基于监督的RSM改进研究
2014-02-09张立民张建廷
刘 凯,张立民,张建廷,马 超
(海军航空工程学院电子信息工程系,山东烟台264001)
0 引 言
文本分析目的在于准确、高效的提取文档信息和分析文本语义。RBM[1]作为克服传统概率主题模型[2-4]后验概率难以推断缺点的无向图模型,受到越来越多的关注。RAP[5]将词汇视为泊松分布样本,较好的实现文本信息特征的提取,但存在处理不同长度文本计算难度大的问题。RSM[6]克服了RAP的缺点并衍变诸多模型如Document NADE[7,8]、Over Softmax Model[9]等。但上述算法均为无监督学习方法,对于存在类别属性的文档并没有考虑类别信息对于文本特征提取的影响,本文针对这一问题,在RSM的基础增加类别信息处理,并提出了基于监督的RSM-sRSM。新模型将不仅提高学习的收敛速度与收敛精度,而且对于文本表达更加准确。
1 RSM模型
1.1 受限玻尔兹曼机
受限玻尔兹曼机(RBM)是在玻尔兹曼机的基础上增加了限定条件形成的,即层内单元无连接、层间单元全连的两层结构(可见层和隐藏层)的双向连接马尔可夫随机场(MRF),其网络连接如图1所示。

图1 RBM单元连接
RBM的能量形式请参见文献[1],如下所示

由于层间单元是无连接的,可以很方便的推导出隐单元和可见单元的后验概率分布,分别如下所示[10]

其中sigm(x)=1/(1+exp (-x))。
1.2 RSM模型
Ruslan Salakhutdinov在文献[6]中提出了RSM,是在RBM的基础上通过将可见单元设定为多项分布样本,实现了文本的有效表示。RSM中,将每一个文本作为一个RBM的训练样本,设定v∈{1,…,K }D,其中K是词汇单词的数量,D是文本的大小,隐单元h∈{0,1 }F代表潜在语义,故可见层为一个K×D的二值矩阵(=1表示在可见单元i的位置上出现的是第k个词汇),其能量形式如下所示

其可见单元和隐单元的后验概率分别为式(6)和式(7)
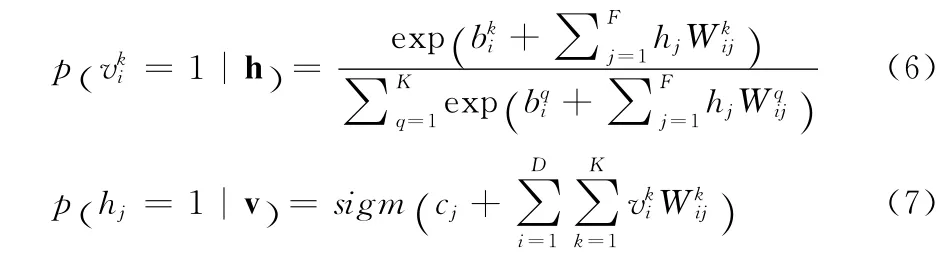

RSM模型的单元连接形式如图2所示。

图2 RSM连接
1.3 CD算法
RBM可以通过极大似然法则进行无监督学习,即最大化数据出现的概率,但由于剖分函数难以计算,因此Hinton于2002年提出了CD算法[11],通过执行block Gibbs采样,提高数据的后验概率分布下限,实现训练目标。
算法介绍(CD=1):
ε是CD中随机梯度下降的学习速率
W是RBM的权重矩阵
b是RBM的输入偏置
c是RBM的隐单元偏置
对于所有的隐单元节点i
从后验概率Q hi|X()
对于所有的可见单元j
从后验概率P (x-j|H+)采样x-j∈{0,1}
对于所有的隐单元节点i
权值更新
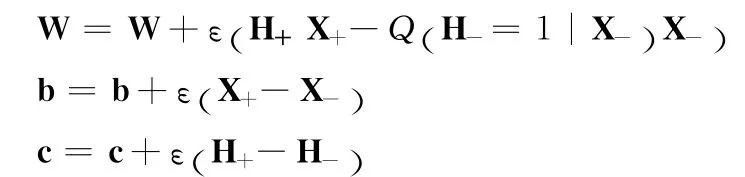
2 sRSM模型
2.1 基于监督的RSM模型
由于RSM为无监督学习模型,对于带有类别信息的数据并不十分适用,因此提出一种基于监督的RSM,新模型通过增加类别单元,影响隐单元的后验概率分布,实现带有类别信息的文本特征的提取。新模型不仅可以适用于带有类别信息的数据,而且对于无类别属性的数据也可以直接应用,其使用的广泛性有利于模型的推广。
基于监督的RSM(sRSM)如图3所示。类别单元为类别信息的二进制编码表示。sRSM通过新增类别单元以后,其能量形式如下所示

