数据预处理:数字图书馆的“清洗机”
2013-09-12聂飞霞
聂飞霞,付 敏
(西北大学图书馆,陕西 西安 710127)
随着网络化的发展以及数字图书馆的崛起,图书馆也开始走入了数字化时代。图书馆现有的自动化管理系统中存储着大量的书目数据、读者流通借还数据、书目检索记录、Web访问记录等。但目前图书馆所应用的信息化管理系统只有简单的统计分析功能,无法预测读者的需求以及图书的借阅趋势。数据挖掘技术的应用,使图书馆自动化信息系统中的数据得到了整理与预测,使庞杂的数据成为有用的知识。而数据预处理技术是根据数据挖掘的需求,将现有的已知数据进行清洗转换汇总等操作。由于数据源的庞大与杂乱,预处理前得数据常常被人称为“脏数据”,这就使得数据预处理工作成为数据挖掘前期重要的步骤。只有对预处理过的数据进行数据挖掘,数据挖掘工作才会科学有效。
1 数据提取
数据预处理的前期工作是对所需要的数据进行提取。图书馆信息系统中存在着大量的读者信息、图书信息、读者借还数据、图书借还数据、读者检索数据等,因此数据提取工作也是相对较为繁琐的。下面给出所提取数据的重要字段结构表(本文所提取的数据是西北大学图书馆ILAS系统中的部分数据)。
