基于多分类的地震信息跟踪方法
2015-11-27康建红庞晶源宁宝坤张晨侠
康建红,庞晶源,宁宝坤,张晨侠
(1.吉林省地震局,长春 130117;2.中国地震应急搜救中心,北京 100049)
0 引言
Web2.0时代,现实生活中的突发事件,比如地震,一经报道,短时间内便会引起民众们的关注,越来越多的民众选择通过网络来发表自己的态度、观点、意见等,形成海量的突发事件网络舆情信息。及时跟踪相关突发事件的舆情信息,对于掌控网络舆情发展态势,提高政府决策的民主化与科学化、维护社会稳定具有十分重要的作用。
网络论坛(BBS)自产生以来就一直深受用户的关注和喜爱。由于BBS在信息传播速度、广度和便捷性等方面的优势,加上其庞大的用户数量,BBS对突发事件的介入和参与能力越来越强,是网络舆情信息传播的重要途径和集聚地。
为此,本文以地震事件为例,对面向BBS 的突发事件网络舆情信息跟踪方法进行研究。但在实验中我们发现,以下2个方面的原因导致跟踪系统的性能不是很理想:首先,BBS信息作为一种用户产生内容(User Generated Content,UGC),其中含有较多的噪音,而且长度一般比较短,属于一种短文本,数据稀疏严重,为此,本文提出构建论坛帖子的上下文,并在上下文内基于潜在语义分析(Latent Semantic Analysis,LSA)建立帖子模型;其次,由于话题动态演化特性的存在,话题跟踪系统的漏报率比较高,为此,本文提出建立多焦点的话题模型;最后,实现了基于多分类的信息跟踪方法。实验结果表明,本文提出的方法较好地改善了突发事件信息跟踪的性能。
1 相关工作介绍
突发事件信息跟踪是基于话题检测与跟踪研究中的话题跟踪方法实现。论坛话题跟踪已经引起了国内外研究者的广泛关注[1-2],其中的关键技术有帖子表示模型、话题(突发事件)表示模型以及话题方法[3]。
话题跟踪研究中,最为广泛使用的话题表示模型是向量空间模型,最初由Allan 等人[4]引入到话题跟踪研究中,此后又出现了很多改进方法[5];另外还有基于语言模型[6]、基于LDA[7]的话题建模方法。近期针对话题模型的研究则更多地融入话题结构特征[8-9],从而在真正意义上进入新闻话题形态学习的研究阶段。
实现话题跟踪最简单的方法是基于传统信息检索技术的构建查询的方法[10-11]。该方法简单易行,是研究者们常用的方法。另外,不少研究者采用基于文本分类算法的话题跟踪算法,其中常用的分类算法有KNN[12]、Rocchio[13]以及SVM[14]等。
动态演化特性是话题的重要特性,即随着时间的流逝,话题所关注的焦点会发生漂移,这是影响话题检测与跟踪性能的重要因素之一。目前对该方面的研究开展了一些,但是收效不大。本论文从论坛文本特点和话题的动态演化特性分析入手,分别提出了基于上下文和潜在语义分析的论坛帖子建模方法以及基于多焦点的突发事件建模方法,在此基础上实现了多分类的突发事件信息跟踪系统。实验结果表明,该方法取得了不错的效果。
2 突发事件信息跟踪基本模型
在地震信息跟踪的基本模型中,论坛帖子采用向量空间模型表示,而突发事件采用中心向量表示。其中包括2部分关键内容:最初的中心向量的建立方法和话题与帖子之间的相似度计算。同时,在信息跟踪过程中引入伪反馈技术。基本模型具体描述如下:
1)对已知的与地震相关信息进行预处理操作,包括分词,去停用词;
2)建立表示突发事件的中心向量:首先,利用公式(1)计算给定的相关信息中的每个词k的TFIDF值wk;然后采用TOP-N 的方法抽取突发事件的特征项,而相应的TFIDF 值作为它们的权值,从而建立突发事件的向量表示模型
