一种基于空间金字塔模型的兴趣点对自相关的图像特征
2015-08-07程浩宇郑莹斌蔡烜冯瑞
程浩宇,郑莹斌,蔡烜,冯瑞
一种基于空间金字塔模型的兴趣点对自相关的图像特征
程浩宇,郑莹斌,蔡烜,冯瑞
针对传统视觉词袋模型只考虑兴趣点出现的频率而忽略了局部特征空间信息的问题,提出了一种基于空间金字塔模型的新的图像特征。该特征在标准视觉词袋模型基础上,通过计算属于同一码字的兴趣点对之间的距离,加入了不同码字包含的兴趣点在图像上的空间分布。更结合空间金字塔模型,聚合不同分层过程中提取的特征,更大程度上考虑了空间信息,从而加强了特征对图像内容信息的表示能力。实验结果表明,与传统的词袋模型和金字塔模型相比,具有更高的精准度和分类性能。
场景分类;视觉词袋模型;兴趣点;金字塔模型
0 引言
近年来随着互联网技术的发展,海量的图像数据出现在互联网。面对数据的爆炸性增长,人工地进行管理和分析远不能满足要求,如何通过提取图像特征来表示图像中的视觉内容,进而对图像进行准确的识别引起了人们的广泛关注。
早期的图像理解技术,依靠人工标注的方法表示图像。将人工标注的内容作为图像的标签,再通过文本的检索和识别方法间接地对图像进行操作。这种方法局限于人力的使用,在时效性和精确性上远不能达到需求,同时,由于不同标注者的理解不同,无法保证标注内容的一致性。随着图像处理技术的发展,视觉内容的表示越来越依托于提取图像的视觉特征。基于图像的内容信息,通过提取例如颜色分布、纹理信息等特征来表示图像。进一步地,一系列的图像底层视觉特征被陆续提出,包括SIFT特征[1]等。由于图像的底层视觉特征更侧重于小区域的局部信息,为了对图像整体进行分析又提出了更高层的特征,例如视觉词袋模型,可以表示图像整体的内容信息和结构分布。
视觉词袋模型会提取出图像上的底层特征点,即兴趣点。对兴趣点的特征聚类后构成视觉词典,词典中每一个“单词”即表示图像上具有代表性的一类区域,通常称为码字。通过统计从属于每个码字的兴趣点的出现频率,可得到每一个代表区域在图像上所占的比例大小。最后,通过词典的频率直方图作为特征表示图像信息。视觉词袋模型统计了不同聚类的数量和频率信息,但忽视了不同类别在图像上的空间分布信息。为了解决这个问题,人们在视觉词袋模型基础上,将基于特征空间的空间金字塔模型引入图像中,提出了空间金字塔匹配方法[2]。将图像按网格分格,统计分格后每个区域中的兴趣点出现频率来表示每一个码字在图像上的整体分布信息。
基于视觉词袋的金字塔模型初步统计了码字在图像固定细分区域的出现频率,但仍忽略了从属同个码字的兴趣点之间距离上的相关性,而点之间相关性更能准确表达同一个码字区域内兴趣点的空间分布状况。本文提出了一种基于空间金字塔模型的兴趣点对自相关图像特征,此特征在空间金字塔模型基础上,改进图像分层后的特征提取方法,通过增加兴趣点对之间的空间距离信息,计算同码字的兴趣点在不同距离尺度上的分布情况,形成新的视觉特征,提升了在场景识别数据集上的精度和效果。
1 兴趣点对自相关特征
传统的视觉词袋模型通过对图像进行预处理,提取出图像一定数量的局部特征,得到兴趣点区域和特征表示。再进行特征聚类任务,形成固定类别数目的聚类结果,即视觉词典,其中每一个类别即为词典中的码字。兴趣点的局部特征一般选择表现兴趣点区域属性的底层视觉特征,例如SIFTT特征,HoG特征[33]等。means
本节首先通过传统视觉词袋模型方法得到视觉词典和对应码字。本文的方法选择使用SIFT特征作为表示图像兴趣点的局部特征。SIFT特征提取的图像兴趣点是一些十分突出,不会因光照等因素影响的区域,具有良好的尺度不变性和稳定性。通过SSIFT特征提取方法,得到了表示每个兴趣点的128维特征描述子,从其中选择一定数量进行聚类(通常使用k-means算法[4]),构造出组成视觉词典的码字。得到的视觉词典定义如下:
V={w1,w2,…,wn}
其中wn表示视觉词典中的码字。进一步,通过对所有兴趣点特征进行特征量化,得到兴趣点和码字之间的从属关系。视觉词袋模型通过统计码字出现的频率直方图作为表示图像的特征,给出词典和码字在图像上的频率分布情况。在视觉词袋模型基础上,本文设计了以下方法来得到兴趣点的空间分布关系[5]。
对于图像Γ,我们用pk=(xk,yk表示图像上一个兴趣点rk的位置,此兴趣点在视觉词典中对应的码字记为w(ri)。对于图像上的兴趣点rk和ri,用‖ppk-pi‖来表示两个兴趣点的距离,本文的方法中使用L∞距离如公式(1):

