基于MCMC模拟和伪似然估计法的交叉分类信度模型费率厘定
2014-01-01康萌萌孟生旺
康萌萌,孟生旺
(1山东财经大学 保险学院,山东 济南250014;2中国人民大学 统计学院,北京100872)
一、引 言
信度模型是非寿险精算学中最为重要的成果。从20世纪初至今,信度理论先后经历了两个发展阶段:一是早期的有限波动信度理论;二是现代以贝叶斯理论为基础的最精确信度理论。有限波动信度方法旨在限制数据中的随机波动对估计的影响,虽强调了结果的稳定性,但缺乏坚实的统计理论支持,因此其研究相对较少。现代信度理论之父Arthur Bailey将贝叶斯方法引入信度理论的研究中[1];20世纪60年代末,瑞士精算家Bühlmann提出简单Bühlmann信度模型,在均方误差最小意义下导出了信度保费的公式,在某种意义上这是最接近真实风险的保费估计值[2]。随着信度理论不断发展,信度模型变得越来越灵活,出现了各种更加符合实际的 信 度 模 型,如 Bühlmann-Straub 模 型、Hachemeister模 型、Jewell分 层 模 型 等[3]129-163[4]。Dannenlurg借助方差分量法引入了交叉分类的信度模型,在该模型中所有风险因子均被视为有可能存在交互影响,建立了计算信度估计值的公式,该公式通过把风险变量分解添加到相互独立的方差分量中求得信度估计值[5]。Dannenlurg通过矩估计方法给出了交叉分类信度模型结构参数的估计和保费预测值,然而用矩估计方法估计出来的参数依赖于现有历史数据,在数据资料不充足的情况下很难得到参数的无偏后验估计。同时,矩估计方法计算繁杂,大大限制了交叉分类信度模型在实践中的应用。因此,笔者主要考虑使用贝叶斯方法和来估计参数,预测保费。
在实际应用中,利用贝叶斯方法分析信度模型存在两点困难:一是基于历史经验数据对条件密度和结构函数的估计比较困难;二是即使知道或者估计出条件密度和结构函数,但是由于积分计算的困难和复杂,也很难得到贝叶斯保费的显示表达式。由于这两个方面的困难,使贝叶斯保费的应用受到极大的限制。近几年,随着计算机技术的发展和贝叶斯方法的改进,特别是马尔可夫链蒙特卡洛方法的应用,使原来异常复杂的数值计算问题迎刃而解,对参数后验分布的模拟也更为方便。随着现代贝叶斯理论及其应用的日趋成熟,许多学者开始利用贝叶斯方法估计信度模型的参数[6]。同时,通过对交叉分类信度模型的分解发现交叉分类信度模型的结构与纵向数据极为相似,因此可以利用纵向数据的方法对其进行分析。譬如Frees等人将5种基本信度模型表示为线性混合模型的形式,用最小无偏估计量估计信度保费[7];Antonio等则在gamma分布假设下,将广义线性混合模型用于交叉分类信度模型的费率厘定[8];康萌萌假设在因变量服从泊松、过离散泊松和负二项分布的情况下,用广义线性混合模型厘定了信度保费[9]。
针对传统交叉分类信度模型中结构参数无偏估计的不足和计算过于繁杂,本文构建了基于模型的交叉分类信度模型,并借助于MCMC模拟中的Gibbs抽样,通过WinBUGS和SAS软件包进行仿真分析,得到模型中索赔额的后验分布以及保费预测值。
二、交叉分类信度模型及其参数估计
(一)交叉分类信度模型
Dannenburg D.(1995)借助方差分量方法引入了交叉分类的信度模型,通过带有违约风险的贷款模型给出了双向交叉分类模型的模型形式和参数估计方法。在此模型中,将债务人的婚姻状况和在目前公司的工作时间作为两个风险因素。令I为婚姻状况的水平,J为在目前公司的工作时间水平,I=J=3,两个风险因素都有三个水平值。婚姻状况分为单身、离异、其他三个层次(i=1,2,3);工作时间分为少于两年、两年至十年、十年以上三个层次(j=1,2,3)。此时,两种分类因素地位是对等的,所以采用交叉分类信度模型,两个因素的交互作用也包括在模型中。令Kij为婚姻状况第i类和工作时间第j类的观测个数,即(i,j)中的观测个数,Xijk为(i,j)中第k个观测。观测总个数为401,数据是不平衡的,即每个(i,j)中的观测个数不相等。交叉分类信度模型假设:
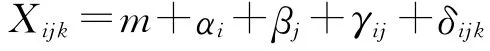
其中αi,βj,γij,δijk被认为是独立随机变量,均值为0,方差分别为为已知数,在本例中为1;模型中的参数都是未知数,必须利用已知数据进行估计出来反映了与个体风险因子无关的小组与小组之间的变化,刻画了小组内部风险的变化情况;αi,βj分别为婚姻状况、工作时间观测值的主要效应,其方差分别为,反映了不同婚姻状况、不同工作时间之间的变化情况。
(二)交叉分类信度模型参数估计
Dannenburg D.采用矩估计方法对交叉分类模型进行了估计,计算过程如下所示:

三、基于MCMC方法的交叉分类信度模型参数估计
(一)MCMC方法
在贝叶斯分析中要对后验分布的统计特征进行归纳,如计算各阶矩、分位点等,就需要计算关于后验分布f(θ|x)的各种积分。当f(x|θ)、f(θ)所表示的密度函数具有高维特征或比较复杂时,采用推导的方法来直接计算后验分布f(θ|x)就变得非常困难。为了解决这一困难引入MCMC方法,MCMC方法是一种特殊的蒙特卡洛方法,它通过对马尔可夫链进行蒙特卡洛模拟,使得到的后验分布为马尔可夫链的平稳分布,进而计算后验分布的积分。本质上,MCMC方法是使用马尔可夫链的蒙特卡洛积分,蒙特卡洛积分是通过抽样点{x(t),t=0,1,…}来估计函数h(X)的期望,其估算公式为:

这样通过估计h(X)的均值可以得到总体的均值,当抽样点 {x(t)}相互独立时可以增加抽样次数n来提高估计精度,并且经过一段时间的迭代而X(t)的分布可以收敛到一个平稳分布。这时,MCMC算法的估算式应当去掉收敛以前的迭代而用收敛后的迭代值来估计。在客观应用中,判断是否收敛可以通过观察WinBUGS软件中的轨迹图来进行。至此,可以把MCMC方法概括为如下三步:
第一,在X上选一个“合适的”马尔可夫链,使其转移核为p(·|·),“合适的”含义主要指π(X)应是其相应的平稳分布。
第二,由X中的某一点X(0)出发,用第一步中的马尔可夫链产生点序列X(1),…,X(n)。
第三,对某个m和大的n,任一函数f(x)的期望估计如下:

由于MCMC方法的基本思想是通过建立一个平稳分布为π(x)的马尔可夫链来得到π(x)的样本。因此,构造转移核使已知的概率分布π(x)为平稳分布是至关重要的。不同的转移核将导致不同的MCMC方法、如 Metropolis-Hasting迭代法、Gibbs样本法等,而Gibbs样本法由于计算原理比较简便而被广泛应用。
Gibbs抽样的关键在于仅需要考虑单变量条件分布,这样的条件分布比复杂的联合分布更容易计算,而且通常在形式上更简单(通常是正态分布、逆卡方分布或者其他的一般先验分布)。因此,对n个单变量条件分布里面的n个随机变量依次计算要比直接对联合分布里的一个n维向量积分容易得多。
记X= (X1,…,Xn)T,X-i= (X1,…,Xi-1,Xi+1,…,Xn)T。若Xi|Xi-1=x-i的单变量条件密度f(xi|x-i),i=1,…,n易于被抽样,那么从初值x(0)开始,一次完整的Gibbs抽样要经过以下三个步骤:
(1)选择一个x(t)组成的点序列。
(2)对(1)中所选顺序的每一个i抽取Xi*|x(-ti)~f(xi|x(-ti))。
(3)当(2)对X的每一个组成以选定顺序完成以后,令X(t+1)=X*。
记x(t)=(xt1,…,xtn),则x(t)到x(t+1)的转移概率函数为:

(二)实证分析
根据Dannenburg D.交叉分类信度模型:
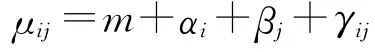
假定:①αi,βj和γij相互独立,且αi~ormal(0,Γα),βi~normal(0,Γβ),γij~normal(0,Γγ)。
②Xijk服从均值为μij、方差为Γδ的正态分布。
③m服从均值为μm、方差为Γm的正态分布。
④以上分布的先验分布为:μm~normal(0,0.000 001),Γm~gamma(0.1,0.01),Γα~gamma(0.1,0.01),Γβ~gamma(0.1,0.01),Γγ~gamma(0.1,0.01),Γδ~gamma(0.1,0.01)。