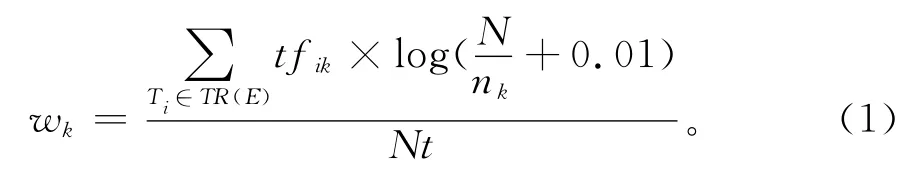
式中:Ti(1≤i≤Nt)为已知的与突发事件E相关的帖子,Nt为已知的与突发事件相关的帖子个数,TR(E)为突发事件E的训练语料集合,tfik为词k在帖子Ti中的词频,N为训练语料中包含帖子的个数,Nk为训练语料中包含词k的帖子的个数。
3)使用Cosine函数(公式(2))计算突发事件E与待跟踪的帖子Ti之间的相似度Cosine(Ti,E),通过相似度阈值θ和相似度之间的比较做出待跟踪的帖子是否和突发事件相关的判断。具体来讲:如果Cosine(Ti,E)>θ,那么帖子和突发事件相关,否则不相关。
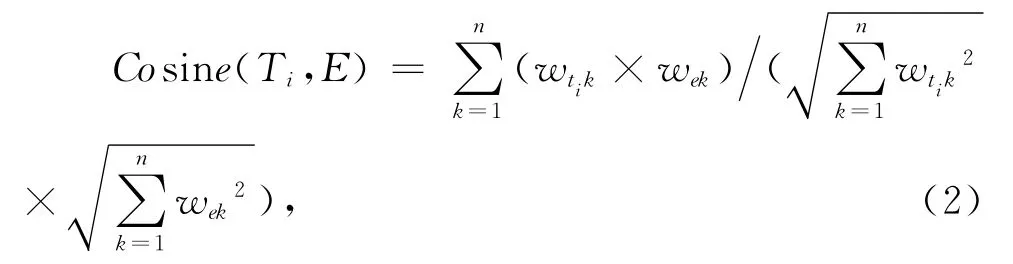
式中:wtik和wek分别表示特征项在论坛帖子Ti和突发事件E中的权值,基于TFIDF 公式计算得到。
4)当Sim(Ti,E)>θ时,判定Sim(Ti,E)是否大于更新阈值μ:如果Sim(Ti,E)>μ,基于伪反馈的思想,将Ti作为起初给定的与突发事件相关的训练帖子,即假设训练语料中突发事件有Nt个相关帖子,那么此时突发事件的相关帖子为Nt+1,利用现在的Nt+1个相关帖子重新统计突发事件的查询向量;否则不更新突发事件的中心向量。
3 基于上下文和潜在语义分析的帖子建模方法
本文提出采用上下文和潜在语义分析相结合的方法建立帖子模型,该方法分为以下3个步骤:
1)预处理。在对帖子建模之前,首先对帖子及其回复进行预处理操作,主要包括中文分词、去除停用词、去除表情符号等。
2)建立帖子上下文。传统的话题跟踪研究是面向规范的新闻长文本的,但是论坛中的帖子长短不一,通常比较短。对一个帖子的回复通常是与帖子围绕同一个话题展开的,为此,本文提出建立帖子的上下文,即一条帖子和对该贴的回复组成了该帖子的上下文。
3)潜在语义分析。LSA 是一种常用的向量降维模型,即把高维向量空间模型表示的文档映射到低维的潜在语义空间中。本文在建立了帖子上下文的基础上,采用LSA 建立帖子的向量空间模型,过程如下:
①建立词汇—语义空间的共现矩阵,即Am×n矩阵。经过预处理,我们共得到14089个上下文,其中含有60147个不同词汇,即m=60147,n=14089,得到A60147×14089矩阵。同时aij采用经典的TFIDF公式来计算:
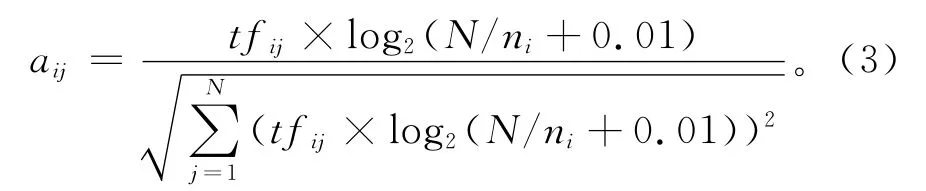
式中:tfij是第i个词在第j条帖子中出现的频度,N是帖子集合中的帖子数,ni是含有第i个词汇的帖子条数。
②对A进行奇异值分解,本文实验中采用SVDLIBC工具进行分解,它是由麻省理工大学开发的,从而得到共现矩阵A60147×14089的近似矩阵Ak,并同时得到词汇向量Uk和帖子向量Vk。
4 基于多焦点的突发事件建模及其应用
4.1 基于多焦点的突发事件建模方法
动态演化特性是话题的重要特性之一,该特性是指随着事态的发展,话题所关注的焦点内容往往会发生迁移和分化,后续的相关内容甚至会与最初的内容大相径庭。比如对于地震事件,最初与话题相关的帖子一般是对地震的时间、地点及现场等情况的简短介绍,接下来便是关于救援、伤亡、成因、影响、灾后重建等内容的帖子。
话题的动态演化特性给话题跟踪带来了一定的困难。通过分析实际突发事件可以发现,虽然话题存在着动态演化,但在一般情况下,与某个突发事件相关的内容大致都是围绕几个焦点展开的,而且每个焦点都有一些特定的核心词汇。为此,本文提出了多焦点的话题建模思想。
