一种基于遗传算法的特征选择和权重确定方法
2015-12-04
(淮北师范大学 计算机科学与技术学院,安徽 淮北 235000)
特征选择,是从一个初始特征集中挑选出一些特征组成最优特征子集,依据这些子集构建的分类器能够使某种评估标准达到最优,具有较高的预测精度.特征选择可以提高构建的分类或回归模型的泛化能力,降低特征维度的同时还提高了计算效率,所以特征选择方法的研究成为目前模式识别研究领域中的一个热点问题.
本文首先讨论了目前常用的一些特征选择方法,分析了这些方法存在的一些问题,随后针对这些问题,本文提出了一种新的基于遗传算法的特征权重确定方法.最后我们通过实验验证了所提算法的效果.
1 特征选择的相关工作
特征选择可以看作是一个搜索寻优的过程.1997年,M.Dash 提出了特征选择的一般框架,清楚的描述了这个过程,如图1所示[1].从图1中可以看到,特征选择过程由四步组成:子集产生、子集评价、终止和验证方法.第一步为产生子集,即由一部分特征组成的集合,接着对这个特征集进行评估,直到停止的条件满足,选择的过程才结束.如果没有条件未满足,则重复前面的工作,直到完成.目前学者们的研究集中于搜索策略和评价标准两方面.
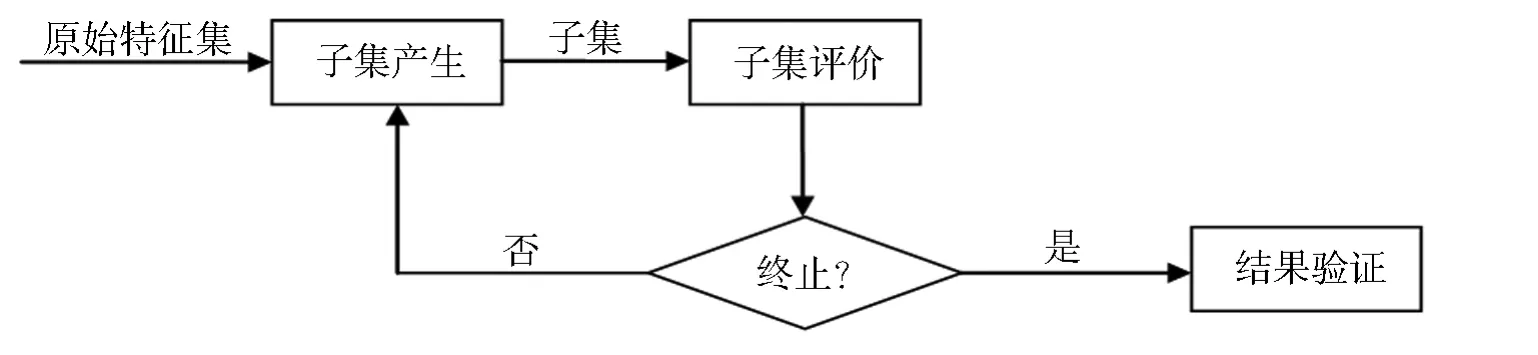
图1 一般特征选择框架图
特征选择的任务,实际上是将特征的维数从M 压缩至对于描述类别是最有效的m 维,这样,所有的可能的特征集的组合数为
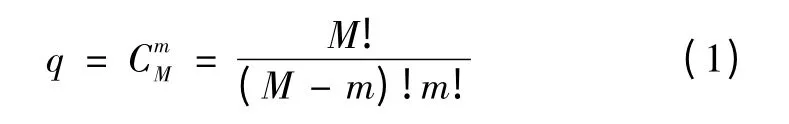
选择哪些特征组成最优特征子集需要一个标准进行评价.这些标准可以分为以下五类:信息相关的度量、距离相关的度量、依赖性相关的度量、一致性相关的度量和分类错误相关的度量等[1].前四类方法根据数据内在的特性来对所选择的特征子集进行评价,独立于特定的算法,常用于过滤模式(filter method)的方法中;分类错误率度量标准则经常与特定的学习算法联系,常用于封装模式(wrapper method)的方法中[2].不同的评价标准会得到不同的特征子集.另外,使用穷举法,对所有的可能的特征组合进行评估,计算量会非常大,也是不实际的.所以,寻找一种理想的搜索算法变得非常必要.根据能否搜索到最优组合,搜索算法可以分为最优搜索算法、次优搜索算法.到目前为止,唯一可以得到最优结果的搜索方法就是分支界定法[3].虽然分支界定法在效率上比穷举法高,但是对于高维度特征空间,计算量还是太大而难以实现.单独最优特征组合是最简单的搜索算法,但是,即使各特征统计独立,组合起来不一定最优.后来出现的搜索算法有顺序前进法 (Sequential Forward Selection,SFS)[4]和顺序后退法 (Sequential Backward Selection,SBS)[5].SFS 没有考虑入选特征之间的相关性,而且不能剔除已入选而品质变低劣的特征.而SBS 则无法入选已被剔除而品质变优良的特征,且由于其是一种自上而下的方法,在高维空间运算,计算量比SFS 大.由于特征选择实际上是一个组合优化问题,因此也可以使用解决优化问题的方法来解决特征选择问题,比如基于启发式搜索策略的禁忌搜索(Tabu Search,TS)算法[6],基于随机搜索策略的粒子群算法(Particle Swarm Optimization,PSO)[7]、模拟退火算法(Simulated Annealing)[6]和遗传算法 (genetic algorithm,GA)[8]等.这些方法都是近似方法,在求解时间和质量上都较为理想,被广泛应用.
