基于MapReduce与两层相关性聚类的实体解析方法
2015-11-02王宁,黄敏
王 宁,黄 敏
(北京交通大学计算机与信息技术学院,北京100044)
基于MapReduce与两层相关性聚类的实体解析方法
王 宁,黄 敏
(北京交通大学计算机与信息技术学院,北京100044)
两层相关性聚类算法由于引入公共邻居,在解析的正确性及抗噪声能力方面性能较好。但该算法分两层执行,在时间效率上不具优势。为此,提出将该算法在MapReduce框架下实现,利用分布式计算提高其执行效率。通过设计辅助文件减少内存消耗以及中间数据的输出,给出分布式环境下的块更新规则,并改写第二层的调整块算法,将需要实时更新的数据统一计算后,根据更为显著的关联特征进行处理。实验结果表明,与TT算法和DTT算法相比,该方法不仅能保证解析的准确性,而且在时间效率上也有大幅提高。
相关性聚类;MapReduce模型;实体解析;大数据;数据集成;分布式计算
1 概述
实体解析[1]是指对现实世界中同一实体的不同表现形式进行识别、连接和分组,它在数据库管理、数据集成、机器学习中都有广泛的应用。大数据时代的到来,使得人们去挖掘数据的潜在价值。
大数据具有数据量大、数据更新速度快、数据源多样和数据存在噪声等特点[2]。其中,数据噪声会造成部分数据关联和依赖的假象。相关性聚类是实体解析的一种基本方法,文献[3]基于对数据噪声的处理提出了一种两层相关性聚类算法,用于提高实体解析的质量。
两层相关性聚类算法分为预分块和调整块两层。与传统的相关性聚类算法相比,该算法在准确率和召回率上占有一定的优势,然而由于分两层实现,它在时间效率上不如传统算法。MapReduce是一种编程模型,它被广泛用于处理大规模的数据集。然而在MapReduce框架下进行数据分析和操作时,数据节点之间不能通信,即数据在处理过程中不能实时更新也无法实现共享,因此需要对两层相关性聚类算法进行改造,将需要实时更新的数据统一计算后根据明显的关联特征进行处理,以适应分布式架构。为提高大数据环境下两层相关性聚类算法的执行效率,本文提出将该算法在MapReduce模型下实现,通过分布式计算提高其效率。本文的主要工作如下:在MapReduce模型下实现两层相关性聚类算法,并结合MapReduce模型特点,设计适合分布式环境和聚类方案的数据格式及辅助文件。设计分布式环境下的邻居相似度计算方法,设计新的邻居数据结构,以减少中间数据量和内存消耗,提高计算效率。提出新的关联规则并重新设计调整块算法,使其在不低于原方法准确率、召回率的基础上实现分布式处理,并从理论上证明该方法的收敛性。
2 相关工作
2.1 两层相关性聚类算法
相关性聚类[4]是实体解析的一种基本方法,因其是NP-hard问题,很多近似算法被提出,以pivot[5]和vote[6]最为典型。两层相关性聚类方法[3]由两层算法实现:上层算法基于邻居关系对数据进行粗糙、允许重叠的预分块处理;下层算法通过引入核的概念,精确定义了记录与块之间的关联程度,以便准确地判断记录归属,进而提高相关性聚类的准确度。该方法由于引入邻居关系,抗噪声能力明显提高。
公共邻居和核:对于记录i与记录j,其公共邻居为CN(i,j)=N(i)∩N(j),若i和j构成的边形成一个分类,则其公共邻居CN(i,j)为该分类的核。
邻居相似度:两层相关性聚类算法使用余弦相似度来计算邻居相似度:

预分块算法:每次选取邻居相似度最大的记录对,将该记录对的公共邻居的邻居作为一个类,并将该记录对的公共邻居作为该类的核。
记录与块的关联程度:如果记录i属于某一个块,那么它应该与该块的核有很强的关联,Ri(c)表示记录i与块c的关联程度,其中:

