基于关联规则的MBD 数据集定义研究与实现
2015-04-13王宏于勇印璞赵罡王伟
王宏,于勇 ,印璞,赵罡,3,王伟
(1.北京航空航天大学 机械工程及自动化学院,北京100191; 2.中国空间技术研究院 通信卫星事业部,北京100094;3.北京航空航天大学 北京市高效绿色数控加工工艺及装备工程技术研究中心,北京100191)
随着数字化技术水平的不断提高,以航空航天为代表的大型装备制造业逐渐采用了基于模型定义(MBD)的全三维数字化设计制造方法[1].国内外针对MBD 技术的应用进行大量研究,文献[2]在波音MBD 应用技术基础上,详细阐述了基于模型定义的技术体系框架以及基本的定义方法和数据组织原则,文献[3]则对MBD 标注信息表达及多视图过滤做了大量研究.这些研究为MBD 技术的应用和推广起到了重要的作用,MBD 数据集也逐渐成为产品研制过程中数据传递的唯一依据[2].然而,在实际应用过程中,随着时间积累,企业构建的MBD 数据集数目呈爆炸性增长,这些数据集是大量的设计人员智慧和知识的结晶,如何获取历史数据集中有用的知识和经验是每一个企业迫切需要解决的问题.
对于产品研制过程中知识的发现、存储、共享和推荐过程有很多专家和学者进行了大量的研究.在MBD 定义过程中,也引入了相关的理论,其中,文献[4]阐述一种通过构建本体知识库对MBD 数据集进行分类管理方法.文献[5]则进一步提出了基于模型定义的工艺知识表示方法及工艺决策方法.然而这些知识的获取方法大多是针对已知的、显式的知识进行处理,而针对隐含的、先前未知的经验和规则的获取大多通过专家系统通过集成研讨厅的方式进行提取[6],并且大多停留在理论阶段,工程的可用性不好.本文则针对MBD 数据集中工程注释信息进行结构化管理,通过统一编码,利用关联规则挖掘的方法分析MBD构建历史记录中工程注释信息,从而得到工程注释间隐含的、对决策有潜在价值的关联关系,实现对MBD 数据集定义过程中工程注释信息的推荐.
1 基本概念
1.1 基于模型定义
基于模型定义是指用集成的三维实体模型来完整表达产品定义的方法,是将原来定义在二维图纸上的几何形状、尺寸与公差以及工艺等产品信息,集成定义在三维实体模型中[7].由于MBD技术要求使用三维实体模型作为生产制造过程中的唯一依据,这样就要求产品数字化定义信息必须按照MBD 技术标准进行分类组织和管理,来满足产品研制过程中的各个阶段对数据的需求.一个完整的MBD 数据集应该包括产品的三维几何信息、设计参考、尺寸、公差和工艺等信息,图1所示为完整MBD 数据集应包含的信息及其组织结构.
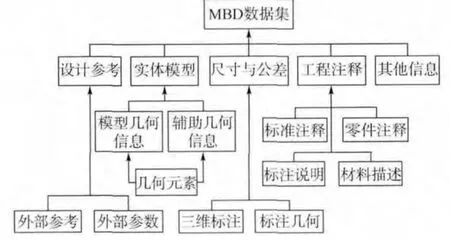
图1 MBD 数据集组成元素Fig.1 Components of MBD dataset
MBD 数据集中包含了产品研制过程中大量的工艺、制造和检验信息,因此,MBD 数据集中相关的非几何信息必须按照一定的格式编辑,并进行合理的存储管理,以便后续的数字化制造系统无需人工干预就能够有效读取和识别这些工程注释信息[8].因此,由计算机对所有工程注释项统一编码和发布.经计算机发布的单条工程注释被称为工程注释项.如表1 所示,工程注释项主要由“编码”、“标注内容”和“URL”构成.其中,“编码”具有唯一性,以便工程注释项被不同的数字化系统识别;“标注内容”则是对工程注释项的简要描述信息;“URL”则连接产品研制过程中相关标准和规范,或者该工程注释项的详细要求信息,表明工程注释项来源和依据.

