基于并行分散搜索的p-中心定位算法
2013-08-08闫志远孙文彬周长江熊婷王江
闫志远,孙文彬,周长江,熊婷,王江
(中国矿业大学(北京)地球科学与测绘工程学院,北京 100083)
0 引言
p-中心定位是一类基本的网络选址问题[1],由Hakimi在1964年首次提出[2]。p-中心定位算法是解算许多地理网络分析问题的基础,如公共设施选址、服务区域规划等。p-中心定位问题是一个NP(Non-deterministic Polynomial)完全问题[3],无法在多项式时间内获得精确解,多采用启发式算法来获取近似解。随着网络数据规模的不断增加,串行启发式算法已无法满足快速获取高质量解的需求,而并行技术能够通过任务分解或数据分割提高算法的效率[4]。因此,在大规模地理网络中,通过并行化技术提升启发式算法的效率,是快速获取p-中心定位问题高质量解的有效途径。
目前,用于解算p-中心定位问题的启发式算法可分为两大类[5]:经典启发式算法和元启发算法。经典启发式算法解算效率高,但解的质量相对较差;而元启发算法解的质量高,但解算时间较长[6]。为了保证解的质量,近年来国内外学者多采用元启发算法进行p-中心定位问题的求解[7-10]。分散搜索算法是一种应用广泛的元启发算法[11],该算法提供了一种求解问题的通用框架,具有良好的可并行性。算法的子过程实现方式灵活多样,既可以采用局部搜索、整数规划等策略,也可采用其它元启发算法[12]。因此,本文拟以分散搜索框架为基础,设计并行的分散搜索算法(Parallel Scatter Search Algorithm,PSSA),在保证高质量解的前提下,提高p-中心定位算法的执行效率。
1 并行分散搜索算法的实现
1.1 p-中心定位问题
p-中心定位问题的数学描述如下:记U={ui|i=1,…,n}为用户点集合;F={fj|j=1,…,m}为备选设施点集合;D={dij|i=1,…,n;j=1,…,m}为距离矩阵,dij表示U中第i个用户点到F中第j个备选设施点的服务距离,如果该备选设施点无法为该用户点提供服务,则令dij=+∞;寻找一个合适的子集S⊂F,|S|=p,使得目标函数达到最小值。
1.2 分散搜索算法的实现
分散搜索算法的基本框架包含5个子模块:多样性解的产生过程、解优化过程、参考集更新过程、子集产生过程和解组合过程。算法的基本流程[12]如图1所示:首先,通过多样性解产生过程生成若干初始解,并对部分或全部解进行优化,得到初始解集(Population);然后,进行参考集(Refset)更新、子集(Subset)产生和解组合的迭代过程;最后,当参考集不再发生变化时,算法结束。根据以上基本框架,将串行分散搜索算法实现分为初始化和计算两个主要步骤。初始化包括:初始解产生、部分解的优化、初始解集和参考集的构建;计算包括:子集的产生、解组合和参考集的更新。串行分散搜索算法的具体实现过程描述如下:
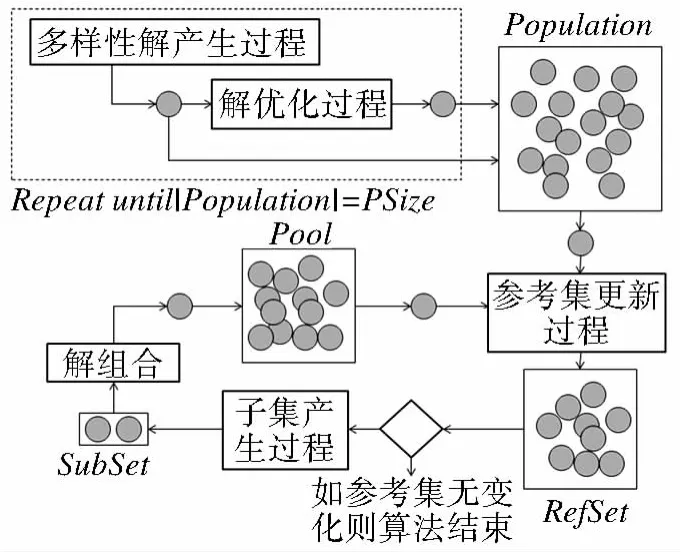
图1 分散搜索算法的基本流程Fig.1 Scatter search diagram
(1)构建初始解集(Population)。初始解集大小为PSize,其中包含HSize个高质量解。首先,用随机方法生成PSize个初始解构成Population,依据初始解的目标函数值(cost)由小到大的顺序排序;然后,从Population中任取HSize个初始解,分别对其进行解优化,从而获得HSize个高质量解。在初始解集的优化过程中,需保证Population中不能出现完全相同的解,且始终保持有序。通过该方法产生的初始解集能满足分散搜索算法要求的“多样性”和“高质量”特性:“多样性”体现为解的随机产生过程,而“高质量”是通过解的优化操作实现。
(2)解优化过程。本文采用Densham-Rushton算法[13]的全局优化过程完成解的优化工作。优化操作是一个反复迭代的过程。首先,从当前解中删除一个设施点,使得删除后目标函数值增加最少。然后,从备选设施点中选择一个未选上的设施点插入当前解中,使得插入后的目标函数值减少最多。最后,判断该交换过程能否改进当前解:若能则实施交换,继续进行上述迭代过程;否则,优化过程结束。
