基于分类的协同过滤图书推荐系统应用研究
2015-04-16陈泽波
陈泽波
(广州工程技术职业学院信息工程系,广东 广州 510075)
1 引言
协同过滤推荐系统是电子商务网站普遍运用的技术,主要目的是为了吸引顾客增加销售额。将协同过滤应用于图书馆日常管理工作中,目的是希望通过推荐系统推荐给读者其感兴趣的图书和文献,帮助读者更好地使用图书馆资源,同时也能提高图书馆馆藏资源的利用率。在原有研究的基础上提出一种改进的推荐算法——基于分类的协同过滤算法,解决了新读者的初始评分问题,根据读者的借阅历史对读者进行分类,结合相关影响因子的分析,改进读者相似度的计算公式,可以有效解决协同过滤推荐系统存在的冷启动及系统扩展性问题。
2 协同过滤推荐系统
2.1 协同过滤推荐系统的原理
协同过滤系统(Collaborative Filtering)也有学者称为“协同推荐系统(Collaborative Recommendation)”。系统假设具有相似兴趣特征的用户将会采用相似的行为。系统的原理是通过用户的注册信息、历史记录来提取用户的行为特征,接着根据这些特征在用户群中寻找相似邻居,最后依据相似邻居的借阅行为向该用户进行推荐。协同过滤系统是最早,也是目前得到最广泛应用的推荐系统。
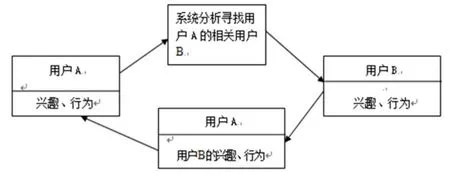
图1 协同推荐原理示意图
在协同过滤推荐系统中,用户对产品的评分通过计算近邻用户对其评分而得到。对于近邻用户的计算,协同过滤推荐系统采用了很多方法来计算。这些算法中,大都基于用户对共同喜爱产品的评价。其中,最常用的方法是夹角余弦方法和Person相关性。根据算法是否需要学习已有数据,可以分为基于近邻和基于模型两类算法。
基于近邻的算法利用用户之前的评分数据,对用户未评价的对象给出一个平均评分。基于模型的算法利用收集用户的打分数据进行学习并构建用户行为模型,然后对某个产品进行预测打分。
2.2 协同过滤推荐系统的优缺点
协同过滤推荐系统的优点是不依赖于推荐对象本身的内容,能够推荐多种介质,甚至包括虚拟对象。同时,协同过滤推荐的个性符合度较高,而且还可以帮助用户发现新的兴趣。缺点是冷启动问题,即对于新产品、新用户,系统得不到产品所获得的评价,也得不到新用户的兴趣爱好、行为记录,因此新产品得不到推荐,新用户无法获得满意的推荐产品。同时,随着用户数量的增加、产品的增加导致计算量过大,信息过滤的效率不高。因此,协同过滤推荐系统适用于用户规模相对稳定、产品数量相对固定的系统。
2.3 协同过滤推荐系统有助于充分开发图书馆资源
图书馆的建设不应该仅考虑不断地扩充图书文献资源,被动地等待读者自己进行选择,而应该以读者为中心,整合各种信息资源和手段,主动为读者提供信息服务,这样既有利于帮助读者找到感兴趣的图书文献,又能大大提升图书馆各类资源的利用率。因此,构建协同过滤图书推荐系统是十分必要的。
3 基于分类的协同过滤算法
读者由于专业的限制、兴趣的导向,往往更多地关注于某一个或几个领域,对该领域内的图书加以评论,而对其它领域内的图书很少问津。据此行为特征,将图书分成若干个不同类型,只对读者感兴趣的一个或几个类别的图书由读者进行比较过滤推荐。这样,可以大大减少参与推荐的图书数目和读者数目,从而可以有效地克服数据稀疏性和系统可扩展性的问题。
3.1 图书的初始评分值问题
由于图书文献数量巨大,不是每本图书都有机会得到读者的评分。同时,每天都有新书经加工后进入数据库,这些新书无法获得读者的评价,导致数据稀疏性问题。这里采取图书的初始评分法来解决这一问题。即在新书进行编目和分类加工时,给新书一个初始评分,以解决数据稀疏性问题。
而对于系统已保存的大量未获评价的图书,在推荐系统实施之前,可以由系统主动赋予分值。根据图书的流通次数、流通频率、借阅时长,系统计算出一个推荐分值。如公式1所示:

其中,v0表示评分的基数,可以设定为-0.5;n表示近两年的流通次数,当n>10时,n/10取值1;t表示平均借阅时长,单位为天,当t>20时,t/20取值1。
通过以上两步举措,可以保证在推荐系统实施之前,所有推荐对象图书都可以获得一个初始评分。
3.2 图书和读者的分类
利用《中图法》,对待推荐的图书进行分类。这里的图书分类不同于著录工作中的分类,无需进行细致的类目分析,只须根据图书的分类号将其纳入相应的二级类目中即可。一本图书在分类时可能不仅仅归属于某一类目,有时会同属于某两类或多个类目。
根据读者评价过的图书,判断这些图书的类别,可以进一步把读者划分在某一类或某几类中。表1列出了已经分类的读者列表,从表中可以判断读者所属类别。
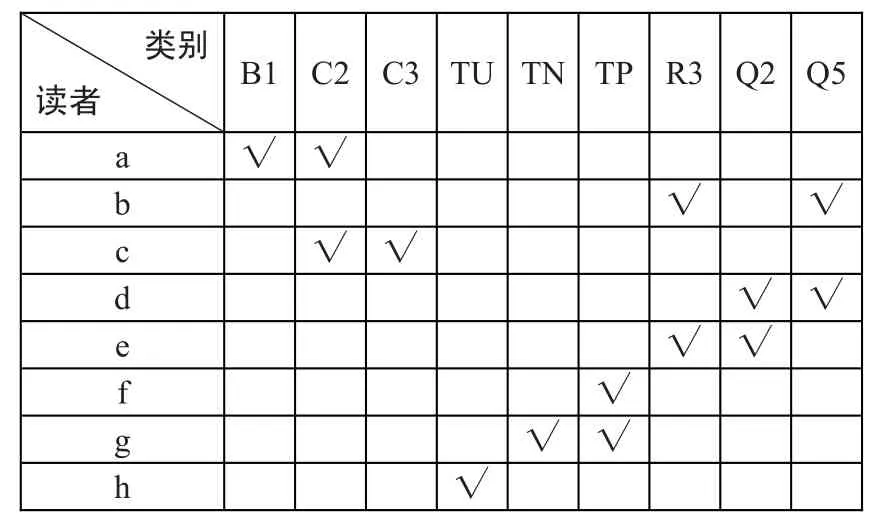
表1 读者分类表
表2是从借阅数据中抽取的部分信息,根据读者评价过的图书、喜爱的图书,来判断读者的分类。
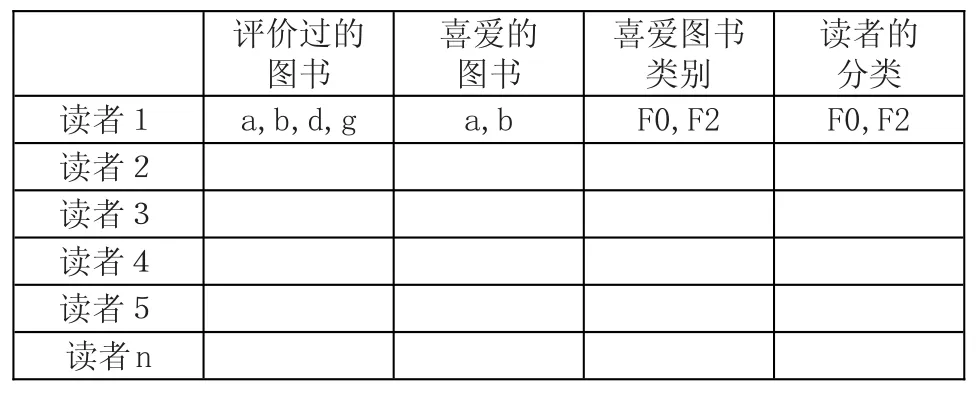
表2 读者评价图书分类表
3.3 读者相似度的影响因子
在现实情况下,读者的身份、职称、年龄等不一而同;有的读者评分时偏向于积极评价,因此分值偏高,有的读者评分时偏向于审慎评价,因此分值偏低;一些读者给出的评价比较公正客观,而一些读者给出的评价随意性较大。不同读者给出的评分值对其他读者的影响度是不同的,比如研究生导师评价较高的图书显然会对其研究生有重要推荐价值。可见,读者的推荐能力是不同的。
有鉴于此,对读者的推荐能力进行加权处理,以便正确反映读者的推荐能力,提高推荐的精确度。
(1)读者身份
按照常理,本科生、研究生、讲师、副教授、教授对某专业图书的推荐能力是逐渐提高的。因为他们对某专业的研究时间、科研水平也是逐渐提高的。所以,读者相似度的第一个影响因子w1用读者的身份来表示。