读者信息表主要包括读者姓名、读者证号(区别读者的唯一标志)、性别、院系、部门等。读者信息表结构如表1所示。
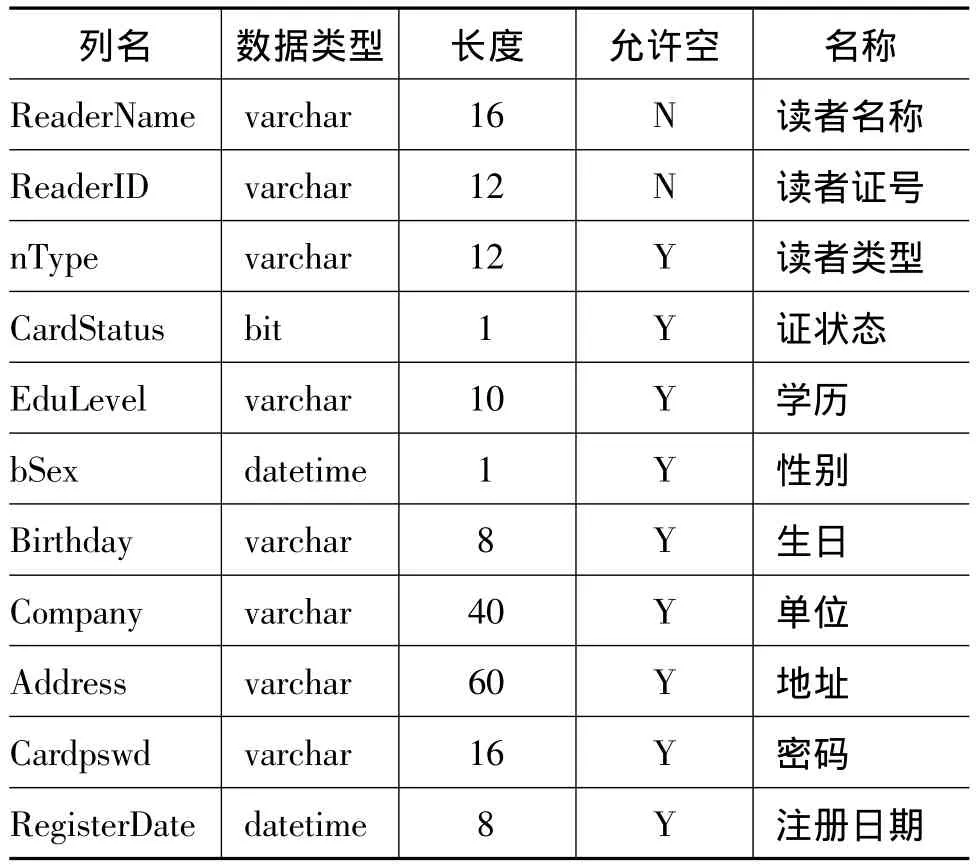
表1 读者信息表结构
图书信息表记录了馆藏图书的题名、分类号、索取号、ISBN号、条码(区别图书的唯一标志)等。图书信息表结构如表2所示。
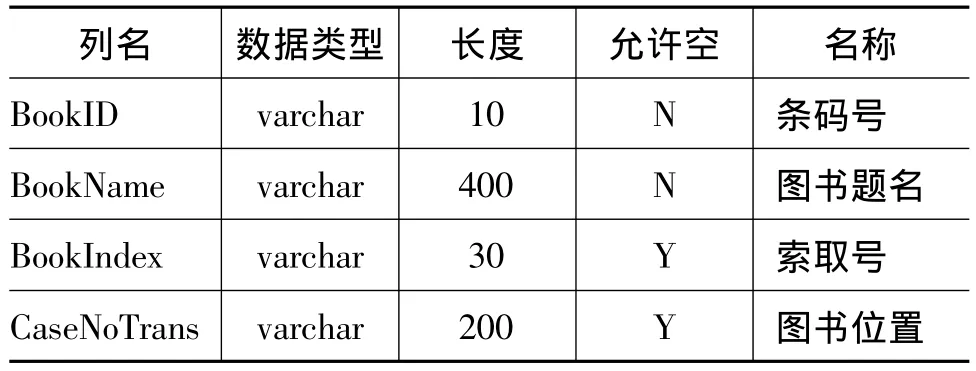
表2 图书信息表结构
借还信息表主要记录了借阅和归还两个过程的读者以及图书信息,包括读者姓名、读者证号、图书题名、图书条码、还书时间等。借还信息表结构如表3所示。
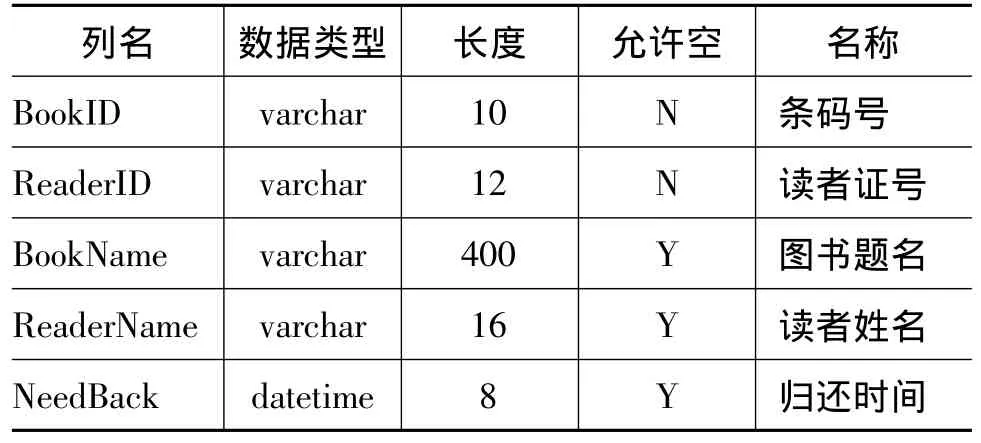
表3 借还信息表结构
2 数据预处理
