带排斥关键字的空间关键字查询
2015-08-07屠川川
屠川川
带排斥关键字的空间关键字查询
屠川川
定义了一种新的空间关键字查询模式,即带排斥关键字的空间关键字查询,它在普通空间关键字查询基础上添加了排斥关键字(即不需要的关键字),提高的查询的灵活性并使得查询场景更贴近真实情形。为这种新的关键字查询模式设计了混合空间索引以加速查询处理。混合空间索引由二叉树和R-树组成(文中称之为BIR树),并设计了相应的查询剪枝算法以加速查询。实验证明在这种空间关键字查询模式下,BIR树有着相当高的查询效率。
关键字查询;空间索引;排斥关键字;IR-树;地理信息数据
0 引言
随着互联网的发展,越来越多的信息可以从网上获取,能够从这大量的数据中找到需要信息的搜索引擎变得越来越重要。在另一方面,越来越多的互联网服务商开始提供基于位置信息的服务,并且专注于地理信息的搜索引擎也已经有了很大的发展。传统的信息搜索引擎致力于在尽可能短的时间内返回用户所需要的准确的数据,与此类似,地理信息搜索引擎也把在尽可能短的时间内找到需要的数据作为目标。两者的结合,基于带关键字的地理信息查询的互联网服务已经得到初步的发展。普通的餐馆,酒店的查询仅仅到了地理信息搜索引擎,而现在互联网服务商能够提供给客户更多的选择,比如在查询餐馆的同时指定口味、人气、以及一系列针对个别客户的定制化信息,这些信息都需要用到传统的信息搜索引擎来完成。
但是,仅仅是将信息搜索引擎和地理信息搜索引擎简单的结合仍然无法很好地满足现实生活中的需求,因为,目前的查询模式只能够允许用户输入他们感兴趣的关键字。让我们看几个简单的例子,在外地旅游的时候预定旅馆是一个在互联网上被非常频繁使用的服务。通常可以指定旅馆的位置、价格、以及一些额外的信息如全天热水、无线网络、可以携带宠物等。在传统的空间关键字查询模式中,用户可以在指定地理位置之后选择一些自己需要的关键字,然后,服务器会根据这新信息为用户介绍一些合适的旅馆。但是,一些特殊的要求无法在这种查询模式中得到满足,比如某人对某些动物过敏,因此,不希望在允许携带宠物旅馆中居住,或者有些人不喜欢烟味,因此,不希望住在一个可以抽烟的旅馆。在传统的空间关键字查询模式中,由于用户无法输入他们不需要的关键字,因此,对于服务器返回的结果,他们需要挨个检查是否满足他们的特殊需求。因此,本文中提出了一种新的空间关键词查询模式,允许用户输入他不喜欢的关键字,并根据这新信息进一步精简返回给用户的查询结果列表,以节省用户挨个检查的时间。
定义1. 带排斥关键字的空间关键字查询是一个信息检索的问题。所有兴趣点以及它们包含的地理位置和关键字是这个问题的数据基础。两个关键字集合(Wl, Wd)以及一个地理位置p作为问题的输入,Wl代表用户需要的关键字,Wd代表用户不需要的关键字,p由经纬度表示。目的是找到距离p最近的一个或几个带有Wl中所有关键字并且不带任何一个Wd中关键字的兴趣点。
1 相关工作
在传统空间关键字查询领域已有很多的相关工作,大多数相关论文都使用这样一个问题模型,用户提交一个查询地点以及一组关键词,服务器在数据库中找出靠近查询地点并且满足用户提交关键词的一个或者一组查询目标。针对这个问题模型,一系列论文提出了大量的索引以及算法来优化查询效率。比如论文[1]中提出了一个结合了倒排文件(inverted file)和R*[2]树的索引结构以及一整套针对带关键词的空间查询的框架体系,作为这个领域最早的论文之一,整合多种索引的想法具有很大的启发性意义。论文[3]沿用了这个索引,并提出了更高效的查询算法。论文[4]和[5]为传统搜索引擎优化了算法,使得搜索带有地理信息标签的网页搜索成为可能。论文[6]提出了IR树索引,这也是本文提出索引结构参考的的一种高效的带关键字空间信息的索引结构。还提出了一种IR树的改进版本,DIR树,进一步优化了空间关键字查询的效率,由于这种索引是目前在这个领域比较高效并且有代表性的索引结构,因此本文中将它作为了对比算法。论文[7]扩展了IR树并为它设计了完整的查询框架。[8]提出了IR树的另一种优化,W-IR树。[9]提出了bR*树,一种将位图和R*树结合在一起的索引结构。论文[10]考虑到了关键词的分布,认为不同关键词被查询到的概率是不同的,这也是本文实验中作出的一个假设。论文[11]提出了一种完全基于倒排文件的索引结果(S2I),而没有用到R树等空间索引,并提出了对应的查询算法。空间信息和关键词信息的结合是一个很热门的研究方向,在这个领域还有很多相关工作,由于篇幅所限,很多相关工作无法在这里一一介绍。