表1 工程注释项Table 1 Engineering note item
1.2 关联规则基本原理
Agrawal 等[9]于1993 年首先提出了挖掘顾客交易数据库中项集间的关联规则问题,此后人们对关联规则的挖掘进行了大量研究,其核心都是基于频集理论的递推方法.设I={i1,i2,…,in}是所有项的集合.给定一个事务数据库D,其中的每一个事务T 是项集I 中一些元素的集合,在事务数据库中相当于历史数据记录,即T⊆I.一条关联规则就是形如A ⇒B 的蕴含式,其中A ⊆I,B⊆I,并且A∩B=∅,其支持度Ssup和置信度Cconf表示为:Ssup(A)=P(A);Cconf(A⇒B)=P(B|A).对于同时满足最小支持度(Smin_sup)和最小置信度(Cmin_conf)的关联规则,就是可以作为知识输出的强关联规则[10].
生成频繁项集是关联规则挖掘的第一步,在很大程度上决定着整体的挖掘效率[11].它通过计算事务数据库中各种项集组合的最小支持度,判断是否为频繁项集.一旦从数据库中找出所有频繁项集,则可以从频繁项集中提取关联规则,通过设置最小置信度的约束,进而获取强关联规则.
在MBD 数据集定义过程中,所有项的集合I对应于企业标准管理系统中所有的工程注释项.事务数据库D 对应产品研制过程中MBD 数据集创建的所有历史记录,记录了MBD 数据集代号及引用的工程注释项编码,如表2 所示,每一条历史记录都构成事务数据库中的一个事务,MBD 数据集代号作为该事务的唯一事务码.
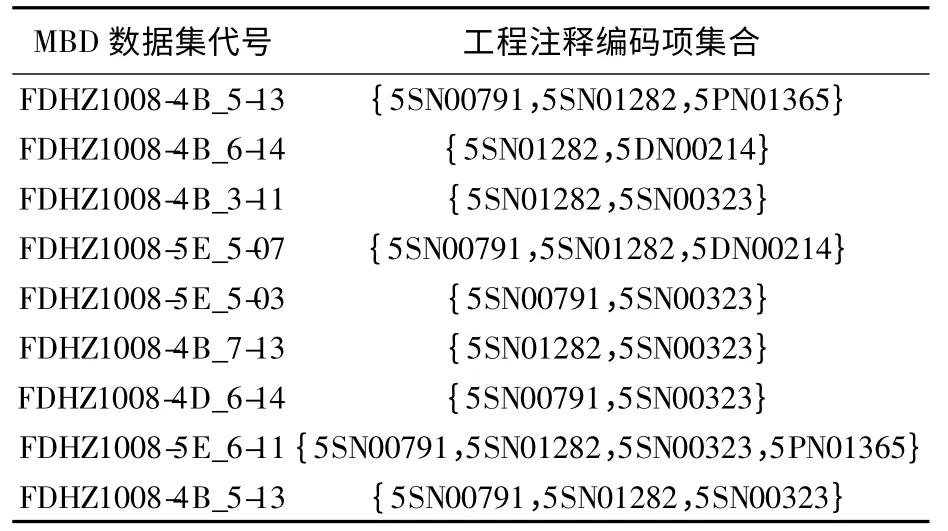
表2 MBD 数据集构建历史记录Table 2 Created history record of MBD dataset
2 标准注释项关联规则挖掘
2.1 频繁项集的生成
挖掘频繁项集的经典算法是Apriori 算法和Frequent Pattern-growth (FP-growth)算 法.由 于Apriori 算法在生成频繁项集前需要对数据库进行多次扫描,同时产生大量的候选频繁集,导致Apriori 算法时间和空间复杂度较大[12].由此,Han[13]提出了FP-Growth 算法.FP-Growth 算法只需要扫描2 次数据库:第1 次扫描数据库,得到一维频繁项集;第2 次扫描数据库,利用一维频繁项集过滤数据库中的非频繁项,同时生成FP 树.由于FP 树蕴涵了所有的频繁项集,其后的频繁项集的挖掘只需要在FP 树上进行.本文采用FP-growth算法,其基本思路[14]为:
1)对事务数据库进行第1 遍扫描,利用数据库中的事务集构造一棵频繁模式树(Frequent Pattern-tree,FP-tree).
