一种基于用户兴趣的STC改进算法
2015-10-21骆绍烨
骆绍烨
(莆田学院信息工程学院,福建莆田351100)
一种基于用户兴趣的STC改进算法
骆绍烨
(莆田学院信息工程学院,福建莆田351100)
作为一种常用的在线文档聚类算法,STC算法聚类结果在用户个性化方面存在不足。改进后的算法结合用户兴趣模型,通过增加基类选择因子和改善基类合并规则来进行改进,实现基于用户兴趣特征的个性聚类效果。实验表明,改进后的算法具有较好的准确性和效率。
STC算法;用户兴趣模型;文本聚类
在浩大复杂的互联网中,各种资源信息充斥其间,搜索已成为不可或缺的最重要的网络应用之一。根据CNNIC的最新统计,搜索引擎的网民使用率达到了80.3%,仅次于即时通信排在了所有的网络应用中的第2位[1]。然而,搜索引擎仅只是对结果按照一定规则进行排序,用户一般只看搜索结果的前几条记录,无法全面了解搜索结果,而聚类技术则可以解决这一问题。
传统的文本聚类主要是对一个或若干个文档集进行离线的聚类分析,文档数量格式等相对固定。而在网页数据聚类分析时,网页的内容和格式等相对繁杂,并且要求在线完成聚类分析。目前, STC算法是WEB挖掘中使用最广泛的在线聚类分析算法之一。
1 经典STC算法
后缀树(Suffix tree)起源于Weiner在1973年提出的一种数据结构[2],主要用于字符串处理,能快速高效地解决字符串匹配和查询问题。后缀树的构造方法较多,比较常用的是Okkonen’s算法[3]。该算法具有较好的时间性和空间性,且容易理解。其基本思想是:假设T[0..i-1]的后缀树已经建好了,那么在T[0..i-1]的每个后缀T[0..i-1], T[1..i-1],..T[j..i-1],..T[i-1..i-1],””(空字符串)的后面加上字符T[i]就可以得到T[0..i]的后缀树[4]。
运用该算法,构造一个具有m个词的字符串S的后缀树的伪代码实现如下:

广义后缀树是将后缀树中的单一字符串推广到多个字符的字符串,并对新字符串运用后缀树构造方法进行构造。搜索结果聚类是将处理过的搜索引擎检索到的文档或网页看成一个很长的字符串,对该字符串构建广义后缀树,选取后缀树中出现的相同的短语作为基类,然后进行合并运算。具体步骤如下:
1)文档预处理:首先清除文档中一些无关的内容,包括网页标签、标点符号、空格等。如果是英文文档,需要进行词干提取,而中文文档则需要进行中文分词处理[5]。
2)构造广义后缀树:将处理过后的文档运用后缀树构造方法构造相应的广义后缀树。
3)选择基类:节点N的权值Score(N),其值由公式(1)来确定:
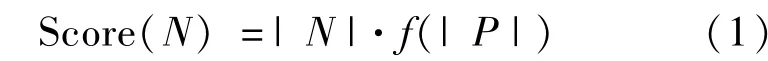
式中,|N|表示节点N所包含的文档数目,候选基类的|N|值应至少等于2,即最少包含两个文档才有资格作为候选基类,|P|代表节点N所包含的词语数,当|P|小于7时,f(|P|)是一个线性函数,大于等于7时,则是一个固定的常数[6]。将计算出的各个节点权值进行排序,选择权值最大的前几个短语作为候选基类。
4)基类合并:对所有的基类短语进行相似度比较,对于基类短语Na和Nb,如果
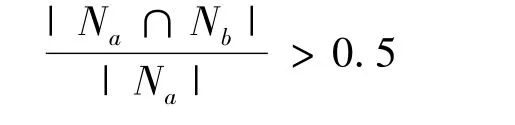
和

则两个基类可以合并。其中|Na|,|Nb|分别表示基类Na和Nb的总文档数,|Na∩Nb|表示两个基类的相同文档的数目[7]。
广义后缀树的聚类方法相对其他一些聚类算法具有许多优点:算法的空间复杂度不高,不似向量空间模型需要占用大量的空间用于表示高度稀疏的文本向量矩阵;广义后缀树算法使用短语作为基类,保存了一定语义结构,有益于提高文本语义的聚类效果;算法相对简单,可以适应在线聚类搜索引擎的需要。
2 算法的不足和研究现状
经典的STC算法主要是针对广义搜索的聚类,忽略了用户的个性化需求。不同的用户搜索的需求各异。同样搜索“篮球”,不同的人感兴趣的话题就不一样,有的感兴趣的话题集中在篮球联赛、“NBA”等篮球比赛上,而有的可能感兴趣的是篮球本身的材质、价格等。在聚类的过程中加入用户兴趣因素能有效提高聚类的准确性,更好地满足用户的需求。目前,针对STC聚类算法的研究主要通过改进聚类的各个阶段来实现算法的优化。而预处理阶段和后缀树构造阶段与用户兴趣关系不大,因而主要通过改进基类选择和基类合并两个阶段来改进算法,提高聚类效果。
