交通信息分布式处理中的Hadoop调度算法优化
2014-02-09孙卫真王秀锦徐远超
孙卫真,王秀锦,徐远超
(首都师范大学信息工程学院,北京100048)
0 引 言
随着交通信息采集技术的改进和发展,城市交通数据量迅速增长。经过2008年奥运会,京交会及园博会等大型社团活动的交通数据多年的积累,以及出租车行业,特种行业浮动车的数据汇集,交通数据量大且复杂,地理分布广泛,数量已达到并超过PB级。因此,对这些交通数据进行数据挖掘和建模、实时提取和处理进而反馈诱导和交通控制已经成为智慧城市的必需。利用分布式计算任务调度服务程序实现计算机集群资源的统一调度是提高交通信息提取和分析准确率以及信息实时性的有效方法。
Map Reduce(映射和化简)[1]是分布式计算框架中最为通用和重要的一个,其开源实现Hadoop(分布式处理软件框架计算平台)技术自发布以来就得到广泛的推广和应用。该平台不仅开源而且适合将各种资源、数据等部署在廉价的计算机上进行分布式存储和分布式管理[1]。
城市智能交通系统要将海量的交通信息在数据处理平台上快速地部署和任务调度,以便为出行者提供及时有效的交通信息,满足用户的实时性要求。Hadoop是用于对海量数据进行分布式处理的并行系统,在大型集群上对数以万计的作业和任务执行调度,要想使得系统能够高效完成用户提交的任务,就需要对平台的调度算法进行优化,以期获得较好的运算效率。
为了提高Hadoop平台对海量交通数据的处理能力,在开源框架Hadoop性能以及智能交通数据处理算法的基础上,针对城市交通数据特点,提出了适合不同交通数据类型的改进型计算能力调度算法,以期提高海量智能交通数据的处理效率。
1 分布式调度算法
当前Hadoop平台下最常用的作业调度算法有FIFO(先进先出调度)算法、fair scheduler(公平调度)算法和capacity scheduler(计算能力调度)算法3种。在分布式系统中,作业的调度以及计算能力的均衡和计算节点的效率是衡量一个算法优劣的主要指标,提高分布式计算的效率也必然从这几个方面对调度算法进行改进。Zaharia M等人针对多用户并发作业提出了一种基于细粒度资源共享的公平调度算法——Quincy,在数据量减少一小部分的情况下可大幅度提升集群的吞吐率[2];2010年Isard M等人使用600台计算机组成的集群,通过处理Facebook数据证明公平调度与数据的本地化是一对矛盾体,并且在公平调度算法的基础上加入了延时调度的思想,大幅度提升了数据的本地化比例[3];Yahoo公司开发的“计算能力调度算法”模拟出具有指定计算能力的独立的集群资源为不同用户作业提供服务,此算法分为队列间的调度和队列内调度[4,5]。多个队列可以保证每个队列的计算能力,并且计算能力调度是一种基于资源的调度,计算更具有灵活性。
但是计算能力调度算法没有全面考虑用户多样性的特点,在单队列中的调度仍然采用的是先进先出的策略;另外交通信息的实时性和紧急性决定了在处理此类信息的算法中必须具有很强的交互性,并且算法的实时性与本地化计算比例密切相关。
所以针对交通信息数据的特殊性,调度队列在分配作业时需要有更好的匹配策略[4,6];交通数据短作业较多,作业类型不同,所以作业之间的相互依赖关系会变得更加复杂,这也势必会增加计算中的延时[7]。因此在分布式系统中处理交通数据,需要根据城市交通的特点设计出适合其应用的调度算法,从而提高资源的利用率,提高平台的计算效率。
2 Hadoop调度算法及优化
基于对分布式作业调度算法的研究以及对城市交通信息数据的分析,针对大规模分布式离散的交通信息处理提出了基于计算能力调度算法的改进算法,即在原算法的基础上加入了多种作业调度的策略,包括先进先出结合短作业策略、紧急抢断策略、作业队列匹配策略和延时调度策略。改进后的算法继承了经典计算能力调度算法多队列作业调度模型所具有的稳定性、扩展性和并行性好的优势,并对交通信息数据的处理具有针对性。
计算能力调度算法支持多个队列,以保证其计算能力,考虑到交通信息中用户具有多样性,设计队列时按不同类型简单划分为长作业队列和短作业队列,长作业队列专门处理大作业,短作业队列可专门处理小作业,这样对作业的处理针对性强,可提高作业处理效率。队列划分的实现需要额外设计一个作业筛选器,专门负责将作业划分归类,归类流程如图1所示。