数据源的获取、数据获取和信息集成等相关研究为数据预处理提供了基础。根据数据挖掘的需求,将相关的多源数据集成融合后,需要进行多种数据预处理操作。数据预处理的主要流程包括数据清理、数据集成和融合、数据变换、数据规约以及在数据挖掘结果的评价计划基础上进行的二次预处理的精炼。数据预处理的基本流程如图1所示。
2.1 数据清理
数据清理工作是数据挖掘准备工作中最耗时耗力的工作,但也是最重要的工作。最初获得的原始数据往往是夹杂着很多错误的、有噪声的、空白的、缺失的或者冗余的数据。数据清理工作就是将这一部分数据加以处理。
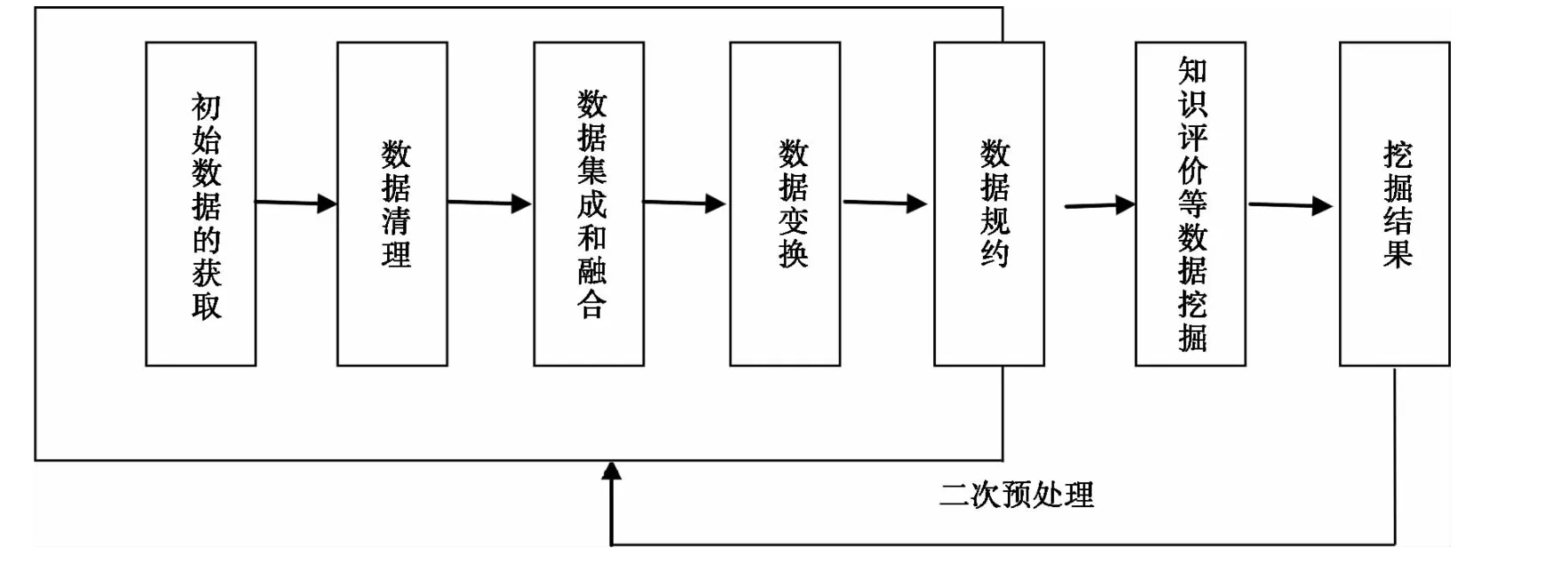
图1 数据预处理基本流程图
在图书馆信息系统中获得的数据源,主要需要做的工作是删除错误值、补充空缺的信息以及修改部分不吻合的值。本次从图书馆信息系统中共获得借阅数据6798条,图书数据6704条,读者数据621条。其中借阅数据中有借阅失败的冗余数据以及与数据挖掘工作无关的属性值,而读者数据中有读者名称空缺专业名称错误等信息都需要进行处理。表4是某一时间段西北大学图书馆图书借阅原始信息表dbo.BorrowHistory中的数据。