2)将FP-tree 分化成一些条件模式基,即包含FP-Tree 中与后缀模式一起出现的前缀路径的集合,然后在对这些条件模式基重复以上过程,直到构造的新FP-tree 为空,或者只包含一条路径.
3)枚举所有可能组合并与此树的前缀连接即可得到频繁项集.
以表2 的MBD 数据集构建历史记录表为例使用FP-growth 算法进行关联规则挖掘.首先,对事务数据进行第1 次扫描,导出频繁1 项集和支持度计数,假设最小支持度计数为2.然后将频繁1 项集按支持度计数递减顺序排序,结果集记为L.于是,就有 L = {{5SN01282:7 },{5SN00791:6 },{5SN00323:6},{5DN00214:2},{5PN01365:2}}.
然后,创建频繁模式树FP-tree.首先创建树的根节点,用“Null”标记.接着第2 次扫描事务数据库.每个事务数据中的项按L 中支持度计数排列次序进行重新排序,然后并对每一个事务创建一个分支.例如扫描第1 条事务数据“FDHZ1008-4B_5-13:{5SN00791,5SN01282,5PN01365}”按L中支持度计数排序后可表示为“{5SN01282,5SN00791,5PN01365}”,使FP-tree 包含3 个节点的第1 个分支<5SN01282 >,<5SN00791 >,<5PN01365 >,其中“5SN01282”作为根的子女链接 到 根,“5SN00791”链 接 到“5SN01282”,“5PN01365”链接到“5SN00791”,依次类推,最终构建频繁模式树FP-tree,如图2 所示,左边表示表头项,树中相同项的节点要链接起来,其中每个节点数字代表对应项在该节点支持度计数.
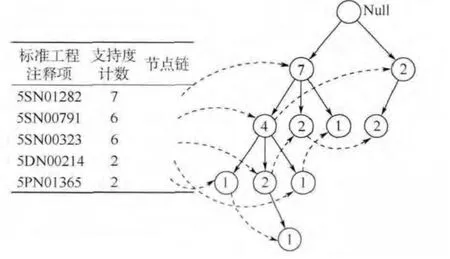
图2 频繁模式树Fig.2 Frequent pattern-tree
最后可通过对FP-tree 的挖掘获得频繁项集.首先在构造的整个事务数据库的频繁模式树上进行条件模式基的挖掘,纵向沿着表头向上,也就是按照表头中频繁1 项集支持度计数的升序方向,优先遍历头表,同时横向遍历其所对应的链表域,并对该链表域节点纵向向上遍历直到根结点停止,即得到一个序列,这个序列就是条件模式基.接着,对条件模式基继续建立局部FP-tree.直到生成只包含单个分支的FP-tree,通过枚举所有可能组合并与此树的前缀连接即可得到频繁项集.表3 给出通过挖掘条件模式基生成频繁项集.

表3 生成频繁项集Table 3 Generate frequent item set
2.2 提取强关联规则
当在事务数据中找出所有频繁项集,可通过最小置信度过滤出强关联规则.置信度可用式(1)[15]计算:
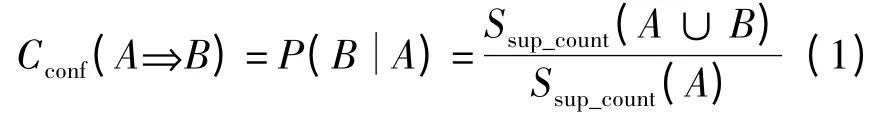
条件概率用项集支持度计数表示,其中,Ssup_count(A∪B)是包含项集A∪B 的事务数,而Ssup_count(A)是包含项集A 的事务数.
