基于财务指标的我国上市公司信用风险评价研究
2014-03-22周经纬
周经纬
(东莞职业技术学院财经系,广东 东莞,523808)
基于财务指标的我国上市公司信用风险评价研究
周经纬
(东莞职业技术学院财经系,广东 东莞,523808)
上市公司的信用风险评价是当前我国学术研究的热点问题。以我国上市公司为研究对象,选取了2011年末期118家上市公司作为研究样本,其中ST企业44家和非ST企业74家,分别建立了线性判别模型和逻辑回归模型两种信用风险评价模型。通过模型比较发现,两种模型均能对企业的信用风险做出较为准确的判断,但逻辑回归模型的效果更优,具有更高的判别准确率。
上市公司;信用风险;评价;实证研究
一、引言
信用风险又被称为违约风险,是指债务人在债务期限结束时不能按时履行债务合约,最后导致债权人损失的可能性[1]。信用风险广泛存在于经济个体交往之中,是现代经济体系面临的主要风险。当前我国上市公司违规失信事件屡见不鲜、层出不穷,上市公司的信用风险问题已受到越来越多的投资者及政府部门的重视。上市公司的信用风险评价和控制已成为当前我国学术研究的热点问题。现有的研究多局限于利用性判别模型、逻辑回归模型、KMV模型等单一方法判断上市公司信用风险,由于没有考虑模型自身缺陷,得出的结论具有片面性。
二、文献回顾
国外对公司信用风险的研究较早。1936年,Fisher第一次提出了判别分析法,这给信用风险测度研究带来了新的思路。1968年,美国财务专家Altman借鉴Fisher的思想利用多元判别分析技术建立了Z评分模型[2]。该方法在一定程度上弥补了单变量分析方法的不足。1977年Altman、Haldeman和Narayanan修正并扩展了该模型,建立了Zeta判别模型,经过实证检验,该模型的预测能力非常强,对破产前一年的预测准确度达到96%[3]。由于Zeta判别模型较简便、成本低、效果好,德国、法国、日本等国家都先后依据该模型发展出与之相适应的信用风险度量模型。Zeta判别模型虽然能有效识别公司的信用级别,但它要求数据服从多元正态分布、等协方差,前提条件过于苛刻。现实中大量数据严重违背了这些假定。
为此,Press and Wilson、Ohlson采用了Logistic Function建立了Logit信用评分模型。Logit模型没有严格的前提条件,它不需假定任何概率分布,也不要求等协方差。Smith和Lawerence用Logit模型得出预测贷款违约最理想的变量;Westgaard根据1995—1999年间挪威所有有限责任公司的资料,建立了违约Logit模型,发现资产报酬率、短期流动性、企业资产规模、资本结构4个指标对评估企业破产具有统计显著性。国外学者采用大样本来研究问题,变量选取比较全面,效果也比较好,具有一定的借鉴意义。
国内的相关研究起步较晚。1999年陈静以1995—1997年A股市场27家ST公司和27家非ST公司为总体样本建立了两个线性判别模型首次对我国上市公司信用风险进行预测,总体判别正确率为92.6%[4]。然而其用来检验模型判别正确率的样本就是用于估计参数的样本,因此判别正确率有高估的倾向。2000年陈晓等以1998—1999年37家ST公司为样本,建立Logistic回归模型并得到了86%的预测准确度。2003年,梁琪通过对142家上市公司的财务失败进行实证研究,提出了预测我国上市公司经营失败的主成分判别模型,指出企业的景气指标、盈利指标、增长指标和资本市场指标4个主成分最能解释上市公司的经营失败情况[5]。2007年张立军等以A股市场164家上市公司为研究对象,选取了9个财务指标先进行因子分析,得出相对应的主成分指标,再进行Logistic回归分析,结果表明回归预测的效果较好[6]。国内研究成果大多是利用单一的方法去研究信息风险问题,较少考虑模型本身的缺陷,也没有进行模型之间的对比分析,因而得出的结论具有一定的片面性。本文在前人研究的基础上,以我国上市公司为研究对象,分别建立了线性判别模型和逻辑回归模型,并进行两种模型的比较分析,通过模型之间的交互验证,得出更为一般和合理的结论。