基于这个能量函数,那么v,(l)的联合概率分布见式(10),其中Z为归一化因子(剖分函数)+采样h+i∈0,{1}

图3 sRSM模型

隐单元、可见单元与类别单元的激活概率分别见式(11)、式(12)和式(13)

可见单元和类别单元能够同时参与生成数据,若数据为无类别数据,则类别单元L为零向量,即为标准的RSM模型。
2.2 学习算法
针对于sRSM算法,其学习过程(CD=1)改进为:输入:对于一条带类别信息的文本训练数据
ε是CD中随机梯度下降的学习速率
W是RSM的隐单元与可见单元的连接权重矩阵
b是RSM的可见单元偏置
c是RSM的隐单元偏置
WL是RSM的隐单元与类别单元的连接权重矩阵
a是RSM的类别单元偏置
对于所有的隐单元节点i
从后验概率Q (hi|X+)采样h+i∈{0,1}
对于所有的可见单元j
对x-j进行多项采样,得到新的X-
从后验概率Q (ll=1|h+)采样l-i∈{0,1}
对于所有的隐单元节点i
权值更新
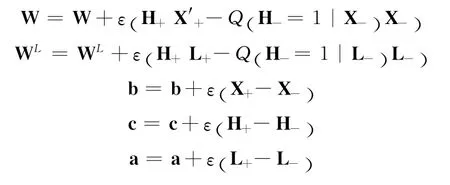
3 实验结果及分析
3.1 重构率实验
对于RBM通常通过重构误差[12]来对其进行评价。
从图4可以得出,sRSM模型的重构误差下降速度要高于RSM,其模型收敛效率和学习能力要强于RSM模型。

图4 RSM与sRSM重构误差对比
3.2 文本检索实验
在设计完成sRSM模型以后,采用具有类别属性的20-newgroups作为文本训练集对模型的文本表示性能进行测试。
20-newgroups文档集共包含18845篇文章,整个文档集被分为20个不同的新闻组,每一个新闻组包含不同的主题。整个数据被分为11314个训练样本和7531个测试样本。首先对文本去除停用词和无用词;再次提取信息增益最大的前5000个词汇整合为字典库;最后将每个文本转变为向量的形式。
模型对文本表达能力的检测可以通过简单的文本检索指标进行判断。通常评价文本模型在信息检索的效能指标有两个