设定最小置信度,关联规则的生成为:
1)对于每个频繁项集L,产生L 的所有非空子集.
根据规则包含工程注释项的数目,对于关联规则A⇒B 可以是一对一、一对多、多对一和多对多的关系,由于在MBD 数据集工程注释项推荐中,各工程注释项相比电子商务商品项之间具有更强的逻辑性和规律性,为了提高推荐准确性和推荐效率,本文仅保留一对一和多对一的关联规则.对于表3中的频繁项集{5SN01282,5SN00791,5PN01365},提取关联规则如表4所示.

表4 关联规则提取Table 4 Extraction of association rules
若设定最小置信度为0.7,则关联规则{5PN01365,5SN00791 } ⇒ {5SN01282 },{5PN01365,5SN01282}⇒{5SN00791}为强关联规则.
2.3 推荐序列的生成
推荐是系统根据当前MBD 数据集已经添加的工程注释项,与规则库中规则前项进行匹配,推荐规则后项过程.对于关联规则A⇒B,关联规则前项为当前已经添加到MBD 数据集中的工程注释项的非空子集,关联规则后项为系统推荐工程注释项.因此,工程注释项推荐为根据当前MBD数据集已经添加的工程注释项的非空子集作为规则前项提取规则后项,进而根据规则置信度大小产生top-n 推荐序列的过程,算法步骤为:①对每个当前MBD 数据集u,设置一个候选推荐集Pu,并将候选推荐集Pu初始化为空.②对每个当前MBD 数据集u,搜索规则数据库,找出该MBD数据集支持的所有关联规则集合Ru,且关联规则前项的所有工程注释项出现在当前MBD 数据集u 已经添加的工程注释项中.③将关联规则集合Ru右部的所有工程注释项加入候选推荐集Pu.④从候选推荐集Pu删除当前MBD 数据集已经添加的工程注释项.⑤对候选推荐集Pu中所有候选项根据置信度值进行排序,如果一个项在多条关联规则中出现,则选择置信度值最高的关联规则作为排序标准.⑥从候选推荐集Pu中选择置信度最高的前N 个项作为推荐结果返回.
3 系统实现与应用
3.1 系统功能框架
基于关联规则的MBD 数据集定义系统主要由对工程注释进行管理的集成标准管理模块,离线关联规则挖掘模块、在线MBD 数据集定义模块组成.图3 为系统功能框架.
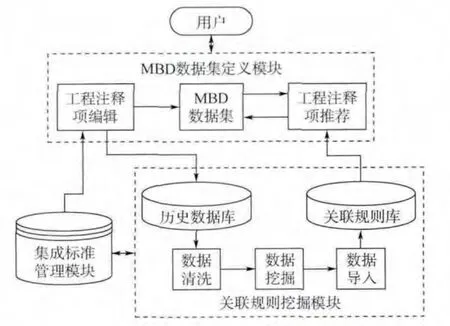
图3 MBD 数据集定义系统框架Fig.3 Frame of MBD dataset definition system
1)集成标准管理模块.
集成标准管理模块管理产品研制过程中所有设计、工艺、制造和检验的技术要求及相关标准,以及相关工程注释项,任何授权的单位和研制人员都能够进行检索,进而保证产品研制过程中不同研制单位生成MBD 数据集可以被数字化设备有效的读取和识别,也为实现工程注释项挖掘和推荐的前提.同时,在CATIA 中开发与集成标准管理模块的接口,使得设计人员在CATIA 可以调用集成标准管理模块中工程注释项,完成工程注释项编辑.集成标准管理模块主界面如图4所示.
