Clementine软件功能缺陷分析
2015-08-09张钰莎蒋盛益
张钰莎,蒋盛益
(1.广东外语外贸大学 南国商学院,广东 广州 510545;2.华南师范大学 计算机学院,广东 广州 510631;3.广东外语外贸大学 思科信息学院,广东 广州 510420)
0 引言
Clementine是一个可视化程度高、使用简便的数据挖掘平台,其操作与数据分析的一般流程相吻合[1].数据分析通常经过数据加载、数据展示和预处理、模型建立、模型评价等环节.Clementine形象地将这些环节中的功能表示成若干节点,将数据分析过程看成数据在各个节点之间的流动过程,并通过一个可视化的“数据流”直观地表示整个数据分析过程.Clementine的操作目的就是要建立一条或多条数据流,通过不断修改和调整流中的节点及参数,执行数据流,进而完成整个数据分析任务.由于Clementine操作简单易懂,没有编程的要求,使得管理人员、销售人员等非技术人员都能进行数据分析,在实际领域中的应用越来越广泛.但是,在使用过程中,我们发现部分节点预测性能不佳,甚至存在严重不足,本文通过实例分析离群点检测、特征选择及抽样等节点存在的缺陷.
1 离群点检测
聚类、分类、关联分析等数据挖掘方法重点在发现适用于大部分数据的常规模式,应用这些方法时,离群点(Outlier)通常作为噪音而被忽略以降低或消除离群数据的影响.但在安全管理、风险控制等应用领域,识别离群数据的模式比正常数据的模式更有价值.离群点检测被广泛用来发现稀有模式,或数据集中显著不同于其他数据的对象[2-3].通过对离群数据的分析可以迅速、准确地甄别异常事件,如电信、保险、银行、电子商务的欺诈检测、灾害气象预报、商业营销中极高或极低的客户识别,医学诊断研究中发现新的疾病对医疗方案或药品所产生的异常反应,网络安全中的入侵检测、海关报关中的价格隐瞒、过程控制中的故障检测与诊断等.
Clementine提供了一个离群点检测节点Anomaly,在两步聚类的基础上实现离群点检测.首先应用两步聚类算法对数据集进行聚类,将数据集划分为若干个簇(即对等组),然后对每个样本,计算与其最近的簇间距离,并根据距离的大小计算其“离群指数”,来度量这个样本到底有多么“离群”.可以通过设定离群指数的阈值,将那些大于阈值的样本作为离群点样本.Anomaly节点完成两个任务:一是从数据集中确定哪些是离群样本;二是对每个离群样本,分析是哪些属性导致该样本成为离群样本.
但两步聚类算法是以k-means算法为基础的,对离群数据较敏感,存在离群数据时聚类效果不太好,这导致Anomaly节点性能理论上存在缺陷.而一趟聚类算法[5]不易受离群数据的影响,因此基于一趟聚类算法的离群点检测算法性能较Anomaly节点更佳[4-5].下面通过UCI[6]中几个实例数据集加以验证说明.
1.1 离群点检测在淋巴系造影术中的应用
淋巴系造影术(Lymphography)数据集包含148 条记录,每条记录由18个离散属性来描述,所有记录被标识为1-4 的4个类别,类1与类4总计包括6条记录,占整个记录数的4.05%,利用离群点检测方法来识别这些稀有记录.使用一趟聚类算法和Clementine的两步聚类方法将数据集划分为8个簇后,各个簇包含的记录类别分布如表1所示.从表1的类别分布数据可以算出两种聚类方法得到的聚类熵分别为0、0.051.可见,一趟聚类算法较两步聚类方法的聚类效果要好.
