基于质谱与支持向量机的清香型白酒等级判别
2014-03-17程平言范文来
程平言,范文来,徐 岩
(教育部工业生物技术重点实验室,江南大学生物工程学院酿酒科学与酶技术研究中心,酿造微生物与应用酶学研究室,江苏无锡214122)
基于质谱与支持向量机的清香型白酒等级判别
程平言,范文来*,徐 岩
(教育部工业生物技术重点实验室,江南大学生物工程学院酿酒科学与酶技术研究中心,酿造微生物与应用酶学研究室,江苏无锡214122)
不同等级白酒鉴别对控制白酒质量和保护消费者利益有重要意义,文中以牛栏山酒为例,研究清香型白酒质量等级鉴别方法。运用顶空固相微萃取质谱(HS-SPME-MS)技术获取三类不同等级的57个牛栏山酒样质荷比m/z 55~191范围内的离子丰度值数据,分别进行偏最小二乘回归分析(PLS)和主成分回归分析(PCR),其中PLS模型的预测结果明显优于PCR。同时PLS与PCR模型的回归系数用于选择重要特征离子,其中PLS与PCR回归系数法分别选择了12和10个离子,用选择的离子变量构建支持向量机(SVM)模型,模型对测试集的预测准确率分别为80%和86.7%,其中PCR回归系数法选择的特征离子为m/z 71、103、104、106、127、149、161、179、183和184。
等级鉴别,顶空固相微萃取质谱,偏最小二乘回归分析,主成分回归分析,支持向量机
食品安全与质量等级鉴别已日渐引起人们的关注。目前,白酒研究大多采用色谱技术[1-3]和光谱技术[4]。其中范文来等[2]应用毛细管色谱法结合聚类分析清晰区分了四川地区与江淮流域的浓香型白酒;Yang等[4]应用近红外光谱技术鉴别了三种不同品牌的白酒。它们大多是关于白酒不同产地、品牌的鉴定,而很少涉及同种酒不同质量等级的鉴别。近年来,顶空固相微萃取质谱技术[5](HS-SPME-MS)逐渐用于白酒鉴定,这一方法无需酒样预浓缩及化合物解析,能够快速用于大批量样品鉴定。近期,Cheng等利用HS-SPME-MS技术实现了八种不同白酒的产地鉴别[6]及浓香型白酒的等级鉴别[7-8],主要采用了逐步线性判别分析[9]、偏最小二乘-判别分析[10]以及神经网络等[11]化学计量学方法。
本文以清香型牛栏山不同等级酒为例,研究HS-SPME-MS技术结合偏最小二乘回归分析(PLS)、主成分回归分析(PCR)和支持向量机[12-13](SVM)等分析法,建立清香型白酒质量等级鉴别模型。首先,采用HS-SPME-MS技术分析获取不同等级牛栏山原酒的离子丰度值数据;然后,经PLS和PCR分析选取重要特征离子,构建SVM模型,并比较模型的预测结果,确定最适等级鉴别模型及离子变量选择方法。
1 材料与方法
1.1 材料与仪器
牛栏山酒样 实验选用三个等级的牛栏山酒样,分别为特制大米查酒(DC)、特制二米查酒(EC)和优质酒(YZ),其中每类等级各有19个酒样,采用分层抽样法将整个样品集分成训练集(42个酒样,每类等级14个)和测试集(15个酒样,每类等级5个),其中训练集用于构建等级鉴别模型,而测试集则用于验证模型的准确性;氯化钠 上海国药集团,分析纯。
Milli-Q超纯水系统 Millipore,Bedford,MA,USA;自动顶空进样系统 德国Gerstel公司;GC 6890N-MSD 5975气相色谱-质谱联用仪 美国Agilent公司。
