宽函数的布尔匹配及其在FPGA重综合中的应用*
2013-08-19张峰王作建吴洋于芳刘忠立
张峰 王作建 吴洋 于芳 刘忠立
(1.中国科学院 微电子研究所,北京 100029;2.北京飘石科技有限公司,北京 100029)
近年来,现场可编程门阵列(FPGA)在速度、容量及功能性方面有显著提升,因此在诸多应用领域逐渐取代专用集成电路(ASIC).FPGA 的应用和广泛普及为数字系统的设计带来极大的灵活性.当前大多数FPGA 的可编程逻辑块(CLB)基于查找表(LUT).一个k 输入LUT(k-LUT)包含有2k个静态存储器(SRAM)单元,可实现任意输入数不大于k的逻辑.为进一步提高CLB 的配置灵活性,目前商用FPGA 的CLB 结构增加了很多辅助单元用来更高效地实现各种功能.比如使用多路复用器(MUX)和异或门(XOR)来辅助实现快速进位链,使用MUX来组合宽输入的LUT 等.为了有效地利用现代FPGA芯片的这些异构特性,需要在已有基于LUT映射方法的基础上进行扩充或改进.
1 目标FPGA 结构
以Xilinx 公司的CLB 结构为例,1 个CLB 包含两个逻辑片(SLICE),每个SLICE 包含两个基本逻辑单元(LC),每个LC 由一个k-LUT 和一个时序元件D 型触发器(DFF)组成,如图1 所示.
对于一个LUT 基CLB 结构,假如CLB/SLICE能实现任意k 输入函数,那么定义k 的最大值为CLB 的特征数值.对于变量数大于特征数值k 的函数,定义该函数为相对于CLB/SLICE 的宽函数.
以k-LUT 的k 值等于4 为例(如图1 所示[1]),每个SLICE 中含有两个LUT(F 和G),1 个2 选1 MUX H,用于将SLICE 中的两个4-LUT 组合成5-LUT,则该SLICE 的特征数值k 为5,每个SLICE可实现输入数不大于5 的任意逻辑,或者1 个4 选1 MUX,或者输入数在6 到9 之间的部分逻辑(宽函数).类似地,2 选1 MUX I 将两个H 的输出组合,则CLB 的特征数值k 为6,使得1 个CLB 可以实现输入数不大于6 的任意逻辑,或者1 个8 选1 MUX,或者输入数介于7 到19 之间的部分宽函数.

图1 包含两个SLICE 的CLB 视图[1]Fig.1 Detailed view of two-SLICE CLB[1]
由几个k-LUT 组成的网表通常被称作LUTs 结构,如图2 所示.从广义上讲,SLICE 和CLB 也属于LUTs 结构.对于宽函数与LUTs 结构之间的布尔匹配问题,通常有以下几种应用:FPGA 结构的评估、对LUTs 结构的工艺映射、对映射后的网表进行的重综合.
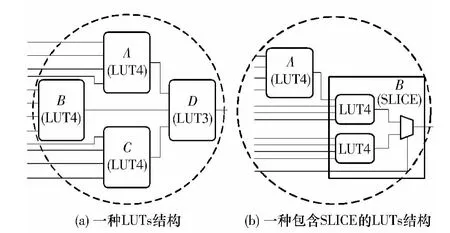
图2 LUTs 结构示例Fig.2 Examples of LUT structures
2 布尔匹配问题的研究现状
国内对布尔匹配问题的研究报道较少,国外的研究主要基于以下几种方法.
(1)结构化匹配.结构化的工艺映射工具(如文献[2]和[3])一般采用这种方法.该方法主要基于输入数的匹配,因此对宽函数的匹配问题成功率较低.
(2)基于可满足性(SAT)的匹配方法[4-5].该方法可有效地对宽函数与LUTs 结构进行匹配,可保证存在的匹配能被找到,但是这种方法非常耗时.文献[4]报道,在60s 的限制时间内,该方法对10 输入变量的函数只有50%的匹配成功率.因此,受运行时间限制,基于SAT 的匹配方法一般用于输入数≤10的函数.
(3)基于NPN 等价类的方法[6-7].该方法主要基于NPN 等价类编码方法.即对给定的LUTs 结构,将所有能实现的函数的NPN 等价类预先计算好,存入库中,在需要匹配时将库文件导入内存中,将待匹配的宽函数进行NPN 编码后在库中查找匹配.这种方法效率很高,运行时间少,缺点是对库的依赖大,数量庞大的NPN 等价类会占用大量内存.如文献[6]中对9 输入的函数如果要达到95%的匹配率,需要占用155.7 MB 内存,而且输入数每增加1,内存占用会增加近10 倍.因此这种方法一般适用于特定的结构,并且输入数≤10 的情况.
