基于GPU的可扩展哈希方法*
2015-12-19胡学萱奚建清林妙
胡学萱 奚建清 林妙
(1.华南理工大学 计算机科学与工程学院,广东 广州510006;2.华南理工大学 软件学院,广东 广州510006)
哈希索引是一种快速的数据检索方法,已广泛应用于文件系统、数据库系统及一些情报检索系统中[1].动态哈希能优雅地扩展存储空间,根据其方法的不同,可分为可扩展哈希[2]和线性哈希[3].如 何扩展和收缩哈希表,快速更新索引记录以便有效地使用哈希索引,一直以来受到人们的广泛关注.Ellis[4]提出了一种基于目录锁和桶锁的两级锁模式的可扩展并行哈希算法;Hsu 等[5]提出了一种可以并发插入删除的可扩展哈希算法;Kumar[6]提出的EHCW算法使用了两阶段锁和事务回滚的策略,可并发扩展/收缩目录,分裂/合并数据页;Lea[7]提出了一种基于复杂锁模式的Java 并发包,允许在改变表大小的同时进行并行查询;Gao 等[8]提出的可扩展哈希算法周期性地切换到全局以调整哈希表大小状态,进行多进程协作执行数据项迁移;Shalev 等[9]提出的RSO 算法通过改变桶地址来扩展或收缩表;Zhang 等[10]提出了基于线性哈希和RSO算法的LHlf 算法;陈虎等[11]提出了一种利用多核处理器的并行计算能力提升批量插入线性哈希表性能的算法;黄玉龙等[12]提出了一种图形处理器(GPU)加速的线性哈希表的批量插入算法GBLHT.
高性能和可扩展的哈希表是当代大数据应用的需求,故需要提高哈希表的并发处理能力.可编程图形处理器因其众核和高存储器带宽而成为并行计算的超强工具,统一计算设备架构(CUDA)这种基于GPU 的计算架构,提供了易用的编程模型和应用程序接口(API),使得将GPU 用于通用计算成为可能[13].为充分利用GPU 的高并发计算能力,提升可扩展哈希方法的性能,文中提出了一种基于GPU 的可扩展哈希方法gEHT.
1 相关的哈希方法
1.1 可扩展哈希方法
可扩展哈希方法分裂和合并桶时,不像线性哈希方法那样按顺序进行,而是按需要进行[2],即当向桶内插入的数据量超过桶的剩余容量时,就分裂该桶,一次分裂产生的两个桶互为对应桶;反之,当桶及其对应桶内数据被删除后不足一个桶的容量时,就合并这两个桶.
图1给出了一个初始桶经过多次分裂形成的分裂树,其中树根为初始桶,实节点为已分裂产生的桶,称为实桶,虚节点为预分裂产生的桶,称为虚桶;实有向边为已产生的分裂,虚有向边为预产生的分裂.桶分裂一次,产生实有向边所指的下一层的两个桶,最底层的所有实桶为现有桶.可见,桶000、001、100、101、10 和11 为现有桶.
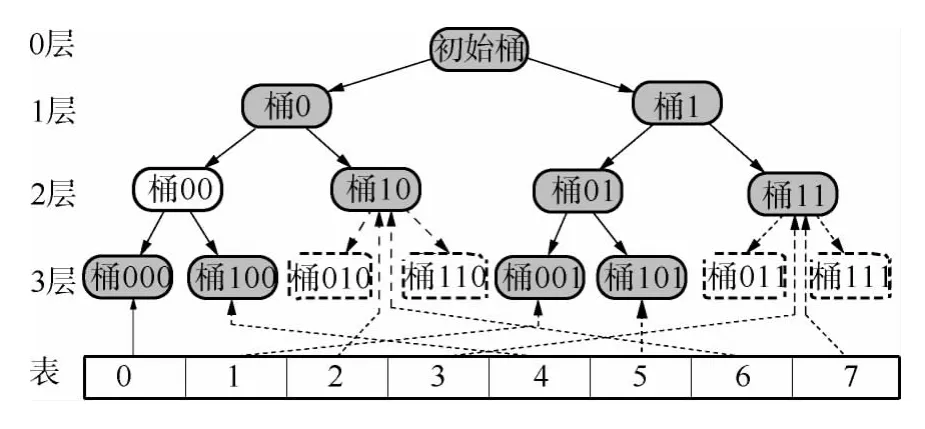
图1 桶的分裂树Fig.1 Split tree of bucket
由于各桶的层次无序,必然导致有些目录项所指的桶为虚桶,解决的方法是将这样的目录项指向该虚桶的实上级桶,即分裂树上该虚桶到初始桶的分裂路径上最大深度的实桶.这样,在检索数据时,能一次定位到不同局部深度的桶上,而不用层层探索,加快了检索速度.