三、样本与指标的选取
(一)模型样本的选择
本文的样本来自于在沪深市场上市公司。由于ST公司比一般正常的上市公司具有较高的信用风险(违约风险),为了便于说明问题和对比,本文选取了有代表意义的ST公司和正常的上市公司这两类样本进行研究。鉴于金融机构的财务比率的特殊性,本文只选择非金融机构作为研究样本。模型总样本由2011年末期118家上市公司组成,其中经营失败组(ST企业)44家和经营正常组(非ST企业)74家。所有数据均取自雅虎网和中投证券数据库。
(二)模型指标的确定
一般而言,企业信用评价及违约风险大小与企业财务状况密切相关。企业财务状况良好时,资本运营顺畅、现金流量管理能力较好,企业就可能守信、有能力且可及时还款。反之,当一个企业财务出现危机时,企业的经营、运作和盈利均处于不利状态,就可能出现拖欠货款、丧失信誉等行为,导致企业信用危机,更加剧了财务困境。因此,对企业信用风险的测度可以转化为衡量企业财务状况的问题。按照指标的选取原则并结合我国上市公司的实际情况,本文从反映公司盈利能力、营运能力、偿债能力和现金流量能力等方面选取财务指标来构建模型。指标具体如表1所示:

表1 选取的财务指标
其中X1表示净资产收益率,该指标越高,说明企业自有资本获取收益的能力越强,运营效益越好,对企业投资人和债权人权益的保证程度越高,企业的预期违约率就越低;X2表示存货周转率,该指标越高,表明存货变现的速度越快,存货占用的资金越少,利用效率越高,企业的资产管理水平就会越高。X3表示流动比率,该指标越高,反映企业短期偿债能力越强,债权人的权益越有保障。X4表示主营业务现金比,该指标越高,说明企业取得的收入大部分都是现金,利润质量高,企业偿还债务的能力越强,违约风险越低。
(三)模型指标的自相关性检验
为判断模型指标是否存在自相关性,需要对这些变量作Pearson相关性分析。表2列示了Pearson检验结果。从表2中可以看出4个财务指标比率变量两两之间的相关性并不强,除了流动比率与存货周转率的相关性0.289稍微大一点,其余各个财务比率变量之间的相关系数基本都小于0.05。这样一个相关系数矩阵完全符合建立判别分析模型和逻辑回归模型的要求。
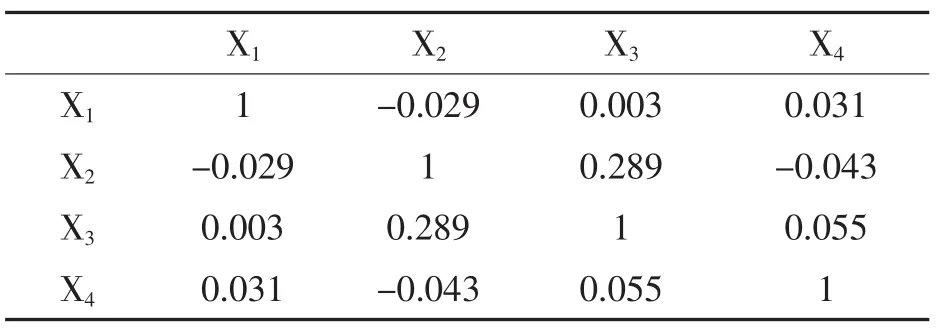
表2 解释变量Pearson相关系数(N=116)
四、模型的建立
(一)基于线性判别模型的实证分析
以样本企业2011年年报数据为基础,经运行SPSS软件,进行单变量组间均值相等检验(如表3所示)。由表3知,变量X2和X4的显著水平均大于0.05,没有通过显著性检验,判断作用不显著;而变量X1和X3的显著水平均小于0.05,说明在0.05的显著水平下变量X1和X3通过了显著性检验,可进行判别分析。Wilks’Lambda统计量是测度判别量作用大小的统计量,如果某变量的Wilks’Lambda值较小,那么该变量判别分析的作用就越大。表3中变量X1的Wilks’Lambda值小于变量X3,说明变量X1在判别模型中的作用大于变量X3。
表4显示标准化的典型判别函数系数,于是可得到如下两个标准化的典型判别分析模型:
非ST公司Fisher判别函数:

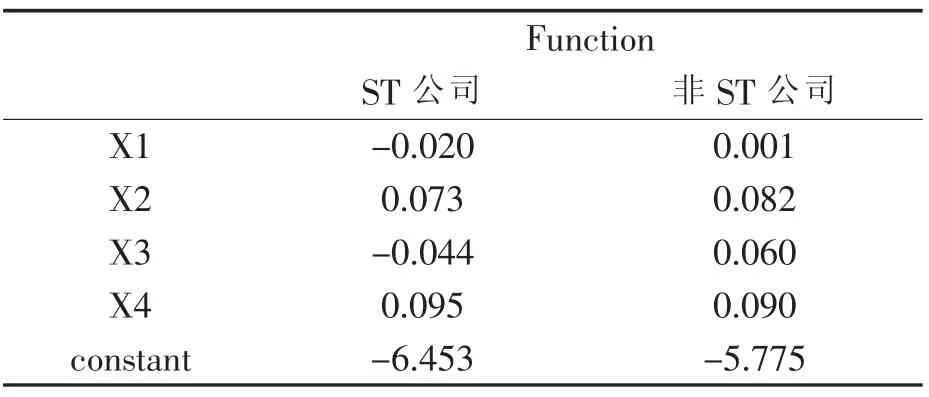
表4 标准化的典型判别函数系数
利用模型(1)和模型(2)对数据样本进行判别分析,汇总计算结果为74家非ST公司中,使用判别分析后全部划分到非ST公司,误判个数为0;而44家ST公司,有30家被划分为ST公司,14家被划分为非ST公司,误判个数为14,因而总的误判率为11.9%,这表明判别分析模型的总体判别准确率达到88.1%。
(二)基于逻辑回归模型的实证分析
为了保持逻辑回归模型与线性判别模型的数据一致性,逻辑回归模型选用的参数数据与线性判别模型都是净资产收益率、存货周转率、流动比率和主营业务现金比。把样本数据输入SPSS统计软件,调用Logistic回归过程,得到运行结果(见表5)。

表5 模型摘要