(4)基于布尔函数分解的方法[8-9].该方法适应性广,主要通过分解算法将布尔函数分解,使得每一个分解后的子函数能被k-LUT 实现.这种方法的匹配率和效率取决于被匹配的布尔函数和采用的分解算法,通常在分解的过程中采用启发式的方式来提高算法的效率.
3 布尔匹配方法及其应用
文中所采用的布尔匹配方法属于基于布尔函数分解的方法,采用MUX 分解技术和不相交支持集分解(DSD)算法相结合的技术.
文献[6]中提及,给定逻辑函数与LUTs 结构之间的匹配问题,可以归为两类:①提供确定的LUTs结构(如CLB、SLICE),判断给定的逻辑函数能否被实现;②提供完全定义函数,产生一个较小的LUTs结构来实现.
文中对①、②两种情况都进行考虑,提出一种适应图1 中CLB 结构和一般性LUTs 结构(见图2)的布尔匹配方法,并将其应用于以面积为优化目标的工艺映射后的重综合中.在该应用中,先考虑第①种情况(基于MUX 分解技术,将在第3.1 节中详细介绍);在第①种情况无法满足的情况下,考虑第②种情况(基于DSD 技术,将在第3.2 节中详细介绍).最后,将文中提出的布尔匹配方法应用于工艺映射后的重综合,并通过实验证明:文中的算法利用图1中CLB 结构的特点,使电路在FPGA 实现上能得到很好的面积优化效果.
3.1 基于MUX 的分解方法
3.1.1 香农展开式
使用f(X)表示布尔函数f(x1,x2,…,xn),其中X={x1,x2,…,xn}.对于给定的f(X),使用f¯xi和fxi表示f(X)相对于xi的余因子.f(X)相对于多个变量的余因子的定义类似,例如f(X)相对于xi的香农展开式[10-11]为f(X)=xifxi+¯xif¯xi,f(X)相对于多个变量的香农展开式的定义类似.
在图1 中,将F、G 和H 的输入信号集合分别表示为XF、XG和和分别表示LUT F和LUT G 的大小(即输入数),输出信号分别表示为oF、oG和oH,MUX H 选择oF还是oG作为输出取决于外部选择信号xH.使用图1 中1 个SLICE 来实现f(X)时,可以将f(X)表征为¯xHy1(XF)+xHy2(XG),即f(X)相对于变量xH的香农展开式,其中XF∪XG∪{xH}=X,y1(XF)、y2(XG)表示f(X)相对于xH的余因子.
3.1.2 对SLICE/CLB 的布尔匹配
对布尔函数和SLICE/CLB 之间进行布尔匹配,可以由香农展开式获得,伪代码如下:


如果匹配成功则函数muxDecompose 返回1 值,否则返回0 值.
定理1 1 个SLICE 能够实现f(X),当且仅当存在相对于xH∈X 的香农展开式

因此,给定一个宽函数F,通过调用函数find-BestCofVar 遍历输入集合中的每个信号,将其作为MUX 的选择信号,对该信号进行香农展开,获得两个余因子(cof0、cof1)的输入集合数(cof0->nVars,cof1->nVars).遍历结束后将两个余因子的输入集合总数最小的信号作为选择信号bestVar.
如果香农展开式中两个余因子的输入集合均不大于k(k 表示k-LUT 的大小),则可获得对于SLICE的一个匹配.如果遍历输入集合结束后,未获得对于SLICE 的一个匹配,则尝试去寻求该宽函数对CLB的匹配.
定理2 f(X)不能用1 个SLICE 实现,而能用1 个CLB 实现,当且仅当存在相对于xH∈X 的香农展开式

式中,xH0、xH1分别表示图1 中SLICE0 和SLICE1 中的xH信号,y01、y02表示f(X)相对于xH0的余因子,y11、y12表示f(X)相对于xH1的余因子.
如果宽函数对SLICE 的布尔匹配失败,则对f(X)的输入集合总数最小的两个余因子分别进行进一步处理,如果两个余因子的输入集合数都大于LUT 的输入数,则对两个余因子分别调用函数muxDecompose进行香农展开,则可获得f(X)的4 个子余因子;如果只有一个余因子的输入集合数大于LUT 的输入数,则只对这一个余因子调用函数muxDecompose进行香农展开,则可获得f(X)的3 个子余因子.如果获得的所有子余因子的输入集合数都不大于LUT 的输入数,则获得宽函数f(X)对CLB的一个布尔匹配.
