基于多子群萤火虫算法的数据库查询优化
2014-04-03刘东
刘 东
LIU Dong
陕西理工学院 物理与电信工程学院,陕西 汉中 723001
School of Physics and Communication Engineering,Shaanxi University of Technology,Hanzhong,Shaanxi 723001,China
1 引言
随着数据库技术成熟和应用范围的扩大,出现了许多大规模数据库,而查询优化是提高数据库性能的关键技术之一,因此针对一个查询问题,如何找到一种最优查询计划至关重要,成为数据库研究中的重要课题[1-2]。
找到数据库的最优查询计划就是要构造一棵代价最小的多连接查询树,为此针对数据库查询优化问题,国内外学者从不同角度做了大量的工作,提出许多查询优化算法[3]。最传统的查询优化算法采用穷尽搜索算法或其他变形算法,当连接关系数目较小时,可以取得较好的查询效果,但现代数据库管理系统的查询连接数目通常很大,这类算法毫无用处,没有什么实际应用价值[4]。随后有学者提出动态规划算法解决数据库查询优化问题,但查询效率低,不能满足现代数据库查询要求[5]。大量研究表明,数据库查询优化包括了许多约束条件,实质上是一个组合优化问题,群智能算法具有搜索速度快的优点,因此一些学者将群智能算法应用于数据库查询优化问题的求解中[5]。文献[6]等提出一种基于遗传算法的数据库查询优化方法,采用遗传算法对查询执行计划代价进行求解,取得了不错的效果。Kumar等人根据查询数据关联度之间的关系,提出一种基于遗传算法的数据库查询优化方法[7]。遗传算法虽然具有寻优能力强的优点,但是对于不同问题需要设置不同的遗传算子,存在局部搜索能力差等不足[8]。为此,一些学者基于组合优势,如Zhou对遗传算法进行改进,但对于不同问题,需要进行相应的改进,通用性差[9]。Po-Han Chen等将模拟退火算法引入遗传算法的变异过程中,获得比遗传算法更优的数据库查询优化效果,但是存在寻优结果不稳定等缺陷[10]。林桂亚等利用蚁群算法对数据库查询优化问题进行求解,取得了不错的效果[11]。萤火虫群算法(Firefly Algorithm,FA)是一种模拟萤火虫发光行为的群智能优化算法,多个萤火虫被随机散布于整个搜索空间内,所有萤火虫都具有一个由被优化问题所决定的适应度值,对应于该萤火虫的荧光亮度。然后每个萤火虫个体都在其视觉范围内追随荧光亮度更强的萤火虫飞行,经过多次群体运动后,所有个体将聚集在荧光亮度最强的萤火虫附近,完成最终寻优,为解决数据库查询优化问题提供了一种新的研究方法[12]。
针对数据库查询优化效率低的难题,提出一种多子群萤火虫群算法(MG-FA),并将其应用于数据库查询优化问题求解中。首先将数据库查询计划左深树看作一个萤火虫,然后通过萤火虫相互学习机制和信息交流找到数据库查询最优方案,并通过仿真实验测试其性能。
2 多子群萤火虫优化算法
萤火虫优化算法是一种模拟萤火虫发光行为的群智能优化算法,其基本思想为:用搜索空间中的点模拟自然界中的萤火虫个体,将问题目标函数定义成萤火虫所处位置的相应解,将寻优过程模拟成萤火虫个体向更亮萤火虫的移动过程。设共有m个萤火虫,第i个萤火虫在 N 维空间中的当前位置为 Xi=(xi1,xi2,…,xiN),萤火虫位置优劣通过萤火虫亮度描述,并决定其移动方向,其相对荧光亮度为:

式中,I0为表示第i只萤火虫最大荧光亮度;λ为光强度吸收参数;rij为萤火虫i与 j之间的距离,定义为:

吸引度(β)决定了萤火虫移动的距离,定义为:

式中,β0为最大吸引度因子。
萤火虫i被萤火虫 j吸引后移动的位置更新由式(4)决定:

式中,xi、xj为第i和第 j个萤火虫所处的空间位置;α为步长因子;rand()是随机数[13-14]。
在实际应用中,由于萤火虫算法实质是一种随机优化算法,因此存在一些不足,如果萤火虫算法进化后期收敛速度慢,易陷入局部最优解等[15]。
2.1 保持种群的多样性
种群多样性对萤火虫的寻优性能起着至关重要的作用,为此,首先将萤火虫群分为n个子群,并为不同子群设置不同α、λ、β0等参数,各子群根据自己寻优方式进行并行寻优,以满足全局寻优要求;然后为每个子群设置公告板,记录每次迭代后的各子群最优值及相应个体位置,并将所有子群的最优个体组建为“决策层”,如果某子群最优值连续3次没有发生变化,那么就认为该子群发生早熟,可能陷入局部最优,此时从“决策层”找到更优萤火虫个体,并对早熟子群的最优个体将利用式(1)~(4)向其他子群的更优个体进行学习,从而完成位置转移,跳出当前局部最优区域。“决策层”构建了各子群之间的信息交流与相互学习的途径,能够对早熟子群提供更明确有效的指导;最后若发现某子群已陷入局部最优,但在“决策层”中找到更优的其他子群个体时,采用高斯变异因子对该子群进行扰动。高斯分布是一种工程常用的重要概率分布,其概率密度函数如式(5)所示:

式中,σ为高斯分布的方差,μ为期望。
将子群内的萤火虫按照优劣大小排序,利用子群内的最优萤火虫将排名最后的萤火虫群体进行状态替换更新,同时对更新萤火虫群体的状态进行高斯变异处理,如式(6)所示。

式中,N(μ,σ)为服从期望为 μ,方差为σ的高斯分布的随机向量。
2.2 自适应变步长机制
步长因子α取值影响萤火虫算法的收敛性能影响,为了提高算法收敛速度和全局寻优能力,在寻优过程中采用自适应变步长机制:初期α值较大,提高全局寻优能力;随着迭代次数增加,逐步减小α值,加快后期收敛速度,具体调整方式为:

式中,Δα为步长衰减系数,在(0.95,1)内取值。
2.3 域约束
为保证萤火虫个体始终在有效搜索空间进行搜索,对萤火虫个体进行域约束处理,具体为:

式中,xmin和xmax分别为搜索空间下限和上限。
采用4个准测试函数:Sphere、Griewank、Ackley和Rastrigin对FA算法、粒子群优化(PSO)算法和MG-FA算法的性能进行测试,4个测试函数见表1所示。

图1 不同算法的收敛性能比较

表1 用于测试算法性能的函数
FA、PSO和MG-FA算法的运行结果如图1所示。从图1可知,Sphere函数只有一个全局最优值,较容易求出;Griewank函数在全局最优值附近不是光滑连续的,增大了搜索难度;Ackle函数只有一个全局最优值,但在全局最优值的附近几乎呈不连续状态,在全局最优值附近搜索的难度很大。Rastrigin是一种病态函数,全局最优与局部最优有很深的狭缝,很多搜索算法几乎无法找到全局最优值,由此可知,针对所有函数,MG-FA算法的进化迭代次数更少,收敛速度更快,并且具有更高的收敛精度,主要是由于在多子群相互学习机制的驱动下,MG-FA算法更容易跳出进化停滞状态,当发生进化变慢或者停滞时,MG-FA算法能通过子群之间的信息传递,牵引进化受阻的萤火虫重新进入进化状态,具备一定的进化复苏能力,从而能够更好地满足局部搜索和全局精度的全面寻优要求,具有更好的求解效率。
3 查询优化的MG-FA设计模型
3.1 设计模型
数据库查询过程会涉及到多个关系表,不同表之间的连接次序导致查询结果的多样性。对于n个表,左、右深树均含有n!个查询优化计划,查询优化是找到一条最小查询代价的执行计划[11]。设一个查询请求可能的查询计划集合为S,那么元素 s的相关联代价为cost(s), 若有 n 个关系 R={r1,r2,…,rn}参与连接运算,tm表示中间关系,那么cost(s)为中间关系tm代价的总和,数据库查询优化问题的数学模型为:

3.2 查询优化的MG-FA设计
3.2.1 编码
MG-FA算法第一个步骤是对所解问题进行编码,因此,编码好坏是MG-FA是否成功的一个关键因素。为了保留连接树的特征,本文采用直接以树的形式编码。对于图2的左深树,萤火虫的编码方式为“653412”。
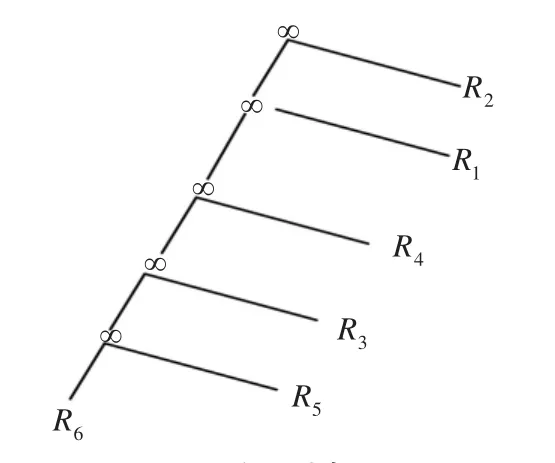
图2 左深树表示
3.2.2 适应度函数
查询优化的目标是要获得代价cost(Xi)最小的执行计划,因此萤火虫个体的适应度函数必须与cost(Xi)相关,因此适应度值函数定义如下:

3.2.3 MG-FA数据库查询优化算法的工作流程
MG-FA算法将数据库查询计划左深树看作一个萤火虫,然后通过萤火虫之间的协作找到数据库查询最优计划,在萤火虫搜索过程中,引入高斯变异策略,提高算法的全局搜索能力,避免陷入局部最优,具体工作步骤如下:
(1)对左深树组成的解空间中的连接操作进行编码,后续遍历连接树得到编码序列L。
(2)初始化参数。设置萤火虫数目m及萤火虫子群数n,并为各子群分别设置光强吸收系数λ、最大吸引度因子 β0及步长因子α。设定收敛条件,并在求解空间内随机生成各萤火虫的初始位置 xij(i=1,2,…,n,j=1,2,…,m/n)。
(3)根据式(10)计算各子群萤火虫的适应度值 f(xi)作为其最大荧光强度,并将各子群中的最佳适应度值记为 fibest,计入子群公告板。
(4)由式(2)计算各子群萤火虫个体的相对荧光亮度Iij,比较所属子群邻域内萤火虫的荧光亮度大小,并确定各萤火虫的位置进化方向。
(5)由式(3)计算各子群萤火虫的吸引度 βij,并根据式(4)更新萤火虫的空间位置。
(6)查询各子群公告板,判断各子群是否出现迭代次数已达到3次,并且 fibest的连续变化量小于1e-3的现象,若是,则转步骤(7),否则,转步骤(8)。
(7)从其他子群公告板中寻找最优个体,若存在优于自身子群的最优值,则让自身的最优萤火虫向其他更优子群的最优个体进行位置转移;若否,则在自身子群内进行高斯变异操作。
(8)根据式(5)收缩步长,并对所有萤火虫个体进行域约束操作。
(9)如果满足终止条件,最优萤火虫位置对应的数据库查询计划。
综合上述可知,基于MG-FA具体流程如图3所示。
4 仿真实验
4.1 仿真环境
为了测试MG-FA算法的性能,在AMD Athlon II X46313.0 GHz,RAM 4 GB,Windows 7操作系统环境中进行仿真实验,采用SQL Server 2005作为数据库软件,采用VC++编程数据库查询优化算法。对比算法为:萤火虫优化算法(FA)、粒子群优化(PSO)算法。采用查询和执行代价评估算法性能。