根据分类器与评价函数的关系,特征选择的模式目前可以分为过滤式、封装式以及混合(Hybird)模式[2].基于过滤式的方法独立于分类器,其方法是使用一定的函数,对于候选的部分特征进行分类能力的评估,同时用某种策略从中选择最好的一些特征.这种方法实现简单,效率高,但是由于独立于分类器,容易和分类器产生偏差.基于封装式的方法则将分类器封装于其中,直接以分类的正确率作为特征选择的目标,分类正确率最高的那一部分特征将被作为最后的特征集被选中.在这种方法中,分类学习算法就封装在特征选择过程里面,分类算法的识别正确率直接成为了特征子集的评价准则,所以其精度一般较过滤模式方法高,但是每次对特征子集的评价都要计算分类器的精度,所以其效率不高.目前一些学者结合这两类方法的优点,把两者结合起来形成了一类混合模式的方法,也取得了较好的效果[9].
遗传算法由生物进化的过程启发而产生.生物从最简单的低等生物发展出复杂的高级生物,期间经历了漫长的进化,通过遗传和变异等,按照“物竞天择,适者生存”的规则演变而来.遗传算法对求解问题的模型,没有特别的要求,是一种非数值优化方法,所以适应性比较广泛.其次,在搜索时,遗传算法采用群体搜索策略,从一个群体进化到另外一个群体,提高了效率,且不易陷入局部最优.这些优点,让遗传算法被广泛应用于特征选择中.
2 基于遗传算法的特征选择和权重确定方法
遗传算法是一种基于封装模式的特征选择方法.这种方法把分类器封装于其中,直接以分类器的精度作为评价特征子集的选择标准.由于每次需要计算分类器精度,所以效率不是很高.另外,也没有考虑到特征的权重,事实上每个特征对于分类的贡献不是同等的.所以,我们提出了一种基于遗传算法的特征选择和权重确定方法.这种方法的过程如下图2所示.

图2 基于遗传算法特征选择和权重确定方法示意图
这种方法主要分为以下两步进行.
第一步:由传统的GA 算法初选出候选特征集.
这一步主要是从原始特征集中选出比较好的一些初始特征集,用于后续的精选和权重确定.使用二进制位编码的方法创建一个二进制位串代表一个染色体C.一个特征fi使用一个二进制位,也就是一个基因位gi来表示,则有下面一个关于fi和gi函数关系:
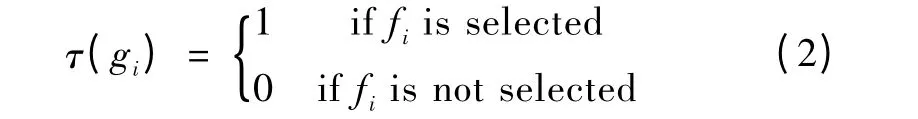
从式2 中,我们可以看到基因位和特征一一对应,有多少特征就需要有多少基因位来表示.当基因取值为1 时,表明特征被选中,反之则反.第一步流程图如图3所示.