1.2 基于并行技术的动态哈希
文献[4-7]中提出基于锁的算法,具有死锁、长时间延迟和优先级倒置的缺点,当进行表的扩展或收缩时,这些情况更加严重.文献[8]算法使用了write-all 算法,时间复杂度为常数.RSO 算法[9]使用链表来存储数据,故其访问效率低,仅适用于将关键字的低位作为最高有效位的哈希函数.文献[10-12]算法使用了溢出桶,降低了检索效率,并且延迟的分裂使得分裂前溢出桶的数据要重新迁移到分裂后的桶中,这种冗余的数据迁移必然会降低插入的效率.
2 可扩展哈希方法在GPU 上的实现
2.1 基于GPU 的存储结构
为了在GPU 上动态伸缩表并克服可扩展哈希表成倍扩展的缺陷,文中采用两层表结构,分别是段表segList 和桶表bucketList,段表存放段地址,桶表存放桶地址.以桶表的伸缩实现少量的表扩展,段表的重构实现大量的表扩展[12].当扩展的桶集中在少数的段时,只需扩展少数的桶表,其他未扩展桶表可被重用.另外,段表、桶表和桶内数据都采用数组(即便于GPU 并行处理的结构),并且桶内数据采用数组的结构体(SOA)结构而非结构体的数组(AOS),以适应GPU 的存储器的优化存取要求.文献[12]的两层存储结构仅用于动态伸缩.文中采用的存储结构如下:

上述定义中,Gd 为全局深度,bucketNum 为现有桶的数量,Ld 为桶的局部深度,insertLoc 为桶内下一个空闲地址,数组is_df 是每条数据的删除标记.初始时有M 段,每段由N 个桶构成,每个桶的容量为b 条记录.维护这种结构的挑战在于保证桶分裂/合并和表扩展/收缩后,目录项能指向改变后的桶.表及桶的改变分为以下4 种情况:
(1)桶分裂,段表不扩展.如果桶b[i]分裂产生新桶b[i+M·N·2b[i].Ld],分裂后所有桶的最大局部深度未超过全局深度,则段表不扩展.如果没有第(i+M·N·2b[i].Ld)/N 段桶表则增加它,修改该桶表第(i+M·N·2b[i].Ld)%N 项指向新桶,其他项指向相应虚桶的实上级桶.桶b[i]和b[i+M·N·2b[i].Ld]的局部深度为b[i].Ld+1.
(2)桶合并,段表不收缩.若桶b[i]和b[i+M·N·2b[i].Ld]合并,合并后所有桶的最大局部深度不小于全局深度,则段表不收缩.释放桶b[i+M·N·2b[i].Ld],修改桶表目录项i+M·N·2b[i].Ld指向桶b[i],桶b[i]的局部深度为b[i].Ld-1.若第(i+M·N·2b[i].Ld)/N 段桶表所有表项指向的桶的局部深度都小于全局深度,则释放该段桶表.
(3)段表扩展.若分裂后所有桶的最大局部深度大于全局深度,则段表扩展.扩展后的第(i+M·N·2b[i].Ld)/N 项指向新增的桶表,其他表项指向其实上级桶所在的桶表.
(4)段表收缩.合并后所有桶的最大局部深度小于全局深度,则段表收缩.
