基于后缀数组改进的全文索引结构研究
2013-10-15刘畅,张猛
刘 畅, 张 猛
(1. 吉林工商学院 信息工程学院, 长春 130062; 2. 吉林大学 网络中心, 长春 130012)
0 引 言
随着信息技术的快速发展, 网络信息席卷全球, 产生了大量的文本、 图像以及多媒体等各种形式的电子信息资源。如何在浩瀚的网络数据中查询非结构数据----文本, 并对其进行高效的存储, 是目前值得研究的热点问题。其中, 全文检索技术成为国内外学者研究的热点。全文索引结构是一种能高效识别一个文本全部子串的数据结构, 以数据压缩、 模式匹配算法和文本数据库为基础, 在数据挖掘、 生物信息学和数据库中有广泛应用。但是, 全文索引技术的一个主要缺陷是其空间占用率太大, 远高出检索数据的本身, 所以全文索引的巨大存储开销使其应用受到很大限制。
笔者主要研究了一种基于后缀数组[1]的全文索引结构, 此结构可实现一种占用空间极小的压缩的后缀自动机(DAWG: Directed Acyclic Word Graph)[2], 其索引结构的基础是rank[3]和select[4]函数, 在相同数据规模的前提下, 可降低存储空间的占有率, 并不降低存储的效率。通过扩展状态转移函数, 引入加权边, 可得到加权有限自动机模型。在此基础上, 构造一种新的全文索引结构----加权有向词图(WDWG: Weighted Directed Word Graph)[5], 通过实验证明其功能与DAWG相同, 计算速度相当, 但其存储复杂度小于DAWG。
1 基本定义
1) 字符集。一个字符集Σ是建立了全序关系的集合, 它为每个字符分配一个唯一数字, 字符集Σ中的元素称为字符,Σ*代表Σ上的所有字符串集合。
2) 字符串。是由零个或多个字符组成的有限序列, 一个字符串S是将n个字符顺次排列形成的数组, 字符串在存储上类似字符数组, 所以, 每位的单个元素都是可提取的,n称为S的长度,S的第i个字符表示为S[i]。
3) 子串。字符串S的子串S[i..j],i≤j, 表示S串中从i到j一段, 即顺次排列S[i],S[i+1],…,S[j]形成的字符串[6]。
4) 后缀。后缀是指从某个位置i开始到整个串末尾结束的特殊子串。字符串S从i开头的后缀表示为Suffix(S,i), 即Suffix(S,i)=S[i..len(S)][7]。
比特串上rank函数和select函数是压缩的全文索引结构的两个关键操作。对这两个函数的定义如下: rank函数是返回结果集分区内指定字段值的排名, 指定字段值的排名是相关行之前的排名加1, 设T[1..n]是个比特数组, 函数rank1(T,x)和rank0(T,x)分别计算T中的在位置x之前(含x)的1或0的数量。Select函数的机制中提供的数据结构, 实际上是一种long类型的数组, 每个数组元素都能与打开的文件句柄建立联系, 函数select1(T,x)和select0(T,x)分别计算T中第x个1或0在T中的位置。其中rank函数可在常数时间内计算, 且使用不超过n+o(n)比特空间的数据结构; select函数可在常数时间内计算, 且使用空间不超过n+o(n)比特的数据结构。
2 基于后缀数组的全文索引结构