在确定基类阶段,经典STC算法仅是根据节点所包含共同文档的数目和短语所含词语数来确定候选基类权值,而没有考虑用户的搜索倾向。如果选择出来的基类短语与用户兴趣差异很大或不相关,该次聚类结果也大打折扣。如何在基类短语中融入用户兴趣,已有研究主要通过加入词频权重因子来提高准确性[2,8-9]。然而,词频权重因子虽可以看作用户的兴趣度,但用户的兴趣来源不应仅依靠词频确定。因此,刘德山在权重公式中还加入了查询词得分系数[10],将包含查询词的基类权重扩大100倍,使其尽可能地包含查询词,在减少偏差的同时也限制了基类的选择范围。
在基类合并方面,经典STC算法考虑的是基类所含文档的相似度,如果共同文档在两个基类中占有率都超过一半,则对两个基类合并。在这样的规则下,大多数情况下是合理的,但并不全面。有些基类具有很高的单方共同文档率(即共同文档占其中一方的比例),但由于两者文档数悬殊,无法满足规则。针对这一问题,林庆等人将合并条件扩展到具有文档包含关系的两个基类[11],即如果一个基类的覆盖文档是另一基类的组成部分,则合并两个基类,避免同时出现具有包含关系的聚类。但这一附加规则仍然无法处理那些不具有包含关系而单方共同文档率很高的基类。同时,传统的STC聚类合并仅基于共同文档率,忽略了基类内容间的关系。肖坤通过比较文档的感兴趣程度与聚类的质心来衡量相关度[12],虽引入了用户兴趣,但忽视了用户兴趣主题的多样性,文档基类的用户感兴趣程度类似并不代表兴趣主题是相关的。
3 基于用户兴趣的改进STC算法
针对现有算法的不足,文中充分研究用户的兴趣在聚类过程中的表达,改进算法的基类选择和基类合并阶段,使聚类检索更好的体现用户的个性要求,实现更切合用户需求的聚类效果。
在聚类选择中加入用户兴趣,首先必须确定用户需求。用户兴趣的表示方法有多种,这里选择常用的向量空间模型来表示。
定义1:用户的兴趣模型I通过一系列兴趣节点Ik来表示,Ik∈I,对于每个Ik,均有二元组(sk,wk)表示,sk表示的是用户感兴趣的特征词,wk表示sk所对应的特征词权重。其数学描述如下:
I={(s1,w1),(s2,w2),(s3,w3),…,(sn,wn)}(2)式中,n是兴趣模型特征词的总数,wn通过IR领域中文本处理运用最为广泛的词频——反文档频率算法来确定[13]。将用户兴趣加入到基类短语的权值计算中,将基类权值计算修改为

式中,wi表示候选基类短语中第i词在用户兴趣模型中的权重,ni表示基类短语中第i词在文档中的频率。修改后的公式中增加了用户兴趣因子,避免了某些与用户兴趣密切相关的短语因包含的文档数较少而落选。已有研究中用户兴趣通常只由短语中各词在兴趣模型中的权重决定,没有考虑到该词在覆盖文档中的出现频率。用户兴趣词出现频率更高的文档,用户感兴趣的可能性自然更高,加入词频能更好地体现用户的兴趣。
在基类选择时,个别基类短语节点包含了大量的文档,可能超过了所有文档数的一半,甚至接近总文档数,此类短语节点计算出的基类权值也必然很大。但正因为此类节点代表性太广泛,将导致聚类结果没有区分度,即大部分文档都集中在一个分类中,失去了聚类的意义。因此,在计算基类权值之前应对候选基类节点进行筛选,筛去包含文档数过多的节点,通常建议节点的文档包含比(文档包含比=节点文档数/总文档数)不超过30%[6]。
3.2 改进的基类合并算法
在基类合并过程中,为了避免一些基类的“子类”或者“近似子类”因文档数量差异过大而无法合并,在原有合并规则的基础上增加一条新的规则来处理这一情况。
小学数学课程标准对于数学教育至关重要,制定标准必须非常谨慎.课标的制定绝非产品设计,可以为所欲为;而是严肃的科学研究,去寻求和确定建构学生知识大厦的正确途径.由于课标不当,几代美国人已经在数学上遭遇了滑铁卢;在加拿大,“数学恐惧症”也在大幅蔓延.希望数以百万计的孩子不再被当作试验品,重蹈覆辙.