2)关联规则挖掘模块
由于关联规则是以大量MBD 创建历史记录数据为基础进行分析,并且采用关联规则挖掘生成频繁项集的过程非常耗时,因此采用离线处理方法对历史记录进行挖掘.在长期使用过程中,企业会根据自身实际情况会对自己的产品研制体系进行变更、废止或更新一部分工程注释项,因此首先要对MBD 创建历史记录中数据进行清洗,去除一些无意义和噪声数据.然后再对清洗后的数据采用关联规则算法对处理过的数据进行挖掘,进而生成强关联规则.最后将获取的强关联规则导入关联规则数据库中.关联规则挖掘模块用户界面如图5 所示.
对于关联规则存储一般包含5 个部分:规则前项、规则后项、支持度、置信度和规则生成时间.工程注释项推荐过程,也是MBD 数据集中当前工程注释项与规则前项匹配,获取规则后项过程.表5为关联规则表结构.
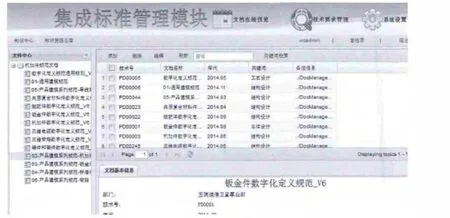
图4 集成标准管理模块主界面Fig.4 Main interface of integrated standard management module

图5 关联规则挖掘模块Fig.5 Association rule mining module

表5 关联规则表结构Table 5 Structure of association rules table
3)MBD 数据集定义模块.
MBD 数据集定义模块包含MBD 数据集工程注释项编辑及推荐功能.工程注释项编辑功能可以通过添加或删除相关工程注释信息完成MBD数据集构建.工程注释项推荐功能通过读取当前MBD 数据集已经添加的工程注释项,以当前MBD 数据集中工程注释项非空子集作为规则前项,以规则库中关联规则后项为推荐内容,生成推荐序列,进而显示在工程注释项编辑界面中.图6为系统工程注释项的推荐界面.
3.2 应用验证
本文将系统部署某航天企业,利用该企业现有MBD 构建历史记录为数据源,进行关联规则挖掘,获取强关联规则,并以某型号支架体MBD 数据集构建为例,对系统有效性进行验证.
1)关联规则挖掘.