图3 MG-FA算法的数据库查询流程
4.2 结果与分析
4.2.1 搜索和查询消耗代价比
不同数据库查询优化方法的查询和执行最优计划的代价比如图4、5所示。
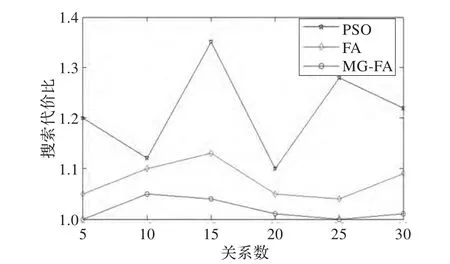
图4 各种算法的搜索代价比
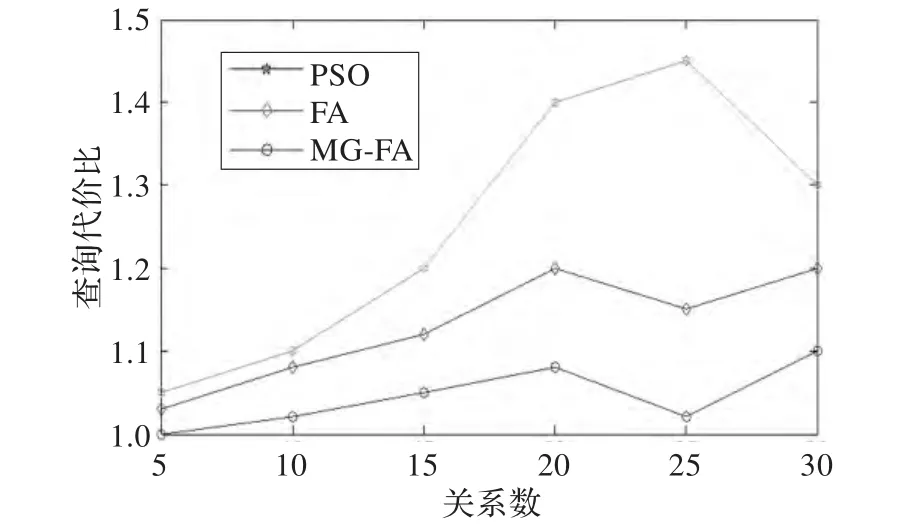
图5 各种算法的查询代价比
从图4和5的结果进行分析可以得到如下结论:
(1)PSO算法代价消耗比曲线变化幅度较大,说明PSO算法在求解数据库查询问题时,性能不稳定且求得最优查询执行计划的准确率不高。
(2)相对于PSO算法,FA的整体搜索代价比曲线并未出现明显变化,变化相对平衡,对比结果表明,相对于PSO算法,FA算法加快了算法的收敛速度,随着关系数的增加,FA算法的整体优化效果要优于FA算法。
(3)相对于PSO、FA算法,MG-FA算法的性能得到相应提升,主要是由于高斯变异算子增加了种群多样性,有较地实现了算法全局与局部搜索的平衡,不仅提高了数据库查询效率,而且大幅度地减少了执行代价,能够更快速地找到最优数据库查询计划。
4.2.2 迭代次数和执行时间
不同算法的收敛速度和最优查询计划执行时间见表2和3。
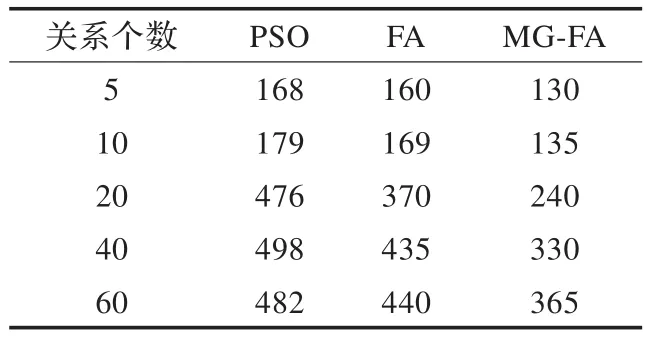
表2 各算法的查询优化计划迭代次数