该规则的数学描述:
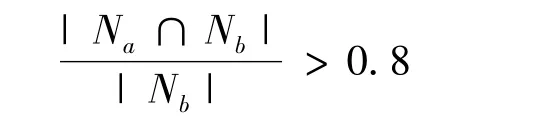
或者
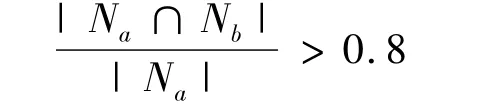
通过修改,新的合并规则能够更好地解决基类包含问题,当共同文档数达到其中任一文档数的80%以上时,就认为两个基类具有包含关系或近似包含关系,可以将两个基类合并。
现有的STC聚类合并大多是基于共同文档率考虑的,很少涉及文档的内容联系,仅有部分研究采用文档用户感兴趣度来表达文档间的内容关系[12]。但兴趣度接近只是表达用户对文档的感兴趣程度是类似的,无法代表内容之间的关联。而文档的主题是内容的体现,文档主题的一致或类似也就表示文档内容具有一定的相似性,即文档的主题相似性反映了两者的内容联系。
基类文档的主题虽然可以通过词频来确定,但这样确定出的主题自由度过大,过于宽泛而不具针对性。引入用户兴趣模型来确定主题,可以通过用户兴趣模型中的权重来识别主题的重要性,避免确定出如“运动”、“商品”等过于宽泛的主题词,而降低主题区分度。
定义2:对于基类B的用户兴趣主题T(B),通过一系列主题节点Tk来表示,Tk∈T(B),对于每个Tk,均由一个二元组(sk,ik)表示,sk表示的是用户兴趣主题的特征词,ik表示sk在基类B中的兴趣度。其数学描述如下:

其中 ik=nk*wk/nB
式中,nk表示特征词在B中出现的次数,wk为特征词的权重,nB是基类文档B的总词数。
为了突出体现基类的用户兴趣主题,选取基类中兴趣度最高的3个主题兴趣节点作为基类B的主要兴趣主题特征词,记为T′(B),3个主要兴趣主题特征词构成的集合为文档的主要用户兴趣特征,记为S′(B)。
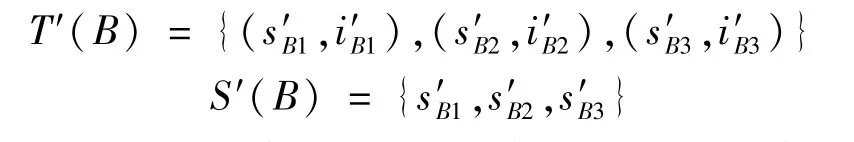
对于两个基类,考虑到基类主题的相对广泛性和不可确定性,共同文档率仍然作为主要考虑因素。只有达到一定共同文档率的两个基类,才进行必要的主题分析。如果它们的主要兴趣特征词的兴趣度均超过一定阈值(记为δ),且3个主要兴趣相同,则两个基类合并。对特征词兴趣度的阈值要求既节省了时间,也避免了仅依靠主题相似的不确定性。
综合以上,基类Na和Nb合并的前提是满足以下条件之一:
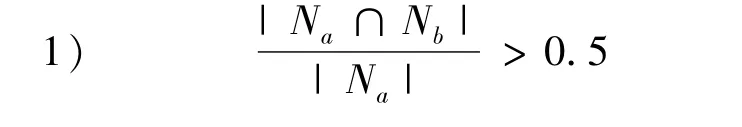
和
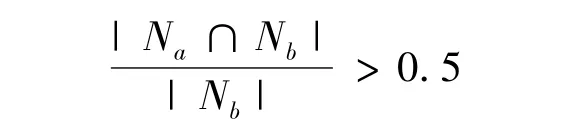
或者
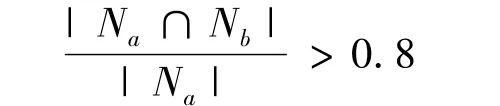
3)i′Na>δAND i′Nb>δAND S′(Na)=S′(Nb)
4 实验结果及分析
为了验证基于用户兴趣的改进STC聚类算法,设计了原型系统进行实验测试,对经典STC算法和改进后的算法进行分析对比。实验数据通过微软Bing API获得,聚类方法在J2EE的平台上实现,运行在酷睿i5、4 GB内存的Windows XP计算机上。