统计该企业于此相关工程注释项共计134 条,在MBD 数据集构建历史记录中选择相关历史数据记录1 000 条,设置支持度为0.1,置信度为0.3,并以此1 000 条数据为基础进行关联规则挖掘.图7 为系统关联规则挖掘的结果报告.
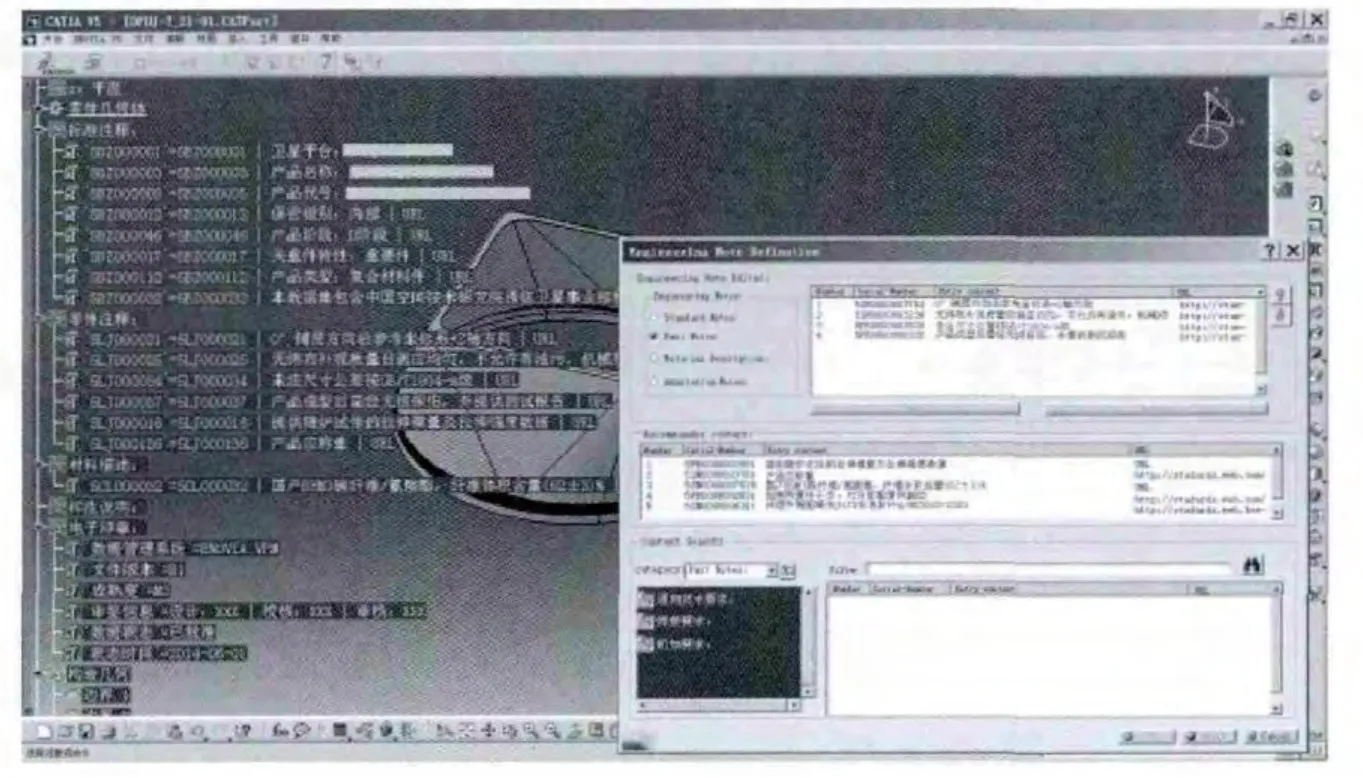
图6 工程注释项的推荐Fig.6 Recommendation of engineering note items

图7 关联规则挖掘结果报告Fig.7 Result report of association rule mining
2)工程注释项推荐.
该支架体主要由4 块蜂窝夹层复合材料板,2根支撑杆以及若干连接件组成.以该支架体为验证对象,对系统推荐有效性进行评价.设完成当前编辑中MBD 数据集一共需添加n 项工程注释项,在系统当前刷新中,数据集中已包含工程注释项数目为m,推荐给用户的工程注释项数目为a,其中包含有效推荐项数目为b,则当前系统推荐效率即有效推荐项占系统给出推荐项百分比η=a/b×100%,推荐准确率即系统当前刷新推荐有效项占数据集仍然缺少工程注释项百分比R =b/(n-m)×100%.该支架体零件MBD 数据集所包含工程注释项均在7 ~10 之间,取1 ~8 为数据统计区间,计算工程注释项推荐效率及其准确率,求平均值,分析结果统计如图8 所示.
如图8 可知,系统推荐的准确性随当前所编辑的MBD 数据集中包含的工程注释项的增加而增加.而当MBD 数据集的编辑即将完成,在系统每次推荐工程注释项数目不变条件下,包含有效项随之减少,推荐效率降低.
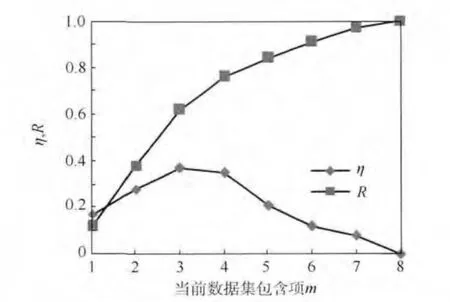
图8 推荐效率及准确率统计Fig.8 Statistics of recommendation efficiency and accuracy rate
4 结 论
本文从应用角度出发,通过对MBD 数据集创建过程的历史记录进行关联规则挖掘,获取工程注释项间潜在的关联关系,从而实现MBD 创建过程中相关工程注释项的推荐,实际应用中表明:
1)其相较于传统的MBD 定义方法,在选择注释项准确性及其效率上都有所提高,具有很好的工程可操作性.