图2为桶分裂/合并和表扩展/收缩的一个例子.图2(a)所示的桶经过收缩和扩展,产生图2(b)、2(c)所示的桶和表.其中,图2(a)的桶00 和10、01和11 分别合并为图2(b)的两个桶0 和1,则原指向桶00、10 的表项合并后指向其实上级桶0,指向01、11 的表项合并后指向其实上级桶1,桶的最大局部深度小于合并前的全局深度,段表和桶表收缩为原表的一半.图2(a)的桶00 扩展为图2(c)的桶000 和100,桶的最大局部深度大于原全局深度,段表扩展一倍,桶表扩展第2 段,使段表的第2 项指向新增的桶表,第3 项指向第1 段桶表.新增的桶表中,第4 项指向新增的桶100,其他扩展的表项5 指向虚桶101 的实上级桶01.可见,采用这种目录结构虽然扩展了指向新增桶的桶表,但能寻址倍增的桶(包括虚桶).
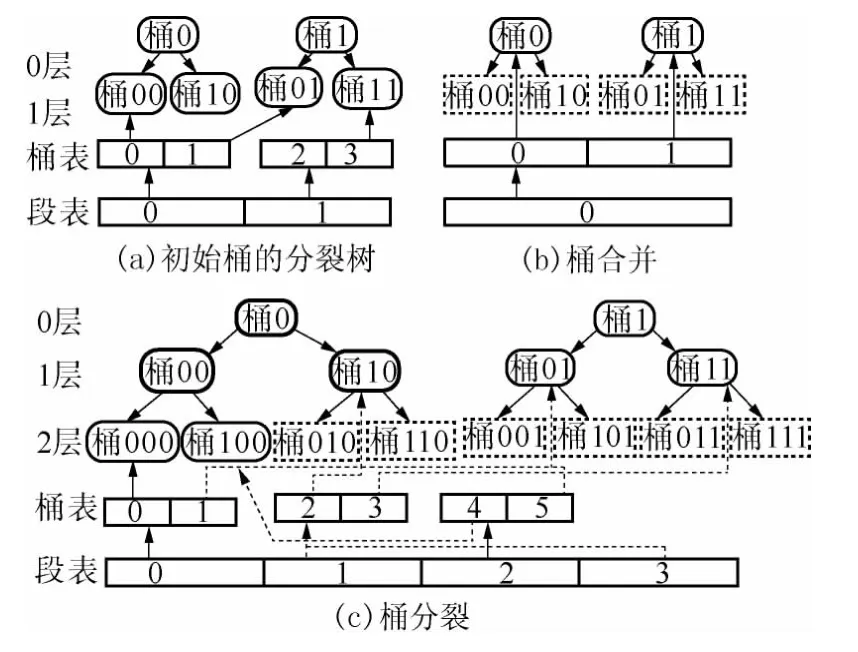
图2 表的收缩和扩展Fig.2 Shrinking and growing of table
2.2 创建哈希表算法
哈希索引的创建包括创建段表、桶表和桶,并使段表和桶表的各项指向新创建的桶表和桶.算法并行创建段内的桶,伪代码如下:

2.3 查询算法
检索数据先计算该数据的散列值,然后定位到桶中并在桶中搜索该数据.在GPU 中,可使每个数据用一个线程处理,高并发地执行.文献[12]的查询算法是基于线性哈希的,因而,对每个数据的查询,延迟比可扩展哈希大.文中查询算法的伪代码如下:

2.4 删除算法
本算法采用延迟删除的策略,即删除并不立即执行,只对删除数据做标记.在批量插入数据时,用插入数据覆盖有删除标记的数据.该算法只需要在查询算法queryEHTable 中加入对要删除的索引记录做标记,文中不再赘述.
2.5 插入算法
当批量插入的数据量大于该桶的剩余容量时,需要分裂桶,如果分裂后仍不能满足插入需要,则要继续分裂直到满足需求为止.分裂会使部分数据迁移到新桶中,这些中间过程的数据迁移是不必要的,会降低索引更新速度,成为插入过程的性能瓶颈[11].因此,文中采用预分裂技术,先循环预测桶的分裂情况,再分裂桶或扩展表并插入数据;充分利用GPU的计算能力,并行处理预测过程和实际插入过程以提高插入效率.