1.2 实验方法
1.2.1 样品准备 将所有不同等级的牛栏山酒样,用超纯水稀释到10%vol,取8mL置于20mL自动进样顶空瓶中,加入3g氯化钠,盖上瓶盖。
1.2.2 SPME条件 参考文献[14],对方法适当改进,采用DVB/CAR/PDMS三相萃取头于恒温40℃下预热5min,后在同一温度下萃取吸附15min;萃取完成后,萃取头插入气相色谱仪进样口中解吸分析物。由于本方法仅需获得酒样的整个顶空色谱图而无需解析化合物,因此,将解吸时间设为10min。
1.2.3 质谱条件 EI电离源,电子轰击能量为70eV,离子源温度为230℃;扫描范围为35~350amu。
1.2.4 化学计量学分析 文中采用PLS、PCR方法构建等级鉴别模型,并比较两模型的鉴别结果。同时,PLS和PCR也用于筛选重要离子,借助PLS和PCR模型回归系数值的大小,筛选出重要的特征离子。用筛选得到的离子变量构建SVM模型,并比较两模型的预测准确性。文中所使用的软件分别为Unscrambler 9.7,Matlab 2012a及Libsvm工具箱。
2 结果与分析
通过HS-SPME-MS技术获取不同等级牛栏山酒质荷比m/z 55~191范围内的离子丰度值,图1显示了牛栏山不同等级原酒的离子平均丰度质谱图。不同离子的丰度值存在明显差异,其中m/z 88离子作为基峰,在所有酒样中它的离子丰度值最高,且它是乙酯类化合物的特征离子[5]。另外,低质荷比的离子丰度值明显高于高质荷比离子,甚至某些离子的丰度值在图中趋于0。图1中显示出牛栏山特制大米查酒、特制二米查酒以及优质酒的离子相对丰度变化趋势基本相同,仅在某些离子处的丰度值存在明显差异。其中特制大米查酒和特制二米查酒的离子丰度值要低于其优质酒,特别是在高质荷比的离子区域,它们的丰度值在图1中趋于0。可见,从质谱图中无法得到能够区分三类等级牛栏山酒的客观可靠的差异,因此,需借助合适的化学计量学方法来提取重要的特征离子实现牛栏山酒等级的鉴别。
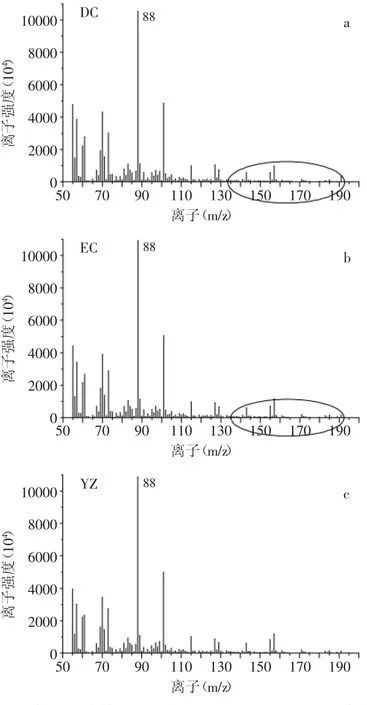
图1 牛栏山三个等级酒质荷比m/z 55~191范围内的离子平均强度质谱图Fig.1 The average mass spectrum of Niulanshan liquors with different grades in the range of m/z 55~191
不同酒样的离子丰度值构成数据矩阵,但在进行化学计量学分析前,需对数据进行标准化处理。首先,对观测值进行标准化,将最高峰m/z 88离子的相对丰度值设为100%,其他离子的相对丰度值根据比例计算,这样可排除因仪器、酒精含量等外在因素造成的离子丰度值差异对判别结果的影响;然后,对离子变量进行处理,由于某些离子的丰度值为零,采用四次方根法进行数据转换[15]。另外,由于m/z 88离子作为基峰,在酒样中的相对强度相同,因此将其去除,如此形成了57行(训练集42个,测试集15个)×135(m/z 188离子丰度值为0)列的数据矩阵。
2.1 偏最小二乘回归分析