对于每一个兴趣点,定义Tk(wj,d)表示rk与其相邻区域内兴趣点的相关性以及相关的兴趣点分布比例,定义如公式(2):
其中ri∈Γ表示兴趣点 ri在图像中。
Tk(w,d)表示了兴趣点ri与码字为wj的兴趣点集合的相互关系,用来统计距离兴趣点rk为d的wj兴趣点子集分布情况。为了描述词典中两个码字wi和wj之间的相关性,统计从属码字wi的所有兴趣点和另一个码字wj之间的相互关系,定义Tk(wi,wj,d 如公式(3):

Tk(wi,wj,d)计算两个码字wi和wj分别对应的兴趣点中距离为d的比例。一个计算兴趣点相关性和码字相关性Tk(wi,wj,d)的示例如图1所示:

图1 计算兴趣点相关性
将所有wi,wj,d取值下的结果连接起来,串成一个向量,即可得到一个表示兴趣点之间分布关系的图像特征[6]。假设图像大小为w×h,取D=max(w,h),则特征维度为n2D.
在此基础上进一步,若仅计算同一个码字对应的兴趣点间的相关性,会忽略冗余信息,加强特征表示的紧凑型,同时,计算的复杂性大大降低。为了描述码字在兴趣点位置分布上的自相关性,我们定义corr(wi)来表示所属码字为w 的兴趣点对中,距离为d的比例,称为兴趣点对自相关特征,corr(wi)定义如公式(44):

最后,将视觉词典中所有码字wn和距离d取值下对应的特征串成一个向量,就能构成图像的兴趣点对自相关特征如公式(5):
在本文的算法中,距离的取值取决于图像的大小。将距离区间平均分为s个区间:I1=[0,L),I2L),…,Is=[(s-1)L,D),其中L D/s.此时,特征的维度降为ns。
2 空间金字塔模型的优化
金字塔模型的一种思想是将特征空间进行一系列不同程度的分格,在不同层次的网格分割结果上进行特征匹配,再将不同层次上的匹配结果进行加权求和得到特征集整体的相似度[7]。另一种实现方式是在不同层次的网格分割结果上,对每一个网格区域运用基本的特征提取方法,然后,将各个层次上的各个区域的特征进行加权处理并线性连接,得到金字塔特征,最后,用得到的特征向量进行匹配。本节中,我们尝试采用第二种实现方式,将兴趣点对自相关特征与空间金字塔模型进行结合,改进特征提取方法来优化金字塔模型如图2所示:
图2 空间金字塔模型示例
空间金字塔使用了1w1,2w2,4w4等分层方式,分别对应第0层,第1层和第2层。在提取图像视觉词典后,对图像进行网格分层。定义(m=1,…,221;l=0,…,L)表示分层后的图像区域,其中l表示分层层次,m表示同一层的网格区域。分层结束后,在各个层次依照上一节的方法提取不同图像区域的兴趣点对自相关特征如公式(6):
将得到的各级各单元区域的特征加权处理并线性连接,即可得到图像兴趣点对自相关特征的空间金字塔表示如公式(7):