第二步:由可以确定权重的GA 算法在第一阶段初选出候选特征集的基础上,继续精简特征集,同时也求得最终入选的特征对应的权重.可以确定特征权重的GA 与传统GA 方法的流程大致相同,我们介绍与GA 中不同的几个地方,主要是个体编码方式、解码方式和交叉遗传操作.
(1)个体编码方式
如表1所示,在GA 中,我们用x位二进制位表示一个特征的权重,这样,如果由第一阶段GA 选出来的候选特征集的位数为n位,则特征权重位的位数为nx,即整个染色体的长度.
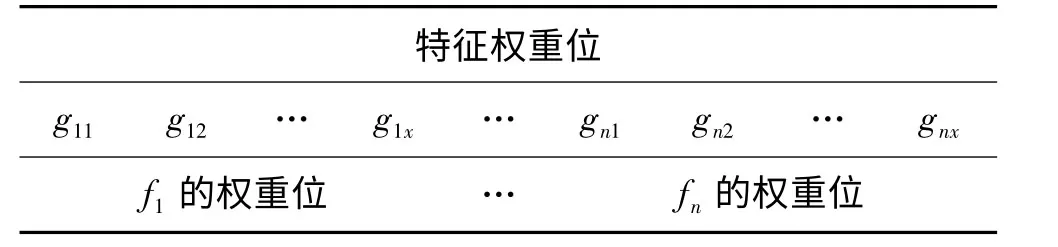
表1 在确定权重的GA 算法染色体中个体的二进制位编码
(2)染色体解码
因为确定权重GA 算法中染色体的编码与传统GA中不同,相应的解码方式也不同,先将每一个特征fi对应的二进制基因位串转化为一个十进制整数qi,然后,就可以求得每个特征的权重:
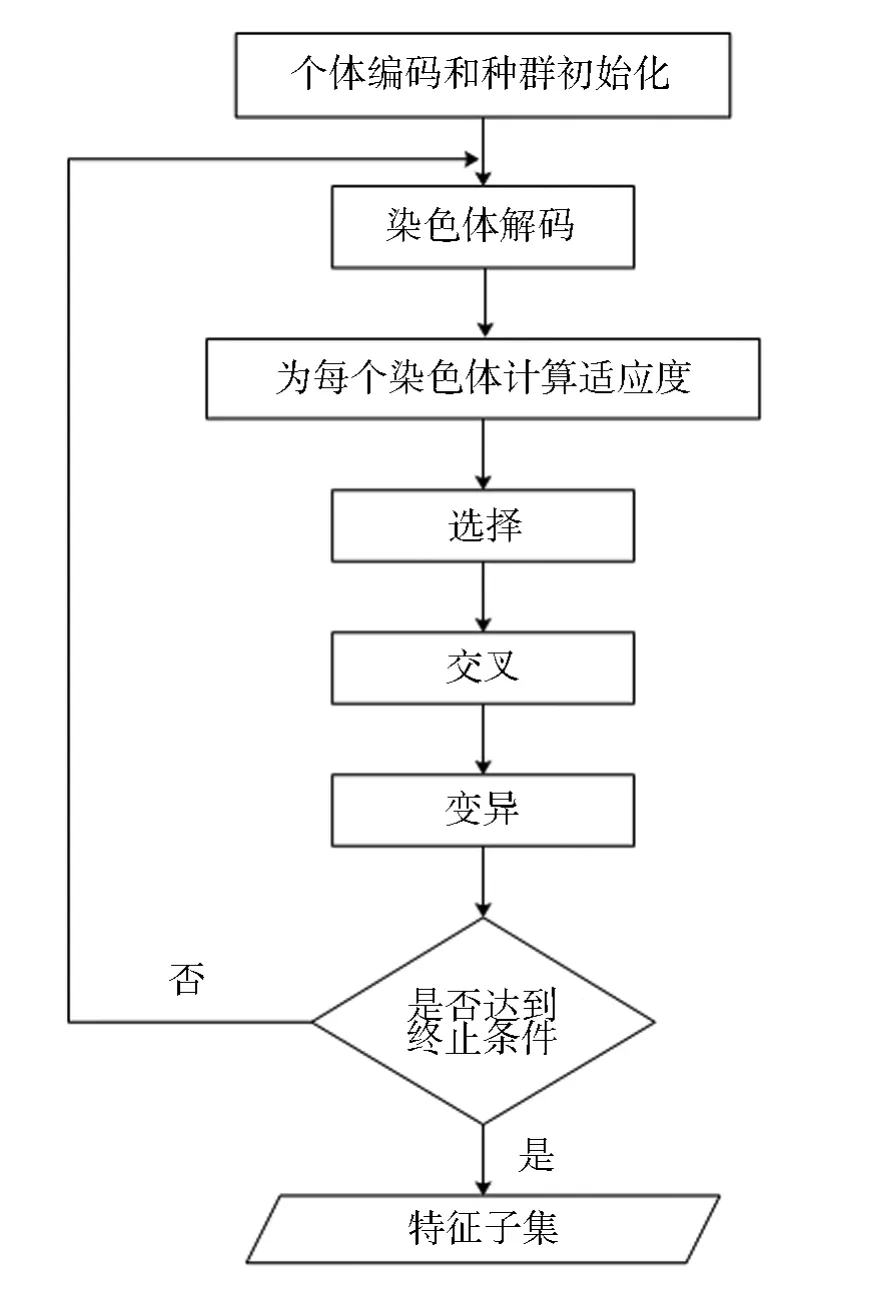
图3 应用GA 进行候选特征子集选择流程图
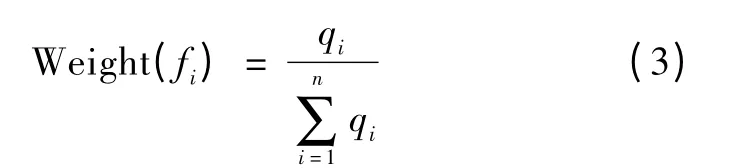
(3)交叉遗传操作
由于在第二步的GA 中,基因的编码方式与传统GA 不同,我们使用了x位表示一个权重位,为了在进行交叉操作后,尽量不会因为交叉使得一个特征的权重被严重改变,我们在进行交叉操作时,交叉点选择为n的整数位处,也是随机选择,但是不处于这一点时就重新再选择,直到满足这个条件位置为止,这与在GA 中采用的传统的方法那样完全随机选择交叉点不同.
通过上述的两个步骤,我们就可以得到一个精选的特征子集及其对应的权重.
3 实验及结果
为了验证所提算法的效果,开展了以下一系列的实验.
3.1 数据来源和实验方案