PLS分析特别适用于X变量较多的情况,虽然此方法起初并非用于分类判别,但它的应用成功实现了这一目的[16]。首先,将牛栏山酒的不同等级作Y变量,并对它的值作如下定义:1=特制大米查酒,2=特制二米查酒,3=优质酒,若网络模型的输出值在0.7与1.3之间,则酒样判别为特制大米查酒,若输出值在1.7与2.3之间,则酒样判别为特制二米查酒,若输出值在2.7与3.3之间,则酒样判别为优质酒。分界点的选择标准与其他已报道的研究相似[17-18]。PLS回归分析可降低变量维度,本文中筛选出7个主成分,占整个变量集方差的96%,此最适主成分数由交叉验证的最低预测残差确定。用训练集酒样构建PLS模型,在此过程中,采用留一法交叉验证[19]测试模型的有效性,即每次留一个酒样对由剩余酒样建立的模型进行验证,此过程重复n次,其中n为酒样总数,模型的预测能力为n个模型预测准确率的平均值。选取前两个成分来可视化酒样的聚类结果,如图2,不同等级的牛栏山酒样基本能够分开,仅少数酒样发生部分重叠,其中特制大米查酒呈散状分布,主要分布于第三象限中;特制二米查酒与优质酒分布较集中,呈平行分布。可见,PLS分析能够实现不同等级牛栏山酒的分类聚集。
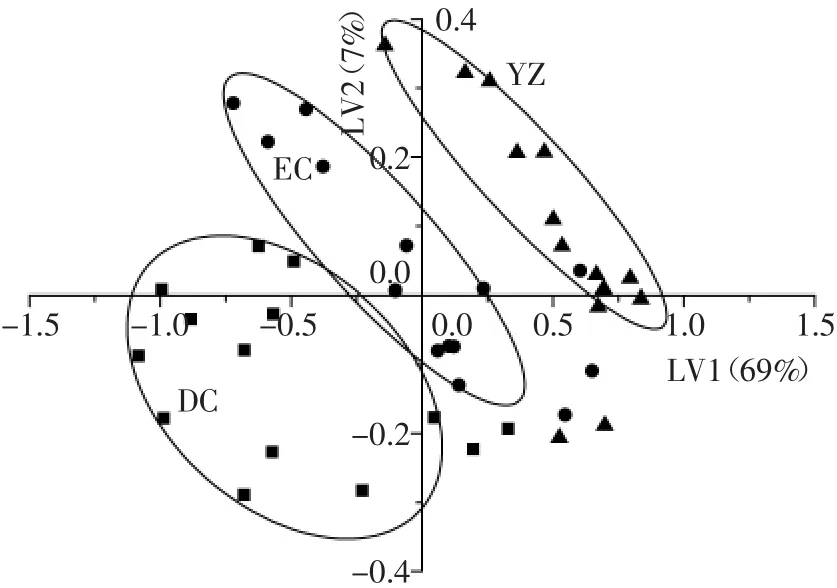
图2 不同等级牛栏山酒的PLS得分图Fig.2 The PLS two-dimensional diagrams of Niulanshan liquors of different quality grade
PLS模型的预测性能由R2、训练集和交叉验证的均方根误差来确定。表1中显示PLS模型对训练集的R2和均方根误差值分别为0.969和0.143。当R2值越接近1,模型的拟合结果越好,可见,此PLS模型对酒样等级的拟合效果较好,能够用于牛栏山酒样等级的预测。从表1中可见,PLS模型对训练集不同等级牛栏山酒样的预测准确度都很高,分别为92.9%,100%和92.9%。
为了验证模型对未知等级样品的预测能力,本文中引入测试集,其所含酒样未用于模型的构建。表1中显示PLS模型对测试集中不同等级牛栏山酒样的预测准确率分别为60%、100%和60%。另外,模型对测试集的R2为0.872,等级的整体预测准确率为73.3%。

表1 PLS和PCR模型的性能参数及不同等级牛栏山酒的预测准确率Table 1 The performance parameter and prediction accuracy of PLS and PCR model for Niulanshan liquors of different quality grade
2.2 主成分回归分析
应用PCR分析时,对酒样等级的预设值及分界点选择标准与PLS模型相同。PCR分析同样可以降低变量维度,最后以交叉验证的最低预测残差选出7个最适主成分,占整个变量集方差的95%。用训练集酒样构建PCR模型,在此过程中,与PLS模型相同,采用留一法交叉验证测试模型的有效性。选取前两个成分来可视化酒样的聚类结果,如图3,不同等级牛栏山酒样的聚类效果不如PLS分析,不同等级的酒样无法分离,特别是特制二米查酒与优质酒酒样发生明显重叠。
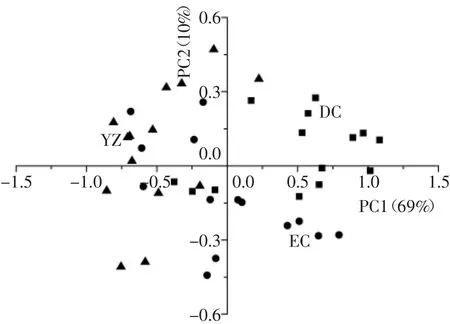
图3 不同等级牛栏山酒的PCR得分图Fig.3 The PCR two-dimensional diagrams of Niulanshan liquors of different quality grade