表4 读者原始借还信息表
如表4所示,该原始数据记录了某一时间段读者的借阅信息,其中szMemo属性列记录了借阅失败的信息,我们可以通过编写SQL语句对bResult属性值为False的行进行删除。同时,可以删除我们数据挖掘工作不需要的属性列,如对bBooking列与szRead列进行删除。得到读者借还信息表如表5所示。
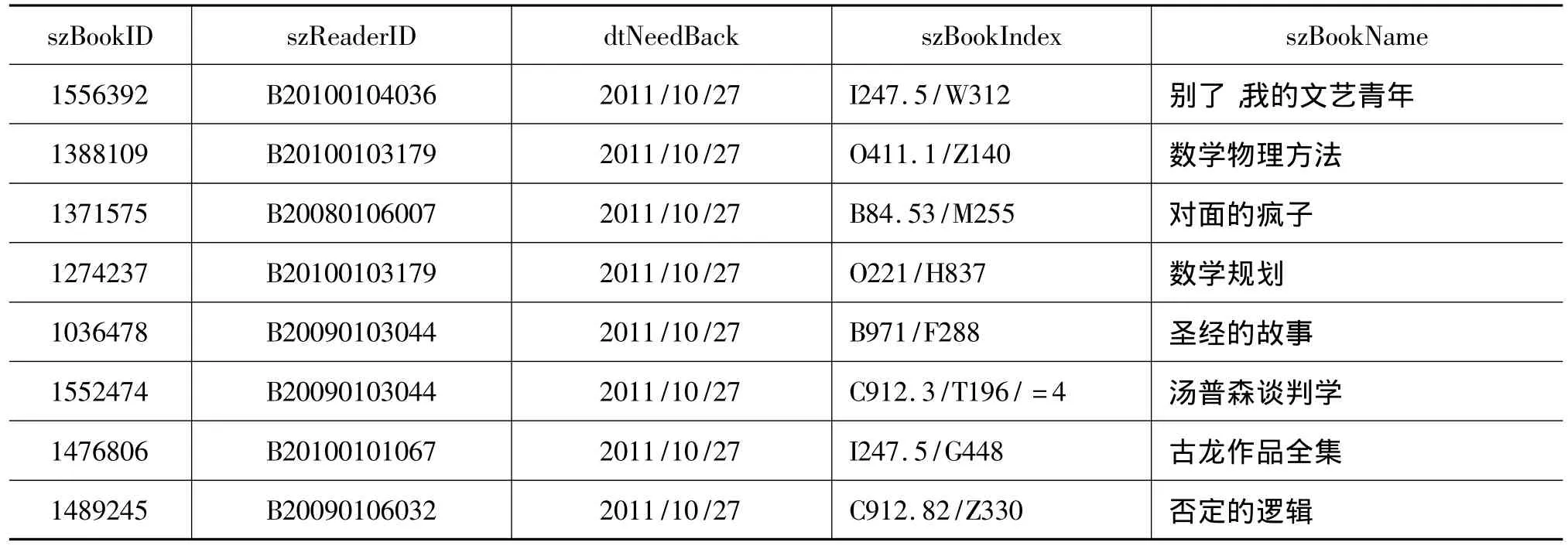
表5 读者借还信息表
2.2 数据融合与变换
本文所用到的读者信息与读者借还信息是分别处于两个数据表中的单独数据,我们需要利用SQL语言将这两个表进行融合与变换。文中表5为数据清理后的读者借还信息表,表6为数据清理后的读者信息表,将读者信息表中的读者姓名即Reader-Name属性列与读者单位Company属性列增加到读者借还信息表中,得到加了 ReaderName属性与Company属性的读者借还信息表,如表7所示。
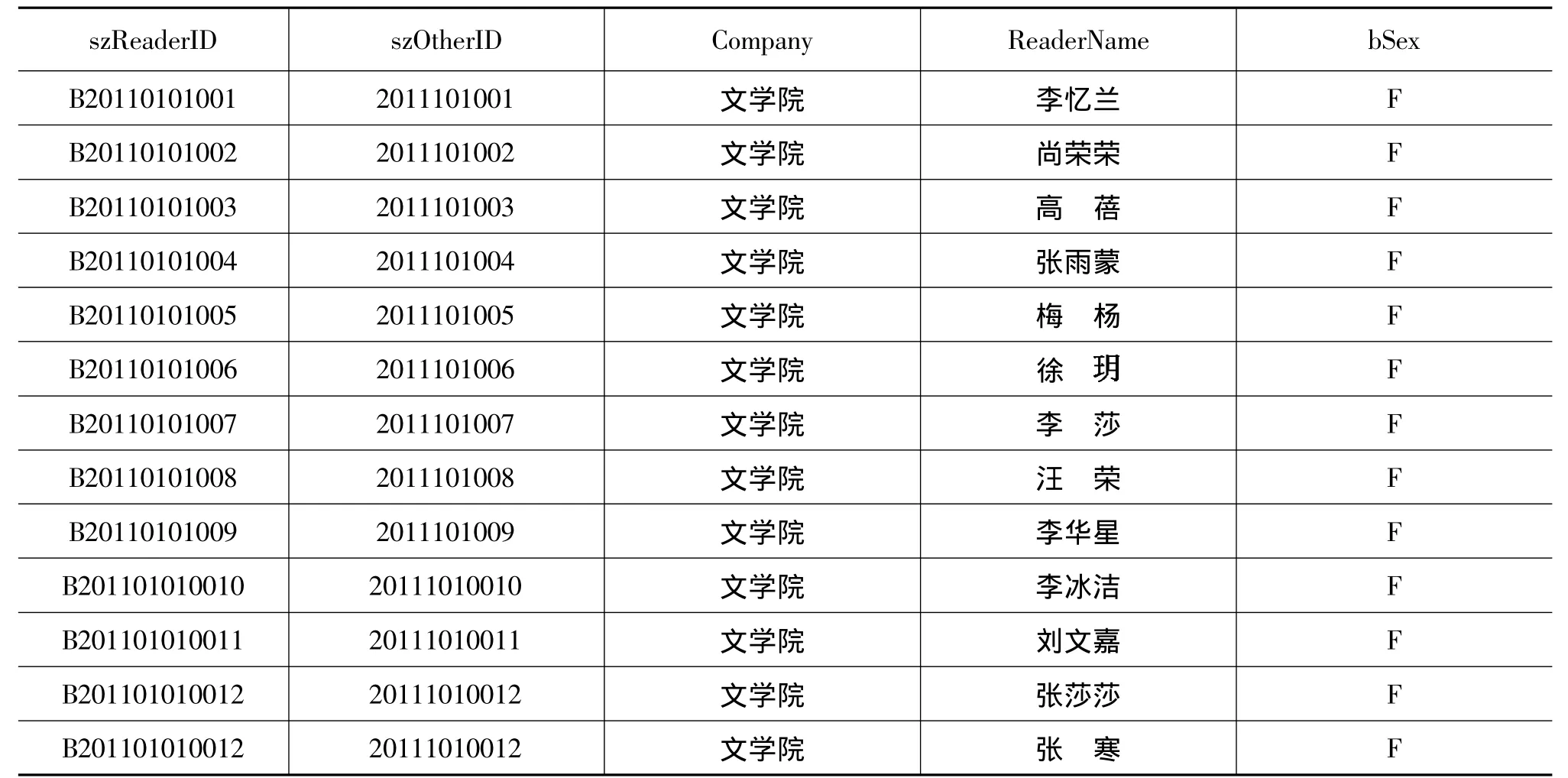