鉴于以上的分析,我们基于多焦点的话题建模方法如下:
1)从网络论坛中收集大规模关于地震的帖子;
2)将上述的帖子进行聚类,目的是为了获取地震事件里的所有焦点,假设聚类的个数为Num,即生成焦点为Focusi(1≤i≤Num);
3)统计每个焦点Focusi(1≤i≤Num)里面出现的高频词;
4)为每一个焦点Focusi(1≤i≤Num)建立一个向量空间模型,其中,特征项为焦点里出现的高频词,而权值采用TFIDF公式进行计算。
4.2 基于多分类的突发事件信息跟踪方法
基于多分类信息跟踪方法的思想是指将突然事件动态演化过程中出现的多个焦点看成是多个类,而各个类会在跟踪过程中动态更新。该方法的过程如下:
1)对已知的与地震相关的信息进行预处理操作,包括分词,去停用词;
2)首先按照基础模型中的方法建立突发事件的向量空间模型,开始系统会建立一个模型,随着跟踪过程的进行,会根据跟踪的焦点情况建立多个模型;
3)使用公式(4)计算待跟踪的帖子Ti与突发事件的相似度
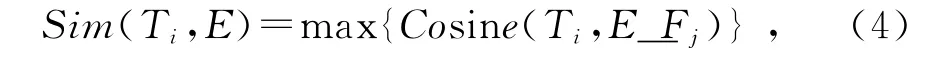
式中:E_Fj表示当前时刻已经建立的突发事件的焦点;
4)如果Sim(Ti,E)大于预设的相似度阈值θ,则此帖子与突发事件相关,否则不相关;
5)设定一个是否建立新焦点的阈值ω(ω>θ),如果Sim(Ti,E)>ω>θ,则将Ti加入到取得最高相似度的焦点中;如果ω>Sim(Ti,E)>θ,则新建立一个焦点。
5 实验设置与结果分析
5.1 语料与评测依据
由于目前尚无公认的用于网络舆情信息跟踪的论坛语料,为了评测本文提出的算法的有效性,我们从各大论坛手动收集了123 709条论坛帖子,其中有75 231条帖子是关于“汶川地震”的,其余的帖子都是和地震无关的。在实验中,将语料分为2部分,一部分作为训练,另一部分作为测试。训练语料包含86 570条论坛帖子,其中50 476条帖子是关于汶川地震的,其余的语料作为测试语料。
实验中采用了话题检测与跟踪评测会议的评价标准,采用漏报率、误报率和归一化检测开销作为评价标准。如果用表1表示跟踪结果,则系统的漏报率Pmiss和误报率Pfallout及归一化检测开销(CDet)Norm可以分别由公式(5)、(6)、(7)定义:
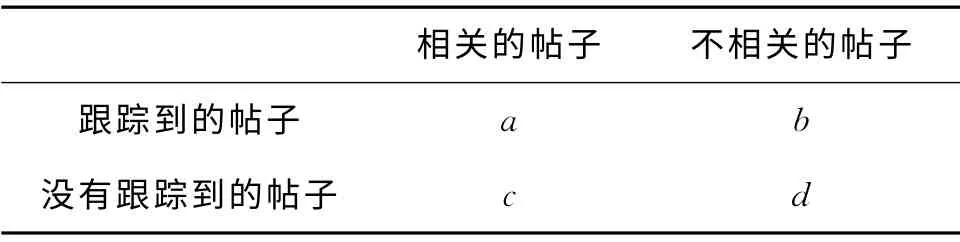
表1 评测标准含义
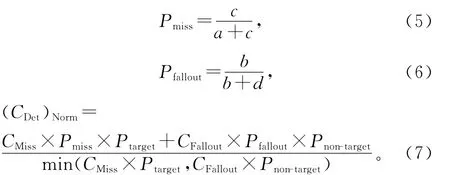
式中:CMiss和CFallout分别表示漏报和误报的开销,Ptarget是目标话题的先验概率,表示关于某个话题的微博出现的可能性,而Pnon-target=1-Ptarget。CMiss、CFallout及Ptarget的值通常都是根据具体情况预先设定,TDT 评测中他们通常取值1.0,0.1,0.02,本文实验中也采用此值。显然,漏报率、误报率越小,归一化检测开销(CDet)Norm越小,话题检测系统的性能就越好。
5.2 实验与结果分析
5.2.1 突发事件信息跟踪基本模型实验与结果分析
本组实验主要是验证本文采用的突发事件信息跟踪基本模型(Baseline)的性能,首先在训练语料上进行了训练,得到了最佳性能时的参数;其次在测试语料上进行了测试。
1)基本模型的训练
