基于组合权重的犹豫模糊语言决策方法
2015-11-02彭新东宋娟萍
彭新东,杨 勇,宋娟萍,蒋 芸
(西北师范大学计算机科学与工程学院,兰州730070)
基于组合权重的犹豫模糊语言决策方法
彭新东,杨 勇,宋娟萍,蒋 芸
(西北师范大学计算机科学与工程学院,兰州730070)
犹豫模糊语言决策方法中的权重需要人为给出,具有较大主观性,导致决策结果不稳定。针对该问题,提出一种组合权重,用于解决犹豫模糊语言多属性决策中权重未知的问题,并克服因主观权重带来的不确定性。通过最大偏差方法分别获得犹豫模糊语言集中的犹豫模糊集与语言集的客观权重,对这2种客观权重进行组合并归一化,从而得到组合权重,并给出基于组合权重的逼近理想解排序法的决策方法与犹豫模糊语言组合加权几何算子决策方法。实例结果表明,2种方法的决策结果相同,验证了组合权重的可行性。
犹豫模糊语言集;组合权重;最大偏差;客观权重;几何算子
1 概述
1965年Zadeh[1]基于现实生活的不确定性,提出了模糊集。文献[2]将模糊集应用到文本分类。2010年Torra[3]提出了犹豫模糊集,其允许成员函数有一系列在[0,1]的值。文献[4]定义了犹豫模糊集上的运算法则及一些聚集算子,并将其应用到多属性决策。2012年Rodriguez等[5]将犹豫模糊集与
语言集结合,提出了犹豫模糊语言集,解决了语言评价体系的单一评价问题。2014年Lin等[6]基于犹豫模糊语言集,着重于模糊值的犹豫,给出了相应的聚集算子,并将其应用到企业资源计划(Enterprise Resource Planning,ERP)系统的决策。文献[7]讨论了犹豫模糊语言集的距离与相似性度量。文献[8]基于犹豫模糊语言集,提出了相应的聚集算子,但是侧重于语言变量的犹豫。以上研究内容给出了专家的主观权重,一定程度给决策结果带来很大的不确定性。
实际上,由于社会的复杂性与现有知识的匮乏性,基于主观权重的决策带来了很大的随机性,这时候需要摒弃主观的权重赋予,通过寻求数据内部关系来确定客观权重,进而保证决策的公平性。
以上述内容为基础,本文研究一种犹豫模糊语言集模型,提出组合权重,给出基于犹豫模糊语言集的逼近理想解排序(Technique for Order Preference by Sim ilarity to an Ideal Solution,TOPSIS)方法,并将其与犹豫模糊语言组合加权几何算子的结果进行对比。
2 预备知识
为了叙述方便,给出了犹豫模糊集[3]、犹豫模糊语言集[6]相关理论。
设S={si|i=0,1,…,g}是一个有限的有序集合,且含有奇数个语言值,si代表一个可能的语言值。例如一个含有7个语言值的语言集为:S={S0=极低,S1=很低,S2=低,S3=一般,S4=高,S5=很高,S6=极高}。通常情况,语言集需满足以下4个条件[9-10]:
(1)有序性:si>sj,当且仅当i>j;
(2)负算子:Neg(si)=sj,其中,j=g-i;
(3)最大算子:max{si>sj}=si,如果i≥j;
(4)最小算子:m in{si>sj}=sj,如果i≥j。
设语言值sθ1,sθ2的距离测度为[11]:

定义1 设X为非空集合,在X上的犹豫模糊集E定义为:
E={<χ,hE(χ)>|χ∈X}
其中,hE(χ)为[0,1]中一些不同数组成的集合,表示χ∈X的可能隶属度。为了方便,称h=hE(χ)为一个犹豫模糊元素[4]。
对个数不同的2个犹豫模糊元素,通过让个数少的犹豫模糊元素增加其最大元素的值使两者元素个数相同[12],故其定义了犹豫模糊元素h1,h2的欧氏距离:

定义2 设X为非空集合,在X上的犹豫模糊语言集A定义为:

其中,hA(χ)为[0,1]中一些不同数组成的集合,表示对于语言集sθ(χ),χ∈X的可能隶属度。为了方便,a=<sθ,h>为一个犹豫模糊语言元素。
定义3 对任意的犹豫模糊语言元素a=<sθ,,其为a的得分函数,对2个犹豫模糊语言元素a1,a2,如果S(a1)>S(a2),则a1>a2;如果S(a1)=S(a2),则a1=a2。
定义4 对3个犹豫模糊语言元素a=<sθ,h>,a1=<sθ1,h1>,a2=<sθ2,h2>,则:
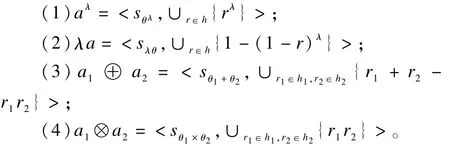
3 2种犹豫模糊语言决策方法
3.1 客观权重与组合权重计算方法
3.1.1 客观权重计算方法
文献[13]为了解决多属性决策权重未知问题,提出了最大偏差法来确定属性的客观权重。对一个多属性决策问题,一个属性的偏差值越大应该分配一个更大的权重。
对属性χi∈X,方案Ai对其他所有方案的偏差定义如下:

其中,i=1,2,…,m;j=1,2,…,n;d(sij,sKj)代表相应犹豫模糊元素或语言值之间的距离,如式(1)与式(2)。
对于属性χi∈X,所有方案对其他方案的偏差值为:

所有属性对所有方案的总偏差值为:

其中,wj代表属性χi∈X的权重。
基于以上分析,首先可以构造一个非线性模型使所有偏差值最大来选择权重wj,定义如下:

然后构造一个拉格朗日函数如下:

同时对L(λ,wj)中的λ,wj求偏导:

求得权重wj如下:

最后将其归一化如下:

3.1.2 组合权重计算方法
假设犹豫模糊语言集中的语言集的客观权重为wl=(wl1,wl2,…,wln),其中,wln代表第n个属性下的语言值权重。犹豫模糊集客观权重为wh=(wh1,wh2,…,whn),其中,whn代表第n个属性下的犹豫模糊元素权重。通过式(3)改变相应的距离d(sij,sKj),也即语言值距离式(1)与犹豫模糊元素距离式(2),可以分别获得相应的客观权重wl,wh。
组合权重ωc=(ωc1,ωc2,…,ωcn)定义如下:

3.2 基于TOPSIS的决策方法
设A={A1,A2,…,Am}为方案集,C={C1,C2,…,Cn}为属性集,相应属性对应的权重信息完全未知。S={s0,s1,…,sg}为语言集。假设矩阵D=(dij)m×n是一个犹豫模糊语言集,其中,dij=<sθij,hij>(i=1,2,…,m;j=1,2,…,n)是犹豫模糊语言元素的形式。
TOPSIS方法的基本观点是选择一个离正理想方案最近且离负理想方案最远的方案,因此,需定义正理想方案、负理想方案和分离测度。
在犹豫模糊语言环境中,犹豫模糊语言正理想方案(Positive Ideal Solution,PIS)定义为A+,犹豫模糊语言负理想方案(Negative Ideal Solution,NIS)定义为A-,具体定义如下:

其中,χj代表第j个属性下进行取值的标号;sθij代表第i个方案中第j个属性下的语言值;λ表示犹豫模糊元素的个数;代表排序好的第i个方案中第j个属性下的犹豫模糊元素里第λ个值;分别表示第n个属性下犹豫模糊元素中第l个元素的最大值与最小值。
对每个基于PIS A+与NIS A-方案的分离测度d+i,d-i,根据语言值距离与犹豫模糊元素距离的乘法效应,即两者共同决定了犹豫模糊语言的距离,定义如下:

其中,wj表示第j个属性权重;θij表示第i个方案第j个属性下的语言值下标;θ+j,θ-j分别表示语言值下标的最大值与最小值;g表示犹豫模糊语言集中的语言值的个数。
对于犹豫模糊语言方案Ai的相关亲近系数:

其中,0≤Ci≤1,i=1,2,…,m。
易知当方案Ai与PIS A+越接近,同时与NIS A-越疏离,则Ci越接近于1,也即该方案越好。故可通过相关亲近系数Ci来确定方案的排序,进而从中选择一个最佳的方案。
算法1 基于TOPSIS的决策算法
SteP1 根据专家给出的决策信息构造犹豫模糊语言决策矩阵D=(dij)m×n。
SteP2 根据式(3)计算犹豫模糊集与语言集的客观权重,经式(4)计算犹豫模糊语言集组合权重。
SteP3 通过式(5)与式(6)得到相应犹豫模糊语言PIS A+与NIS A-。
SteP4 经式(7)与式(8)计算每个方案Ai的分离测度d+i,d-i。
SteP5 用式(9)计算每个方案Ai的相关亲近系数Ci。
SteP6 按照相关亲近系数Ci的大小对方案Ai进行大小排序,Ci越大,表示方案Ai越好。
3.3 犹豫模糊语言组合加权几何算子
本节使用犹豫模糊语言组合加权几何(Hesitant Fuzzy Linguistic Combined W eighted Geom etric,HFLCWG)算子进行相应的决策,定义如下:

算法2 基于HFLCWG算子的决策算法
SteP1 根据专家给出的决策信息D=(dij)m×n,通过式(10)给出HFLCWG算子:

SteP2 通过式(11)计算所有方案Ai的得分函数S(di):

SteP3 对所有的得分函数S(di)进行排序,选择值最大的作为最佳方案。
4 应用实例
经过市场调查,某投行计划投资4个互联网公司:网游公司(A1)、浏览器公司(A2)、搜索引擎公司(A3)、在线视频公司(A4)。基于市场信息,该投行对每家公司进行了3个方面的评价,也即评价指标为:长期收益(C1),投资风险(C2),投资难度(C3)。但相应的权重信息未知,用犹豫模糊语言信息评估4个互联网公司在3个评价指标下的语言集为S={S0:极低,S1:很低,S2:低,S3:一般,S4:高,S5:很高,S6:极高},根据投行专家评估获得的犹豫模糊语言决策矩阵D(dij)4×3如图1所示。

图1 犹豫模糊语言决策矩阵
算法1的实例详解如下:
SteP1 构造的犹豫模糊语言决策矩阵如图1所示。
SteP2 根据式(3)计算犹豫模糊集客观权重向量为wl=(0.434 8,0.391 3,0.173 9)T与语言集客观权重向量为wh=(0.391 0,0.260 7,0.348 3)T,经式(4)计算出犹豫模糊语言集组合权重向量为ωc=(0.511 2,0.306 7,0.182 1)T。
SteP3 通过式(5)与式(6)得到相应犹豫模糊语言PIS A+与NIS A-为:A-={<S1,{0.2,0.4,0.5}>,<S2,{0.3,0.4,

0.4 }>,<S3,{0.3,0.4,0.4}>}
SteP4 经式(7)与式(8)计算每个方案Ai的分离测度:

SteP5 用式(9)计算每个方案Ai的相关亲近系数Ci:
C1=0.240 7,C2=0,C3=1,C4=0.155 0
SteP6 根据相关亲近系数排序得,A3≻A1≻A4≻A2,其中,≻表示优于,故最优方案为A3。
算法2的实例详解如下:
SteP1 通过式(10)整合每个方案Ai(i=1,2,3,4)在所有属性Cj(j=1,2,3)下的评估值di(i=1,2,3,4):

SteP2 通过式(11)计算所有方案Ai(i=1,2,3,4)的得分函数S(di)(i=1,2,3,4):