3.2 基于DSD 的分解方法
3.2.1 DSD 的一些基本概念
定义1 一个完全定义函数F,如果存在一种输入组合,当其中一个变量值切换时,F 的值发生变化,则称该变量值为F 的必要依赖项.
定义2 F 的支持集定义为F 的所有必要依赖项的集合.
定义3 如果两个函数不包含相同的变量,则称这两个函数的支持集不相交.
定义4 一个完全定义函数的分解定义为一个只包含一个原始输出(PO)的布尔网络,该布尔网络与原函数在功能性上等价.
定义5 不相交支持集分解是指一个完全定义函数分解得到的布尔网络,该网络中各节点的支持集相互之间不相交[9].
根据定义5,DSD 通常结果是一个树形结构(每个节点只含有一个扇出),每个叶节点的支持集称为约束集,其余变量称为自由集.如果DSD 之后,每个节点都不能再进行DSD,则称这个DSD 为一个极大DSD.
3.2.2 对LUTs 结构的布尔匹配
计算极大DSD 的文献有[9,12-14]等,在这些文献中所述算法的基础上,文中提出了一种适用于可能包含SLICE 的LUTs 结构的布尔匹配方法.使
用DSD 算法进行布尔匹配的伪代码如下:

函数decompose_rec 的输入是完全定义函数F和用于限制分解模块的支持集大小的限制数k,该函数可对自身进行递归调用,直到F 分解完全或分解失败.如果F 分解成功,则该函数返回1 值,否则返回0 值;
函数decompose_rec 首先会调用函数support-Minimize,该函数用于移除无意义的变量,并返回F的新支持集.例如,对于F = acd,如果其支持集为(a,b,c,d),则b 是F 的无意义变量.函数support-Minimize 会将变量b 从F 的支持集中移除,新的支持集大小为3.
为充分使用图1 中CLB 里的MUX,在进行DSD之前,首先尝试使用基于MUX 的分解,该方法已在3.1 节中详细介绍.
函数dsdAnalyze 用于分析DSD 的可能性,该函数尝试进行DSD,计算出所有k 可行的约束集,从中选出最好的约束集,最后返回DSD 树.
如果DSD 树不为空,并且得出的约束集大小为k 或k-1,则对函数F 调用dsdSplit 进行DSD,分解成约束集BSets 和自由集FSets.文中算法的特点是,dsdSplit 尽可能地一次分解出多个大小为k 的约束集.以图2(a)为例,对于给定的12 输入完全定义函数,在第1 次DSD 分解后,得到3 个大小为k 的约束集,分别用A、B、C 3 个节点来实现.此时自由集已为空,小于k,不需要做进一步分解,只需要新增一个D 节点,使其扇入分别为A、B、C 节点即可.至此,给定的宽函数用图2(a)匹配成功.
假如dsdSplit 进行DSD 分解后,自由集大于k,则需要对自由集做进一步分解.以图2(b)为例,对于给定的12 输入完全定义函数,在第1 次DSD 分解后,BSets 用A 节点来实现,此时FSets 含有8 个变量,大于k,因此递归调用decompose_rec 对FSets 做进一步的分解.假设此次基于MUX 的分解成功,则将FSets 用B 节点(SLICE)来实现(如果MUX 分解失败,则需要调用dsdSplit 进行DSD 分解).至此,给定的宽函数用图2(b)匹配成功.
3.3 以面积为优化目标的重综合
重综合[15]是一项重写电路结构的技术,它可以在不改变电路功能的情况下有效地减小面积或延时.重综合通常与工艺映射同时进行[14],或者单独作为映射后的优化动作[16]进行.重综合需要探寻庞大的解空间,所以与工艺映射同时进行非常耗时,从而使这种方法只能对小的电路进行优化.而在映射后进行重综合,则可以选择不同于工艺映射的策略,例如只选择映射后网络里的部分节点(如关键路径或近关键路径节点)进行重综合,或者使用比映射过程中更简洁高效的截计算方法[17],这些策略可以大大减小运行时间,从而可以更好地处理大的电路.