调整块算法:预分块得到的结果中含有许多重叠部分,调整块算法依赖于记录序列,对于某一个记录,将它归并到与其有最大关联程度的块中。
2.2 MapReduce框架以及实体解析
Hadoop[7]分布式系统架构包括HDFS分布式文件系统和MapReduce编程模型两部分。HDFS拥有对数据读写的高吞吐率,因此适合构建大数据集上的应用。MapReduce是一个用于大数据量计算的编程模型,其应用程序最基本的组成部分包括一个Mapper类和一个Reducer类。
在大数据环境中,实体解析是一项计算方法多样、计算量繁重的工作。采用MapReduce框架提高其计算效率成为目前较流行的研究方向。Kolb等人基于MapReduce构建了一个用于大型数据集的dedoop实体解析系统[8-9],通过几种先进的负载平衡策略来提高系统性能[10]。文献[11]提出一种基于MapReduce的三阶段相似集合连接方案,有效地分割数据和平衡工作量,并减少跨记录的数据复制。文献[12]提出了一种新颖的实体解析方法用于删除冗余数据,该方法基于分块技术实现。
3 基于MapReduce的两层相关性聚类算法
3.1 系统框架
图1给出基于MapReduce的两层相关性聚类方法的框架,分数据准备(统计邻居和计算邻居相似度)、预分块、调整块(关联程度的计算和记录的添加与删除)3层。第2层预分块仍保留之前的分块方案,本文的工作主要针对数据准备阶段和调整块阶段实现。
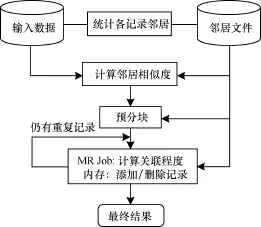
图1 基于MapReduce的两层相关性聚类方法框架
修改后的调整块为两层迭代算法,需要证明其收敛性。在算法执行过程中,每次迭代对每条记录,将它从与其关联程度低的块中删除,因此,只需证明每个记录最终有且仅有一个块与其相关联,即记录最终仅出现一次,便可证明该算法是收敛的。定理及其证明保证了算法的收敛性。
定理 对于给定的记录集合I={I1,I2,…,Ii},I上的α个分块集合C={c1,c2,…,cα},I中每条记录在C上重复划分次数的集合N={n_I1,m,n_I2,m,…,n_ Ii,m},其中,n_It,m表示记录It(1≤t≤i)经过m次迭代后被重复划分的次数。当迭代m(1≤m≤α)次后,N={1,1,…,1},即每条记录仅属于唯一一个分块。
证明:对于α个分块,每个记录最多被重复划分α次。在本文算法中,每次迭代至少将一条被重复划分的记录从与其关联程度低的块中删除,即对∀n¯It,m∈N(1≤n_It,m≤α),当n_It,m>1时,n_It,m+1=n_It,m-β(1≤β≤α)。每经过一次迭代,被重复划分的次数至少会减少一次。因此,∃m(1≤m≤α),迭代m次后,N={1,1,…,1}。
3.2 邻居文件及邻居相似度
3.2.1 邻居文件
每一阶段均需要使用邻居信息,为了减少map到reduce的中间数据量,将邻居信息作为一个独立的文件,供各阶段使用。获取邻居文件的输入数据为仅包含正边的无向图,该无向图由文献[4]中的方法得到。
对于一个仅包含正边的无向图,以其边作为输入,以记录id作为key值,统计每一个记录的邻居,获取邻居文件的过程如图2所示。对于每一条边序列,在map阶段交换记录id形成中间数据,在reduce阶段,以每一个id值形成分组,统计邻居,形成邻居文件。邻居文件的输出格式设计如下:
(记录id索引/记录邻居1/记录邻居2/……)

图2 获取邻居文件的MapReduce过程
3.2.2 邻居相似度计算
本文计算有正边相连的2个记录的邻居相似度。对于每条边,通过记录id索引查找邻居文件获得邻居,计算邻居相似度,算法过程如下:
算法1 邻居相似度计算


