基于倾向值加权的网络调查总体参数Horvitz-Thompson估计
2015-01-01牛成英孙秋碧
牛成英,孙秋碧
(福州大学 经济与管理学院,福建 福州350108)
一、引 言
随着互联网技术的发展和网络应用的普及,网络调查在市场调查、社会科学等领域的研究中得到越来越广泛的应用,许多专家学者对网络调查相关问题展开了深入研究。纵观国内外文献,关于网络调查的相关研究主要集中在网络调查应用、网络调查与传统调查的比较研究、影响网络调查回答率的因素研究以及网络调查中受访者隐私权保护等方面[1-5];也有专家学者对网络调查的设计、组织与实施过程进行了研究,对网络调查问卷及问题设计提出了科学建议,研究开发了实施网络调查的相关应用软件[6]。但是,关于网络调查统计推断理论研究的文献相对较少,有关网络调查统计推断的文献大多局限于与传统调查方法的对比研究,利用网络调查数据对目标总体特征的分析研究主要集中在调查数据的描述性统计方面[7]。由于网络调查是基于传统调查理论基础但又不完全等同于传统调查的一种调查研究方法,所以现有的在完全随机抽样方法下的传统抽样调查统计推断理论不再完全适合网络调查,故应结合网络调查特点,在传统调查统计推断理论基础上,研究建立一套严密的网络调查统计推断理论体系,为各领域利用网络调查进行问题研究的统计推断提供理论指导。
与传统抽样调查方法相比,网络调查的抽样方法主要包括:基于非概率抽样的网络调查和基于概率抽样的网络调查[8]215-232。基于非概率抽样的网络调查不再完全遵从随机化原则,使得该类网络调查统计推断的难度增大;基于概率抽样的网络调查中,由于被调查者自身因素的影响,使得该类网络调查的统计推断结果出现结构性偏差。近年来,倾向值统计分析方法在非随机化观测试验中被广泛应用[9][10]86-87。这种统计分析方法,将研究总体单元分为试验处理组和试验控制组,利用研究总体单元已有的辅助信息,即协变量(如个体特征或影响试验结果的各因素),估算被研究试验单元在协变量条件下进入试验处理组的条件概率,即倾向值。一方面,可以利用倾向值匹配方法,对试验处理组与控制组中倾向值相等或相近的单元进行匹配,对观测试验研究中影响试验结果的因素进行均衡,以此达到“事后随机化”的目的,进而降低观测试验结果中由于被研究单元非随机化分配引起的统计推断偏差;另一方面,利用倾向值加权方法,对试验处理组与控制组成员进行加权,从而使得它们能够更好地代表研究的目标总体。在网络调查实践中,通常在调查前或调查过程中可以获得与被调查指标相关的协变量,如在社会科学调查研究中与人有关的人口统计特征、在医学临床研究中患者具备的一些生理指标等。在网络调查统计推断中,基于这些协变量的倾向值分析方法,已被探索用来修正网络调查中可能产生的误差,降低由被调查者参与回答的倾向性而产生的样本结构性偏差的影响,提高总体参数统计推断的精度[10]105[11-12]。