有效地判断完全定义的宽函数能否用LUTs 结构实现(即宽函数与LUTs 结构之间的布尔匹配问题),是FPGA 重综合算法中的核心问题.为解决此问题,文中将第3.1 节和第3.2 节介绍的布尔匹配算法应用于映射后的重综合中.
首先对映射后的布尔网络进行分析,将所有LUTs 节点从输出(原始输出和触发器的输入)到输入(原始输入和触发器的输出)按逆拓扑顺序排列.然后计算出每个节点的输入变量数不大于16 (受当前数据结构限制,暂只支持16 以下输入数)的截,并将其中权重比较高的一部分存入截集合.
遍历截集合,对每个截计算出截的函数(真值表).接着使用第3.2.2 节中介绍的函数decompose_rec 来分解截的函数,用功能性等价的LUTs 结构与截的函数进行布尔匹配.
以图2 为例,假设截的根节点和叶节点之间形成的锥为图2(a),而匹配成功后新的LUTs 结构为图2(b),图2(b)比图2(a)所包含的节点数目少.如果替换后网络的关键路径延时不会增加,则把锥替换成新的LUTs 结构.
也就是说,文中进行的重综合的目标是在不损害电路延时的情况下去减小面积.
4 实验结果及分析
为验证第3 节所提算法的优化效果,文中从MCNC[18]和ISCAS’89 基准电路集中选取20 个电路对第3.3 节中的重综合(以下简称ime)策略进行测试.测试环境:CPU 为Intel core i7 CPU870 2.93 GHz,内存为4 GB,操作系统为Windows XP,编译环境为Visual C++2008.实验结果网表均通过ABC 里的验证工具证明与原始电路等价.
实验中用到的ABC[19-20]命令有:
st:将当前网表经过一级结构化哈希转化成与非图(AIG)网表;
resyn:迭代运行5 次AIG 重写[21]的逻辑综合脚本命令;
dc2:迭代运行10 次AIG 重写的逻辑综合脚本命令;
dch:一种累积结构化选择的逻辑综合脚本命令,该命令运行命令resyn 之后运行命令dc2,并收集网表的3 个快照:原始网表、运行resyn 之后的中间网表以及最终网表.
if:一种高效的FPGA 工艺映射命令,基于优先截算法[22],能够对结构化选择的网表进行映射.
mfs:一种以面积为优化目标的重综合命令[15],属于基于SAT 的布尔匹配算法.
lutpack:一种以面积为优化目标的重综合命令[9],属于基于余因子提取和DSD 分解技术的布尔匹配算法.
4.1 以4-LUT 为映射目标的实验
本实验的映射目标为图1 中基于4-LUT 的CLB结构,分别运行如表1 所示的4 组命令.
“choices”栏:代表迭代运行4 次基于结构化选择的工艺映射(st;dch;if-C 12),并从4 次结果中选出面积最好的结果;
“lutpack”栏:代表迭代运行4 次基于结构化选择的工艺映射,并交叉运行重综合命令lutpack(st;dch;if-C 12;lutpack),并从4 次结果中选出面积最好的结果;
“mfs”栏:代表迭代运行4 次基于结构化选择的工艺映射,并交叉运行重综合命令mfs(st;dch;if-C 12;mfs),并从4 次结果中选出面积最好的结果;
“ime”栏:代表迭代运行4 次基于结构化选择的工艺映射,并交叉运行文中的重综合算法ime(st;dch;if-C 12;ime),并从4 次结果中选出面积最好的结果;
现有的工艺映射工具[2,22]无法使用图1 中CLB里的MUX H 和I,造成很多资源的浪费,而使用MUX H 和I 并不影响电路的面积,只是对电路的延时有一定增加,所以本实验中面积模型只统计最终使用的LUT 数量.由于工艺映射后无法得知布线资源里的延时,所以ABC 的延时模型只统计电路关键路径上的LUT 层级,一个k-LUT 的延时为1.由文献[1]可知,图1 中F/G 的输入端到X/Y 输出端的最小延时为0.29 ns,F/G 的输入端到F5 输出端的最小延时为0.32 ns,F/G 的输入端经过H 后到X 输出端的最小延时为0.36 ns,F/G 的输入端经过H 和I后到Y 输出端的最小延时为0.44 ns.据此,本实验中ime 的延时模型在ABC 中标准的LUT 延时模型基础上作了一定的适应性改变,将1 个SLICE 的延时定为1.2,1 个CLB 的延时定为1.5,虽然是近似延时模型,但足以保证结果的合理性.