从表1中可见,PCR模型对训练集的R2和均方根误差值分别为0.879、0.284,模型预测性能明显低于PLS模型,且R2值未接近于1,模型的拟合结果不太好。PCR模型对不同等级酒样准确率分别为78.6%、85.7%和71.4%,准确率差异较大,且低于PLS模型,这可能受样本数和酒样代表性的影响。借助测试集来验证PCR模型的泛化能力,不同等级酒样的整体预测准确率为66.7%。从总体看,PLS模型对等级的判别结果优于PCR模型。
2.3 SVM模型比较
本文中PLS和PCR方法也用于变量选择,提取重要的特征离子。这一选择方法以回归系数为基础,根据PLS和PCR模型对各离子的回归系数的大小来选择重要离子,应特别注意回归系数绝对值大的离子变量对等级判别越重要。对PLS和PCR模型,分别选取回归系数绝对值大于1.1和0.7的离子。从图4可见,PLS回归分析选取了m/z 72、76、106、112、155、157、166、170、177、179、180、183共12个离子;而PCR分析选取了m/z 71、103、104、106、127、149、161、179、183、184共10个离子。其中两种方法均选出了m/z 106、179、183这3个离子,需特别注意它们对等级判别的重要性。
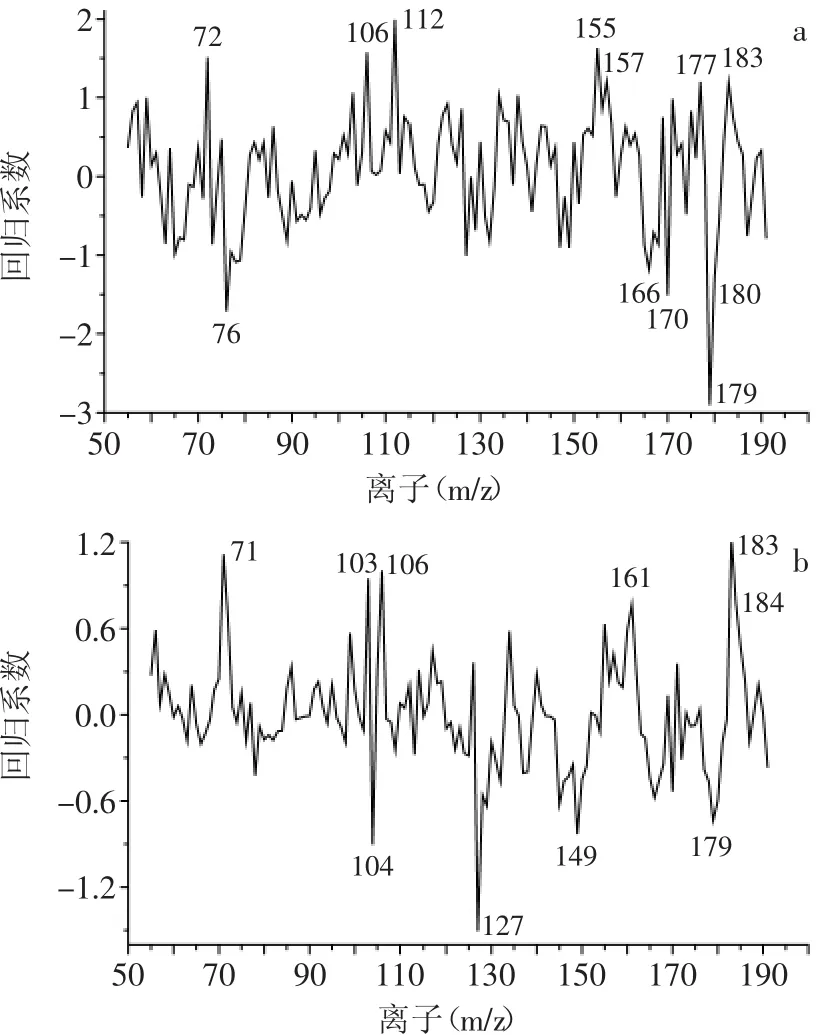
图4 PLS(a)和PCR(b)模型对m/z 55~191范围内离子的回归系数图Fig.4 The regression coefficients of PLS(a)and PCR(b)models in the range of m/z 55~191
将两种方法筛选出的离子,组成新的数据矩阵用作SVM模型的输入集,牛栏山二锅头酒样等级的预设值为输出层,预设值及分界点选择标准与PLS模型相同,构建SVM模型。SVM在解决小样本、非线性及高维模式识别中表现出许多特有的优势[20]。应用SVM过程中,需首先解决三个重要问题,分别是合适的输入数据集、核函数和最优核参数。常用的核函数主要有径向基函数、多项式和S型函数。与其他函数相比,径向基函数应用更广泛[21],因此本文中选用径向基函数。在确定了核函数的基础上,需确定最优的核参数g和惩罚因子c两个参变量[22],才能准确地构建等级判别的SVM模型。SVM采用结构风险最小化原则来选择最优参数,明显优于传统网络的经验风险最小原则[23]。本文中采取十折交叉验证和网格搜索算法在2-10~210的区域内寻找最优c和g值(图5)。可见,根据PLS回归系数法选择的离子所构建的SVM模型的最优c和g值分别为45.25和0.707;而根据PCR回归系数法选择的离子所构建的SVM模型的最优c,g值分别为2和11.314。图5中显示了SVM模型的网格搜索过程,坐标点为最优参数c和g组合。
表2显示了由所得的两组最优参变量c和g值构建的SVM模型的性能参数和不同等级白酒的预测准确度。可见,由PLS回归系数法选择的变量构建的SVM模型对测试集酒样的R2和均方根误差分别为0.895和0.081,略优于PCR回归系数法。其中PLS回归系数法构建的SVM模型对训练集酒样的预测准确率分别为85.7%、100%和92.9%,测试集酒样的平均预测准确率为80.0%;由PCR回归系数法构建的SVM模型对训练集酒样的预测准确率分别为92.9%、92.9%和100%,测试集酒样的平均预测准确率为86.7%,仅2个特制大米查酒样预测错误,造成模型预测错误的主要原因是用于构建模型的训练集酒样代表性不明显。因此,若要提高模型的预测准确性,增加样本数是必不可少的过程。