表3 读者身份的加权系数
w1表示读者身份的加权系数,k1,k2,k3,k4逐渐提高,教授的加权系数为1,表示教授的影响力最大,推荐能力最强。
(2)评价过的图书数量
当读者对某一领域内的图书大量阅读并给出评价,说明该读者在此领域的研究时间增加、知识掌握全面、经验值提高,给出的评价也更具有影响力。因此,用读者评价过的图书数量作为读者相似度的第二个影响因子w2。

(3)评价的准确度
当一本图书被较多的读者借阅后,得到较多评价时,它会有一个平均评分值。而这个平均评分值也是最接近该图书的真实评分。这样,当一位读者对图书的评分越接近平均评分值,说明该读者对图书评价的准确度越高,其推荐力也越强。因此,评价的准确度可以作为读者相似度的第三个影响因子w3。

其中,i表示读者评价过的某本图书,B表示读者评价过的图书的集合,vi表示读者对图书i的评分值,-vi表示i获得的平均评分值,Max和Min分别表示i所获得的最大评分值和最小评分值,n表示读者评价过的图书数量。
综上所述,影响读者相似度的因子可以用如下公式表示:

3.4 算法流程
(1)图书和读者的分类
按照《中图法》的分类方法,以二级类目为不同的类别种类,将图书分别划分到所属类别。对于属于交叉学科的图书,将其分别归类于同属的类别。
对于读者的分类,可以依据读者的评分来进行划分。读者评分值高、评价数多的几种图书类别通常代表了读者的兴趣爱好,可将读者归入相应的类别。而读者评分值低、评价数少的类别基本不在读者的兴趣范围,读者不属于这些类别,对于这些类别的图书不予推荐。读者由于专业、兴趣和时间的限制,往往固定于某几个知识领域的图书,因此同一读者的分类以2-3种为好。过多的分类会造成运算量大,推荐精确度低等问题。
确定了目标读者a的所属类别后,对该类别的读者进行分析,对于读者评分数小于阈值的读者予以屏蔽,留下有效读者。
(2)相似度的计算
在基于分类的协同过滤算法中,某一类别中的图书之间相关性很强,读者对某类图书的评价等价于读者对该类图书的评价总和,即

其中,va,k表示读者a对某一类别ck的评价,j表示类别ck中的某一种图书,va,j表示读者a对图书j的评价。
如果某本图书同时属于多个类别,那么对该类别的评价则应进行加权计算,如公式6所示:

其中,pj,k表示图书j属于图书分类ck的概率,其满足即图书j分属各个类别的概率之和应为1。
读者之间的相似度计算采用皮尔逊相关系数算法计算。计算读者a、b的相似度如下:
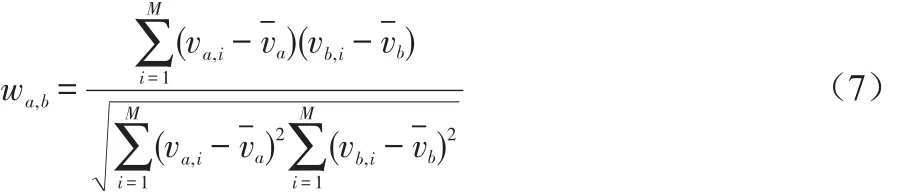
其中,M表示读者a,b共同评价过的图书类,-va,-vb分别代表a,b所评价过的图书类的平均评分值。根据相似度的大小,确定读者a的最近邻居集U。
(3)生成推荐结果
在读者a的最近邻居集所属的图书类别中,预测这些图书类对读者a的可能评分值。根据修正的余弦相似性(Adjusted Cosine)算法,考虑读者相似度的影响因子,对预测评分值提出如下公式:
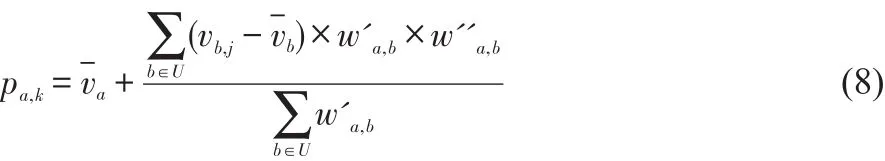
其中,pa,k表示读者a对图书类k的预测评分值,-va,-vb表示a,b对图书类的平均评分值,U表示a的最近邻居集,w'a,b表示读者a、b相似度的修正值,w''a,b表示a、b相似度的影响因子。
进一步的,得到a对图书类k的预测评分值pa,k之后,读者a对图书j的预测评分值可以通过公式9得到:

其中,wk表示图书j属于类k的概率,R表示j所属类的集合。通过计算得出读者a的预测评分值最大的前几项推荐图书,推荐给读者。
4 结语
伴随着互联网技术的广泛应用,现代图书馆正向数字型图书馆方向发展,加上原始的馆藏资源不断增加。面对如此巨大的信息资源,读者需要某种手段来帮助他们找寻对自己有用的信息。文章提出的基于分类的图书推荐系统,就是在这方面做努力,希望能帮助读者找出符合需求的馆藏,得到个性化的推荐服务。
[1]谢琳惠.推荐系统在高校数字图书馆的应用[J].现代情报,2006,(11):72-74.
[2]Resnick P,Iakovou N,Sushak M,et al.GroupLens:An open architecture for collaborative filtering of netnews.Proc 1994 Computer Supported Cooperative Work Conf[J].North Carolina:Chapel Hill,1994:175-186.
[3]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学研究进展,2009,19(1):1-15.
[4]曾庆辉,邱玉辉.一种基于协作过滤的电子图书推荐系统[J].计算机科学,2005,32(6):147-150.
[5]孙守义,王蔚.一种基于用户聚类的协同过滤个性化图书推荐系统[J].现代情报,2007,(11):139-142.
[6]Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C].Proc 10th International WWW Conf.New York:ACM Press,2001:285-295.
[7]Lee TQ,Park Y,Park YT.A time-based approach to effective recommender systems using implicit feedback[J].Expert Systems with Applications,2008,34(4):3055-3062.
[8]Chen YL,Cheng LC.A novel collaborative filtering approach for recommending ranked items[J].Expert Systems with Applications,2008,34(4):2396-2405.
[9]Yang MH,Gu ZM.Personalized recommendation based on partial similarity of interests[M].Advanced Data Mining and Applications Proceedings,2006,4093:509-516.