表1 中“比率1”一行的统计结果表明,与choices相比,在不增加电路关键路径延时的基础上,ime、lutpack、mfs 均能对工艺映射后的网表进行面积优化,减少LUT 的使用数量,优化比例分别达到7.9%、6.1%和8.1%.实验结果表明,对于本实验的映射目标,ime 比lutpack 有更好的面积优化效果,运行时间上也小于lutpack.表1 中“比率3”一行的统计结果表明,与mfs 相比,ime 在运行时间上为mfs 的41.2%,而面积仅增加0.2%.

表1 k=4 时对CLB 工艺映射后进行重综合的实验结果Table 1 Resynthesis results after technology mapping for CLB when k=4
4.2 以6-LUT 为映射目标的实验
为验证文中提出的算法的通用性,对文献[23]中6-LUT 的器件另外进行了一组映射实验,运行命令与实验一中相同.据文献[24],6-LUT 的延时TILO 最小值为0.08 ns,使用F7MUX 组合出7-LUT 的延时TILO_2 最小值为0.20 ns,使用F8MUX 组合出8-LUT 的延时TILO_3 最小值为0.31 ns.据此,本实验ime 的延时模型中,将6-LUT 的延时层级定为1,7-LUT 的延时层级定为2.5,8-LUT 的延时层级定为4,虽然是近似延时模型,但足以保证结果的合理性.
表2 中“比率1”一行的统计结果表明,ime 对基于6-LUT 的SLICE 结构也具有较好的面积优化结果,与choices 相比,在不增加电路关键路径延时的基础上(2.2%的优化),ime 对工艺映射后的网表面积能达到7.8%的优化结果,该结果优于lutpack 的4.9%.对于mfs,表2 中“比率1”一行的统计结果表明,mfs 对6-LUT 网表有更好的优化结果,达到惊人的27%.该结果与文献[15]中不同的原因在于,无从得知文献[15]中所用ABC 软件的版本;为了合理公平地比较不同算法的优化结果,在本实验中统一采用了ABC 2012 年7 月18 日的版本,而此版本中,choices 已对网表得到较好的映射结果,所以mfs 的优化比率比文献[15]中稍差.与mfs 相比,ime 在运行时间方面优势明显,仅为mfs 的29.8%,但在面积方面差距较大,差距主要在电路clma、ex5p、pdc、spla 等几个电路上.mfs 的运行结果表明,ime 在面积方面仍有较大的优化空间,下一步的研究是在保证运行时间较优的情况下进一步优化电路面积.

表2 k=6 时对CLB 工艺映射后进行重综合的实验结果Table 2 Resynthesis results after technology mapping for CLB when k=6
实验1 和实验2 的结果表明:ime 能充分利用图1 中CLB 里的逻辑资源;在合理的运行时间内,并且在不增加电路关键路径延时的前提下,不仅对大规模组合电路有很好的面积优化效果,对于时序电路中时序元件之间的组合逻辑同样具有很好的面积优化效果.由于Xilinx 公司大多数器件采用类似图1中的CLB 结构,器件之间仅在k-LUT 的大小和CLB中k-LUT 的数量上存在差异.因此,文中提出的算法对Xilinx 公司的器件具有一定的通用性和适用性.
5 结语
文中提出一种对宽函数与CLB 结构进行布尔匹配的方法,该方法结合使用香农展开式和不相交支持集分解算法,主要针对Xilinx 公司的CLB 结构.将文中的布尔匹配方法应用于工艺映射后的重综合,能够在不增加电路关键路径延时的基础上,对4-LUT 和6-LUT 工艺映射后的电路网表在面积上分别获得7.9%和7.8%的优化结果.文中提出的方法能充分利用CLB 的结构特点,在普通工艺映射的基础上,使输入数不大于16 的宽函数能使用更少的LUT 数来实现,从而达到面积优化的效果.
[1]Xilinx Inc.VirtexTM2.5 V field programmable gate arrays[EB/OL].(2001-04-02)[2012-08-14].http:∥china.xilinx.com/support/documentation/data _ sheets/ds003.pdf.
[2]Chen D,Cong J.DAOmap:a depth-optimal area optimization mapping algorithm for FPGA designs[C]∥Proceedings of the 2004 IEEE/ACM International Conference on Computer-Aided Design.San Jose:IEEE/ACM,2004:752-759.
[3]Mishchenko A,Chatterjee S,Brayton R.Improvements to technology mapping for LUT-based FPGAs [J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2007,26(2):240-253.