实验的数据来源于南佛罗里达大学(University of South Florida)的DDSM (Digital Database for Screening Mammography,DDSM)[10].我们构建了一个基于钼靶乳腺X 线摄片和多特征最近邻算法[11]的乳腺肿块计算机辅助诊断系统.在训练阶段,先建立一个大规模参考库,主要由含有正常组织的感兴趣区域(Region of Interest,ROI)和含有肿块的ROI 两类区域组成.随后使用分割算法对参考库中的所有ROI 进行可疑肿块轮廓提取.当分割完成后,在分割结果上应用特征提取和计算方法计算所有ROI的特征集.这样就得到了参考ROI 特征数据库.在整个特征数据库上,使用特征选择、权重确定算法及分类决策算法,并引入已经确诊的金标准(Truth File)对上述结果进行判定.分割算法我们使用的是一种基于动态规划法的方法[11].在诊断阶段,使用基于图像内容检索 (Computer Aided Diagnose using Content-based Image Retrieval,CBIR CAD)方法,针对放射科医师任意感兴趣的区域去进行检测,CAD 系统除了返回待查询的区域和肿块的相似度分数和/或肿块是良性还是恶性的分类分数,还有最相似的K 幅参考感兴趣区域图像.
3.2 参数设置
(1)种群规模和个体初始化时阈值
种群的大小用来控制种群的规模.显然,种群规模越大,相当于增大了搜索的群体以及种群多样性,找到理想解的可能性就越大,但是计算量肯定会增大.本文中种群大小设置为40.
(2)进化代数
进化代数用来控制遗传算法的结束时间.一般来说,代数越多,越可能找到理想解,但搜索时间会增加.在本文中,这个值设置为300.
(3)交叉概率
交叉概率用于控制参与交叉的个体数量,这个值不宜过小,也不宜过大.过小的话,则会使得算法收敛速度过快而陷入局部最优,过大则会使大量优秀个体遭到破坏,而使算法不收敛.在本文中设置为0.7.
(4)变异概率
变异概率用来控制参与变异的个体数量.它的影响主要是在进化的后期,和交叉概率的作用类似.在本文中,设置为0.001.