本文研究以基于概率抽样的网络调查为基础,尝试将传统调查的统计推断与倾向值分析方法相结合,探索网络调查目标总体参数估计的无偏估计量和估计量方差来源,建立更加符合实际情况的网络调查统计推断方法,分析网络调查中影响统计推断结果的因素。由于网络调查中存在被调查单元无回答的现象,利用样本中回答单元观测值进行总体参数统计推断时,会改变样本单元的实际入样概率。为了控制样本单元入样概率不因无回答单元的存在而改变,以下分析均基于对网络调查样本缺失数据进行插补处理后的完整样本进行统计分析。
二、倾向值计算模型及方法
倾 向 值 分 析 方 法 (propensity score analysis method),是建立在反事实框架(counterfactual framework)理论基础上的一种统计分析方法,于1983年由统计学家Rosenbaum和Rubin首次提出,并对倾向值概念进行了界定[9]。倾向值分析方法主要用于观测研究中修正选择性偏差,也是观测研究中均衡组间偏倚的有效方法;主要目的是通过均衡组间多个混杂因素变量(协变量)来降低偏倚,实质是将多个协变量的影响因素用一个倾向指数来表示(相当于降低了协变量的维度),然后根据倾向值匹配方法对观测研究中处理组和控制组的组间单元进行匹配,对观测性数据的混杂因素进行类似随机化均衡处理。所谓反事实,就是指在原因不存在的情况下会发生的潜在结果或事件状态。比如在观测试验中,对于处理组(干预状态)成员而言,反事实就是处在控制组(控制状态)下的潜在结果;对于控制组(控制状态)成员而言,反事实就是处在处理组(干预状态)下的潜在结果[10]17-20。
因为网络调查样本中存在无回答单元,根据Rosenbaum和Rubin给出的倾向值定义,目标总体可划分为回答组和无回答组,所以可将倾向值分析方法引入网络调查研究中以修正总体参数的估计结果。
网络调查中,可将倾向值理解为:已知观测协变量向量为k维向量Xi=(xi1,xi2,…,xik),k≥1,i=1,2,…,N,在给定协变量Xi条件下,被调查者i(i=1,2,…,N)属于回答组的条件概率:
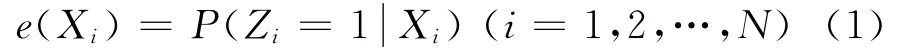
称为被调查者i参与回答的倾向值,其中Zi为分组变量,如果被调查者i属于回答组,则Zi=1;如果属于无回答组,则Zi=0。
假定分组变量Zi和协变量Xi相互独立,则:
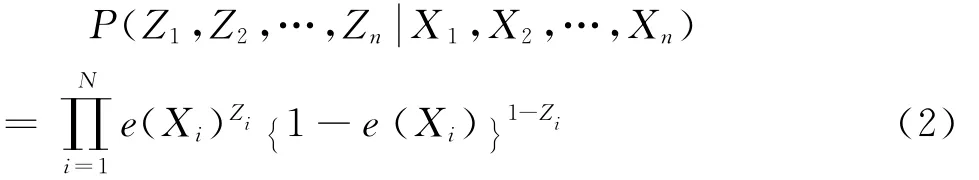