批量插入算法流程如图3所示,预测部分和插入部分的算法主要由子算法A、B、C、D 构成.插入算法的步骤如下:
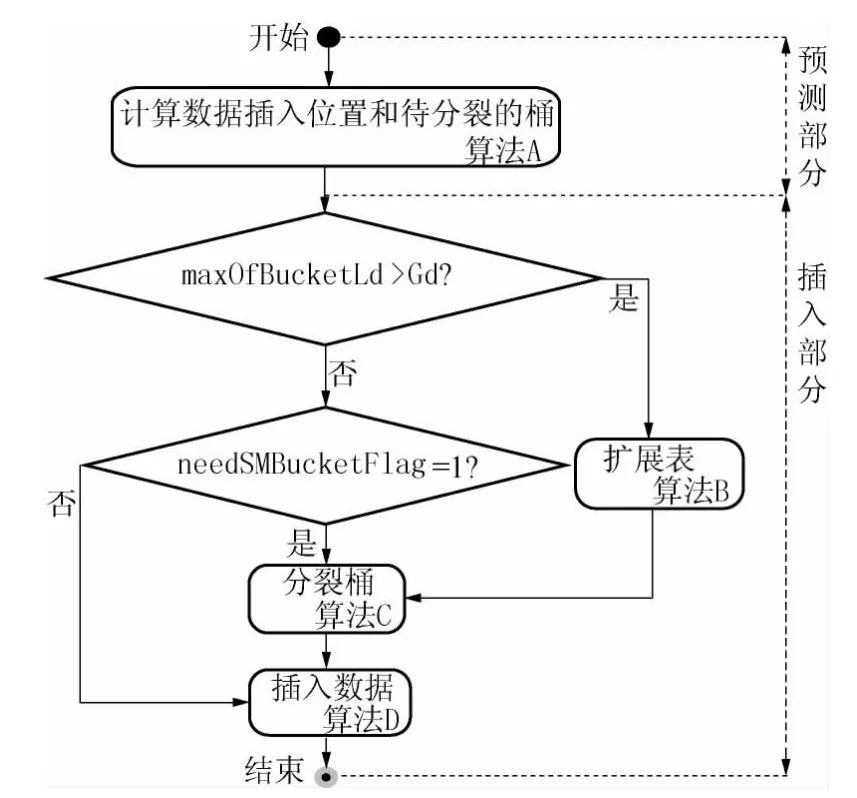
图3 批量插入算法流程图Fig.3 Flowchart of batch insertion algorithm
(1)计算数据插入的桶号insert_bucketNo、各桶插入数据量insert_bucketNum、待分裂的桶号needSMBucketNo、待分裂的段号needSMSegNo、桶预计分裂到的局部深度SMBucketLd、待分裂桶的数量needSMBucketNum、所有待分裂桶预计分裂到的最大局部深度maxOfBucketLd.若待分裂桶的数量needSMBucketNum>0,则置待分裂桶标记needSMBucketFlag=1,并根据上轮循环预计的桶分裂到的局部深度SMBucketLd,循环计算以上数据,直到needSMBucketNum=0,如算法A(countInsert).
(2)若所有待分裂桶预计分裂到的最大局部深度maxOfBucketLd>Gd,则转步骤(3),否则转步骤(4).
(3)扩展段表和桶表,将扩展的段表表项指向新建的桶表,如算法B(growsTable).
(4)若有需要分裂的桶,即needSMBucketFlag=1,则转步骤(5),否则转步骤(6).
(5)分裂桶,修改桶表指针,如算法C(splitBucket).
(6)插入数据,如算法D(insertData).