3.3 实验结果
为了测试和评估所提出的新特征和新的特征选择方法的效果,我们对7种方法进行了实验.这些方法中,有使用所有特征且权重都为1的AF-KNN 方法和GA-KNN 方法以及本文方法.实验结果如表2所示,表中K值为KNN 算法所选出的与待测ROI 最相似的参考ROI的数目.在本文实验中,是在遗传算法的染色体中设定相应的基因位,一起训练出来的.95%置信区间是本文实验结果要求达到的95%可信度所跨度的范围.受试者操作特性曲线 (Receiver Operating Characteristic Curve,ROC 曲线)[12]是广泛采用的评价CAD 系统性能的工具,有别于单阈值分析的方法,通过设置很多阈值进行决策,可以获取到含有多对灵敏度和假阳性率值组成相应的二元有序点对集合,再分别以假阳性率、灵敏度值为横、纵坐标,既可以通过二维坐标系,在二维空间中描述这些点,连接这些点而成的曲线就是ROC 曲线.Az为ROC 曲线下包络的面积,是描述受试者操作特性曲线最重要的指标,该值越大,表明系统性能越好.

表2 各种方法的实验结果
从表2中可以发现由传统的GA 方法选出了34个特征作为候选特征子集,对63 维特征进行了初步降维,然后本文方法在这个基础上最终选出了24个特征,并确定了特征相应的权重.在临床中,一般认为Az值:0.5~0.7之间时诊断价值较低,在0.7~0.9之间时诊断价值中等,而在0.9 以上时诊断价值较高.本文的方法,全特征法以及GA 特征选择方法得到的Az 下的面 积 分 别为:0.8782 ± 0.0078,0.8632 ±0.0081和0.8478 ±0.0088,从数据上看,进行GA 特征选择后,入选特征为34个,特征维数明显降低,而CAD 性能也明显提高,说明特征选择对分类器性能的提高有很重要的作用.而且用本文所提出的方法特征数进一步降为24个,CAD的性能却比前面的两种方法有更大的提升,说明本文所提方法行之有效.
4 结论
特征选择是模式识别中非常关键的一步,挑选出最优特征子集的同时还能降低特征维度,提高计算效率.很多算法在进行特征选择的时候没有考虑到特征的权重,简单的将特征的分类效力同等对待,这是不合理的.本文提出了一种两步选择特征的方案,先用遗传算法初选出一个特征子集,在此基础上再用能够确定特征的遗传算法进一步精选特征,并确定特征的权重.实验结果显示,我们的算法取得了较好效果.
[1]Dash M,Liu H.Feature selection for classification[J].Intelligent data analysis,1997,1 (3):131-156.
[2]郑雅敏.基于遗传算法的特征选择方法的改进研究[D].重庆:重庆大学通信工程学院,2008.
[3]刘亦韬,胡维华.一种处理Top-k 逆向查询的分支界定算法[J].杭州电子科技大学学报,2014 (6):76-79.
[4]Liu B,Li S,Wang Y,et al.Predicting the protein SUMO modification sites based on Properties Sequential Forward Selection (PSFS)[J].Biochemical and biophysical research communications,2007,358 (1):136-139.
[5]Xue B,Zhang M,Browne W N.Particle swarm optimisation for feature selection in classification:Novel initialisation and updating mechanisms[J].Applied Soft Computing,2014 (18):261-276.
[6]许鹏飞,苗启广,李伟生.基于函数复杂度的自适应模拟退火和禁忌搜索新算法[J].电子学报,2012,40(6):1218-1222.
[7]张丹,韩胜菊,李建,等.基于改进粒子群算法的BP算法的研究[J].计算机仿真,2011,28 (2):147-150.
[8]Handbook of genetic algorithms[M].New York:Van Nostrand Reinhold,1991:20-65.
[9]Fischer U,Hermann K,Baum F.Digital mammography:current state and future aspects[J].European radiology,2006,16 (1):38-44.
[10]Keller J M,Gray M R,Givens J A.A fuzzy k-nearest neighbor algorithm[J].IEEE Transactions on Systems,Man and Cybernetics,1985 (4):580-585.
[11]Song E,Xu S,Xu X,et al.Hybrid segmentation of mass in mammograms using template matching and dynamic programming[J].Academic radiology,2010,17 (11):1414-1424.
[12]Eltonsy N H,Tourassi G D,Elmaghraby A S.A concentric morphology model for the detection of masses in mammography[J].IEEE Transactions on Medical Imaging,2007,26 (6):880-889.