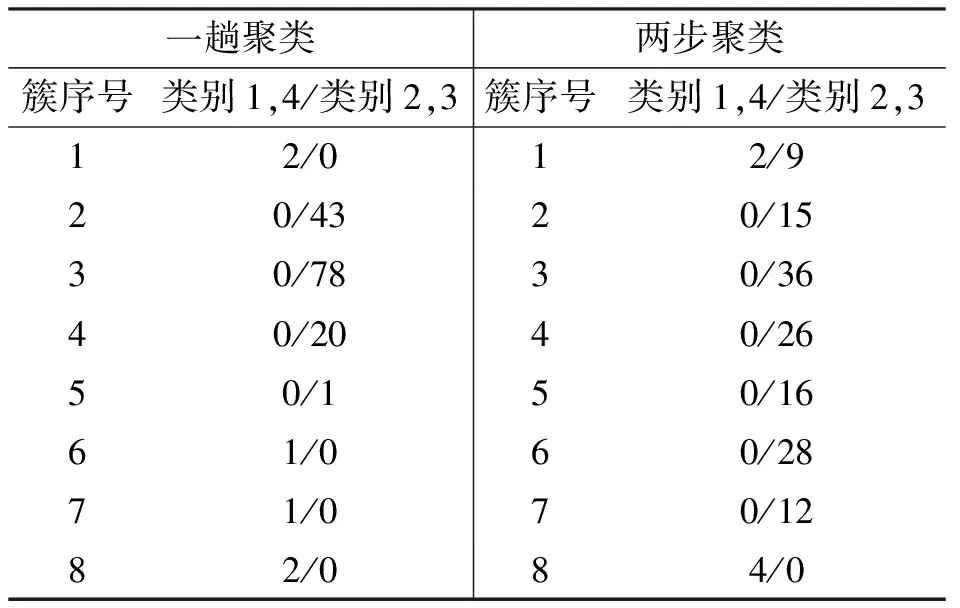
表1 划分为8个簇后的类别分布
使用基于一趟聚类的离群点检测方法[4],检测到离群指数大的前5条记录均为稀有记录,第10条记录为稀有记录.而对应于Clementine的Anomaly节点,离群指数大的前7条记录能检测出5 条稀有记录,前31 条记录才能检测出全部6条稀有记录.在该数据集上,文献[4]中方法性能明显优于Anomaly节点检测方法.
1.2 离群点检测在癌症诊断中的应用
乳腺癌数据集(Wisconsin breast cancer data set)包含483条记录,其中恶性记录39条,良性记录444条,每条记录由9个数值属性来描述.恶性记录占比8%,我们的目的是利用离群点检测方法将恶性记录从测试数据中识别出来.使用一趟聚类算法和Clementine的两步聚类方法将数据集划分为4个簇后,各个簇包含的记录类别分布如表2所示.利用表2的结果可以求出两种聚类方法得到的聚类熵分别为0.095、0.085;两种聚类方法在该数据集上的聚类效果差异不大.
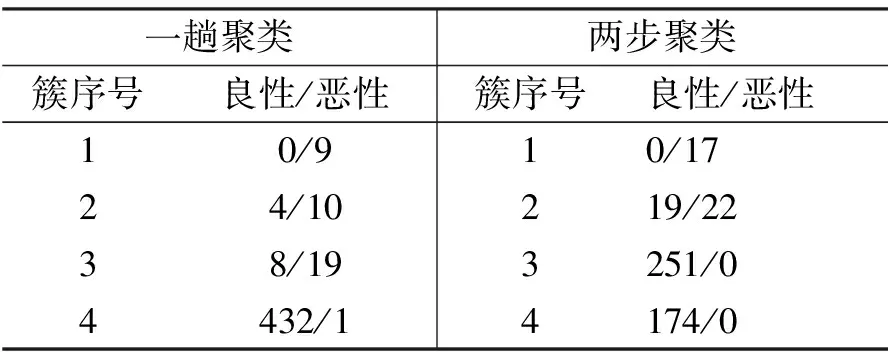
表2 划分为4个簇后的类别分布
进一步,使用基于一趟聚类的离群点检测方法[4],检测到离群指数大的前27条记录全部是恶性记录,前44条记录中包含38条恶性记录,前59条记录中包含全部39条恶性记录.而Clementine的Anomaly节点检测方法离群指数大的前51 条记录全部是良性记录,前100条记录只包含8条恶性记录,前242条记录中才能包含全部39条恶性记录.在该数据集上,文献[4]中方法性能显著优于Anomaly节点检测方法的性能.