(3)参考集(RefSet)的构建与更新。参考集的大小为RSize,其中包括RSize1个高质量解和RSize2个多样性解(RSize1+RSize2=RSize)。参考集的构建以初始解集Population为基础。首先,从初始解集中选择RSize1个质量最高的解插入参考集,并从初始解集中删除这些解。然后,评估初始解集中剩余解与参考集中现有解之间的相异度,从初始解集中选择相异度最高的解插入参考集,并从初始解集中删除该解;反复执行这一过程,直到参考集中解的数量为RSize时,构建过程结束。参考集的更新以解组合过程产生的新解集合Pool为基础,更新方法同上。
(4)子集(SubSet)产生方法。本文采用最常用的二元子集方法。为了避免重复产生相同的解,只有参考集中的新解能用于子集的产生。
(5)解组合过程。解组合的目的是产生新解(存放于Pool解集中),为后续参考集的更新提供基础解集。本文选用“求并-减点”的策略实现解的组合过程。首先,对子集中的两个解S1和S2进行求并操作得到新解S,此时p≤|S|≤2p(p为中心点数),S可能为不可行解。然后,从S中删除一个设施点,使得删除该点后解的目标函数值增加最少;反复执行该删除操作直到S中设施点的个数为p。从S中搜索待删除点的时间复杂度为O(n),组合过程的时间复杂度为O(n*p)。由此可见,解组合过程是一个非常耗时的过程。
1.3 分散搜索算法的并行化
为了提高分散搜索的效率,本文设计了一种并行分散搜索算法(PSSA)。PSSA采用一种粗粒度的并行策略,即将串行算法中部分反复执行的操作分配给不同进程并行执行,从而提高算法的运行效率。在串行分散搜索算法中,初始解的优化和解组合过程占用了大量的运行时间(分别达到总运行时间的73%和13%)。因此,对这两个过程进行并行化可以大幅提升算法的效率。PSSA采用主从模式:主进程负责高质量解的回收、初始解集的构建、参考集的生成与更新以及少量的初始解优化和解组合任务;从进程主要负责初始解的优化和解组合操作。PSSA的流程图如图2所示。PSSA的实现过程如下。
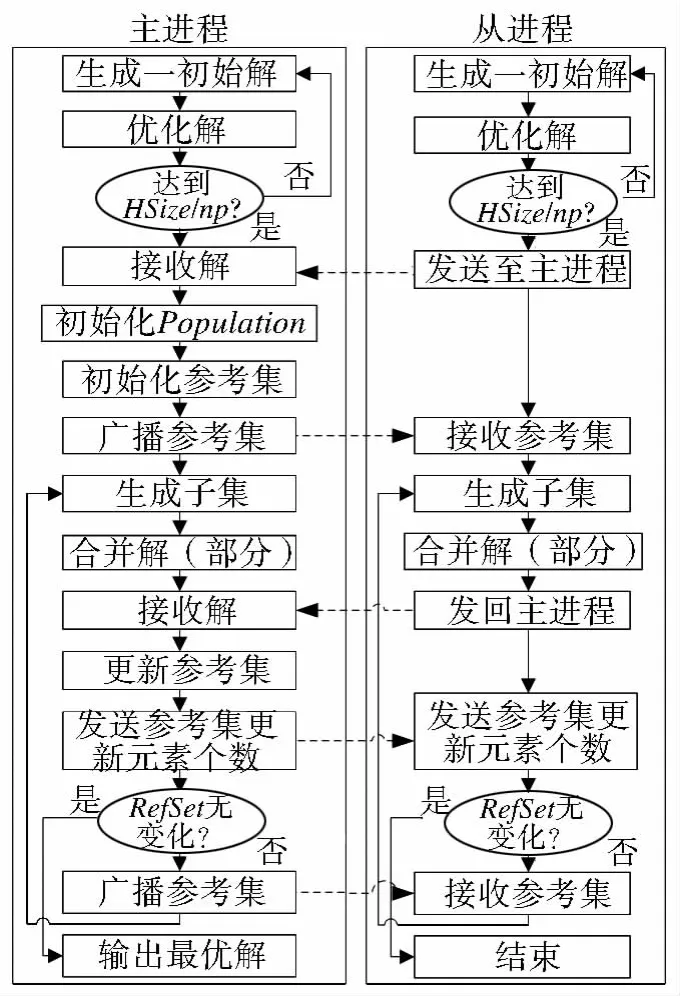
图2 PSSA流程图Fig.2 Flow diagram of PSSA
(1)构建初始解集。在初始解集的构建过程中,对部分解的优化操作是相互独立的,因此可以采用任务并行的策略对其进行并行化。首先,在各进程内随机产生HSize/np(np为进程数)个解并进行优化处理;然后,各从进程将优化后的高质量解发送至主进程,由主进程完成初始解集的构建。为了保证求解质量,当HSize无法被np整除时,需调整各进程内产生高质量解的个数。调整的原则是:各进程产生高质量解的个数相同(避免部分进程闲置等待),且总数不小于HSize。通常,HSize的数目远小于PSize,因此,HSize的小幅增加不会影响初始解集的多样性,反而能加快搜索的收敛速度。
(2)参考集的更新与同步。主进程根据更新后的参考集是否发生变化决定算法是否终止:若参考集无变化,则算法结束;否则,主进程需将参考集中新产生的解广播给各从进程。在广播过程中,首先由主进程向各从进程广播参考集中新解的个数,各从进程收到消息后建立大小对应的接收缓冲区;然后由主进程向各从进程广播参考集中的新解。随着算法迭代次数的增加,参考集中的新解个数会不断降低。因此,该方法能有效地减少冗余通信。
(3)解组合过程。解组合过程中不同子集上的组合操作是相互独立的,因此可以采用区域分解的策略对其进行并行化。首先,将所有二元子集平均分配至各进程,由各进程分别对部分子集进行合并操作;然后,各从进程将合并产生的新解发送至主进程,由主进程进行参考集的更新操作。由于二元子集的产生是一个计算量很小的过程,其计算时间远小于将其广播至各从进程的通信时间。因此,为了减少通信量,各进程均执行一次子集产生操作,而非由主进程产生子集后分发给各从进程。各进程完成子集产生过程后,根据其进程编号和总进程数计算属于该进程的子集,对它们进行解组合操作产生新解,然后将这些新解发回主进程。