邻居相似度的计算采用MapReduce模型,主节点将邻居文件上传到缓存供各从节点下载使用,从缓存获得邻居文件的部分在map类的setup函数中实现(1行~3行),之后在map函数中通过id索引查询邻居文件,获得邻居信息并计算邻居相似度(5行~8行),再通过reduce函数输出(9行~10行)。
3.3 调整块
原有的调整块算法每将一个节点归于某一个分块或从某一个分块中删除,将会及时更新其他记录与所在块的关联程度。然而,基于MapReduce的算法无法实时对数据进行更新,因此采用迭代的方式对数据进行处理,并尽可能地在一次迭代中处理更多的数据,以减少迭代次数。因此,本文定义了最大关联程度、最小关联程度、最大关联块和最小关联块来帮助判断记录的归属(定义1、定义2),并定义了相关运算来操作块中记录的添加和删除(定义3),同时为运算提供判断标准(定义4)。
定义1 对于记录i以及与其相关联的块bK,表示i与bK的关联程度。记录i的最大关联程度定义为i与其所关联块的关联程度的最大值,记作maχ_c(i);记录i的最小关联程度定义为i与其所关联块的关联程度的最小值,记作m in_c(i)。即:定义2 对于记录i,记录i的最小关联块定义为与i有最小关联程度的块,记作min_b(i);记录i的最大关联块定义为与i有最大关联程度的块,记作maχ_b(i)。

定义3 设分块C由非核记录集C1和核的记录集C2组成,记作C={C1,C2},其中C1={I1,I2,…,Ii},C2={Ii+1,Ii+2,…,IK}。定义非核记录It(1≤t≤i)对C的依附为C⊕It,C对记录In(1≤n≤K)的排斥为C⊗In,其中:

定义4 给定记录集合I={I1,I2,…,Ii}和α个分块集合C={c1,c2,…,cα},A表示与记录进行依附操作形成的新块,B表示与记录进行排斥操作形成的新块。对某条记录It(1≤t≤i)及其所有关联的块cm(1≤m≤α),分布式环境下的块更新规则定义如下:
(1)当maχ_c(It)≠min_c(It)时,若min_c(It)>0,则A=maχ_b{It}⊕It,B=min_b{It}⊗It;若若则
(2)当maχ_c(It)=min_c(It) 时,若则
3.3.1 分布式坏境下的调整块算法
调整块分MR阶段和内存阶段两部分执行。首先将预分块P表示成<key,value>对的形式代入MR阶段计算。调整块算法的总循环如下:
算法2 调整块算法总循环

对于预分块阶段产生的粗糙的、有重叠的分块P,每一次循环都将计算记录与所在块的关联程度,并根据关联规则输出处理文件(7行),在内存中进行添加和删除(8行),当每个记录均只出现一次时,循环结束,此时可得到无重叠的分块结果(9行)。
MR阶段采用MapReduce模型实现,具体算法如下:
算法3 调整块算法MR阶段