2 对比算法
在这个部分我们将详细介绍一种名为DIR(document similarity enhanced inverted file R-tree)树的索引结构以及对于本文提出问题的搜索算法。因为,DIR树是一种在空间关键词搜索领域非常高效的索引结构,我们将使用它作为本文实验的对比算法。
DIR树作为IR树的一种拓展,是一种利用倒排文件(inverted file)索引带权值关键词信息,同时,利用R树的索引空间信息的混合数据结构。倒排文件是一种优化关键词查询的索引结构。一个倒排文件是由多个链表组成的,每个链表的表头是一个关键词,之后的每个链表结点是一个包含这个关键词的兴趣点,通过倒排文件,可以在O(1)得到时间内得到包含某个关键词的所有兴趣点。DIR树中使用的倒排文件进行了简化,一个R树结点,相应的倒排文件的每个关键字链表中只记录了该结点所包含的兴趣点中带有该关键词并且权值最大的兴趣点信息。本文将关键字查询的问题做了适当简化,去掉了关键字的权值,因为,在实验中使用的DIR树的倒排文件退化成了类似位图(bitmap)的结构。
DIR树的兴趣点插入以及结点分裂规则都和传统R树有着不同。在插入一个兴趣点时,普通R树会通过兴趣点的位置信息选择一个适合的叶子结点,而DIR树会同时考虑空间信息以及关键词信息,找出在空间上和文本相似度上都较高的叶子结点作为插入结点。R树结点的分裂同样会考虑到关键词信息。调整空间信息和关键词信息在DIR树中的比重,就可以适应各种应用场景。在DIR树上的搜索过程和传统R树非常类似,一个查询会从DIR树的根结点进入,并将所有可能满足条件的下层结点加入待查找队列。这里的条件包括空间位置以及关键词。空间位置可以通过每个结点的MBR来获得,关键词信息则是通过结点中的倒排文件获得。假设一个查询Q包含以下信息:经纬度坐标p(x,y),和关键词信息Wl(k1,k2,…,kn)以及Wd(k’1,k’2,…,k’m)。当访问到DIR树中的某个结点时,我们按照距离查询点从近到远依次检查它的每个孩子结点的倒排文件。如果倒排文件满足两个关键词集合(包含Wl中所有关键词并且不包含任意一个Wd中的关键词),则检查该结点是否为叶子结点,如果是叶子结点,直接返回作为结果。如果不是,则将它加入查询队列,并取出查询队列前端结点开始下一次迭代。
由于R树结点上的倒排文件只能记录该结点上出现过哪些关键词,并不能很好的代表结点上所有兴趣点,我们可以看一个例子:当访问到DIR树中某个结点N时,我们检查它的倒排文件,如果Wl中出现了倒排文件中没有的关键词,那么这个结点可以从待查找队列中去除,但是我们却不能根据Wd集合与倒排文件的关系将结点从候选中去除,因为即使倒排文件中包含了某个不需要的关键词,该结点中仍可能存在满足Wd集合条件的兴趣点。这会导致查询空间的变大,从而导致查询效率低下。
3 BIR树
在这个部分我们将详细介绍一种新的数据,二叉树与IR树的混合索引,该索引改进了IR树的结构,从而避免上面提出DIR树在处理Wd集合时的缺点,同时为关键词增加一个二叉树索引,进一步提高了带关键词空间查询的效率。本章节将会分为两部分,第一部分介绍BIR树的结构以及构建过程,第二部分介绍查询的处理过程。
3.1 BIR树结构
定义2. Binary R树(简称BIR树)是一棵基于一组关键词集合和(W)建立的平衡二叉树。第i层上所有结点Rs保证如下性质:Wi是W中第i个关键字,BIR树第i层上所有左结点中只存在包含Wi关键字的兴趣点,右结点中只存在不包含Wi关键字的兴趣点。二叉树一共k层,每一个叶子结点都是一棵改进后的IR树(将在后面详细介绍)。对于一个给定兴趣点以及一棵已经建立的BIR树,根据兴趣点包含关键字的信息,它会属于二叉树唯一一个叶子结点。一棵两层BIR树的简单例子,有两个关键词被索引在二叉树中如图1所示:
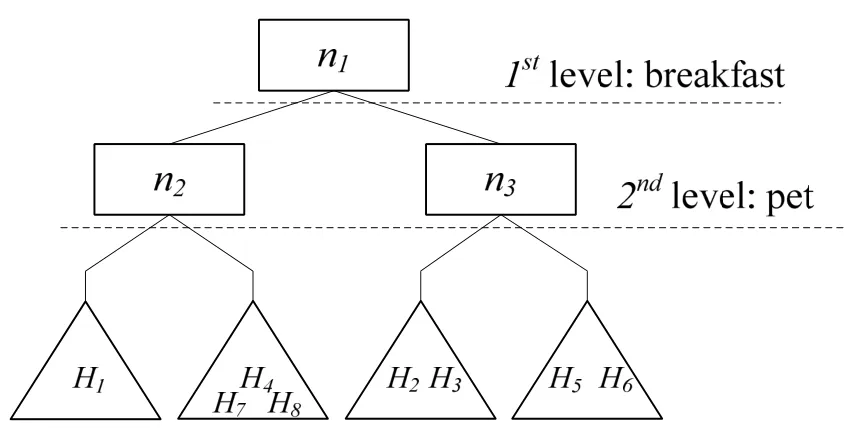
图1 BIR树例子
所有兴趣点最终落在二叉树的叶子结点内,并组成若干棵R树。由于二叉树的存储开销是和高度程指数增长的,因此,在二叉树中能够索引的关键词数量是很有限的。通常热门的关键词会被优先索引在二叉树中,使得二叉树索引能够在大多数查询中都起到剪枝的作用。