-2对数似然值用于检验全部自变量的作用是否显著,适用于含连续性变量的情况。-2对数似然值越小,模型的拟合效果越差;该值越大,模型的拟合效果越好。从上表看,模型拟合的较好。Cox&Snell R2和Nagelkerke R2与线性模型的R2相似,是对回归模型变异中可解释部分的量化,这两个拟合系数的数值越大,模型的拟合效果越好,由上表可知模型拟合的较好。
利用同样的数据,对上述4个财务比率运用SPSS13分析软件的Logistic回归分析功能中的多种自动筛选最佳自动变量功能进行筛选,通过SPSS分析软件运算,我们从上述4个财务指标中选择“净资产收益率”作为最佳自变量。回归结果参数估计如表6所示:

表6 Logistic回归结果
由上表,可得估计的Logistic回归方程如下:

其中X1为净资产收益率。
运用上述模型(3)对118个训练样本进行判定,计算出相应的P值,若P值<0.5就判断企业为守信较差的企业(信用较差);若P值≥0.5就判断企业为守信较好的企业(信用较好)。将样本具体数据代入模型(3),得到的回判精度见表7所示:

表7 Logistic模型 识别结果
从表6的回判结果可以看出,而44家ST公司,有43家被划分为ST公司,1家被划分为非ST公司,预测准确率达97.7%;74家非ST公司中,判断正确的达73家公司,预测准确率达到98.6%,模型总的预测准确率为98.3%,与判别分析模型的分类表相比,预测准确率提高了10.2%。
五、两种模型的比较分析
通过以上分析可知,线性判别模型和逻辑回归模型对企业进行信用风险分析都能得到很高的判别准确度(大于82%),因而两种模型对于判别企业的信用风险具有重要的参考价值。两种模型相比较而言,逻辑回归模型则要比线性判别模型有着更高的准确性。具体分析,判别分析模型对非ST公司的判别准确性非常高,本案例分析中没有误判,但对ST公司的判别正确率偏低。逻辑回归模型对两类企业的判别准确率都相当高,与线性判别模型相比突出表现在对ST公司的判别上,本案例分析中仅存在一个误判。逻辑回归模型对企业信用风险的判别准确率高于线性判别模型是有原因的。线性判别模型的基本思想是假设财务指标可以反映企业的信用状况,通过对企业主要财务指标的分析和模拟,测度企业的信用水平。因而该模型对数据质量具有较高的依赖性,例如要求变量的多元正态分布、独立性及等协方差矩阵等,而一旦财务数据指标不能完全满足这些条件,其在信用分析评价与预测中的准确性就会打折扣。逻辑回归模型是一种非线性的概率模型,它对于自变量的分布没有具体的要求,也不需要假设自变量之间存在多元正态分布,因而参数估计更加稳健,预测中的准确性更高。逻辑回归模型并非完美,也具有一定的缺陷,如该模型对异常数据的分析很容易产生误判。因而,在实际信用风险评价中应多种模型结合使用,综合评价,减少误判。
六、加强我国上市公司信用风险监管政策建议
(一)加快培育权威的专业商业信用评级机构
专业的商业信用评级机构是企业与金融机构和投资者之间相互了解和信任的中介与桥梁,能够较好的解决证券市场信息不对称问题。因此,培育专业的商业信用评级机构是完善上市公司信用风险评估体系的基础。然而当前我国商业信用评级行业还处于群雄并起的发展阶段,评级机构数量众多,但普遍规模不大,竞争激烈,评级结果的市场认同度不高,严重缺乏像美国标普、穆迪和惠誉这样权威的专业商业信用评级机构。因此,我国政府主管部门应该参照和借鉴美国信用评级机构培育和管理经验,加快建立和培育本土相对权威的商业信用评价机构,为社会信用体系的发展创造良好的宏观环境。
(二)加快信用风险基础数据库的建设进程
大量的数据信息是进行准确的信用风险度量的基础,也是建立信用风险管理体系的基础,只有在信用数据库建立起来后,才能更好地管理信用风险。当前我国企业信息风险基础数据库建设已取得一定的成绩,2006年实现全国联网运行,截止2012年12月底,企业征信系统为1859万户企业和其他组织建立了信用档案,但与发达国家相比我国信用风险数据库建设仍处于初级阶段,还存在信息采集不及时、信息质量不高、更新不及时等问题,导致资信评估质量不高,准确性较差,进而抑制其有效地发挥作用。因此,要提高我国企业信用风险评估水平,需要进一步加快信用风险基础数据库的建设进程。