(4)结果输出。计算结束后,由主进程将最优解以空间数据表的形式输出至PostgreSQL数据库。输出结果包含一张点表和一张线表:点表含有p条记录(p为中心点数),每条记录为一个设施点,属性数据包括分配到该设施点的所有用户点的距离总和、用户点个数等;线表含有n条记录(n为用户点个数),每条记录为一个用户点,属性数据包括该用户点所属设施点的编号、服务距离等。
2 实验
为了测试PSSA的运行效率和求解质量,笔者在Visual Studio 2010环境下使用C⧺语言进行PSSA的实现,并应用模拟的路网数据进行了相关实验。实验数据包括3个不同规模的数据集,如表1所示。并行环境为一台双核PC(CPU为Intel Core i3 530,内存为3.24GB)和一台四核PC(CPU为Intel Core i5-2400,内存为3.24GB)组成的 Windows PC集群,消息传递接口采用MPICH2。

表1 测试数据集Table 1 Experimental data sets
实验中分别应用Densham-Rushton(DR)算法与PSSA算法(1~6进程),在3个不同规模的数据集中,求解100个中心点的p-中心定位问题。其中,PSSA的元启发参数为:PSize=100,HSize=5,RSize=10,RSize1=5,RSize2=5。由于DR算法与PSSA的结果均依赖于初始解,每次得到的解会略有不同。因此,所有实验结果(包括运行时间和解质量)均为10次反复运行后的平均值。运行结果分析如下。
(1)运行效率。如表2所示,PSSA具有良好的并行效率。当进程数为1、2、3时,运行时间随着进程数的增加而减少;当进程数为5时运行时间最短,比串行分散搜索算法减少了近60%,已经与DR算法相当。但当进程数由3变为4和由5变为6时,运行时间没有减少,反而出现增加的现象。其原因是:当进程数为3或4时,为了保证高质量解的总数不小于HSize(实验中HSize=5),每个进程分别生成2个高质量解(总数分别为6和8);此时,各进程的运算量没有减少,而通信量有所增加(通信时间增加),所以运行时间也会相应增加。因此,当HSize为np的整数倍时(np为进程数,HSize为高质量解个数),PSSA算法的并行效率最好。

表2 运行时间的对比Table 2 Comparison of running time
(2)解质量。表3中目标函数值为将用户点按距离最近分配到各设施点后的距离总和。第一列为DR算法求得的目标函数值,第二到七列分别为PSSA(1~6进程)得到的结果较DR算法结果的改进比例。由表中数据可以看出,PSSA得到的结果均优于DR算法,将目标函数值降低了0.4%~0.9%。
在数据集pmp_5569_7667中,PSSA得到的结果如图3所示。该区域覆盖东北及华北部分地区,中心点数为100。五角星表示最终解的设施点;所有用户点用一条直线与其所属设施点相连,便于分析人员定位。

表3 解质量的对比Table 3 Comparison of results

图3 PSSA计算结果(数据集:pmp_5569_7667)Fig.3 PSSA′s result on data set pmp_5569_7667
3 结论
本文基于分散搜索实现了高效的p-中心定位算法,并采用主从模式对串行算法中较耗时的解优化和解组合过程进行并行化,实现了解算p-中心定位问题的并行分散搜索算法(PSSA)。基于不同规模路网数据的实验表明:1)PSSA具有良好的加速比,高质量解个数为进程数的整数倍时,并行效率最高;2)尽管PSSA算法的运行时间与DR算法相当,但PSSA算法获得了更高质量的解(目标函数值较DR算法降低0.4%~0.9%),兼顾了算法的高效率与解的高质量。
[1] 黎青松,杨伟,曾传华.中心问题与中位问题的研究现状[J].系统工程,2005,23(5):11-16.
[2] HAKIMI S L.Optimum locations of switching centers and theabsolute centers and medians of a graph[J].Operations Research,1964,12(3):450-459.