网络调查中,分组变量Zi和目标总体单元潜在观测值Yi在给定协变量Xi下是条件独立的,即,且对回答组和无回答组中的所有单元都存在一个非零回答概率,即0<,亦即,其中是目标总体单元i无回答的潜在观测值,是目标总体单元i回答的潜在观测值,i=1,2,…,N。当被调查单元i参与回答时,观测值Yi记为,否则,观测值Yi记为
实际应用中,倾向值e(Xi)是通过二分类变量的Logistic回归方法估计得到的。被调查者的倾向值可用二分类变量Logistic回归方法表达如下:
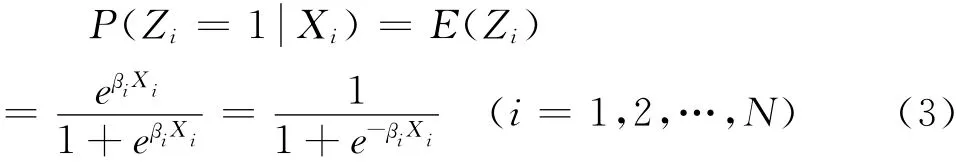
其中Zi为二分类状态,Xi为已知协变量向量,βi为向量回归参数。
式(3)是一个非线性模型,即Zi不是协变量Xi的线性函数,但是可以通过使用Logit函数将其转换成Xi的线性函数:

其中P为倾向值。
式(4)可以采用最大似然估计或普通最小二乘法(OSL)进行估计得到,但采用最大似然估计时一般很少使用解析方式,而是通过计算机数值程序迭代方法得到βi的估计值,进而估计得到倾向值e(Xi)的估计值。
三、基于倾向值加权的总体参数Horvitz-Thompson估计量构造
许多调查研究的统计推断中,为了尽量消除统计推断的偏差,采用了多种数据处理方法,例如针对人口统计特征差异,经常使用事后分层方法。这种方法以普查资料为参考,依据人口变量进行分层,然后进行加权调整,以降低无回答误差[13]。
同传统调查一样,网络调查数据收集过程中,由于较低的回答率或不完整回答而出现大量数据缺失。一方面,相对于传统调查中的面访式调查,由于调查者与被调查者缺乏双向互动,导致网络调查的缺失数据大大增加,极大地影响了基于网络调查数据统计推断的结果;另一方面,在网络调查中,由于参与调查的回答者相对于无回答者有更为自愿的倾向,这也会导致调查结果产生结构性偏差。
倾向值加权旨在对回答组和无回答组成员进行加权,从而使得它们能够更好地代表目标总体。下面,在对网络调查样本缺失数据进行插补处理后的完整样本基础上,应用倾向值加权的方法,调整被调查者参与调查的概率,然后构造目标总体参数的无偏估计量。
关于总体参数的估计通常主要关注总体均值、总体总值以及总体比例的估计,本文以总体均值的估计为例来构造总体参数的无偏估计量,其他总体参数的估计可以类推得到。
假设总体由回答组S1和无回答组S0组成,如果S1中的单元被抽中,就可以得到回答,即得到一个观测值;否则,如果S0中的单元被抽中,就无法得到回答,即出现数据缺失。N1为总体中回答组单元数,N0为总体中无回答组单元数,N为总体单元数,则N=N0+N1;文中大写字母与小写字母分别表示有关总体与样本的观测值,例如Y1,Y2,…,YN表示目标总体单元观测值,y1,y2,…,yn为样本单元观测值。
假设采用概率抽样方法从总体中抽取容量为n的简单随机样本,调查结果显示,回答单元为n1,无回答单元为n0,则n=n1+n0。令:

其中y0i在调查过程中没有直接获得,而是通过缺失值插补方法插补得到,记为,即为无回答单元真实观测值与插补值之间的偏差,假设。对网络调查中无回答单元的缺失数据进行插补后,即可得到一个无缺失数据的完整样本,利用该样本数据对总体参数进行统计推断,可降低网络调查中总体参数估计量的无回答误差。
类似于不等概率抽样Horvitz-Thompson估计量的构造[14]161-198,将权重定义为:
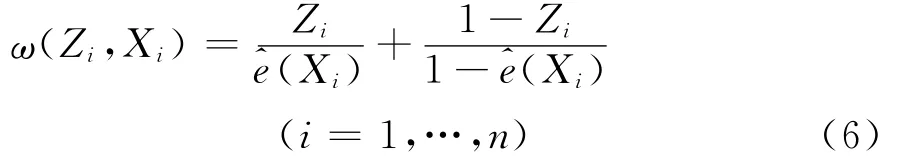
对总体均值参数进行估计时,如前所述,既要考虑抽样单元的入样概率,又要考虑抽样单元参与调查的倾向值。总体均值基于倾向值加权的Horvitz-Thompson估计量可表示为:

即:

证明:样本均值
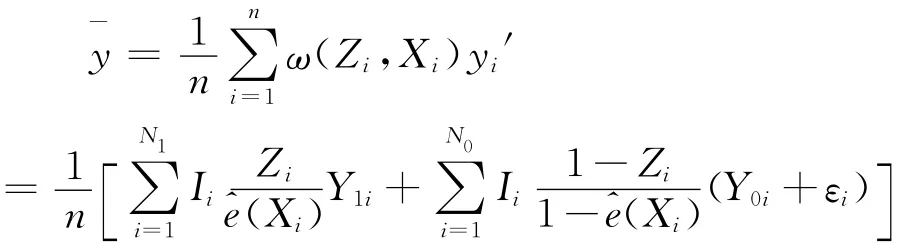
其中Ii为随机变量:

在采用无放回简单随机抽样方法时,调查单元i被选入样本时,,且当Z=1时,i;当Zi=0时,则[14]201:
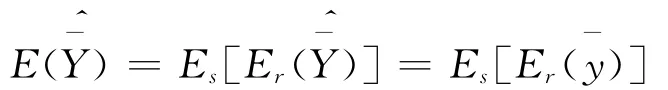

故基于倾向值加权的Horvitz-Thompson估计量是总体均值的无偏估计。
由此可见,在网络调查的总体参数估计中,由于受被调查单元的不同倾向值影响,统计推断中总体参数估计的实质已经从等概率抽样的参数估计转化为不等概率抽样的估计。因此,关于网络调查的总体参数估计,采用类似于不等概率抽样的Horvitz-Thompson估计量更为合理。
四、总体参数 Horvitz-Thompson估计量的方差
总体参数估计量的方差是从平均意义上说明参数估计量的差异状况,也是对抽样方案和估计方法进行评价的标准之一。类似于传统调查,利用网络调查数据进行参数估计时,估计量的方差一方面与抽样方法有关,另一方面与被调查单元的回答概率,即倾向值大小有关,则估计量的方差可以表示为[14]201:
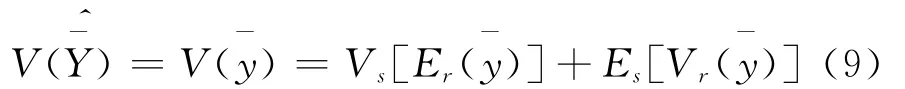
即:
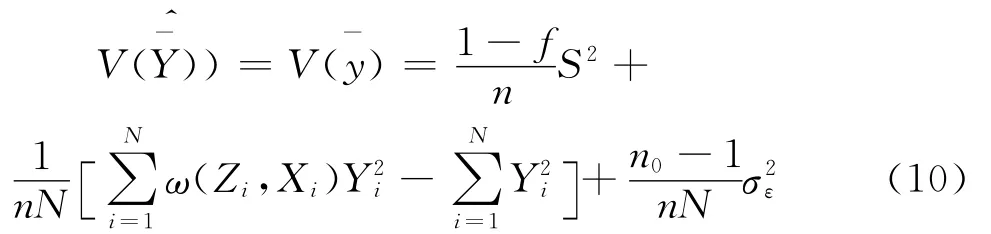
其中Vs,Es分别为随机抽样的方差和期望,Vr,Er分别为与回答概率有关的方差和期望。
证明:因为
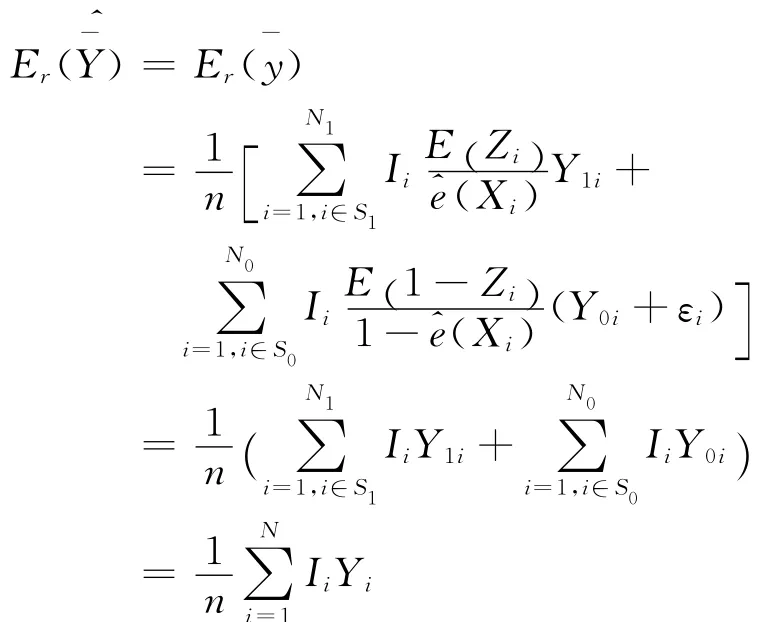
另一方面,由于样本单元Zi,Zj的取值相互独立,则Cov(Zi,Zj)=0,因此:
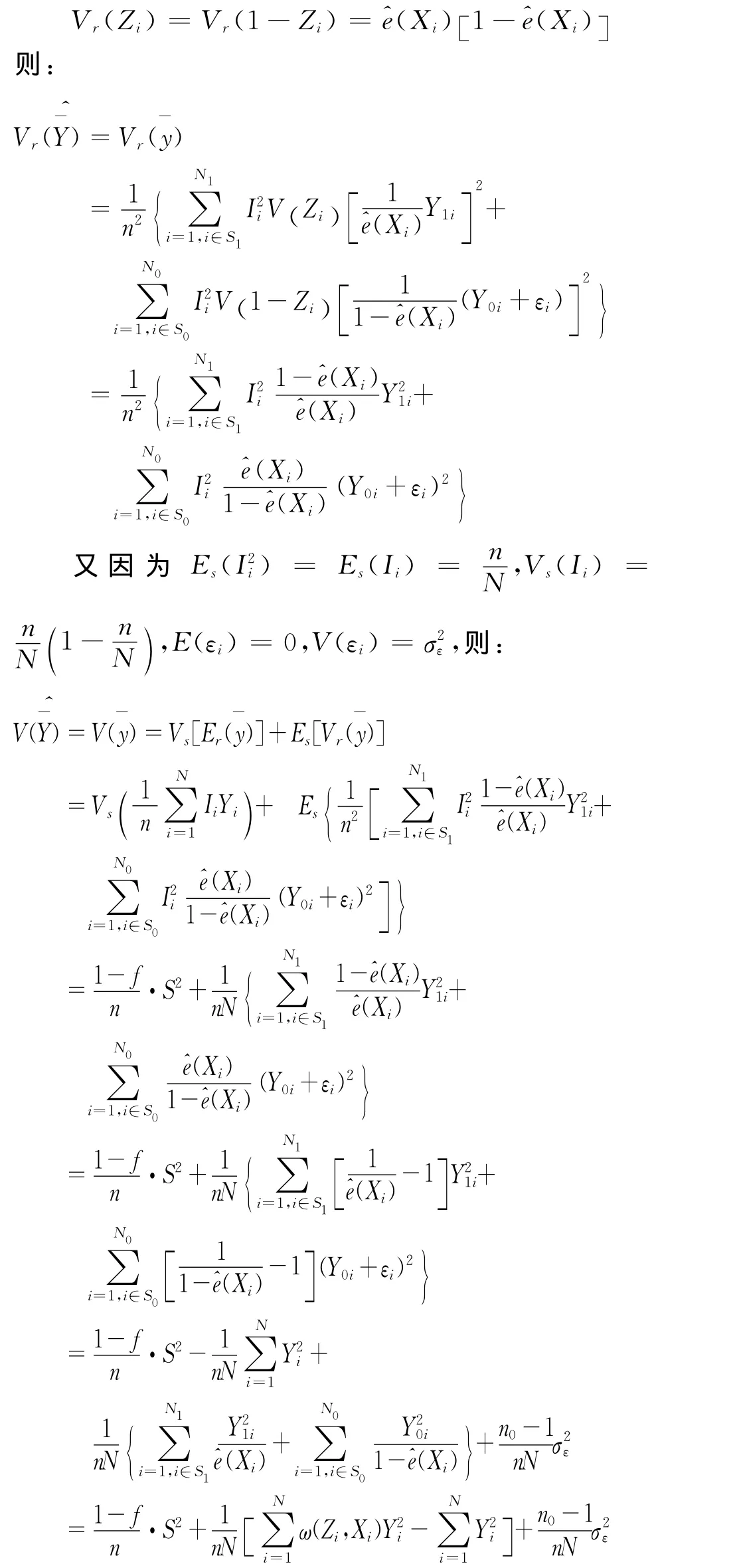

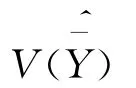