实验1:不采用伪反馈技术,即表示突发事件的中心向量不会随着跟踪过程的进行而动态更新。通过在训练语料上进行实验,当相似度阈值θ=0.19时,Baseline 系统的性能最好,其中漏报率=0.396 8,误 报 率=0.192 0,归 一 化 检 测 开 销=1.337 6。
实验2:采用了伪反馈技术,即当跟踪到一个相似度非常高的网络舆情时,我们将其用于更新突发事件中心向量。通过实验,当相似度阈值θ=0.18,更新阈值μ=0.32时,Baseline系统的性能最好,其中,漏报率=0.367 2,误报率=0.187 6,归一化检测开销=1.286 4。
从上述2组实验结果看出,通过引入伪反馈技术,可以随着跟踪过程的进行动态更新中心向量,从而很好地应对话题的动态演化特性。为此,我们后续所有的实验中都采用了伪反馈技术,并且都将相似度阈值设置为0.18,更新阈值设置为0.32。
2)基本模型的测试
我们在相似度阈值θ=0.18,更新阈值μ=0.32时,对基本模型在测试语料上进行了实验,此时的实验结果为:漏报率=0.367 0,误报率=0.180 9,归一化检测开销=1.253 4。
5.2.2 改进方法的实验与结果分析
本组实验主要对本文提出的方法进行了验证,实验设置见表2。
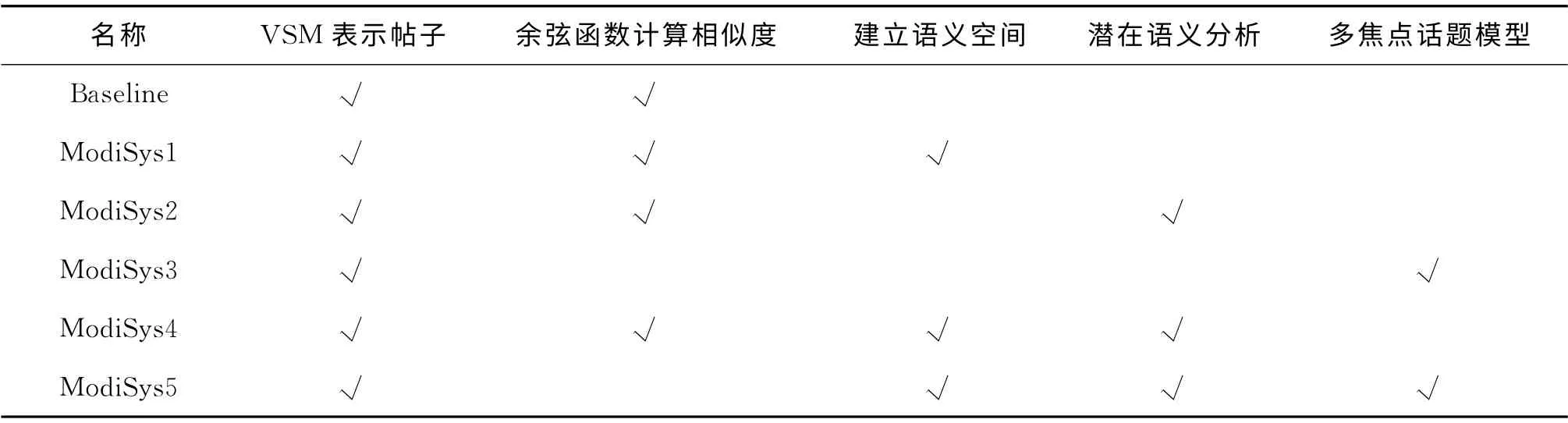
表2 实验设置表
可以看出,我们共设置了6 组实验,其中,ModiSys1至ModiSys5 是基于我们提出的不同方法的不同组合而形成的系统。各个系统的评测结果见表3。

表3 实验结果
可以看出,本文提出的方法对系统性能有着不同程度的改善,证明了本文提出方法的有效性。仔细对比实验结果可以发现,改进的信息跟踪系统的漏报率和误报率有了不同程度的降低,这说明我们提出的改进方法可以更好地发现有关突发事件的网络舆情信息,漏报的概率越来越低[15]。
6 结论及下一步工作
论坛是民众们发表网络舆情信息的重要网络媒介之一,是许多单位和个人进行舆情监控的重要场所[16]。突发事件发生后,为了及时有效地发现论坛中关于该事件的网络舆情信息,本文对面向论坛的突发事件信息跟踪方法进行了研究,从论坛帖子表示模型和突发事件表示模型2个方面展开研究。首先提出了基于上下文和潜在语义分析的帖子表示模型;其次多焦点的突然事件表示模型;最终实现了基于多焦点突发事件表示模型的信息跟踪方法。结合对话题动态演化特性的分析,该方法基于多分类思想实现跟踪,即将一个突发事件演化过程中出现的各个焦点看成是一个分类,而且这些分类会在跟踪过程中动态变化。
实验结果表明,潜在语义分析可以较好地应对论坛草根性带来的用词多样性问题,而多焦点的话题模型可以在一定程度上弥补话题的动态演化特性对跟踪系统性能的影响,二者结合起来取得了不错的实验效果。
目前研究中所使用的评测语料是手工收集的,下一步工作拟研制面向主题的网络爬虫技术,通过爬虫程序自动下载突发事件网络舆情信息,在更大规模的语料上验证本文提出方法的有效性。
[1] 刘晓亮.基于维基百科的军事舆情论坛话题追踪方法[J].计算机应用,2012,32(11):3026-3029.
[2] 席耀一,林琛,李弼程,等.基于语义相似度的论坛话题追系统[J].计算机应用,2011,31(1):93-96.
[3] Kamaldeep Kaur,Vishal Gupta.A survey of Topic Tracking Techniques[J].International Journal of Advanced Research in Computer Science and Software Engineering,2012,5(2):383-392.