(三)规范上市公司财务信息披露,增强会计信息真实性
在企业信用风险评价模型计算过程中的大量数据都来源于公司披露的财务数据,信用风险评价模型直接应用上市公司的数据对信用风险进行评估,这就要求证券市场必须是有效的。我国与国外成熟的资本市场相比还存在着一定的差距,会计舞弊现象时有发生,会计信息失真较为严重,这给信用风险评价模型的建立和有效测量带来了一定的风险。为了保证财务困境预测模型在实际应用中的有效性,针对目前我国上市公司会计信息失真较严重的现状,我国政府主管部门需要加大对上市公司信息及注册会计师行为的监管力度,规范上市公司财务信息的披露行为。
[1]郭富霞,路兰,高齐圣.基于主成分的logistic模型的上市公司信用风险评价分析[J],青岛大学学报:自然科学版,2012(2):106
[2]E.I.Altman.Financial ratios,discriminate analysis and the prediction of corporate bankruptcy[J].Journal of Finance,1968(9):589-609.
[3]Altman,Haldeman,Narayanan.ZETAAnalysis:Anew model to identify bankruptcy risk of corporations[J]. Journal of Banking and Finance,1977(1):29-54.
[4]陈静.上市公司财务恶化预测的实证分析[J].会计研究, 1999,(4):31-38
[5]梁琪.企业信用风险的主成分判别模型及其实证研究[J].财经研究,2003(5):52-58
[6]张立军,刘菊红,刘月.Logistic模型在上市公司财务状况评价中的运用[J].东北财经大学学报,2002(1):61-63.
(编辑:马慧 徐永生)
An Empirical Research on Credit Risk of Listed Companies in China Based on Financial Indicators
ZHOU Jing-wei
(Finance Department,Dongguan Polytechnic,Dongguan 523808,China)
Credit risk evaluation of listed companies has become a focus of academic research in China.Taking listed companies in China as research object,this paper selects 118 listed companies at the end of 2011 as samples,including 44 ST companies and 74 non-ST companies,respectively establishes linear discriminating model and logical regression model,two kinds of credit risk evaluation modes.The results of comparing the two models show that both models can make accurate judgment of credit risks of enterprises,however,the logical regression model is better and has the higher accuracy of the linear discriminating model.
listed company;credit risk;evaluation;empirical research
F 272.5
A
1671-4806(2014)03-0020-04
2014-02-28
周经纬(1977—),男,湖南衡阳人,讲师,硕士,研究方向为财务与会计。