由以上分析可以看出,利用网络调查数据进行统计推断时,基于倾向值加权的总体参数Horvitz-Thompson估计量是一个无偏估计量。估计量方差的大小受抽样方式、抽样单元的回答概率以及插补数据的偏差等因素影响,事实上,这一结果更符合实际情况。
五、结 论
目前,尽管网络调查已在各类调查研究中广泛应用,但是利用网络调查数据对目标总体特征进行统计推断的问题还存在很多不确定性因素,有待于进一步深入讨论。网络调查研究中,要提高统计推断的可靠性、降低估计偏差,一方面要以传统抽样调查统计推断的理论方法为基础,另一方面要针对网络调查不同于传统调查的特征,建立符合网络调查的统计推断理论方法。对采用概率抽样进行的网络调查,可以充分利用目标总体已有的或可获得的辅助信息,设计网络调查抽样方法,估算样本单元回答概率,并通过加权修订相关影响因素,以提高总体参数估计的精度,降低估计偏差。
网络调查统计推断研究中,基于插补后的样本数据进行倾向值加权统计推断说明:1.用网络调查数据进行统计推断时,总体参数估计量的方差大小与目标总体单元间的变异程度密切相关,当目标总体单元间变异程度较小时,估计精度相对较高。2.可以充分利用已有或可获得的目标总体单元与调查结果相关的辅助信息,通过分析样本中回答单元和无回答单元的特征,选择最佳插补方法,降低因缺失数据插补而造成的偏差。3.利用目标总体单元与调查结果相关的辅助信息,估计样本单元回答概率,对样本观测值进行恰当地加权调整,可以提高总体参数估计精度和降低估计偏差。4.充分考虑影响统计推断结果的因素和产生估计误差的过程,有利于分析估计量偏差的来源。在调查过程中设计更为合理的抽样方法、采用激励方法提高被调查单元的回答概率等措施,可以提高网络调查数据质量和统计推断的可靠性。
[1] Gill Fenella J,Leslie Gavin D,Grech Carol,et al.Using a Web-based Survey Tool to Undertake a Delphi Study:Application for Nurse Education Research[J].Nurse Education Today,2013,33(11).
[2] 向蓉美.问卷调查方式的革新和比较[J].统计与信息论坛,2002,17(1).
[3] 于洪彦,黄晓治.书面调查和网络调查的区别——两种数据收集方法的比较[J].统计与信息论坛,2011,26(10).
[4] Weimiao Fan,Zheng Yan.Factors Affecting Response Rates of the Web Survey:A Systematic Review[J].Computers in Human Behavior,2010,26(2).