表3 各算法的执行时间对比 s
对表2和表3进行分析可知:
(1)对于数据库的关系连接数n=20的查询优化问题,当迭代476次时,PSO算法便找到了最优数据库查询计划,其相应执行时间为250.77 s。
(2)相同条件下,当迭代370次时,萤火虫优化算法(FA)便找到了最优数据库查询计划,相应的数据查询的执行时间为200.27 s,相对于PSO算法,FA加快了算法的收敛速度,提高了最优解的质量。
(3)MG-FA算法迭代240次后得到比FA和PSO算法更优的数据库查询计划,其执行时间为185.05 s。
综上可知,MG-FA算法的搜索速度更快,较好地防止了早熟收敛,提高了数据库查询效率。
5 结束语
数据库查询优化是一种要求速度快、效率高的优化问题,针对当前数据库查询优化算法存在的效率低,难以获得最优解的缺陷,结合数据库查询的特点和萤火虫算法的优点,提出一种多子群萤火虫算法的数据库查询优化方法,首先将萤火虫群分为不同参数的多个子群,各子群内的萤火虫跟随所属子群的最优萤火虫分别进行寻优操作,然后在各子群的最优萤火虫之间构建相互学习机制,实现子群间的信息交流,最后采用数据库查询优化数据进行仿真实验,实验结果表明,MG-FA是一种性能良好的数据库查询优化方法,能够获得比其他算法更佳的查询结果。
[1]许新华,胡世港,唐胜群,等.数据库查询优化技术的历史、现状与未来[J].计算机工程与应用,2009,45(18):156-161.
[2]于洪涛,钱磊.一种改进的分布式查询优化算法[J].计算机工程与应用,2013,49(8):151-155.
[3]林键,刘仁义,刘南,等.基于查询优化器的分布式空间查询优化方法[J].计算机工程与应用,2012,48(22):161-165.
[4]邱桃荣,葛寒娟,魏玲玲,等.基于相似度的粗关系数据库的近似查询[J].计算机工程与应用,2008,44(21):195-198.
[5]史恒亮,任崇广,白光一,等.自适应蚁群优化的云数据库动态路径查询[J].计算机工程与应用,2010,46(9):10-12.
[6]帅训波,马书南,周相广,等.基于遗传算法的分布式数据库查询优化研究[J].小型微型计算机系统,2009,30(8):1600-1604.
[7]Kumar T V V,Singh V,Verma A K.Distributed query processing plans generation using genetic algorithm[J].International Journal of Computer Theory and Engineering,2011,3(1):38-45.
[8]Zhou Z H.Using heuristics and genetic algorithms for large-scale database query optimization[J].Journal of Information and Computing Science,2007,2(4):261-280.
[9]Chen P H,Seyed M.Hybrid of genetic algorithm and simulated annealing for multiple project scheduling with multiple resource constraints[J].Automation in Construction,2009,18(4):434-443.
[10]林桂亚.基于粒子群算法的数据库查询优化[J].计算机应用研究,2012,29(3):974-975.
[11]Gandomi A H,Yang X S,Talatahari S.Firefly algorithm with chaos[J].Communications in Nonlinear Science and Numerical Simulation,2013,18(1):89-98.
[12]刘长平,叶春明.一种新颖的仿生群智能优化算法:萤火虫算法[J].计算机应用研究,2011,28(9):3295-3297.
[13]Horng M H.Vector quantization using the firefly algorithm forimage compression[J].ExpertSystemswith Applications,2012,39(1):1078-1091.
[14]Senthilnath J,Omkar S N,Mani V.Clustering using firefly algorithm:performance study[J].Swarm and Evolutionary Computation,2011,1(3):164-171.
[15]Coelho L S,Mariani V C.Firefly algorithm approach based on chaotic Tinkerbell map applied to multivariable PID controller tuning[J].Computers&Mathematics with Applications,2012,64(8):2371-2382.