首先测试聚类的效果。测试时,改进的STC算法采用两种不同的用户兴趣模型。两种用户兴趣模型分别给予不同的特征词,用户兴趣模型A的特征词为“原理”、“课程”、“课件”、“教程”等倾向计算机专业学习的词语,而用户兴趣模型B则选用“安卓”、“Apple”、“手机”、“移动”等有关手机操作系统的词语。表1是检索词为“操作系统”在检索文档数为500的情况下,不同算法或用户兴趣模型检索聚类情况。
从表1可以看出,经典STC算法形成的聚类标签数量更多一些,且相对比较杂,其中包含了检索词“操作系统”以及“软件”、“系统”等较多宽泛的词语,甚至出现了一些无显著意义的聚类标签,如“网”、“64位”、“提供”等。而在改进STC算法的两个不同用户兴趣模型下,聚类标签中均没有出现检索词,部分代表性差的标签也消失了。这是由于在改进的算法下,文档包含比过高的词被剔除。同时,通过在选择基类时引入用户兴趣特征词权重因子,改进后的算法产生的聚类标签更多地包含了对应用户兴趣模型中的特征词。此外,经典STC的聚类标签中有部分词语有着包含关系,如“XP系统”和“XP系统下载”,改进的算法通过合并单方重复率过高的文档集避免了这样的情况。

表1 聚类结果对比Tab.1 Clustering results
第2组实验测试算法的时间复杂度。从微软Bing搜索的结果中分别选用不同数量的搜索结果文档,运用改进前后的算法进行测试。文档数量分别选取100,200,300,400,500 5个层次,测试结果为5个不同检索词的平均聚类时间,其结果如图1所示。
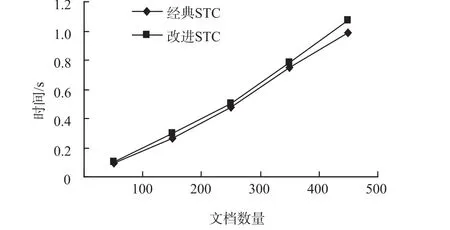
图1 算法改进前后聚类时间对比Fig.1 Clustering time about the algorithm s before and after im p rovem ent
从图1中可以看出,改进STC算法在相同文档数量的情况下,所花费的时间均要比经典STC的长,这主要是由于改进的算法基类合并时不但要对文档重复度进行判断,还要对基类的兴趣主题相似度进行对比。但是每个基类的兴趣特征词的兴趣度计算只需要遍历基类文档一次即可,基类数目通常也不会太多,所以增加的时间耗费并不明显。
5 结 语
通过分析原有的STC聚类算法,结合用户兴趣模型对算法基类选择和基类合并阶段进行改进。实验结果表明,改进后的算法在基本保证算法时间效率的前提下,完善了经典STC算法的部分缺陷,并具有更加贴近用户需求的聚类效果。
[1]中国互联网络信息中心.第33次中国互联网络发展状况统计报告[EB/OL].(2014-03-05).http://www.cnnic.net.cn/
hlwfzyj/hlwxzbg/hlwtjbg/201403/t20140305_46240.htm.
[2]冯冰洁,杨天奇.后缀树聚类算法在元搜索引擎中的应用[J].微计算机信息,2010,26(1):204-206.