在二叉树的叶子结点时一系列的R树。为了能够处理关键字查询,我们对R树进行了一些改进。和IR树类似,我们首先为R树加上了两个倒排文件IF1和IF2。IF1与IR树上的相同,记录了每个结点中包含的兴趣点的关键词出现情况。IF2记录了该结点包含的兴趣点中共同拥有的关键词信息。也就是说,如果某个R树结点中包含了以下几个兴趣点(I1,I2,…,In),仅当某个关键词ki出现在所有这些兴趣点中时,这个倒排文件才会记录这个关键词。
由于我们在传统R树上添加了两个倒排文件,按照原来完全按空间位置的插入和结点分裂算法,这两个倒排文件的性能无法得到完全发挥。这是因为一般情况下,一个小区域内的兴趣点共同包含的兴趣点数量是很少的,反映在R树上就是,上层结点的IF1会非常大,而IF2则很可能是空集。这对提高查询剪枝的效率是非常不利的。因此我们需要改进R树的插入和结点分裂算法,以适应我们对R树结构的改进。
当一个兴趣点插入一棵BIR树时,首先会比较那些被二叉树索引的关键词,这个结果是确定的。因此我们只考虑将一个兴趣点插入R树的过程。首先我们重新需要定义一个兴趣点o到一个R树结点M的距离,并把关键字的信息也考虑在内。距离公式如下:
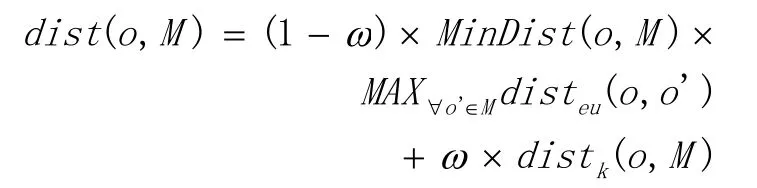
其中distk是兴趣点与R树结点关键词距离,定义如下
于晓明一行参观了法律服务所的党员活动室、接待大厅、人民调解委员会办公室等场所,听取了党建、法律援助、普法等工作情况的介绍,并与前来进行法律咨询的群众进行了亲切交流。

其中分子指兴趣点与M中所有关键词的并集大小,即兴趣点与IF1的并集。分母是兴趣点关键词和IF1的交集大小。这个距离越小表示插入兴趣点和R树结点内兴趣点关键词相似度越大。而距离公式中欧氏距离部分是o与M最短距离和M内距离o最远的兴趣点o’的距离的乘积,同样这个距离也随着o与M的距离增大而增大。将这两个距离加权平均之后得到综合距离,这个距离将欧氏距离和关键词相似度整合到一起,通过调整两边的权值,就可以应对各种情况。
完成了距离函数的定义,我们可以利用原有的R树的插入算法将一个兴趣点插入R树。当R树某个结点到达存储上限时,将会发生分裂。传统R树的分裂算法也是完全按照欧氏距离,将互相靠近的子结点分到同一边。但在这里我们会考虑关键词的信息。我们的目标是,在完成结点分裂之后,得到的两个新的结点中IF1尽可能小,而IF2尽可能大。因此在分裂时,考虑所有分裂可能性,并找出IF1尽可能小同时IF2尽可能大的结果,作为分裂结果。用重新定义的距离函数以及分裂算法得到的R树会与传统R树有较大区别,同一个结点中的兴趣点将会在关键词信息上更加相近,这样的结构非常符合本文提出的查询模式。
3.2 BIR树上的查询算法
完成了R树的构建,我们将在这节中介绍BIR树的查询算法。BIR树的查询主要分为两个步骤,第一步是在二叉树上进行查询,这一步将会得到一组叶子结点。也就是一组R树的根结点作为输出。第二步是在以这些结点为根的R树上进行搜索,利用一个最小堆,能够以很小的代价完成查询搜索。
对于一个查询,按照本文查询模式的定义,会有一个经纬度p(x,y),两个关键词集合Wl和Wd。首先来看第一步。由于二叉树只对几个最热门的关键词进行了索引,因此,我们也只需关注这些关键词有没有出现在Wl和Wd中即可。如果某个被索引关键词出现在Wl中,按照二叉树定义,索引该关键词的层的所有右结点可以从候选中删去,因为,根据定义该层中所有右结点包含的兴趣点都不会包含该关键词,与查询要求相反。同样,如果该关键词出现在Wd中,则所有左结点可以被删去。完成了二叉树上的查询之后,我们得到了一组R树根结点。将这些结点放入一个最小堆,键值为结点和查询点的最小距离。每次从最小堆中取出一个R树结点,检查它的每个孩子结点的两个倒排文件。如果满足,IF1中包含Wl中所有关键词并且IF2和Wd交集为空,则将它作为候选结点加入最小堆,否则直接抛弃。重复这个过程直到找到第一个(根据查询要求可能为第k个)兴趣点。将找到的兴趣点作为结果返回后一次查询就结束了。
4 实验部分
在这章节中,我们通过实验证明了本文提出的索引结构和查询算法的高效性。所有实验都只关注运行时间因为我们认为在内存容量越来越大的现在,I/O性能瓶颈已经可以由扩大内存的手段弥补。我们使用了伦敦的地图数据作为数据来源,一共包括34,162个兴趣点,以及1035个互相不同的关键词。由于建立二叉树时需要关键词的热门程度而我们又无法得到现实生活中各关键词的被查询频度,我们随机了每个关键词的被查询频率,并利用换这个频率建立了二叉树。之后随机生成查询时,关键词的选取仍然会按照这次随机得到的概率分布。我们按照分布为每个关键词分配了出现频率,并取了α=1作为基础值,也就是说大概有20%的关键词占据了80%的概率,我们认为这是符合现实生活中用户的查询习惯的,因为热门的关键词只占总关键词的少数但是会频繁得被查询。在一组实验中,我们将的值从0调整到1.33,来考察α值,也就是说查询关键词分布情况对我们提出的索引的影响。就像之前已经介绍过的,我们将DIR树作为了基准算法,除了对二叉树层数的实验,其他所有实验都是与DIR树做对比得到的。