[4]Cong J,Minkovich K.Improved SAT-based Boolean matching using implicants for LUT-based FPGAs[C]∥Proceedings of the 2007 ACM/SIGDA 15th International Symposium on Field Programmable Gate Arrays.New York:ACM,2007:139-147.
[5]Wang K,Chan C,Liu J.Simulation and SAT-based Boolean matching for large Boolean networks[C]∥Proceedings of the 46th ACM/IEEE Design Automation Conference.San Francisco:ACM,2009:396-401.
[6]Kennings A,Mishchenko A,Vorwerk K,et al.Efficient FPGA resynthesis using precomputed LUT structures[C]∥Proceedings of the 20th International Conference on Field Programmable Logic and Applications.Milano:IEEE,2010:532-537.
[7]Kennings A,Vorwerk K,Kundu A,et al.FPGA technology mapping with encoded libraries and staged priority cuts[J].ACM Transactions on Reconfigurable Technology and Systems,2011,4(4):Article No.35.
[8]Mishchenko A,Wang X,Kam T.A new enhanced constructive decomposition and mapping algorithm [C]∥Proceedings of the 40th Design Automation Conference.Anaheim:ACM,2003:143-148.
[9]Mishchenko A,Brayton R,Chatterjee S.Boolean factoring and decomposition of logic networks[C]∥Proceedings of the 2008 IEEE/ACM International Conference on Computer-Aided Design.San Jose:IEEE/ACM,2008:38-44.
[10]Wikipedia.Shannon’s expansion[EB/OL].(2012-07-06)[2012-08-14].http:∥en.wikipedia.org/wiki/Shannon%27s_expansion.
[11]Cong J,Hwang Y-Y.Boolean matching for LUT-based logic blocks with applications to architecture evaluation and technology mapping [J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2001,20(9):1077-1090.
[12]Rytsar B.A new algorithm of functional decomposition for optimization logic synthesis[C]∥Proceedings of the 2008 Conference on Human System Interactions.Krakw:IEEE,2008:386-389.
[13]Ray S,Mishchenko A,Een N,et al.Mapping into LUTstructures[C]∥Proceedings of the 2012 Design Automation & Test in Europe Conference & Exhibition.Dresden:EDAA,2012:1579-1584.
[14]Bertacco V,Damiani M.The disjunctive decomposition of logic functions [C]∥Proceedings of the 1997 IEEE/ACM International Conference on Computer-Aided Design.San Jose:IEEE/ACM,1997:78-82.
[15]Mishchenko A,Brayton R,Jian J-H R,et al.Scalable don't-care-based logic optimization and resynthesis[J].ACM Transactions on Reconfigurable Technology and Systems,2011,4(4):Article No.34.
[16]Chen L.Post-mapping topology rewriting for FPGA area minimization [D].Waterloo:Department of Electrical and Computer Engineering,University of Waterloo,2009.
[17]Mishchenko A,Chatterjee S,Brayton R.Fast Boolean matching for LUT structures[R].Berkeley:UC Berkeley,2007.
[18]Yang S.Logic synthesis and optimization benchmarks user guide[R].Version 3.0.Durham:Microelectronics Center of North Carolina,1991.
[19]Berkeley Logic Synthesis and Verification Group.ABC:a system for sequential synthesis and verification [EB/OL].(2012-09-20)[2012-10-08].http:∥www.eecs.berkeley.edu/~alanmi/abc.
[20]Brayton R,Mishchenko A.ABC:an academic industrial strength verification tool[C]∥Proceedings of the 22nd International Conference on Computer Aided Verification.Edinburgh:Springer,2010:24-40.
[21]Mishchenko A,Chatterjee S,Brayton R.DAG-aware AIG rewriting:a fresh look at combinational logic synthesis[C]∥Proceedings of the 43rd Design Automation Conference.Anaheim:ACM,2006:532-535.
[22]Mishchenko A,Cho S,Chatterjee S,et al.Combinational and sequential mapping with priority cuts [C]∥Proceedings of the 2007 IEEE/ACM International Conference on Computer-Aided Design.San Jose:IEEE,2007:354-361.
[23]Xilinx Inc.Virtex-5 FPGA user guide[EB/OL].(2012-03-16)[2013-01-10].http:∥www.xilinx.com/support/documentation/user_guides/ug190.pdf.
[24]Xilinx Inc.Virtex-5 FPGA data sheet:DC and switching characteristics[EB/OL].(2010-05-05)[2013-01-10].http:∥www.xilinx.com/support/documentation/data_sheets/ds202.pdf.