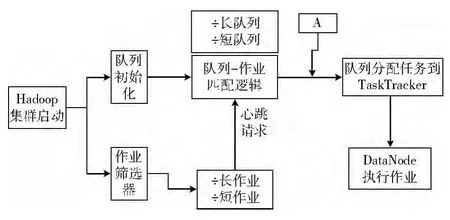
图1 队列与作业划分匹配筛选
筛选器在初始化队列时将队列根据需要划分成长时作业队列与短时作业队列,作业调度器收纳作业,将不同的作业类型分别排队,形成不同类型的作业队列。同时对队列类型的属性做一些配置上的优化,比如短作业类型的队列,此种作业规模比较小,但往往比较多且杂,可以在初始化时将min Map和min Reduce参数调整为较大值。针对交通数据而言,经初步统计这样的作业占据大多数,所以资源分配的比重相应也较大。通过改变参数值和加权处理,不同类型的作业在执行时变得有序、高效,而且能够取得较好的交互性。
在经典的计算能力调度中,在单个队列中默认采用的是先进先出的调度策略,这虽然易于实现,但对于处理交通信息数据这一类的分布式数据并不适用。在海量交通信息中,数据量虽然庞大,但单个作业规模往往并不会呈现出大文件的趋势,而是区域化的短作业会比较多,这时若有长作业一直占用系统资源运行会使得短作业迟迟得不到执行而形成饥饿。所以针对特定的交通信息在这里将算法设计成“基于先进先出原则的短作业优先”策略,即在短作业优先执行的前提下,再按先进先出算法进行作业队列排序,流程图如图2所示。

在单个作业队列内部,如果用户提交的作业中有各种不同类型的作业,例如复杂计算的大作业,简单处理的小作业,强数据依赖型作业,弱数据依赖型作业等。当按照某一调度策略(如小作业优先)时,往往小作业会出现在同一队列的不同节点上,这个时候如果按照小作业队列优先执行,那么可能会形成较大的网络数据流量,造成网络阻塞。所以在保证小作业优先执行的情况下,为了不影响网络的负载能力,需要加入延时调度策略,将短作业优先调度改进策略与延时策略相结合,改善网络间通信的质量。程序设计见下列语句:
收纳作业并将作业Job List初始化为队列
if节点D发送HeartBeat到master then
if节点D释放SparePool then
for作业(循环)
J=Job List.get(n),0=<Job List.length(),n++;
if作业J有一个在节点D上的本地性任务then
立即运行
elseif网络负载>=M then
调用延时函数delaysometime();
if作业J.wait<T then
立即执行长任务或者强依赖型任务或者本地性较强的任务;
else
停止延时函数;
endif
endif
endfor
endif
endif
在上述调度策略下,如果出现较大的网络流量负载,当达到阈值M时,它会自动触发延时调度函数,并且在延时调度期间计算机资源会转向运行其它长作业或者依赖型作业以及其它数据本地性较强的作业。延时调度的时间有一个最大值T,可以根据网络负载状况做实时调整。延时策略有利于加强数据的本地性,有利于减小节点间网络数据传输压力,特别地对分布式计算系统有实际使用价值。
交通信息的实时性和突发性决定了在处理此类信息的算法中应该具有很强的交互性,这时需要引入紧急作业抢断资源的算法来实现。对于常规调度算法来说,如何选择下一个合适的作业运行是其核心问题,所有队列预先被初始化为一个资源量,如果有队列处于空闲状态,它的资源将被分配给当前最忙的队列。所谓忙,是指正在运行的作业数与分配所得资源的比BR
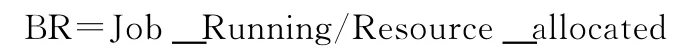
比值越大越忙。这表示计算能力调度算法所具有的特性。但是如果在所有队列间的队列都无空闲资源的情况下,遇到突发情况,某一作业需要紧急执行,就需要把低优先级的作业先挂起,暂时把系统资源让给紧急性作业。等紧急作业执行完毕,释放资源后再根据当时的优先级情况判断是否继续执行暂停的作业。改进后的状态转换如图3所示。
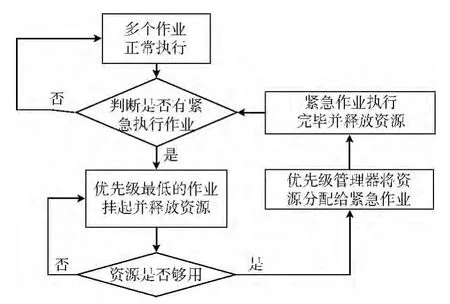
图3 紧急作业抢断资源下的状态转换
3 算法实现及实验结论
改进后的算法中依然是使用3种粒度的对象:queue(队列)、job(作业)和task(任务),分别维护着相关作业的一些信息。基于改进型计算能力算法是基于计算能力调度的改进,所以基本上保持了计算能力调度算法的架构。算法实现的代码主要由5个java程序组成,改进的算法结构如图4所示。