4.1 实验结果图及说明
在实验结果图之前,我们先用一个表格说明实验的基本设定,如表1所示:

表1 实验参数设定
其中带下划线的参数设定是我们在实验中使用的默认值。实验结果图如图2所示:

图2 vs. Layer
每一幅图都对应了表格中一个参数。为了避免特殊情况的影响,提高实验的代表性,在图2中所有数据都是100个随机查询消耗时间的平均值。
首先,我们给出二叉树不同层数情况下查询效率的比较,如图3所示:

图3 实验结果
在图3中我们可以看到,随着二叉树层数的增加,查询时间先减少后增加,然后保持在了一个中等水平。这是因为,随着二叉树层数增加,更多热门关键词被索引,大多数查询在二叉树中就可以极大减少搜索空间,这对查询效率的提升是很明显的。但是二叉树的存储空间是指数增加的,而层数过多也会影响下层的R树结构,造成在R树上查询效率下降,因此,当层数到达4之后,查询效率并没有继续提高,而是下降然后保持在一个中等水平。可以预见,如果层数继续增加,查询效率反而会缓慢下降,因此,在其他实验中,我们使用三层二叉树为热门关键词做索引。
在图3中的4幅图分别是表1中剩下4个参数的实验结果图。在针对某一个参数进行研究时,我们保持剩下的参数都取默认值。从图3中我们可以看到,大多数情况下,BIR树的查询效率都要高于DIR树。在调整|Wl|大小的实验中,BIR树表现出了和DIR树相反的趋势,因为随着|Wl|的增大,BIR树的二叉树部分能够提供更好的剪枝效果,而两种索引的R树部分都会因为比较次数的增加而效率有所降低,最终得到图中的结果。在调整|Wd|的实验中,两种索引的效率都随着|Wd|增大而下降,因为,不需要的关键词对R树的查询效率影响很大,虽然BIR树在二叉树层可以利用Wd中的关键词进行剪枝,但是,仍然比不上R树上查询的效率损失。α的变化对DIR树的查询效率并没有明显的影响,而随着用户查询关键词的集中,DIR树的效率有很明显的提高,因为,越多的被查询关键词被二叉树索引到,那么DIR树的查询效率就能越高。最后,一幅是调整查询中需要兴趣点个数的实验图,从图中可以看到BIR树受到k的影响远远小于DIR树。
5 总结
本文提出了一种带关键词空间查询的新查询模式,提出了高效的索引结构和查询算法,并通过大量的实验证明了索引和算法的高效性。我们打算在路网数据中进一步研究这个新的查询模式,同时我们也将考虑将搜索引擎中常见的排序算法(如Page Rank)结合到这个查询中,使得查询返回的结果能够更贴合实际生活中的应用场景。
[1]Zhou Y., Xie X., Wang C., Gong Y., and Ma W.-Y.. Hybrid index structures for location-based web search [J].In CIKM, ACM, 2005:155-162.
[2]Beckmann N., Kriegel H.-P., Schneider R., and Seeger B.. The R*-tree: an efficient and robust access method for points and rectangles [M].ACM, 1990(19).
[3]Hariharan R., Hore B., Li C., and Mehrotra S.. Processing spatial-keyword (sk) queries. geographic information retrieval (gir) systems [C].In SSDBM. IEEE, 2007.
[4]Chen Y.-Y., Suel T., and Markowetz A.. Efficient query processing in geographic web search engines [C]. In SIGMOD. ACM, 2006:277-288.
[5]Cong G., Jensen C. S., and Wu D.. Efficient retrieval of the top-k most relevant spatial web objects [J]. VLDB, 2009,2(1):337-348.