FENG Bingjie,YANG Tianqi.Suffix tree clustering algorithm in themeta search engine[J].Microcomputer Information,2010,26 (1):204-206.(in Chinese)
[3]Ukkonen E.On-line construction of suffix tree[J].Algorithmica,1995,14(3):249-260.
[4]吴江宁,王治江.一种基于后缀树的Web搜索结果聚类方法[J].情报学报,2010,29(1):78-83.
WU Jiangning,WANG Zhijiang.A clusteringmethod forWeb search results based on suffix tree[J].Journal of the China Society for Scientific,2010,29(1):78-83.(in Chinese)
[5]彭松行.基于描述优先算法的Web搜索结果聚类系统研究[J].心智与计算,2010(4):250-257.
PENG Songhang.Research of Web search results clustering system based on description quality first algorithm[J].Mind and Computation,2010(4):250-257.(in Chinese)
[6]杜红斌,夏克文,刘南平,等.一种改进的基于广义后缀树的文本聚类算法[J].信息与控制,2009,38(3):331-336.
DU Hongbin,XIA Kewen,LIUNanping,etal.An improved text clustering algorithm ofgeneralized suffix tree[J].Information and Control,2009,38(3):331-336.(in Chinese)
[7]刘文婷,滕奇志.后缀树聚类在专用搜索引擎中的应用研究与改进[J].成都信息工程学院学报,2010,25(3):269-274.
LIUWenting,TENG Qizhi.The research and improvement of STC on dedicated search engine[J].Journal of Chengdu University of Information Technology,2010,25(3):269-274.(in Chinese)
[8]彭静,翟英,冯爽.后缀树算法在舆情聚类中的应用[J].河北科技大学学报,2012,33(1):65-68.
PENG Jing,ZHAIYing,FENG Shuang.Application of STC algorithm to internet public opinions clustering[J].Journal of Hebei University of Science and Technology,2012,33(1):65-68.(in Chinese)
[9]阳小兰,钱程,赵海廷.一种基于Nutch的网页聚类系统的设计与实现[J].计算机工程与应用,2011,47(5):118-122.
YANG Xiaolan,QIAN Cheng,ZHAO Haiting.Design and implementation on Web clustering system based on Nutch[J]. Computer Engineering and Applications,2011,47(5):118-122.(in Chinese)
[10]刘德山.一种改进的基于后缀树模型搜索结果聚类算法[J].计算机科学,2011,38(11):148-152.
LIU Deshan.Improved search results clustering algorithm based on suffix treemodel[J].Computer Science,2011,38(11):148-152.(in Chinese)
[11]林庆,袁晓峰,吴旻.中文Web文档聚类算法研究[J].计算机工程与设计,2009,30(20):4759-4761.
LIN Qing,YUAN Xiaofeng,WU Min.Research of one kind of Chinese web document clustering algorithm[J].Computer Engineering and Design,2009,30(20):4759-4761.(in Chinese)
[12]肖坤.面向用户兴趣的校园网聚类搜索引擎的研究与实现[D].长沙:国防科技大学,2010.
[13]龚卫华,杨良怀,金蓉,等.基于主题的用户兴趣域算法[J].通信学报,2011,32(1):72-78.
GONGWeihua,YANG Lianghuai,JIN Rong,et al.Domain of interests clustering algorithm based on users′preferred topics[J]. Journal on Communications,2011,32(1):72-78.(in Chinese)
(责任编辑:杨 勇)
A New STC A lgorithm Based on User Interest
LUO Shaoye
(College of Information Engineering,Putian University,Putian 351100,China)
STC algorithm is an online document clustering algorithm commonly used.There are some deficiencies in users′personalization of the clustering results.The improved algorithm combined with the users′interest model can implement the characteristic clustering results by increasing the base class selection factor and improving the merge rules of the base class.The experiments show that the improved algorithm has better accuracy and efficiency.
STC algorithm,user interestmodel,text clustering
TP 391
A
1671-7147(2015)01-0085-05
2014-09-10;
2014-10-16。
福建省教育厅B类科技项目(JB12175);莆田市科技项目(2014G16);莆田学院教育教学改革研究项目(JG2012001)。
骆绍烨(1982—),男,福建莆田人,讲师,工学硕士。主要从事WEB挖掘及WEB应用研究。
Email:Lsy123@163.com