由于Ruslan Salakhutdinov在文献[6]中已经表明RSM模型对文本的表示能力已经优于目前常见的文本表示模型LDA[13],因此新模型sRSM只需要与标准的RSM进行比较即可。
在实验中,均将隐单元个数设置为120,即M=120;由于20-newgroups中类别个数为20,则sRSM中的类别单元个数为5,即L=5,类别数据对应的类别单元的值即为其二进制编码。
由于数据集较为简单,在实验中,判断文档集中的文本是否与查询文本相关的判断标准是两个文本是否具有的相同的类别标签。对于一个给定的测试文档,所有的训练文档按照cosine相似度进行排列,然后依次计算检索出最相关的1,2,4,8,16,…篇文档的查准率和查全率;并且对所有测试文本的计算结果进行平均化,得到其查全—查准曲线(RPC)如图5所示。
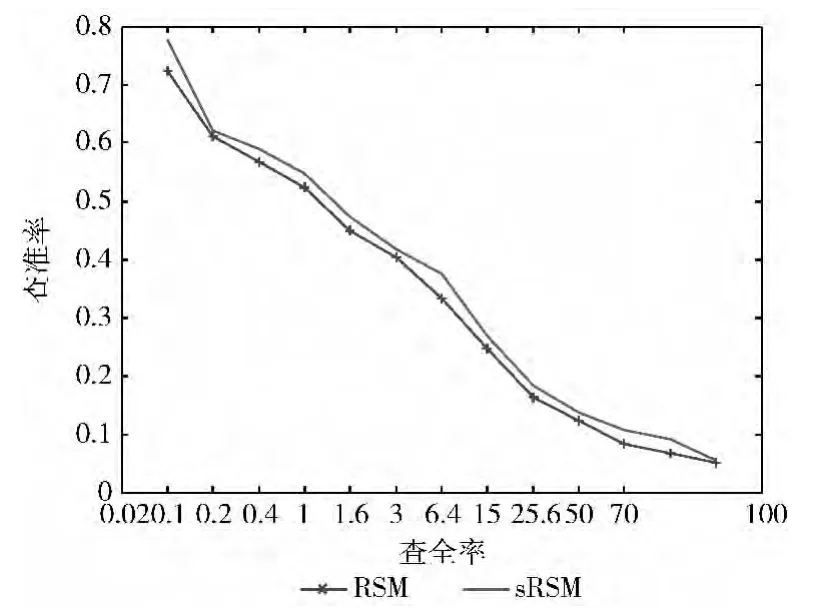
图5 sRSM和RSM的RPC
由图5可以看出,sRSM要优于RSM,特别是针对小样本选择的情况。
4 结束语
本文采用基于监督的sRSM,实现了对带有类别属性的文本信息的有效提取。相对于已有的文本信息提取方法,该方法既保留了标准RSM模型简单、计算隐单元(主题单元)概率快速的优点,又能够利用类别单元实现更迅速的学习。此外该模型还可以应用到无类别属性的文本信息处理,具有较广的应用范围和较高的工程价值。
[1]LeCun Y,Chopra S,Hadsell R.A tutorial on energy-based learning[J].Predicting Structured Data,2006,20(111):489-548.
[2]Andriy Mnih,Hinton G E.A scalable hierarchical distributed language model[C]//Vancouver:Advances in Neural Information Processing System,2008:1081-1088.
[3]Sungjin Ahn,Anoop Korattikara,Max Welling.Bayesian posterior sampling via stochastic gradient fisher scoring[C]//Edinburgh:Proceedings of the 29th International Conference on Machine Learning,2012:1552-1560.
[4]Salakhutdinov R,Hinton G E.Semantic hashing[J].International Journal of Approximate Reasoning,2009,50(7):969-978.
[5]Gehler P V,Holub A D,Welling M.The rate adapting poisson model for information retrieval and object recognition[C]//Montreal:Proceedings of the 23rd international conference on Machine learning,2006:337-344.
[6]Hinton G E,Salakhutdinov R.Replicated softmax:An undirected topic model[C]//Vancouver:Advances in Neural Information Processing Systems,2009:1607-1614.
[7]Hugo Larochelle,Ian Murray.The neural autoregressive distribution estimator[C]//Fort Lauderdale:Proceedings of the 14th International Conference on Artificial Intelligence and Statistics,2011:29-37.
[8]Larochelle H,Lauly S.A neural autoregressive topic model[C]//Lake Tahoe:Advances in Neural Information Processing Systems,2012:2717-2725.
[9]Srivastava N,Salakhutdinov R,Hinton G E.Fast inference and learning for modeling documents with a deep boltzmann machine[C]//Atlanta:Proceedings of the 30th International Conference on Machine Learning.2012:493-510.
[10]Hinton G E.A practical guide to training restricted Boltzmann machines[R].Toronto:Machine Learning Group University of Toronto,2010:129-136.
[11]Hinton G E.Training products of experts by minimizing contrastive divergence[J].Neural Computation,2002,14(8):1711-1800.
[12]Wallach H,Murray I,Salakhutdinov R,et al.Evaluation methods for topic models[C]//Montreal:Proceedings of the 26th International Conference on Machine Learning,2009:1105-1112.
[13]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].The Journal of Machine Learning Research,2003,3(10):993-1022.