[4] Allan J,Papka R,Lavrenko V.On-Line new event detection and tracking[C].Proc of the SIGIR'98,1998:37-45.
[5] Paraskevas Tsantarliotis,Evaggelia Pitoura.Topic Detection Using a Critical Term Graph on News-Related Tweets[C].Proc of the EDBT/ICDT 2015Joint Conference,2015:446-453.
[6] Damiano Spina,Julio Gonzalo,Enrique Amigo.Learning Similarity Functions fro Topic Detection in Online Reputation Monitoring[C].Proc of SIGIR'14,Gold Coast,Queensland Australia,2014:150-167.
[7] Tengfei Liu,Nevin L Zhang,Peixian Chen.Hierarchical Latent Tree Analysis for Topic Detection[C].Proc of ECML PKDD 2014,Part II,LNCS 8725,2014:256-272.
[8] Wenxu Long,Jixun Gao,Zhengtao Yu,et al.Online Chinese-Vietnamese Bilingual Topic Detection Based on RCRP Algorithm with Event Elements[C].Proc of C.Zong et al.(Eds.):NLPCC 2014,CCIS 496,2014:422-429.
[9] Feng A,Allan J.Finding and linking incidents in news[J].Proc of the Conf on Information and Knowledge Management.Lisbon,2007:821-830.
[10] 王会珍,朱靖波,季铎,等.基于反馈学习自适应的中文话题追踪[J].中文信息学报,2006,20(3):92-98.
[11] 焦健,瞿有利.知网的话题更新与跟踪算法研究[J].北京交通大学学报,2009,33(5):132-136.
[12] 张辉,周敬民,王亮,等.基于三维文档向量的自适应话题追踪模型[J].中文信息学报,2010,24(5):70-76.
[13] Mrs Lavanya S,Kavipriya R.A Survey on Event Detection in News Streams[J].International Journal of Computer Science Trends and Technology,2014,5(2):33-35.
[14] 王强.基于SVM 的突发事件新闻话题跟踪方法研究[D].山西:山西大学,2009.
[15] 王海鹰,欧阳春,孙刚.地震应急期关键应急处置业务的时序特征[J].华北地震科学,2014,32(1):59-64.
[16] 叶佳宁,何霆.地震信息微信自动发布系统的设计与实现[J].华北地震科学,2014,32(4):23-28.