图5 SVM模型的最优参数组合c和g的网格搜索图Fig.5 The grid search process of optimal c and g parameter combination of SVM model

表2 不同离子选择方法构建的SVM模型的性能参数及不同等级牛栏山酒的预测准确率Table 2 The performance parameter and prediction accuracy of SVM models built by two ion selection methods for Niulanshan liquors of different quality grade

图6 PLS、PCR和SVM模型对测试集的预测误差图Fig.6 The prediction error of PLS,PCR and SVM model for the test set
由PCR回归系数法选择的离子构建的SVM模型对牛栏山不同等级酒样的预测准确率更高。图6比较了PLS、PCR和SVM模型对测试集的预测误差值,很明显,PLS和PCR模型的误差值波动较大,而SVM1和SVM2模型的误差值在第5号酒样处出现很大波动,但对其他酒样的预测误差变化很平稳。综合考虑,当以±0.3为临界值时,由PCR回归系数法选择的变量构建的SVM模型的预测效果要优于其他模型,此外也说明PCR回归系数法能有效用于提取重要的特征离子。另外,可考虑增加酒样的样本量,提高酒样的代表性来完善模型,提高模型的预测准确度,降低误差值。
3 结论
以±0.3为分界点选择标准,PLS模型的等级预测准确率高于PCR模型,同时用PLS与PCR的回归系数值选择重要的离子变量,构建SVM模型。由PCR回归系数法选择的特征离子所构建的SVM模型,对测试集的预测准确率达86.7%,预测结果优于其他模型,选出的重要离子为m/z 71、103、104、106、127、149、161、179、183和184。因此,质谱技术与支持向量机相结合的方法能够准确用于白酒等级鉴别;且PCR回归系数法能有效地选择重要的离子变量。
[1]祝成,张宿义,赵金松.不同感官等级白酒基酒的聚类分析[J].酿酒科技,2011(9):47-50.
[2]范文来,徐岩.应用GC-FID和聚类分析比较四川地区白酒原酒与江淮流域白酒原酒[J].酿酒科技,2007(11):75-78.
[3]温永柱,范文来,徐岩,等.白酒中5种生物胺的HPLC定量分析[J].食品工业科技,2013,34(7):305-308.
[4]Yang GQ,Zhang SJ,Zhang HH.Study on discrimination of brands of Chinese distilled spirit using near infrared transmission andreflectancespectra[Z].WorldAutomationCongress,Kobe,2010.