1.3 离群点检测在网络入侵检测中的应用
KDDCUP99包含了约49万条网络访问记录,每条记录由9个离散特征和32个数值特征来刻画,并且包含一个标志位(正常记录或攻击记录);因整个数据集太大,从中随机抽取一个包含19 799条记录的子集P,其中正常记录数19 542条,攻击记录数257条,攻击记录占1.3%,可以看成离群点.使用一趟聚类算法和Clementine的两步聚类方法将数据集P划分为12个簇后,类别分布如表3所示.进一步可以算得,两种聚类方法得到的聚类熵分别为0.003、0.013,一趟聚类算法的聚类结果较两步聚类的结果好.

表3 划分为12个簇后的类别分布
采用基于一趟聚类的离群点检测方法[4]在数据集P上进行检测,检测结果如下:离群指数大的前58条记录中包含1条正常记录和57条攻击记录;前656条记录中包含419条正常记录和237条攻击记录.而Clementine的Anomaly节点对应离群指数大的前985条记录中全部是正常记录.在该数据集上,文献[4]中方法性能显著优于Anomaly节点检测方法性能.
2 特征选择
在原始数据中通常包含无关的或冗余的特征,这使得许多分类和聚类等学习算法的效果并不理想.不相关或冗余特征的增加会减慢数据挖掘进程,从而需要花费大量的时间和精力来检查模型究竟应该包含哪些字段或变量,也就是确定哪些特征来参与模型建立.那些和要预测的特征并没有什么关系或者关系不大的特征就没有必要参与建模过程,比如作为主键的“样本号”字段.降低特征维度带来的好处主要有两点:一方面使许多数据挖掘算法效果更好、效率更高;另一方面使产生的模型更容易理解.特征选择是减少维度最常用的方法,其目标是找出最小特征子集,使得数据类别的概率分布尽可能地接近使用所有特征得到的原分布[7-8].通过特征选择,一些和任务无关或者是冗余的特征被删除,从而提高后续数据挖掘的效率,简化学习模型.Clementine软件提供了一个特征选择方法.
从UCI数据集中选取了9个数据集进行测试,数据集的说明如表4.将Clementine中特征选择方法与文献[8]中的方法CBFS进行性能对比.为说明问题,对每个数据集在全部特征集合和选取的特征集合上使用Clementine软件中的C5.0分类算法进行对比测试,以比较对应性能的变化.

表4 实验数据集参数汇总
在每个数据集上,首先进行特征选择,得到特征选择后的特征子集,然后在各特征选择算法处理后的训练数据集上训练得到C5.0决策树分类器,接着得到C5.0分类器在测试集上的分类准确率并记录下来.如表5所示给出了在这些选取的数据集上CBFS及Clementine的特征选择算法得到的特征子集.表6列出了C5.0在特征选择算法处理后的分类准确率.为便于比较,表的第一列给出了分类器在原始数据集上的分类错误率.对数据集采用随机选取的2/3 的数据作为训练集,余下的作为测试集的策略划分数据集,同时在每个数据集上测试10次,以10次的平均指标作为评估的结果.