在字符串处理技术中, 后缀树和后缀数组都是非常有力的工具, 其中后缀树介绍较多, 关于后缀数组则很少见于国内的资料。其实, 后缀数组是后缀树非常精巧的替代品, 比后缀树容易编程实现, 能实现后缀树的很多功能而时间复杂度也不太逊色, 并且比后缀树所占用的空间小很多。后缀数组SA是一维数组, 它保存1,…,n的某个排列SA[1],SA[2],…,SA[n], 并且保证Suffix(SA[i]) 由于后缀数组中的索引点是按照语法顺序存储的, 所以后缀数组的检索思想是对其进行二分查找。然而, 后缀数组是存储于硬盘上的大型数据结构(类似于倒排表), 一次查询logn次的随机硬盘读取是无法接受的, 所以后缀数组的检索通常是从上部索引开始, 先通过对内存中上部索引的二分查找确定查找结果的后缀数组范围, 再将这段后缀数组加载到内存中进行二分查找, 以确定结果。但在对后缀数组的二分查找过程中, 需要随机访问位置点文本进行二分查找中的比较, 如果加载到内存中的后缀数组长度为m, 则一次检索需要logm次的硬盘随机访问。笔者认为可构造后缀片段更长的硬盘级别上部索引, 当加载后缀数组时同时加载其对应上部索引, 以加快查找速度。 图1 字符串ababbaa的DAWG 将全文索引结构和后缀数组结构结合, 可实现一种占用空间更小的数据结构----压缩的后缀自动机。在相同数据规模的前提下, 其空间占有率更低, 运行效率与一般的后缀自动机相似。在空间占用方面, 此数据结构使用nlg |Σ|+o(nlg |Σ|)比特, 其中n为输入串的字符数; 在时间复杂度方面, 一个字符的查找时间为O(lg |Σ|)。紧凑索引结构的基础是rank和select函数, 其实现的时间空间复杂度将影响最终的索引结构。DAWG的例子如图1所示。 算法构造如下: SUFFIXAUTOMATON(x)loop SA-EXTEND(l) let δ be the transition function of (Q,i,T,E) T ← Ø (Q,E) ← (Ø,Ø) p ← Ø i ← STATE-CREATIONloop T ← T+{p} Length[i] ← 0p ← F[p] F[i] ← NIL while p≠NIL last ← ireturn ((Q,i,T,E), Lengh, F) for l from 1 up to x 通过对后缀自动机的进一步压缩可建立一种新型的压缩索引数据结构----WDWG, 它是在基于子串集合一致划分的概念基础上建立起来的。加权有向词图是能接受w(w代表字符串)的子串集合的索引结构, 其功能与DAWG相同, 状态数小于等于DAWG, 它们都对输入串只扫描一遍, 即可报告任意输入位置的后缀中最长的模式因子。但WDWG的空间复杂度小于DAWG, 所以可以作为DAWG自动机的替代。可通过删除WDWG中单扇出节点对WDWG进行压缩, 通过定义先构造WDWG, 再删除单扇出节点和边, 并添加多字母边构造得到的OWDWG[8], 可能仍存在可合并的状态, 所以需增加一步合并操作, 以得到更好的结果。 笔者在实验室的PC机上进行以上几种全文索引结构的比较实验, 其CPU的主频1.6 GHz, 内存为1 GByte。实验数据是随机选中的一组文本数据, 中文部分来自我国的古典名著, 英文部分来自Internet上的经济论文数据库, 按照字节计数选定数据的长度。实验结果如表1所示。 表1 WDWG与DAWG空间占用比较 通过以上实验比较了WDWG与DAWG的状态数量。由此可见, WDWG的状态数量与字母表长度无关, 极为接近文本的长度n, 平均为0.99n, 而且随着n的增加, 更加趋近于n。这是因为随着前缀长度的增加, 在文本中出现两次的前缀占所有前缀的比例也随之减小。而DAWG的状态数量则与字母表长度相关, 二进制串情况下接近2n, 平均为1.63n。 笔者通过对全文索引结构后缀数组的研究和改进, 把全文索引结构和后缀数组有机地结合在一起, 得到了一种基于后缀数据的全文索引结构, 通过对后缀数组的全文索引结构的进一步压缩得到加权有向词图。