[5]Jelen HH,Ziolkowska A,Kaczmarek A.Identification of the botanical origin of raw spirits produced from rye,potato,and corn based on volatile compounds analysis using a SPME-MS method [J].Journal of Agricultural and Food Chemistry,2010,58(24):12585-12591.
[6]Cheng PY,Fan W,Xu Y.Determination of Chinese liquors from differentgeographic originsbycombination ofmass spectrometry and chemometric technique[J].Food Control,2014,35(1):153-158.
[7]程平言,范文来,徐岩.基于质谱与化学计量学的浓香型白酒等级鉴别[J].食品与发酵工业,2013,39(6):94-98.
[8]Cheng PY,Fan W,Xu Y.Quality grade discrimination of chinese strong aroma type liquors using mass spectrometry and multivariate analysis[J].Food Research Internationa(lin press).
[9]Liu L,Cozzolino D,Cynkar W,et al.Geographic classification of Spanish and Australian Tempranillo red wines by visible and near-infrared spectroscopy combined with multivariate analysis [J].Journal of Agricultural and Food Chemistry,2006,54(18):6754-6759.
[10]Abdi H.Partial least squares regression and projection on latent structure regression[J].Wiley Interdisciplinary Reviews:Computational Statistics,2010,2(1):97-106.
[11]Marini F.Artificial neural networks in foodstuff analyses:Trends and perspectives A review[J].Analytica Chimica Acta,2009,635(2):121-131.
[12]Xu Y,Zomer S,Brereton RG.Support vector machines:A recent method for classification in chemometrics[J].Critical Reviews in Analytical Chemistry,2006,36(3-4):177-188.
