li J,Choudhury R R,et al.Micro-blog:Sharing and querying content through mobile phones and social participation [C]//Proceedings of the 6th International Conference on Mobile Systems,Applications and Services.ACM,2008:174-186.
[11]Shan D,Zhao W X,He J,et al.Efficient phrase querying with flat position index [C]//Proceedings of the 20th ACM International Conference on Information and Knowledge Management.ACM,2011:2001-2004.
[12]Stirbu V,You Y.Experiences designing hypermedia-driven and self-adaptive Web-based AR authoring tools [C]//Proceedings of the 3rd International Workshop on RESTful Design.ACM,2012:49-52.
[13]Silberstein A,Terrace J,Cooper B F,et al.Feeding frenzy:Selectively materializing users’event feeds[C]//Proceedings of ACM SIGMOD International Conference on Management of Data,2010:831-842.
[14]Java A,Song X,Finin T,et al.Why we twitter:Understanding microblogging usage and communities [C]//Proceedings of the 9th Web KDD and 1st SNA-KDD Workshop on Web Mining and Social Network Analysis,2007:56-65.
[15]Sankaranarayanan J,Samet H,Teitler B E,et al.Twitter-Stand:News in tweets[C]//Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems,2009:42-51.
[16]Chakrabarti S,Ramakrishnan G,Ramamritham K,et al.Data-based research at IIT Bombay [J].ACM SIGMOD Record,2013,42 (1):38-43.
[17]Seo J,Croft WB,Smith DA.Online community search using thread structure[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management,2009:1907-1910.