如2.4 节所述,插入数据将覆盖有删除标记的数据,因此批量插入数据除了上述情况外,也会有合并桶和收缩表的情况.限于篇幅,以下伪代码仅为分裂桶和扩展表的情况:


2.6 算法优化
根据CUDA 的编程模型,将计算密集的任务交给GPU 线程网格处理,如核函数A、B、C、D,而CPU执行逻辑复杂的处理.在GPU 上的并行优化主要从以下几个方面考虑:
1)任务粒度划分.粒度越细,越能充分利用GPU大量的轻量级线程,算法的并行度越高.文中的创建算法中,桶间并行执行;查询算法中,各数据可并行查询;插入算法的预测部分中,对各数据的插入位置、各桶分裂情况的计算相互独立;在扩展表、分裂桶和插入数据算法中,段间、桶间和数据间的操作相互独立,蕴含大量并行操作,如For each tid…parallel do 与End for 之间的代码所示.
2)程序重构.GPU 的体系结构使其适于进行逻辑简单和数据并行的密集计算.文中合并多个循环以增强计算密度,隐藏访存延迟;重构分支以避免warp 内分支转移造成性能下降;将不同粒度的并行操作合并为一个核函数,以增强计算密度、减少核函数启动开销和数据传输开销.
计算每个桶是否分裂、分裂到的层次等,其迭代空间是所有的桶,因而可合并循环,如A7-A13 行;计算每个数据的插入位置与计算每个桶是否需要分裂,其任务粒度不同,故不能合并循环,但可以合并为一个核函数,以便将待插入数据eData 放入共享存储器重用,如算法A.计算桶是否分裂以及桶的层数,需要根据插入数据量与桶的剩余容量大小比较进行分支选择,文中重构该分支语句,将比较插入数据量与桶的剩余容量大小的逻辑值赋给记录桶是否分裂的数组needSMBucketNo,并将该数组作为桶层数的增量,如A8、A9 行.
3)数据的组织与存储访问.适合并行处理的数据结构、对GPU 上各存储器的充分利用以及规则的访问模式是存储优化的主要方法.
(1)数组能体现数据的并行性,适于GPU 上的密集计算.文中对哈希表结构、算法的输入数据eData、中 间 变 量(如insert_bucketNo、insert_bucket Num、needSMBucketNo、SMBucketLd 等)及输出结果qResult 都使用数组.为了全局存储器的合并访问,尽量将数据由AOS 转为SOA 结构[14],如桶内数据Data 和输入数据eData.文献[12]采用数组结构,但没有将AOS 转为SOA 结构.
(2)GPU 的多层次存储器可满足不同需求,共享存储器访问速度快但容量有限,为块内线程所共有,适合存放重用的局部性数据;全局存储器容量大但速度慢.高效利用片上局部存储器,可提高计算全局访存比CGMA[13],且采用规则访问的模式能显著改善程序的存储墙问题.如算法A 中,待插入数据eData 循环重用,宜用共享存储器存储.从上述算法可以看出,各数组的访存模式中,除insert_bucketNum 为随机访存,needSMSegNo 为跳步访存外,其他都是规则访问,使得全局存储器能合并访问,不产生局部访存冲突,而这两个数组的非规则访存,并不适宜进行循环重构和数组重构[15]来改变其访存模式.文献[12]未提到共享存储器的使用以及数据的规则访问.
4)使用cuda 提供的原子函数和并行算法库以提高代码的性能,如A5、A11、A12 和D1 行所示.
3 算法性能分析
文中从时间和空间两方面讨论gEHT 的性能.假设哈希表初始段数为M,每段的桶数为N,每个桶的容量为b,现有桶的数量为bucketNum,现有记录数为m,批处理的数据规模为batchNum.
3.1 时间开销
(1)查询时间开销.由queryEHTable 算法可知,其时间开销tq主要由计算搜索键对应散列值的时间tc、定位包含数据的桶以及在桶中检索目标数据的时间ts构成.由Q3 和Q4-Q8 行知,tc的复杂度为O(1),ts的复杂度为O(b),因此,查询时间tq的复杂度为O(b)+O(1),即为常数时间,且数据规模batch-Num 越大,越能充分利用GPU 的并行计算能力,从而获得更高的吞吐量.