Map函数通过邻居信息和块信息计算记录与所在块的关联程度(5行~6行),并将结果以(记录id,块id/记录与块的关联程度)的形式输出(7行~8行);reduce函数用于输出需处理的记录信息,map函数的输出数据会将相同key值(记录id)的数据合并,因此,首先找到每一个id的最大关联程度、最小关联程度、最大关联块、最小关联块及关联程度小于0的记录和所在块的信息,存于待处理列表中(10行),再根据关联规则进行判断(11行),最后从待处理列表中获得每一个记录的当前重复次数(12行),再将信息整理后输出(13行)。
3.3.2 调整块算法的后处理
改进后的调整块算法很好地解决了MR中不能实时更新数据的问题。但每一个记录被重复划分的次数不同,其迭代停止的顺序也不同,这会导致许多单一记录的产生。为了减少单一记录形成的分块,对分块后的结果进行再处理:首先,计算结果中单一记录与其他各块的关联程度;然后,获得与该单一记录有最大关联程度的分块,若最大关联程度大于0,则将该记录加入到对应的分块中。
4 实验与评估
4.1 实验环境和实验数据
实验部署的分布式环境由3个节点构成,其中2个节点(1台为主节点)为内存16 GB,CPU 2.93 GHz,硬盘1 TB的Dell服务器,另外1个节点为内存4 GB,CPU 2.73 GHz,硬盘1 TB的Dell服务器。实验所用的算法是在hadoop2.20.0和jdk1.7.0_06环境下实现的。
由于没有合适规模的真实数据集,将cora数据集扩大相应的倍数,并增加数据噪声形成实验数据集。Cora数据集包含对112篇不同文章的1 295个引用,共1 295×(1 295-1)/2=837 865个记录对,扩大数据集后,记录对的数量已达到107数量级。
4.2 实验评估标准
准确率、召回率和F-值常用于评估聚类算法,在非分布式环境下,两层相关性聚类算法在这3个值上均优于传统算法。为适应分布式环境,对调整块算法进行了改进,因此需保证改进后的算法在时间效率提高的基础上,准确率、召回率和F值均不低于原方法的评估结果。
4.3 实验结果与分析
4.3.1 有效性
为方便比较,称原有的二层相关性聚类算法为Two-Tiered(TT),分布式环境下的改进算法为DTwo-Tiered(DTT),经过后处理的算法为DP-Tw o-Tiered(DPTT)。从表1可以看出,对于规模不大的cora数据集,DTT与TT相比,召回率比较高,准确率偏低,综合后的F值基本持平。

表1 DTT与TT在Cora数据集上的聚类效果对比
随着数据量增加,DTT算法在这3个评价指标上出现了变化:准确率较高,基本保持在0.95以上,召回率却在0.7徘徊,F值基本稳定在0.8左右,如图3所示。对结果中出现的单一记录进行再处理后(DPTT),在保持高的准确率的基础上,召回率和F值都有所提高,如图4所示。

图3 DTT的准确率、召回率和F值随数据量变化的情况

图4 DTT与DPTT的结果有效性比较
4.3.2 时间效率
MapReduce模型的最大优势在于它能够处理大数据量的运算。与TT算法相比,DTT算法尽管采取迭代的方式进行处理,但每迭代一次,计算量便会降低,且Hadoop自带的文件系统具有较高的文件读写速度,在查询时间上占有优势。
图5给出了调整块阶段运行的总时间。随数据量的增加,运行总时间呈现比较平缓的增长趋势,但随Hadoop节点数的增加,总时间在大幅降低。

图5 数据量与运行时间的关系
图6 给出了平均运行时间与迭代次数及Hadoop结点数的关系,其中,迭代次数对应图5中的数据量增长。随数据量的增加,记录间的关联关系变复杂,记录被重复划分的次数便会增加,因此,程序运行的迭代次数也会增加,见图6。但各节点数下,每个job的平均运行时间基本保持稳定或有小幅增长,而对于最后2个同为108次迭代次数的5×107和6×107数据量,尽管后者的计算量远多于前者,但平均运行时间的差值却不大,说明本文算法能很好地适应分布式环境。