实验证明, 加权有向词图在相同问题规模的情况下能降低存储空间, 同时不影响检索的效率, 是一种更为高效的全文索引结构。 参考文献: [1]ANSELM BLUMER, BLUMER J, DAVID HAUSSLER, et al. The Smallest Automation Recognizing the Subwords of a Text [J]. Theoretical Computer Science, 1985, 40(1): 31-55. [2]CORASICK A M. Efficient String Matching: An Aid to Bibliographic Search [J]. Communications of the ACM, 1975, 18(6): 333-343. [3]BOYER R, MOORE J. A Fast String Searching Algorithm [J]. Commun ACM, 1977, 20(10): 762-772. [4]贺龙涛, 方滨兴, 余翔湛. 一种时间复杂度最优的精确串匹配算法 [J]. 软件学报, 2005, 16(5): 673-676. HE Long-tao, FANG Bin-xing, YU Xiang-zhan. A Time Optimal Exact String Matching Algorithm [J]. Journal of Software, 2005, 16(5): 673-676. [5]刘传汉, 王永成, 刘德荣, 等. 基于混合策略的单模式匹配算法 [J]. 上海交通大学学报, 2007, 41(1): 36-41. LIU Chuan-han, WANG Yong-cheng, LIU De-rong, et al. Single Pattern Matching Algorithms Based on Hybrid Strategy [J]. Journal of Shanghai Jiaotong University, 2007, 41(1): 36-41. [6]UDI MANBER, EUGENE W MYERS. Suffix Arrays: A New Method for On-Line String Searches [J]. SIAM Journal on Computing, 1993, 22(5): 935-948. [7]PAOLO FERRAGINA, GIOVANNI MANZINI, VELI MAKINEN, et al. An Alphabet-Friendly FM-Index [C]∥Proceedings: 11th International Conference, SPIRE 2004. Padova, Italy: [s. n.], 2004: 150-160. [8]ZHANG Meng, HU Liang, LI Qiang. Weighted Directed Word Graph [C]∥Proceedings 16th Annual Symposium, CPM 2005. Jeju Island, Korea: Springer, 2005: 156-167.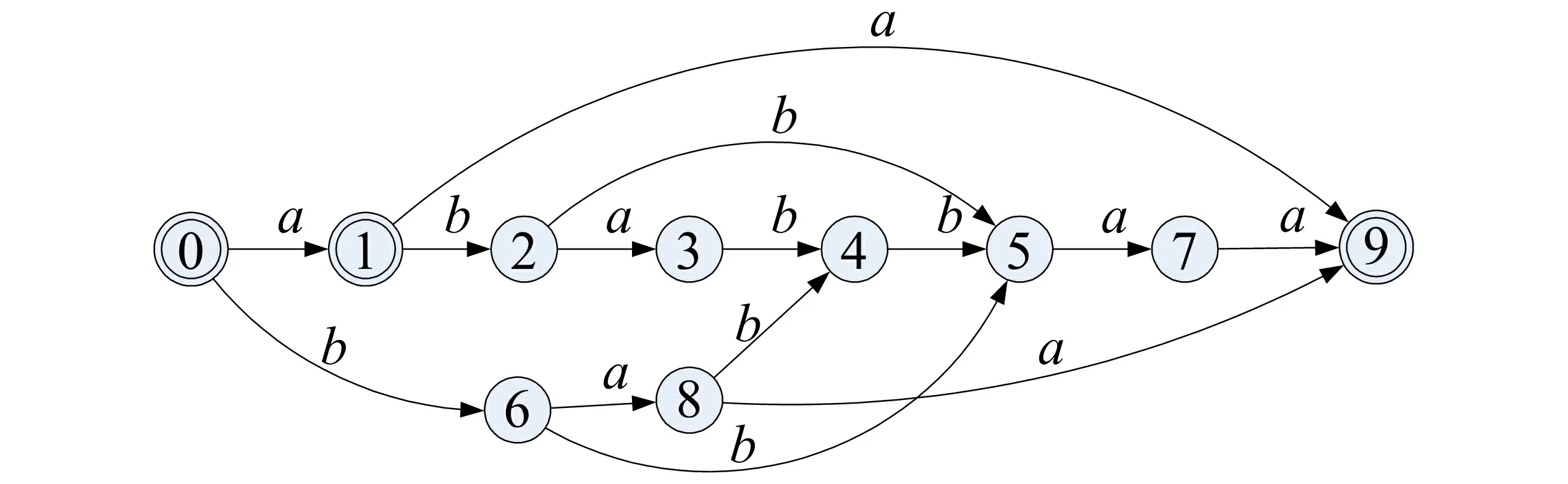

3 加权有向词图
4 实验与比较
4.1 实验方案
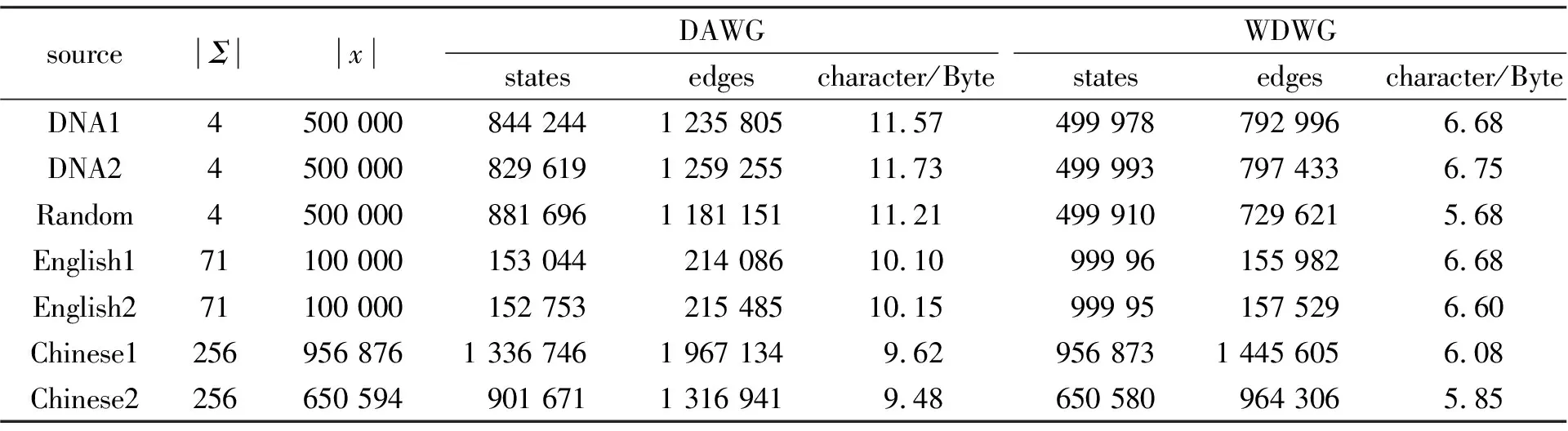
4.2 实验比较
5 结 语