(2)插入时间开销.由insertEHTable 算法可知,其总时间开销ti主要由预测部分和实际操作部分各子算法的执行时间tA、tB、tC和tD组成.
子算法A 循环执行,在最好情况下数据平均插入所有桶中,循环次数为batchNum/(bucketNum·b);在最坏情况下数据都插入同一个桶中,循环次数为batchNum/b,其循环内部的A2-A6、B7-B13 行并行执行,时间开销为O(1).算法B、C 中B2-C11、C1-C7行也是并行执行,其并行内部循环次数与预测部分的循环次数相同,循环内部的时间开销为O(1).算法D 中D1 行的时间代价为O(logrbatchNum)[14](r 为基数),D2-D4 行并行执行的时间开销为O(1).因此,总时间开销ti在最好情况下为O(batchNum/(bucketNum·b)+ logrbatchNum),在最坏情况下为O(batchNum/b+logrbatchNum)).
3.2 空间开销
文中从总空间开销和表扩展的开销两个方面来分析.
1)总空间开销.在GPU 上建立的哈希索引,如2.1 节所述,其显存的开销S 主要包括段表空间SsegList、桶表空间SbucketList和桶空间Sbucket.
若m 条记录占有桶数L(m)≈m/(bln 2)[16],则占有空间Sbucket=bL(m)≈m/ln2,桶表所需空间SbucketList为O(m(1+1/b)/b)[17],段表空间SsegList为O(m(1+1/b)/(Nb)),总空间S 为O(m/ln2+m(1+1/b)/b+m(1+1/b)/(Nb)).
2)表扩展的开销.假设分裂桶产生a 个桶段的扩展,0≤a≤M(M 为扩展前桶的段数,即段表长度),则段表增加M 项,桶表增加aN 项(N 为每段桶表的长度),共扩展M+aN 项.若无段表仅有桶表,则表项要增加MN 项.
(1)当数据倾斜,分裂的桶不多,即a≪M 时,双层表结构中表的扩展是线性的,而单层表结构中表的扩展是二次的,更加剧烈;
(2)当数据均匀分布,每段都有桶分裂,即a≈M时,双层结构表的扩展接近M+MN 项,单层结构表的扩展接近MN 项,而M≪MN,因此这种情况下,双层结构比单层结构多的表项也是有限的.
4 实验
实验在CPU+GPU 的异构平台上进行,CPU 为Intel Core i7-4770k,四核3.50 GHz 主频,GPU 为NVIDIA GeForce GTX 770,1536 CUDA Cores,每个核的频率为1.19 GHz,显存容量为4 GB.集成开发环境为VisioStudio2010,GPU 开发工具包为CUDA5.5.
文中设计两部分实验,分别从时间和空间两个方面检验gEHT 算法的有效性.测试数据集是随机产生的键值对构成的记录,每条记录平均长度为10B,每桶的记录容量b 为64 条,初始桶的总数M×N 为8×1024.
实验1对比Lea 算法、RSO 算法、GBLHT 算法和gEHT 算法在数据操作上的时间性能,其中Lea算法和RSO 算法均采用4 线程.
在包含90%的查询数据、6%的插入数据和4%的删除数据的负载下,4 种算法的吞吐量如图4所示.在4 线程算法中,锁冲突对Lea 算法带来的影响不大,其性能略高于RSO 算法.RSO 算法和gEHT算法的性能都会随着数据量的增加而有所波动,这是因为表收缩或扩展的时间损耗使其吞吐量下降.GBLHT 算法采用的线性哈希及前述优化问题,使其性能略低于gEHT 算法.总的来说,随着负载的增加,GBLHT 和gEHT 算法充分利用了GPU 的计算能力,显著地提高了吞吐量.