[3] GAREY M,JOHNSON D.Computers and Intractability:A Guide to the Theory of Np-completeness[M].Freeman,1979.
[4] 都志辉.高性能计算并行编程技术:MPI并行程序设计[M].北京:清华大学出版社,2001.6-11.
[5] MLADENOVIC N,BRIMBERG J,HANSEN P,et al.The pmedian problem:A survey of metaheuristic approaches[J].European Journal of Operational Research,2007,179:927-939.
[6] TSENG L Y,WU C S.The multistart drop-add-swap heuristic for the uncapacitated facility location problem[C].The 6th International Conference on Informatics in Control,Automation and Robotics,Intelligent Control Systems and Optimization.INSTICC Press,2009.21-28.
[7] 徐先瑞,李响,李小杰.改进的求解约束P-Median问题的分散搜索算法[J].计算机工程与应用,2011,47(20):28-30.
[8] ALCARAZ J,LANDETE M,MONGE J F.Design and analysis of hybrid metaheuristics for the reliability p-median problem[J].European Journal of Operational Research,2012,222(1):54-64.
[9] LANDA-TORRES I,SER J D,SALCEDO-SANZ S,et al.A comparative study of two hybrid grouping evolutionary techniques for the capacitated p-median problem[J].Computers &Operations Research,2012,39(9):2214-2222.
[10] CADENAS J M,CANÓS M J,GARRIDO M C,et al.Soft-computing based heuristics for location on networks:The p-median problem[J].Applied Soft Computing,2011,11(2):1540-1547.
[11] GARCÍA-LÓPEZ F,MELIÁN-BATISTA B,MORENO-PÉREZ J A,et al.Parallelization of the scatter search for the p-median problem[J].Parallel Computing,2003,29(5):575-589.
[12] RESENDE M G C,RIBEIRO C C,GLOVER F,et al.Scatter Search and Path-Relinking:Fundamentals,Advances,and Applications,in Handbook of Metaheuristics[M].Springer,2010.87-107.
[13] DENSHAM P J,RUSHTON G.A more efficient heuristic for solving large p-median problems[J].Papers in Regional Science,1992,71(3):307-329.