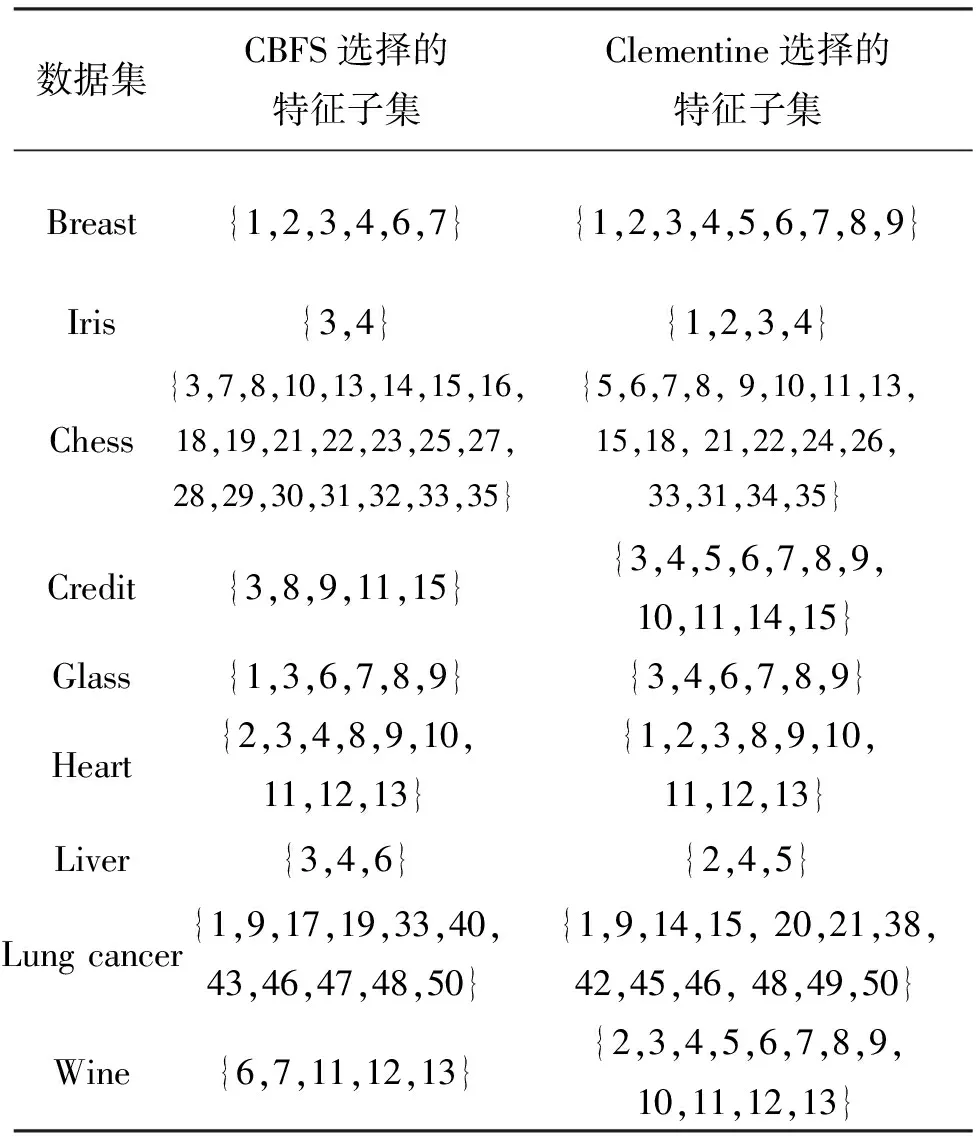
表5 所选数据集在各特征选择算法得到的特征子集
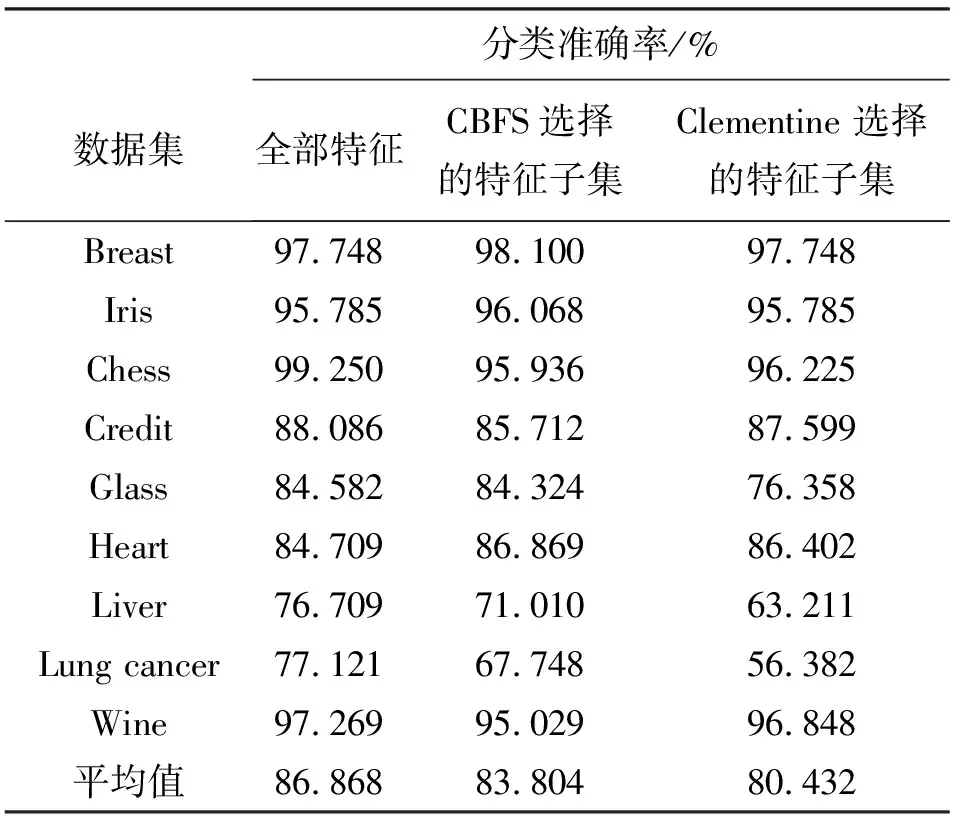
表6 C5.0 在全部特征和选择的特征子集上的分类准确率对比
从实验测试结果可见,文献[8]中CBFS与Clementine中特征选择方法在9个数据集上对特征规约的强度分别为57.14%和47.21%.特别地,Clementine在Breast和Iris数据集上不能识别不同特征的重要程度.在余下的7个数据集中,CBFS得到的特征子集上的分类准确率总体更好.由此可见,CBFS较Clementine的特征选择方法无论在特征规约强度还是规约的质量方面都要好,Clementine的特征选择方法的性能有待改善.
3 记录的随机选择问题
抽样节点、分区节点、平衡节点等几个节点涉及对记录的随机选择.按照通常的理解,随机选择的记录,其结果是不确定的,但随机选择的数据规模应该随用户的指定而确定,但这些相关节点存在很多不确定性.
抽样节点的随机性问题:抽取p%的记录,其记录数不确定.如对于pima数据集,其有768条记录,随机选择50%的记录,应该是384条记录,但其选取的结果子集大小不确定,可能是:374、383、387、393、398、370、368、361、402等.
由于分区节点是将数据集随机划分为2个(训练集、测试集)或3个子集(训练集、测试集、检验集),因此也存在类似的问题,划分子集的大小不是随划分比例而固定.这进一步导致,基于分区的建模和检验,其分类准确率等结果也有一些不确定性.
平衡节点是对符合条件的记录按一定比例随机选取对象,因此也存在类似的问题.在平衡因子确定的情况下,得到的数据集大小也是不确定的.如对于mushroom数据集,其中类别为“p.”的有3916条记录,类别为“e.”的有4208条记录,将类别为“p.”的平衡因子设为0.1,得到的数据集大小应该是4599,但实际得到的大小可能是4564、4590、4618、4609、4611.
4 结论
Clementine软件因其功能强大、可视化程度高、操作简便等特点深受用户青睐,得到了广泛的应用.本文指出了其部分功能节点存在的不足,期待高的版本能改善这些问题.