本文利用Winbugs对模型进行估计。WinBUGS是英国剑桥公共卫生研究所推出的利用MCMC方法进行贝叶斯推断的专用软件包,使用WinBUGS可以很方便地对许多常用的模型和分布进行Gibbs抽样,编程者只要设置好变量的先验分布并对所研究的模型进行一般性描述,就能很容易实现对模型的贝叶斯分析。在WinBUGS中可以使用有向模型方式对模型进行直观的描述,也可以直接编写模型程序。Gibbs抽样收敛后,可以得到参数的后验分布的均值、标准差、95%置信区间和中位数等信息,并给出后验分布的核密度估计图、参数的Gibbs抽样动态图等,使抽样结果更直观、可靠。为了减少参数自相关的影响,保证模拟的结果具有随机分布的性质,共进行0000次模拟后选取第100 00~100 000次的结果作为样本,结果见表1。
从表1中可以看出,模型抽样模拟结果厘定出了两个风险因素不同分类组合下一年的经验平均赔付额Yij=Xij,Kij+1,也叫贝叶斯保费,即表1中y[i,j]的均值,例如在婚姻为单身、工作时间少于两年的组中,下一年的贝叶斯保费为187。MC error表示MC误差是用于描述模型模拟效果的,由样本的均值和后验分布的均值比较得到。Jimmy Fox等人曾指出,当参数的后验分布的估计比较正确时MC误差应当比较小。通常MC误差小于标准差的1/20时就可以认为达到了要求。5.00%和95.00%分别表示分布的5%分位点和95%的分位点。从表1中可以看到,该模型模拟结果的标准差和MC误差都很小,说明模型具有很好的稳定性,且表1中给出了贝叶斯保费均值、5%的分位点、中位数和95%的分位点,从而为保险公司厘定保费提供了一定的参考范围。另外,在WinBUGS中可以设定其他的分位点,公司可以根据需要来获得想要的数据范围。

表1 Winbugs90 000次抽样迭代参数后验估计统计量表
四、基于伪似然法估计法的分层交叉分类信度模型参数估计
(一)广义线性混合模型
广义线性混合效应模型(Generalized linear Mixed Models,GLMMs)常用来分析非独立响应变量的数据,如纵向数据和重复测量数据,它是在广义线性模型的基础上,在线性预测中引入随机效应,通过随机效应表现重复测量值间的相关结构,从而克服了过度离散和总体异质性问题。不足的是由于模型中包括了随机效应,似然函数可能包括高维数值积分,使边际似然计算复杂化,最大似然估计变得非常困难,甚至没有可能,所以过去一段时间大多数研究者一直致力于寻找避免复杂积分而容易估计的算法程序。
假定要分析的数据由N个对象的观测值组成,ni代表对于第i个对象的观测次数,一般情况下N是相对于各个ni来说较大的值。Yi=(Yi1,Yi2,…,Yini)′是对第i个对象的观测向量。在给定第i个对象的随机效应bi的条件下,Yi1,Yi2,…,Yini是来自某一指数族分布的独立的随机变量,即:

其中φ(·)和c(·)是已知函数,θ是自然参数,φ为尺度参数。连接函数为:

其中β(p×1)为固定效应;bi(q×1)为对应于第i个观测对象的随机效应,随机效应反映了各观测对象间的异质性以及同一个对象不同观测间的相关性;Xi(ni×p)和Zi(ni×q)分别为对应于p个固定效应和q个随机效应的设计矩阵。
再假定随机效应bi(i=1,…,N)独立同分布,其密度函数为π(bi|D),其中D为随机效应bi的协方差,是未知参数。关于未知参数β和D的似然函数为:

其中的积分是关于随机效应bi的q维的积分,在一般情况下该积分很难直接积出,因此要求似然函数关于未知参数的最大值需要用数值积分或者Bayes方法等。本文采用 Wolfinger和O’connell(1993)提出的伪似然法,伪似然法用加权正态混合模型通过迭代分析线性化伪变量来使准似然函数最大化。这种方法被称为“伪似然”,因为每次迭代最大化的拟似然函数是伪变量而不是原始数据。
SAS程序中PROC GLIMMIX过程运用上述方法估计非线性混合模型。该SAS程序中提供了不同的线性化方法,其默认方法为限制性/残差虚拟似然法,产生的虚拟似然函数可用不同的最优化技术加以极大化,默认优化技术为Newton-Raphson算法。
(二)实证分析
先对索赔额数据进行简单分析,从直方图(图1)中可以看出,索赔额不呈正态分布有很长的右尾,这与伽马分布和逆高斯分布相似。因此,用这两种模型来描述赔付金额的变化规律,通过箱线图可以看出每组(i,j)索赔额变化不同且相差较大,因此在分析数据时应将随机因素考虑在内。
伽马分布和逆高斯分布的密度函数为:
伽马分布:

逆高斯分布:

其中伽马分布的均值为μ,方差为μ2/v,尺度参数为v;逆高斯分布的均值为μ,方差为σ2μ3,尺度参数为σ。可以证明,伽马分布和逆高斯分布的偏度系数都可以表示为变异系数(CV)的若干倍数,分别为2CV和3CV,因此在均值和方差给定的条件下(此时变异系数也是给定的,它等于标准差与均值之比),逆高斯分布的尾部更厚,因此适合于更加右偏的损失数据。