2)本文所采用的单维单层次挖掘方法在准确性和效率上还有待于改善和提高,后续的研究工作可以尝试采用分层多维度关联挖掘的方法,以提高挖掘质量和效率.
此外,该方法不仅可以用于MBD 数据集的定义过程,也可以利用关联规则库中工程注释项间关联关系及其关联强度实现MBD 数据集正确性和完整性检查,为提高MBD 建模质量提供了另一种解决思路.
References)
[1] Alemanni M,Destefanis F,Vezzetti E.Model-based definition design in the product lifecycle management scenario[J].The International Journal of Advanced Manufacturing Technology,2011,52(1-4):1-14.
[2] 范玉青.基于模型定义技术及其实施[J].航空制造技术,2012(6):42-47.
Fan Y Q.Model based definition technology and its practices[J].Aeronautical Manufacturing Technology,2012(6):42-47(in Chinese).
[3] Camba J,Contero M,Johnson M,et al.Extended 3D annotations as a new mechanism to explicitly communicate geometric design intent and increase CAD model reusability[J].Computer-Aided Design,2014,57(1):61-73.
[4] Zhang H J,Zhang S,Yan Q.Study on the archives management system of aviation products based on MBD[J].Applied Mechanics and Materials,2013,321-324:2396-2399.
[5] Wan N,Mo R,Liu L,et al.New methods of creating MBD process model:On the basis of machining knowledge[J].Computers in Industry,2014,65(4):537-549.
[6] Park D H,Kim H K,Choi I Y,et al.A literature review and classification of recommender systems research[J].Expert Systems with Applications,2012,39(11):10059-10072.
[7] Clark B,Gerald B,David S,et al.Model based definition,AIAA-2010-3138[R].Reston:AIAA,2010.
[8] 冯国成,梁艳,于勇,等.基于模型定义的数据组织与系统实现[J].航空制造技术,2011(9):62-66.
Feng G C,Liang Y,Yu Y,et al.Dataorganization and system implementation of model based definition[J].Aeronautical Manufacturing Technology,2011(9):62-66(in Chinese).
[9] Agrawal R,Imieliński T,Swami A.Mining association rules between sets of items in large databases[C]∥Proceedings of the 1993 ACM SIGMOD.Washington,D.C.:ACM Press,1993:207-216.
[10] Bobadilla J,Ortega F,Hernando A,et al.Recommender systems survey[J].Knowledge-Based Systems,2013,46(1):109-132.
[11] 高建煌.个性化推荐系统技术与应用[D].合肥:中国科学技术大学,2010.
Gao J H.Technology and application of personalized recommender systems[D].Hefei:University of Science and Technology of China,2010(in Chinese).
[12] 鲍玉斌,王大玲,于戈.关联规则和聚类分析在个性化推荐中的应用[J].东北大学学报:自然科学版,2008,24(12):1149-1152.
Bao Y B,Wang D L,Yu G.Application of association rules and clustering analysis to personalized recommendation[J].Journal of Northeastern University:Natural Scienee,2008,24(12):1149-1152(in Chinese).
[13] Han J W.Miniing frequent patterns without candidate generation[C]∥Proceedings of the 2000 ACM SIGMOD Internal Conference on Management of Data.Washington,D.C.:ACM Press,2000:1-12.
[14] 莫同,褚伟杰,李伟平,等.一种基于扩展FP-TREE 的服务推荐方法[J].华中科技大学学报:自然科学版,2013,41(增刊Ⅱ):81-87.
Mo T,Zhu W J,Li W P,et al.A service recommended method based on extended FP-TREE[J].Journal of Huazhong University of Science and Technology:Natural Science Edition,2013,41(Supp1.Ⅱ):81-87(in Chinese).
[15] Lin W,Alvarez S A,Ruiz C.Efficient adaptive-support association rule mining for recommender systems[J].Data Mining and Knowledge Discovery,2002,6(1):83-105.