SteP3 根据得分函数排序得,A3≻A4≻A1≻A2,故最优方案为A3。
综合算法1与算法2的结果分析可得,易知最优方案都为A3,即在权重未知情况下,基于组合权重的犹豫模糊语言决策方法是可行的,也即本文设计的组合权重保证了决策的公平性,减少了因决策者经验与知识的有限而事先给出的权重带来的随机性,使得决策结果更客观。
5 结束语
本文通过最大偏差法分别获得犹豫模糊语言集中的语言集与犹豫模糊集的客观权重,将两者的客观权重联合并归一化,提出组合权重,将其应用到TOPSIS决策方法中,并与犹豫模糊语言几何组合加权算子方法进行对比,结果验证了该方法的有效性。今后研究如何将其拓展到其他犹豫模糊语言集模型中,从而进一步改进该方法。
[1] Zadeh L A.Fuzzy Sets[J].Information and Control,1965,8(3):338-356.
[2] 张玉芳,娄 娟,李智星,等.基于模糊关系的文本分类方法[J].计算机工程,2011,37(16):149-151.
[3] Torra V.Hesitant Fuzzy Sets[J].International Journal of Intelligent System s,2010,25(6):529-539.
[4] Xia Meimei,Xu Zeshui.Hesitant Fuzzy Information Aggregation in Decision Making[J].International Journal of Approximate Reasoning,2011,52(3):395-407.
[5] Rodriguez R,M artinez L,Herrera F.Hesitant Fuzzy Linguistic Term Sets for Decision M aking[J].IEEE Transactions on Fuzzy System s,2012,20(1):109-119.
[6] Lin Rui,Zhao Xiaofei,Wei Guiwu.Models for Selecting an ERP System with Hesitant Fuzzy Linguistic Information[J].Journal of Intelligent and Fuzzy System s,2014,26(5):2155-2165.
[7] Liao Huchang,Xu Zeshui,Zeng Xiaojun.Distance and Similarity Measures for Hesitant Fuzzy Linguistic Term Sets and Their Application in Multi-criteria Decision Making[J].Information Sciences,2014,271(7):125-142.
[8] Zhang Zhiming,Wu Chong.Hesitant Fuzzy Linguistic Aggregation Operators and Their Applications to Multiple Attribute Group Decision Making[J].Journal of Intelligent and Fuzzy System s,2014,26(5):2185-2202.
[9] Herrera F,Herrera V E,Verdegay J L.A Model of Consensus in Group Decision Making Under Linguistic Assessment[J].Fuzzy Sets and System s,1996,79(1):73-87.
[10] Herrera F,Herrera V E.Linguistic Decision Making Analysis:Steps for Solving Decision Problem s Under Linguistic Information[J].Fuzzy Sets and System s,2000,115(1):67-82.
[11] Xu Zeshui.Group Decision Making with Triangular Fuzzy Linguistic Variables[C]//Proceedings of the 8 th International Conference on Intelligent Data Engineering and Automated Learning.Birmingham,UK:[s.n.],2007:16-19.
[12] Xu Zeshui,Zhang Xiaolu.Hesitant Fuzzy Multi-attribute Decision Making Based on TOPSIS with Incomplete Weight Information[J].Know ledge-based System s,2013,52:53-64.
[13] 王应明.运用离差最大化方法进行多指标决策与排序[J].系统工程与电子技术,1998,20(7):24-26.
编辑 刘 冰
Hesitant Fuzzy Linguistic Decision Method Based on Combination Weight
PENG Xindong,YANG Yong,SONG Juanping,JIANG Yun
(College of Computer Science and Engineering,Northw est Norm al University,Lanzhou 730070,China)
In view of hesitant fuzzy linguistic decision methods are given by people which have great subjectivity and lead to the instability of the decision making results.The combination weight is proposed which is used to solve the problem of unbeknown weight in hesitant fuzzy linguistic multiple attribute decision making and overcomes the uncertainty caused by the subjective weight.By means of the maxim izing deviation method,the objective weights of hesitant fuzzy set and linguistic set in hesitant fuzzy linguistic set can be obtained respectively.This paper aggregates two kinds of the objective weights,and normalizes them to obtain the combination weight.The Technique for Order Preference by Similarity to an Ideal Solution(TOPSIS)method based on combination weight and the method based on hesitant fuzzy linguistic combination weight geometric operator are explored.Example results show that the decision results of the two methods are the same,so as to verify the feasibility of combination weight.
hesitant fuzzy linguistic set;combination weight;maxim izing deviation;objective weight;geometric operator
彭新东,杨 勇,宋娟萍,等.基于组合权重的犹豫模糊语言决策方法[J].计算机工程,2015,41(9):190-193,198.
英文引用格式:Peng Xindong,Yang Yong,Song Juanping,et al.Hesitant Fuzzy Linguistic Decision M ethod Based on Combination W eight[J].Computer Engineering,2015,41(9):190-193,198.
1000-3428(2015)09-0190-04
A
TP391
10.3969/j.issn.1000-3428.2015.09.035
国家自然科学基金资助项目(61163036)。
彭新东(1990-),男,硕士研究生,主研方向:专家系统,决策支持系统;杨 勇(通讯作者),教授、博士;宋娟萍,硕士研究生;蒋 芸,教授、博士。
2014-10-31
2014-11-26 E-m ail:yangzt@nwnu.edu.cn