图6 平均运行时间与迭代次数及HadooP节点数的关系
5 结束语
在大数据坏境下,实体解析的算法不仅要求解析结果的正确性,同时也要确保较低的时间复杂度。本文基于MapReduce编程模型实现两层相关性聚类算法,通过将调整块算法改为两层迭代模型,使其能适应分布式环境,在保证解析质量的基础上,时间效率也大幅提高。今后考虑将预分块算法在分布式框架上实现,以减少对内存的依赖。预分块算法的修改涉及到数据的划分和实时更新问题。此外,将针对调整块迭代算法中的数据特点,调整关联规则以减少算法的迭代次数,同时,设计适合调整块的负载平衡策略,进一步减少调整块的运行时间。
[1] Lise G,Machanavajjhala A.Entity Resolution for Big Data[C]//Proceedings of the 19th ACM SIGKDD International Conference on Know ledge Discovery and Data Mining.New York,USA:ACM Press,2013:214-222.
[2] 维克托·迈尔·舍恩伯格,肯尼思·库克耶.大数据时代[M].盛阳燕,周 涛,译.杭州:浙江人民出版社,2012.
[3] 王 宁,李 杰.大数据环境下用于实体解析的两层相关性聚类算法[J].计算机研究与发展,2014,51(9):2108-2116.
[4] Bansal N,Blum A,Chaw la S.Correlation Clustering[J].Machine Learning,2004,56(1-3):89-113.
[5] Ailon N,Charikar M,Newman A.Aggregating Inconsistent Information:Ranking and Clustering[J]. Journal of the ACM,2008,55(5):23-28.
[6] Elsner M,Chamiak E.You Talking to M e?A Corpus and Algorithm for Conversation Disentanglement[C]// Proceedings of ACL'08.New York,USA:ACM Press,2008:834-842.
[7] Hadoop[EB/OL].(2014-08-18).http://hadoop. apache.org/.
[8] Kolb L,Andreas T,Erhard R.Paralell Entity Resolution with Dedoop[J].Datanbank-Spectum,2013,13(1):23-32.
[9] Kolb L,Andreas T,Erhard R.Dedoop:Efficient Deduplication with Hadoop[J].Proceedings of the VLDB Endowment,2012,5(12):1878-1881.
[10] Kolb L,Andreas T,Erhard R.Load Balancing for MapReduce-based Entity Resolution[C]//Proceedings of ACM ICDE'12.New York,USA:ACM Press,2012:618-629.
[11] Vernica E,Carey M J,Li Chen.Efficient Parallel Setsimilarity Joins Using MapReduce[C]//Proceedings of 2010 ACM SIGMOD International Conference on Management of Data.New York,USA:ACM Press,2010:156-165.
[12] George P.Eliminating the Redundancy in Blockingbased Entity Resolution Methods[C]//Proceedings of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries.New York,USA:ACM Press,2011:325-335.
编辑 索书志
Entity Resolution Method Based on MapReduce and Two-tiered Correlation Clustering
WANG Ning,HUANG Min
(School of Computer and Inform ation Technology,Beijing Jiaotong University,Beijing 100044,China)
Correlation clustering is a basic method for entity resolution.By introducing the concept of common neighborhood into the correlation clustering problem,two-tiered correlation clustering method is superior to traditional approaches in term of accuracy and noise immunity.However,this method is not time efficient because of its two-tiered architecture.In order to im prove its efficiency in big data environment,this paper proposes a two-tiered correlation clustering method based on Map Reduce.Some auxiliary files are designed to decrease memory consumption and intermediate data output.New correlation rules for ad justing blocks are proposed and adjustment algorithm in bottom tier is redesigned so that block adjustment can be processed according to the most salient correlation features.Experimental results show that the resolution method is not only accurate but also time efficient for big data.
correlation clustering;MapReducemodel;entity resolution;big data;data integration;distributed Computing
10.3969/j.issn.1000-3428.2015.09.014
王 宁,黄 敏.基于MapReduce与两层相关性聚类的实体解析方法[J].计算机工程,2015,41(9):80-84,91.
英文引用格式:W ang Ning,Huang M in.Entity Resolution Method Based on MapReduce and Two-tiered Correlation Clustering[J].Computer Engineering,2015,41(9):80-84,91.
1000-3428(2015)09-0080-05
A
TP391
国家自然科学基金资助项目(61370060);江苏省自然科学基金资助项目(BK 2011454)。
王 宁(1967-),女,副教授、博士,主研方向:Web数据集成,大数据管理,数据挖掘;黄 敏,硕士研究生。
2014-09-02
2014-11-04 E-m ail:nw ang@bjut.edu.cn