从图4中可以看出,此改进算法的核心类是ECapacity TaskSheduler,与之关联的类主要有文件配置类ECapacityShedulerConf,初始化类EJobInitialzationPoller,队列管理类EJob Queue Manager和内存容量匹配类EMemory Matcher。
核心类ECapacity TaskSheduler中有各种不同功能的方法,其中有调度器初始化函数start(),该函数初始化各种对象和变量等并加载配置文件;当其中有一个Task Tracker的HeartBeat到达Job Tracker时,如果有spare的slot,Job Tracker(作业追踪器)会调用调度器ECapacityScheduler中的assign Task(),该方法会根据Task Tracker的需要找若干个合适的task。本文算法的改进主要是在原计算能力调度算法框架下添加一些变量和函数,以达到提高处理交通信息数据效率的要求。添加的变量主要包括Task-Type、weigh、isShortJob等;添加的函数包括:优先级设定与获取函数setJobPriority()/getJobPriority(),短作业判定函数isShortJob(),队列类型作业类型匹配函数matchJoband Queue(),延时调度函数delaysometime()。重新编写了sort Queue()方法,主要是在重新排序队列时加入了短作业优先级等属性,还在配置文件conf中做了一些文件设定的参数配置与修改,包括map,reduce最大最小数目,队列分配容量百分比,最大负载能力等。
实验测试环境采用了3个数据节点,一个主节点,PC机的设置均对等相当。Hadoop平台搭建好之后,为保证新的改进型调度算法的有效执行需要从以下几个方面进行优化:
(1)优化应用程序。由于Map Reduce的算法是逐行迭代来解析数据文件的,所以为提高程序的编写效率,应优先设计优化迭代算法。
(2)Hadoop系统参数的优化。主要包括:Linux文件系统参数调整,文件挂载时设置noatime和nodiratime这两个属性可以明显提高文件系统的性能,在可行的范围内调整Readahead buffer参数可以明显改变文件顺序读取的性能,其实际上是修改Linux操作系统中文件缓冲区的容量。另外要避免在Task Tracker和Data Node节点上执行RAID和LVM的操作;Hadoop通用参数调整,namenode、jobtracker、datanode中用于处理RPC(远程过程调用)的线程数的参数以及HTTP server上运行的线程数的参数,在针对不同规模的集群时需要做相应的调整与设置;Hadoop作业调优参数设置:主要包括Map(映射)阶段的中间结果及最终结果的压缩和Reduce(简化)阶段task的参数调优。
为了测试改进型算法的有效性,实验模拟交通信息数据的特点,采用两种类型的测试场景及用例,I/O密集型WordCount和计算密集型Sort,采用控制变量法,分别统计多用户多作业提交模式下,不同算法和不同数据规模的作业平均运行时间。
I/O密集型计算指的是系统的CPU多处于空闲状态,而I/O(硬盘/内存)的繁忙率较高,系统运行时往往呈现出CPU的利用率较低。在I/O密集型的测试中,本实验采用了词频统计WordCount基准测试样例。采用该测试样例的原因是词频统计的数据结构与交通数据中离散分布的数据结构十分类似,如统计某一段时间里各个路口小轿车,巴士,大货车等各类型车辆的通过数量以及其速度等,这和WordCount的词频统计是十分类似的。其实验结果如图5所示。
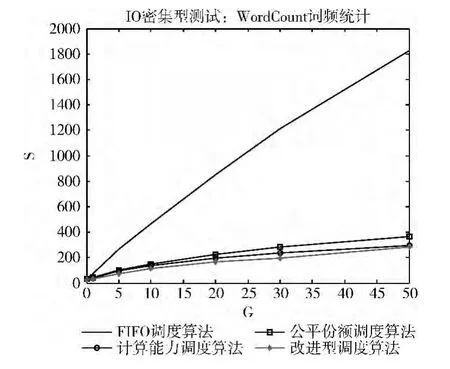
图5 I/O密集型计算不同调度算法效率对比
从图5的统计图可以看出,在多用户多作业条件下,先进先出算法对于I/O密集型的计算效率明显不及公平调度、计算能力调度以及改进型计算能力调度算法,在这种情况下,选用FIFO算法是非常不明智的做法,另外对于多用户多作业情况下,数据规模越大,计算能力和改进型计算能力调度算法为最优算法,改进的算法比原算法稍有提高。