其中U*表示特征向量的线性连接。W1表示不同金字塔层次的加权值,取值如下:
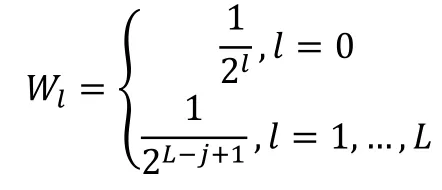
3 实验结果与分析
3.1 scene-15数据集
本实验使用scene-15场景识别数据集来评估实验结果[8]。如图3所示:

图3 scene-15数据集
scene-15包含室内、山脉和街道等15个类别的场景图像,每一类为200到400张图片。对于每个类别的所有图像,实验中随机抽取100张用作训练,剩下的用于测试。同时为了测试数据的准确性和稳定性,实验中尝试了多次的随机划分,重复生成了多组不同的训练和测试数据,最终综合实验结果来评估平均识别准确率。
3.2 实验结果与分析
对于数据集中的图像,首先,依照传统视觉词袋模型生成视觉词典:采用密集采样方法提取图像的兴趣点,进一步提取每个兴趣点128维的SIFT特征,再使用k-means算法进行特征聚类形成视觉词典。然后,应用空间金字塔模型分格,分层过程采用1w1,2w2,4w4 的分格方式。最后,在分格区域上提取图像的兴趣点对自相关特征,特征提取过程中距离区间采用s 2。
得到优化后的金字塔模型特征后,实验使用了SVM分类器来进行图像分类任务,核函数为直方图相交核函数,如下:

实验中首先将视觉词典的码字数量作为变量,来对比不同码字的视觉词典对于实验结果的影响。分别取码字数量为16和200的情况作为实验结果对照。通常情况下,码字数量的增加会提升识别的结果,如图4所示:

图4 单层模型下Corr特征识别结果
通过图4中的实验结果可以看到,对比模型中每一单层的兴趣点对自相关特征识别结果,同一层模型下识别的准确率随码字数量增加有明显提升。当码字数量为200时,由于多码字和分格数量过多情况下特征分辨能力下降,第2层(4w4分格)的识别准确度不如第1层(2w2分格)。
同时将运用直方图特征的传统空间金字塔模型的实验作为对比,分别列举了两种模型下单层特征分类和多层特征融合的实验结果,多层特征为各层特征线性连接后结果如表1、表2所示:

表1 码字数量为16时特征识别准确率
通过表1和表2的实验结果可以看到,在码字数量为16时,多层兴趣点对自相关特征对于传统词袋模型结果,即单层直方图特征,准确率分别提高了10.6%和8.3%。在码字数量为200时,准确率分别提高了5.2%和2.8%。
同时,实验结果显示,无论是对于兴趣点对自相关特征还是直方图特征,多层结构对于单层结构都能取得更好的实验结果。对于兴趣点对自相关方法,在码字数量为16时,直方图特征从单层结构到多层结构分别提高了2.8%和3.4%,兴趣点对自相关特征从单层结构到多层结构分别提高了4.2%和6.3%。码字数量为200时,直方图特征从单层结构到多层结构准确率分别提高了2.4%和0.3%,兴趣点对自相关特征从单层结构到多层结构准确率分别提高了2.7%和5.9%。以上实验结果说明,兴趣点对自相关特征和空间金字塔模型融合的方法优于其他方法,在分类的准确性上有明显的提升。
4 总结
本文提出了一种基于空间金字塔模型和兴趣点对之间相关性的新的图像特征。该特征弥补了传统词袋模型和金字塔模型对兴趣点空间分布的忽略,增强了特征对图像信息的表示能力。同时,该特征改进了金字塔模型中对兴趣点分布的统计方法,进一步加强了特征的紧凑型。实验表明,这种新的图像特征对于传统的金字塔模型有更好的分类准确性,在场景识别数据集上提升了识别结果。
[1]Lowe,D.G:Distinctive Image Features from Scale-Invariant Keypoints[J]. IJCV, 2004,60(2):91-110.
[2]Lazebnik,S.,Schmid,C.,Ponce,J.:Beyond bags of features:Spatial pyramid matching for recognizing natural scene categories[C]. In:CVPR, 2006:2169-2178.
[3]DalalandB.N. T:Histograms of Oriented Gradients for Human Detection.Proc[J]. IEEE Conf.Computer Vision and Pattern Recognition,2005.
[4]Csurka,G.,Dance,C.R.,Fan,L.,Willamowski,J.,Bray,C.: Visual categorization with bags of keypoints.In:Workshop on Statistical Learning in Computer Vision[J]. ECCV, 2004:1-22.
[5]Vodel,J.,Schiele,B.:Semantic modeling of natural scenes for content-based image retrieval[J]. IJCV,2007,76(2): 133-157.
[6]Zheng,Y.,Lu,H.,Jin,C.,Xue,X.:Incorporation spatialcorrelogram into bag-of-features model for scene categorization[M]. In:ACCV,2009.
[7]Hartigan,J.A.,Wong,M.A.:A K-means clustering algorithm[J]. Applied Statics 28, 1979:100-108.
[8]van Gemert,J.,Geusebroek,J.M.,Veenman,C.J.,Smeulders, A.W.M.:Kernel codebooks for scene categori-zation.In:Forsyth,D.,Torr,P.,Zisserman,A[M]. (eds.)ECC V 2008.
Incorporating Spatial Correlogram into Spatial Pyramid Matching
Cheng Haoyu1, Zheng Yingbin2, Cai Xuan3, Feng Rui1
(1.School of Computer Science, Shanghai Engineering Research Center for Video Technology and System, Fudan University, Shanghai 201203, China; 2.SAP Labs China, Shanghai 201203,China; 3.The ThirdInstitute of Ministry of public security, Shanghai 201204, China)
This paper presents a new approach to improve the traditional bag-of-visual-word model for scene categorization. Traditional model considers images as a histogram of the occurrence rate of interest regions. In this approach, the spatial distribution of code words is incorporated to approximate the image geometric information. This works by improving the traditional codeword histogram with calculating the spatial distance between pair wise interest regions. It combines the approach with spatial pyramid matching algorithm to consider global geometric information and strengthen its ability to represent the image content. Experiment results on a public dataset show that the combination with spatial pyramid matching increases the accuracy and improves effectiveness for categorization.
Scene Categorization; Bag-of-features; Interest Regions; Spatial Pyramid
TP311
A
2015.02.25)
1007-757X(2015)04-0001-03
国家科技支撑计划(2013BAH09F01);上海市科委科技创新行动计划(14511106900)
程浩宇(1990-),男,复旦大学计算机科学技术学院,上海视频技术与系统工程研究中心,硕士研究生,研究方向:机器学习和计算机视觉,上海,201203
郑莹斌(1985-),男,SAP中国研究院,研究员,博士,研究方向:机器学习和计算机视觉,上海,201203
蔡 烜(1980-),男,公安部第三研究所,助理研究员,博士,研究方向:机器学习,上海,201204
冯 瑞(1971-),男,复旦大学计算机科学技术学院,上海视频技术与系统工程研究中心,副教授,博士,研究方向:视频图像处理和计算机视觉,上海,201203