[6]Wu D., Cong G., and Jensen C. S.. A framework for efficient spatial web object retrieval [J]. VLDBJ, 2012,21(6):797-822.
[7]Wu D., Yiu M. L., Cong G., and Jensen C. S.. Joint top-k spatial keyword query processing [J]. IEEE TKDE, 2012,24(10):1889-1903.
[8]Zhang D., Chee Y. M., A. Mondal, A. Tung, and M.Kitsuregawa. Keyword search in spatial databases:Towards searching by document [C]. In ICDE,IEEE,2009: 688-699.
[9]G¨obel R., Henrich A., Niemann R., and Blank D.. A hybrid index structure for geo-textual searches[C]. CIKM, ACM, 2009:1625-1628.
[10]Rocha-Junior J. B., Gkorgkas O., Jonassen S., and Nørv°ag K.. Efficient processing of top-k spatial keyword queries. In Advances in Spatial and Temporal Databases [C].Springer, 2011: 205-222.
[11]M. Christoforaki, J. He, C. Dimopoulos, A. Markowetz, and T. Suel. Text vs. space: efficient geo-search query processing. CIKM [J].ACM, 2011:423-432.
Exclusive Spatial Keyword Query
Tu Chuanchuan
(Fudan University, Shanghai200433, China)
This paper identifies a new mode of spatial keyword query, which is the spatial keyword query with keyword exclusion. It adds keyword exclusion (the keywords which are not essential) on basis of the normal spatial keyword query, so as to improve the querying flexibility and make the querying scenario draw to the real-world situation. The paper desires a hybrid space index for this new mode to accelerate the query process. The hybrid space index is made up of binary tree and R tree (called as BIR tree in the paper), it meanwhile desires relevant query Alpha-Beta pruning to boost the query. The experiment demonstrates that BIR tree is high efficiency under this spatial keyword query mode.
earch; Spatial Index; Exclude Keyword; IR-tree; Geo-information
TP393
A
2015.02.02)
1007-757X(2015)04-0019-04
屠川川(1989-),男,复旦大学,硕士研究生,研究方向:空间数据库,上海,200433