计算密集型指的是系统的I/O(硬盘/内存)繁忙率相对CPU的繁忙率要低,系统运作时,往往是I/O(硬盘/内存)的读/写时间较短,需要等待CPU的处理。在计算密集型的测试中,实验数据采用了一周的某出租汽车公司的GPS信息,提取其中的路径和平均速度。分别测试了经典算法以及改进算法下的数据处理性能。其实验结果如图6所示。

图6 计算密集型不同调度算法之间的效率对比
从图6可以看出,此次实验的执行时间的增长幅度要大于I/O密集型计算。在多用户多作业模式下,对于数据量小于5G的作业,4种算法执行时间相当;对于数据量大于5G的作业,改进的计算能力调度算法的执行时间相比其它3种算法较短,并且增长速度较缓慢,而先进先出算法在此种情况下表现最不佳,公平算法次之。
两次实验结果均显示改进型的调度算法相较之前的计算能力调度算法性能有所提高,说明本文所述的改进方向是可行的。
对于紧急作业抢断资源的算法通常是通过设定作业优先级的方法来实现的。在实验中,不同优先级下作业的运行时间是不同的,这主要是基于调度分配的队列和该队列所拥有的资源所决定的。实验中采用改进型计算能力算法为测试算法,初始资源分配百分比为40%,在单一紧急作业模式下(即只有一个紧急作业进行资源抢断),计算机三机集群分别运行在I/O密集型和计算密集型数据集上,测试用例数据规模为1GB,结果见表1和表2。
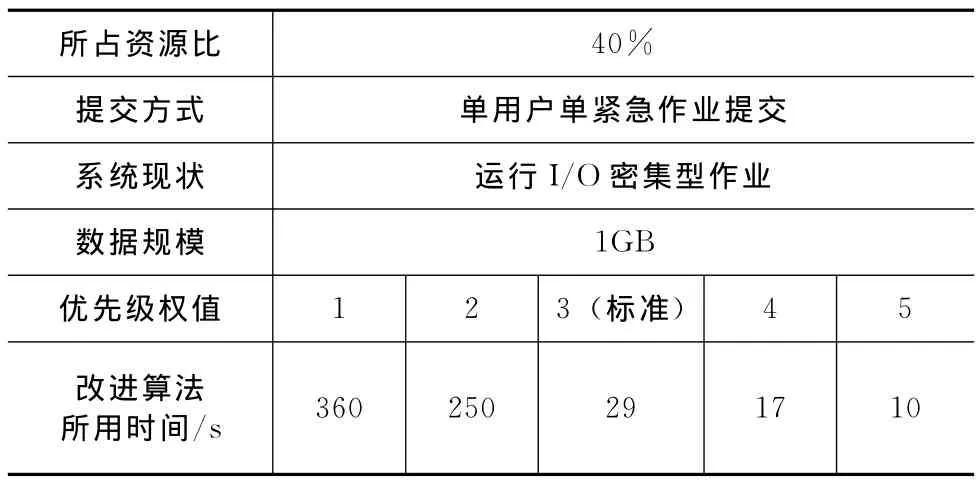
表1 紧急作业在不同优先级下运行时间统计1

表2 紧急作业在不同优先级下运行时间统计2
从表1和表2的结果中可以看出,优先级分为5级,从1到5依次升高,最高优先级为5。在各级不同的优先级中,一般会在标准或以上优先级时才执行抢先策略。作业会抢占系统资源来运行优先级高的作业。当达到最高优先级时,该作业所用时间最少,结果很明显;对于低优先级的作业,它们的运行时间凸显出很长(如表1中优先级值为1和2时),有时还不能确定(如表2中优先级值为1和2时),原因是如果有高优先级的作业在提交运行,且高优先级作业源源不断,则低优先级的作业就难以得到运行,除非等到没有高优先级的作业提交,它才可以进入队列进行排队等待被调度。这种现象在计算密集型作业中特别明显,各个队列的资源几乎被常规作业占用,紧急作业难以抢断,呈现出一种“饥饿”的状态。相对I/O密集型的作业,由于I/O切换期间会短暂出现队列空闲的现象,所以呈现出来的运行时间可信,但也是大大高于标准或以上优先级的运行时间。因此,对于紧急事件,一定首先赋予该作业较高的甚至是最高的优先级,同时辅之以其它措施,例如,可以暂时延时其它作业的调度等,以保证紧急作业得到优先执行。
4 结束语
依据城市交通信息数据特点,对传统计算能力调度算法进行了优化与实现,弥补了传统算法的不足之处,使得优化后的算法能够适应城市智能交通数据处理,实验结果表明,改进的计算能力调度算法无论是从交互性,还是从数据处理性能上,在处理大规模分布式的城市交通数据时都具有一定的优势。城市交通将会是未来海量数据研究的重点之一,下一步将使用该算法对城市交通数据进行更深层次处理,探索更加实际的应用,以满足用户的需求。
[1]XU Xiaolong,WU Jiaxing,YANG Geng,et al.Mass data processing system based on large-scale low-cost computing platform[J].Application Research of Computers,2012,29(2):582-585(in Chinese).[徐小龙,吴家兴,杨庚,等.基于大规模廉价计算平台的海量数据处理系统的研究[J].计算机应用研究,2012,29(2):582-585.]
[2]Zaharia M,Borthakur D,Sen Sarma J,et al.Delay scheduling:A simple technique for achieving locality and fairness in cluster scheduling[C]//Proceedings of the 5th European Conference on Computer Systems.New York:ACM,2010:265-278.