[5] Denniston Maxine M,Brener Nancy D,Kann Laura,et al.Comparison of Paper-and-pencil Versus Web Administration of the Youth Risk Behavior Survey (YRBS):Participation,Data Quality,and Perceived Privacy and Anonymity[J].Computers in Human Behavior,2010,26(5).
[6] Yi-Ching Wang,Ching-Mei Lee,Chih-Yin Lew-Ting,et al.Survey of Substance Use among High School Students in Taipei:Webbased Questionnaire Versus Paper-and-pencil Questionnaire[J].Journal of Adolescent Health,2005,37(4).
[7] Hsiu-Mei Huang.Do Print and Web Surveys Provide the Same Results?[J].Computers in Human Behavior,2006,22(3).
[8] 赵国栋.网络调查研究方法概论[M].北京:北京大学出版社,2013.
[9] Rosenbaum P R,Rubin D B.The Central Role of the Propensity Score in Observational Studies for Causal Effects[J].Biometrika,1983,70(1).
[10]郭申阳,马克·W.弗雷泽.倾向值分析:统计方法与应用[M].郭志刚,巫锡炜,等,译.重庆:重庆大学出版社,2012.
[11]Schonlau M,Zapert K.A Comparison between Responses from a Propensity-Weight Web Survey and an Identical RDD Survey[J].Social Science Computer Review,2003,21(10).
[12]Fan Li,Zaslavsky Alan M,Landrum Mary Beth.Propensity Score Weighting with Multilevel Data[J].Statistics in Medicine,2013,32(19).
[13]曾五一,汪彩玲,王菲.网络调查的误差及其处理[J].统计与信息论坛,2008,23(2).
[14]冯士雍,施锡铨.抽样调查——理论、方法与实践[M].上海:上海科学技术出版社,1996.