表6 读者信息表

表7 加了ReaderName属性与Company属性的读者借还信息表
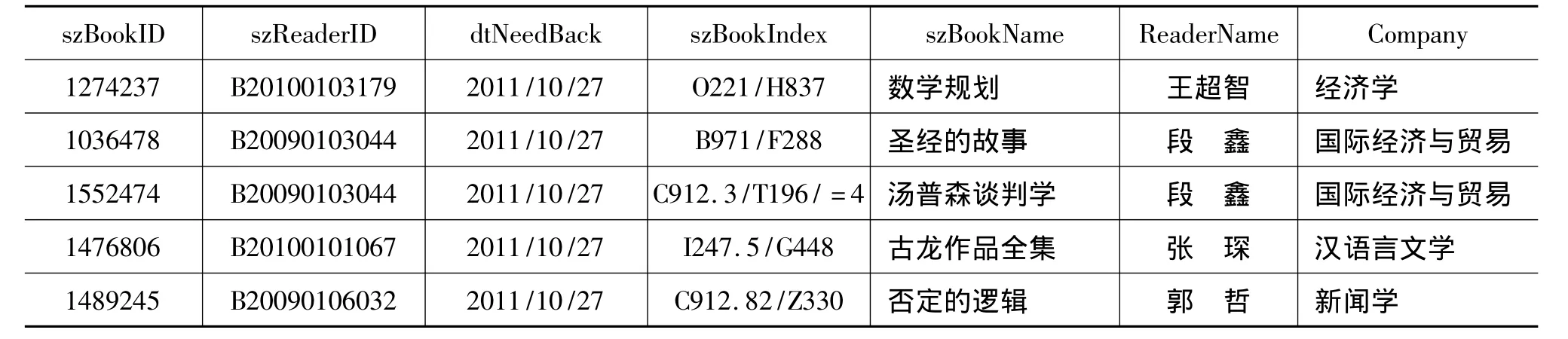
续表7
2.3 数据规约
一般数据库中的数据表都很庞大,为了节约运算时间,我们需要对其进行规约。规约以后的数值将比原值小很多,但却保持了原值的完整性。规约技术使得数据挖掘更加有效可行。利用图书信息表、读者信息表、借还信息表清理融合后得到表7所示的读者借还信息表。该读者借还信息表所记录的读者借阅记录中,图书的属性有条码号、书名以及索取号。其中条码号为识别图书的唯一标志,也就是说每本图书的条码号都是唯一的。而书名和索取号则可能相同,索取号由于记录得比较详细不利于数据挖掘的运算,我们把图书的索取号即szBookIndex属性进行规约。将图书按中图法的22个大类进行划分,得到增加了新属性szCategory的读者借还信息表,如表8所示。
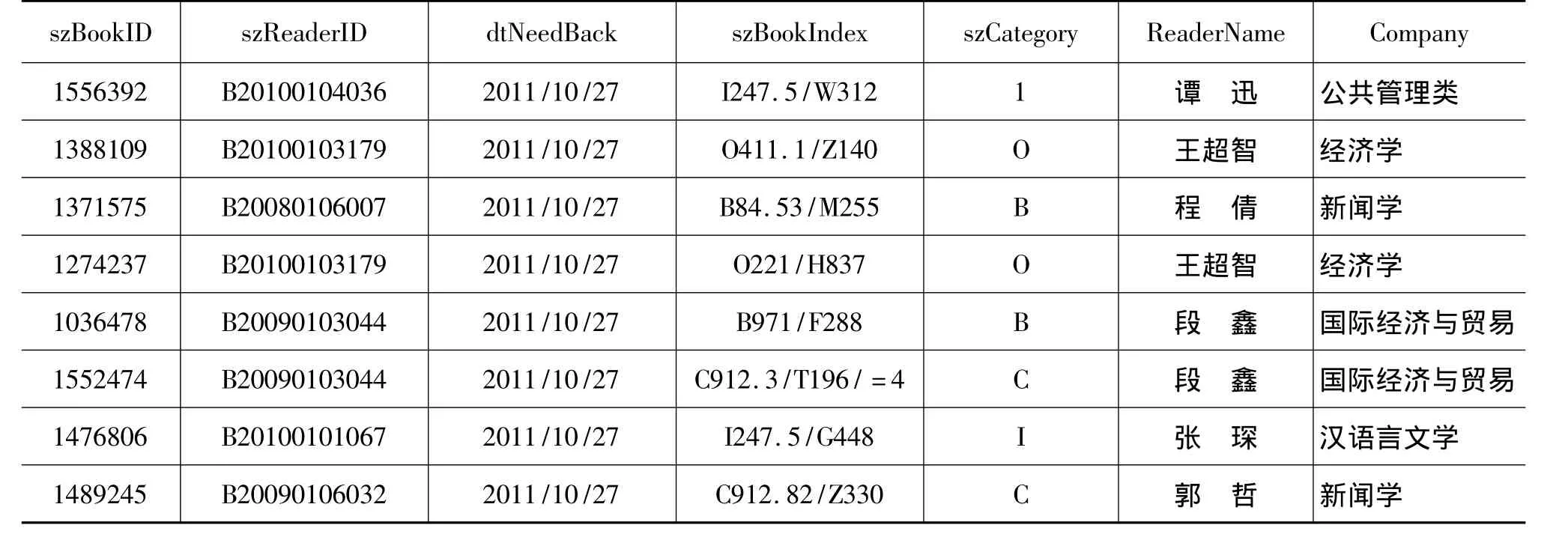
表8 规约后的读者借还信息表
3 结语
数据挖掘技术近几年已经开始应用于数字图书馆,利用数据挖掘方法中的聚类分析可以将读者按阅读兴趣、借阅次数等进行分类。利用数据挖掘方法中的关联规则可以为读者提供个性化的推荐服务,如将读者可能喜欢的图书进行推荐,或者将可能流行的书推荐给采购人员。以上所说的数据挖掘技术的应用都离不开对数据的预处理。因此数据的预处理工作既是数据挖掘工作的基础,也是数据挖掘工作中相对重要的步骤。数据预处理是数据挖掘工作科学有效的基础。
[1]Han Jiawei,Kamber Micheline.数据挖掘:概念与技术[M].北京:高等教育出版社,2001.
[2]谢邦昌.数据挖掘Clementine应用实务[M].北京:机械工业出版社,2008.
[3]Tan Pang - Ning,Steinbach Michael,Kumar Vipin.数据挖掘导论:完整版[M].北京:人民邮电出版社,2011.
[4]高建煌.个性化推荐系统技术与应用[D].中国科学技术大学计算机应用技术,2010.