[3]Isard M,Prabhakaran V,Currey J,et al.Quincy:Fair scheduling for distributed computing clusters[C]//Proceedings of the 22nd Symposium on Operating Systems Principles.New York:ACM,2009:261-276.
[4]DENG Chuanhua,FAN Tongrang,GAO Feng.Resource scheduler algorithm based on statistical optimization under Hadoop[J].Application Research of Computers,2013,30(2):417-419(in Chinese).[邓传华,范通让,高峰.Hadoop下基于统计最优的资源调度算法[J].计算机应用研究,2013,30(2):417-419.]
[5]WANG Feng.Scheduling algorithm of Hadoop cluster job scheduling algorithm[J].Programmer,2009,10(12):1-19(in Chinese).[王峰.Hadoop集群作业的调度算法[J].程序员,2009,10(12):1-19.]
[6]Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[7]You H H,Yang C C,Huang J L.A load-aware scheduler for Map Reduce framework in heterogeneous cloud environments[C]//Proceedings of the 2011 ACM Symposium on Applied Computing.New York:ACM,2011:127-132.
[8]Fischer M J,Su X,Yin Y.Assigning tasks for efficiency in Hadoop[C]//Proceedings of the 22nd ACM Symposium on Parallelism in Algorithms and Architectures.New York:ACM,2010:30-39.
[9]Liu X,Lu F,Zhang H,et al.Estimating Beijing's travel de-lays at intersections with floating car data[C]//Proceedings of the 5th International Workshop on Computational Transportation Science.New York:ACM,2012:14-19.
[10]Edwards M,Rambani A,Zhu Y,et al.Design of Hadoopbased framework for analytics of large synchrophasor datasets[J].Procedia Computer Science,2012,12:254-258.
[11]DING Yuguang,LIU Wenjie,WANG Weilin.Research on capacity scheduling algorithm based on QoS constraints[J].Journal of Sichuan University of Science &Engineering(Na-tural Science Edition),2012,25(3):47-50(in Chinese).[丁宇光,刘文杰,王卫林.基于QoS约束的计算能力调度算法研究[J].四川理工学院学报(自然科学版),2012,25(3):47-50.]