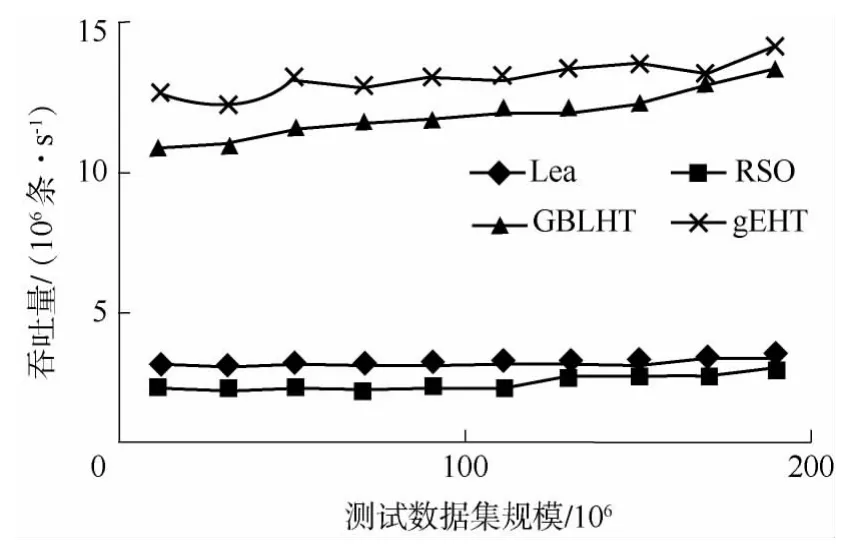
图4 不同负载下4 种算法的吞吐量Fig.4 Throughputs of four algorithms under different loads
实验2测试Fagin 的EH(Extendible Hashing)算法和gEHT 算法随着数据的插入表扩展所占用的空间情况.
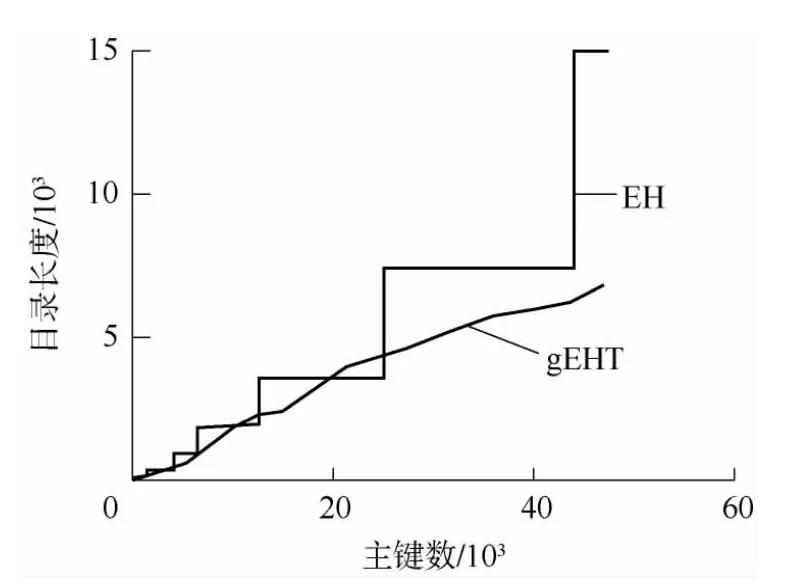
图5 表的大小与插入数据量的关系Fig.5 Directory size versus number of insertions
如图5所示,EH 算法在扩展表时,表长成倍增长,而gEHT 算法接近线性的增长,并且随着插入数据的增加,表空间扩展的速度放缓,甚至小于EH 算法的表空间大小.这是因为随着表空间的扩大,更多的段表项指向相同的桶表,越来越多的桶表被重用,以致尽管gEHT 算法比EH 算法多出段表,其总的表空间大小也不会超过EH 算法.
5 结论
可扩展哈希是一种具有最快检索速度的动态哈希,文中利用GPU 实现了可扩展哈希算法gEHT.首先利用GPU 的计算能力和CUDA 的编程模型,设计并实现了哈希表的创建、索引的更新以及数据检索的高并发算法;为了克服表长增长剧烈的缺陷,文中采用二级表结构,使得段表能重用部分桶表,大大地节省了表结构对空间的需求.最后,通过实验验证了gEHT 算法的性能.