图1 索赔额分布图
在交叉分类模型中将随机效应引入均值中,即令μij=exp(m+αi+βj),可以得到交叉分类信度模型的广义线性混合模型,并用伪似然函数估计模型的参数(见表2)。
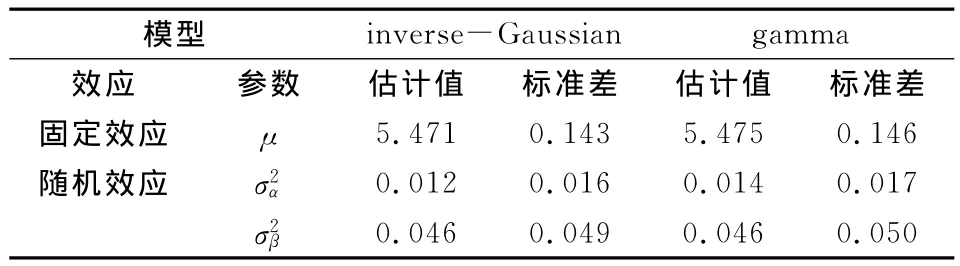
表2 固定效应和随机效应参数估计值表
表2给出了SAS PROC GLIMMIX程序中模型固定效应和随机效应拟合效果。该模型仅有一个固定效应,即μIG=5.471;μGa=5.475,表明了交叉分类模型中索赔额的总均数的对数为5.471(inverse-Gaussian),5.4752(gamma)。在研究总体中索赔额可估计为:PIG=exp(5.471)=237.579;PGa=exp(5.475)=238.698。SAS PROC GLIMMIX程序中用到的数据是伪似然值,所以用其计算的-2LL的值并不能进行模型的比较,并且PROC GLIMMIX过程也不能提供总随机效应的检验,这是目前SAS PROC GLIMMIX程序中存在的缺陷,所以表2中仅给出了随机效应的估计值和标准差。
各组下一年的索赔额可以利用公式μij=exp(m+αi+βj)求出。表3给出了伽马广义线性混合模型和逆高斯广义线性混合模型的估计值,并且将前面矩估计和MCMC模拟的估计值一同列出。从表3中可以看出矩估计方法、MCMC模拟和广义线性混合模型得到的结果相似,MCMC模拟更为保守一些。

表3 交叉分类信度模型预测值
五、结 论
对于财产保险公司来说,经验估费是保险产品定价中的一个重要环节,也一直是各家公司不断探索、力求完善的一项工作。在交叉分类信度模型中由于历史赔付数据不全,使通过矩估计法对历史数据推断得到的未来年度的保费不仅繁琐,而且具有很大的不可靠性,并且得到的估计结果是确定的点估计,没有给出相应的置信区间。基于矩估计的这些不足,本文讨论了利用MCMC和GLMM方法对交叉分类信度模型进行估计,根据模型的估计情况可以得到下面的结论:
MCMC方法的运用具有以下优势:能够在历史数据不完备的情形下,利用 WinBUGS软件包较容易地预测下一年度的保费;能够直观地表示各参数的后验分布,并据此进行区间估计,相对于传统模型只能进行点估计更为科学;该模型弥补了传统模型的不足,提高了计算精度,对保险公司经验费率厘定方法的改进具有现实意义。
GLMM方法的运用具有以下优点:大大简化了交叉分类信度模型的计算过程;许多统计软件(如SAS)可以处理此类模型,使操作变得更加方便;精算师对费率厘定过程又有了新的解释,可以利用图形和其它诊断工具选择模型,并对模型的实用性做出评价。
[1] Bailey A L.Credibility Provedures,Proceedings of the Casualty[J].Actuarial Society,1950(37).
[2] Bühlmann H.Experience Rating and Credibility[J].Astin Bulletin,1967(4).
[3] Hachemeister C A.Credibility for Regression Models With Application to Trend[M].Kahn P M.Credibility:Theory and Applications,New York:Academic Press.
[4] Jewell W S.The Use of Collateral Data in Credibility Theory:A Hierarchical Model[J].Giorndle dell'Istituto Haliano degli Attuari,1975(38).
[5] Dannenlurg D R,Kaas R,Goovaerts M J.Practical Actuarial Credibility Models[R].Institute of Actuarial Science and Econometrics,University of Amsterdam,1996.
[6] Scollnik D P M.Actuarial Modeling With MCMC and BUGS[J].North American Actuarial Journal,2001(2).
[7] Frees E W,Young V R,Luo Y.A Longitudinal Data Analysis Interpretation of Credibility Models[J].Insurance:Mathematics and Economics,1999(24).
[8] Antonio K,Beirlant J.Actuarial Statistics With Generalized Linear Mixed Models[J].Insurance:Mathematics and Economics,2007(40).
[9] 康萌萌.基于广义线性混合模型的经验费率厘定[J].统计与信息论坛,2009(7).