[13]Liu F,He Y,Wang L.Determination of effective wavelengths for discrimination offruit vinegars using near infrared spectroscopy and multivariate analysis[J].Analytica Chimica Acta,2008,615(1):10-17.
[14]Fan W,Qian MC.Headspace solid phase microextraction and gas chromatography-olfactometry dilution analysis of young and aged Chinese“Yanghe Daqu”liquors[J].Journalof Agricultural and Food Chemistry,2005,53(20):7931-7938.
[15]Wold S,Sjöström M,Eriksson L.PLS-regression:a basic tool of chemometrics[J].Chemometrics and Intelligent Laboratory Systems,2001,58(2):109-130.
[16]Pereira AC,Reis MS,Saraiva PM,et al.Analysis and assessment of Madeira wine ageing over an extended time period through GC-MS and chemometric analysis[J].Analytica Chimica Acta,2010,660(1-2):8-21.
[17]Yu H,Zhou Y,Fu X,et al.Discrimination between Chinese rice wines of different geographical origins by NIRS and AAS[J]. European Food Research and Technology,2006,225(3-4):313-320.
[18]Cozzolino Dl,Smyth HE,Gishen M.Feasibility study on the use of visible and near-infrared spectroscopy together with chemometrics to discriminate between commercial white wines of different varietal origins[J].Journal of Agricultural and Food Chemistry,2003,51(26):7703-7708.
[19]Sampaio OM,Reche RV,Franco DW.Chemical profile of rums as a function of their origin.The use of chemometric techniques for their identification[J].Journal of Agricultural and Food Chemistry,2008,56(5):1661-1668.
[20]林翠香.基于数据挖掘的葡萄酒质量识别[D].长沙:中南大学,2010:38-39.
[21]Belousov AI,Verzakov SA,Von Frese J.Applicational aspects of support vector machines[J].Journal of Chemometrics,2002,16(8-10):482-489.
[22]CherkasskyV,MaYQ.Practicalselection ofSVM parameters and noise estimation for SVM regression[J].Neural Networks,2004,17(1):113-126.
[23]Gunn SR.Support Vector Machines for Classification and Regression[R].ISIS Technical Report,1998:5.
Quality grade discrimination of light aroma type liquor based on mass spectrometry and support vector machine
CHENG Ping-yan,FAN Wen-lai*,XU Yan
(Key Laboratory of Industrial Biotechnology,Ministry of Education,Laboratory of Brewing Microbiology and Applied Enzymology,School of Biotechnology,Jiangnan University,Wuxi 214122,China)
Quality grade discrimination of Chinese liquor was benefit for controlling liquor quality and safeguarding the interests of consumers.In this paper,taking Niulanshan for instance,we studied quality grade discrimination of Chinese liquor with light aroma type.Mass spectra of 57 samples were obtained by head space-solid phase microextraction-mass spectrometry(HS-SPME-MS)technology in the range of m/z 55~191.And then,the partial least squares regression(PLS)and principal component regression(PCR)models were developed by calibration set and predicted the quality grade of validation set.Obviously PLS model was superior to PCR model.The support vector machine(SVM)models were built by different ion selection methods,PLS regression coefficients and PCR regression coefficients;the prediction accuracy of SVM models for the test set was 80% and 86.7%,respectively.The ions,m/z 71,103,104,106,127,149,161,179,183 and 184 were selected by PCR regression coefficients.
quality grade discrimination;head space-solid phase microextraction-mass spectrometry(HSSPME-MS);partial least squares regression(PLS);principal component regression(PCR);support vector machine(SVM)
TS207.3
A
1002-0306(2014)08-0049-05
10.13386/j.issn1002-0306.2014.08.001
2013-07-05 *通讯联系人
程平言(1988-),女,硕士研究生,研究方向:酒类风味化学。
国家高技术研究发展计划(863计划)(2013AA102108)。