显存空间十分有限,文中讨论的算法都是在待处理数据能够全部放在显存中的前提下进行处理的.大数据的特征使得批量处理的数据量更大,当其大于显存容量时,又应该如何在GPU 上使用哈希索引,是下一步要考虑的问题.
[1]Du H C,Ghanta S,Maly K J,et al.An efficient file structure for document retrieval in the automated office environment [J].IEEE Transactions on Knowledge and Data Engineering,1989,1(2):258-273.
[2]Fagin Ronald,Nievergelt Jurg,Pippenger Nicholas,et al.Extendible hashing:a fast access method for dynamic files[J].ACM Transactions on Database Systems,1979,4(3):315-344.
[3]Lirwzn W.linear hashing:a new tool for files and table addressing [C]//Proceedings of the 6th Conference on VLDB.Montreal:VLDB Endowment,1980:212-223.
[4]Ellis C S.Concurrency in linear hashing [J].ACM Transactions on Database Systems,1987,12(2):195-217.
[5]Hsu M,Yang W.Concurrent operations in extendible hashing[C]//Proceedings of the 12th Conference on VLDB.Kyoto:Morgan Kaufmann Publishers Inc,1986:241-247.
[6]Kumar Vijay.Concurrent operations on extendible hashing and its performance [J].Communications of the ACM,1990,33(6):681-694.
[7]Lea D.Hash table util.con current.concurrent hash map,revision 1.25,in JSR-166,the proposed Java Concurrency package [EB/OL].(2013-12-01)[2014-03-10].http://gee.cs.oswego.edu/cgi-bin/viewcvs.cgi/jsr166/src/main/java/util/concurrent/.
[8]Gao H,Groote J F,Hesselink W H.Almost wait-free resizable hashtables[C]//Proceedings of the 18th International Parallel and Distributed Processing Symposium.Santa Fe:IEEE,2004:681-689.
[9]Shalev Ori,Shavit Nir.Split-ordered lists:lock-free extensiblehash tables (poster paper) [J].Journal of the ACM,2006,53(3):379-405.
[10]Zhang D,Larson P-A.LHlf:lock-free linear hashing[C]//Proceedings of the 17th ACM SIGPLAN Symposium on Principles&Practice of Parallel Programming.New York:ACM,2012:307-308.
[11]陈虎,唐海浩,廖江苗,等.面向批量插入优化的并行存储引擎MTPower [J].计算机学报,2010,33(8):1492-1499.Chen Hu,Tang Hai-hao,Liao Jiang-miao,et al.MTPower:a parallel database storage engine for batch insertion[J].Chinese Journal of Computers,2010,33(8):1492-1499.
[12]黄玉龙,奚建清,张平健,等.GBLHT:一种GPU 加速的批量插入线性哈希表[J].华南理工大学学报:自然科学版,2012,40(4):49-56.Huang Yu-long,Xi Jian-qing,Zhang Ping-jian,et al.GBLHT:a GPU-accelerated linear Hash table with batch insertion [J].Journal of South China University of Technology:Natural Science Edition,2012,40(4):49-56.
[13]NVIDIA Corporation.NVIDIA CUDA programming guide version 4.2[EB/OL].(2012-04-16)[2014-03-10].http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#ixzz3I5UFqJtq.
[14]Bell N,Hoberock J.Thrust:a productivity-oriented library for CUDA[EB/OL].(2012-12-10)[2014-03-10].http://cloud.github.com/downloads/thrust/thrust/Thrust% 3A%20A% 20Productivity-Oriented% 20Library% 20for%20CUDA.pdf.
[15]Leung S-T.Array restructuring for cache locality [R].Seattle:Department of Computer Science and Engineering,University of Washington,1996.
[16]Enbody R J,Du H C.Dynamic hashing schemes [J].ACM Computing Surveys,1988,20(2):85-113.
[17]Gonnct G H.算法和数据结构手册[M].张子让,周晓东,译,北京:人民邮电出版社,1988.
