一种无结构对等网络资源发现方法
2013-07-13薛冰冰俞卫华
薛冰冰,俞卫华,霍 华
(河南科技大学电子信息工程学院,河南洛阳471023)
0 引言
对等网络主要采用非集中式的拓扑结构,各节点之间直接共享资源,信息传播迅速,网络中用户间信息共享的前提是资源的定位。因此,覆盖网络中的资源发现机制是P2P技术研究的重点。
按照资源发现机制,对等覆盖网络大致可分为混合式、结构化和无结构P2P网络[1]。混合式网络体系仍没有摆脱中心化的特点,存在网络瓶颈和单点故障等局限性,Napster是典型的代表。结构化P2P主要采用基于DHT[2]的分布式发现策略,这种发现机制对特定资源的发现效率较高,适合规模较小的网络应用。分布式无结构P2P网络,如Gnutella[3],在拓扑结构上没有明确控制,节点的动态变化不会对网络结构造成影响,适合较大规模的P2P应用,但如何使节点物理位置与上层覆盖网络相一致[4],提高搜索成功率[5],降低路由延迟[6-7]等问题也成为关注热点。
分布式无结构对等网络中,节点和资源都是随机分布的,资源请求者只能通过邻居节点将消息转发扩散。目前,常见的无结构P2P资源发现方法有Flooding[8]、Random Walks[9]等。这些方法采用盲目的消息转发机制,可以快速定位资源,有较好的容错能力,但随着网络规模的增大,节点有可能多次收到相同的资源请求,会产生大量查询数据。
采用Flooding的搜索方法,节点请求资源时,首先将请求发送给邻居节点,若邻居节点中存在拥有资源的节点,则响应源节点;否则,所有邻居节点将向其各自的邻居节点继续转发请求消息,直到发现目标或者消息跳步达到了设置的最大范围。
Random Walk发现的方法中,节点不再将请求消息转发至所有邻居,而是随机选择k个邻居节点转发消息,这种方法产生的消息流量少,但增加了网络搜索时延。针对无结构对等网络资源发现中出现的问题,k-Random-Walker[10]、Modified-BFS等改进的搜索算法相继提出,本文在研究相关优化策略的基础上,提出了一种基于兴趣相似机制的资源发现方法,将兴趣相似的节点组成域,根据节点的兴趣相似度动态改变域内的节点构成,同时,通过域之间的友好度来提高路由效率。
1 兴趣相似机制
首先定义了相关网络模型和节点间兴趣相似度,并在此基础上给出基于节点兴趣相似度的资源发现方法DPIS。节点在信息传递过程中,维护相应的兴趣度索引,依据各自的兴趣度索引动态调整域内成员;域内资源发现失效的情况下,通过域友好度索引导向路由,减少消息转发过程中的冗余。
1.1 覆盖网模型
无结构对等系统对覆盖网拓扑没有严格限制,考虑与物理网络的匹配,首先将物理相近的节点分组,再根据节点间的兴趣相似度,将系统中兴趣相似度接近的节点划分在同一域中,形成重叠网络。组内和域内均选择性能优越的节点作为超节点,其中,保存本组或本域内普通节点的数量、资源等相关信息,并维护域友好度索引表,记录频繁与之联系的域排序。域内普通节点中除保存自身资源信息,还需要维护兴趣相似度索引,记录与之兴趣相似度最相近的若干节点信息。组和域的划分如图1所示。资源发现首先在本域内的同组节点中进行,若同组域内发现失效,则在域内其他组的节点中进行,最后考虑跨域搜索。
节点间的兴趣相似度反映了节点所拥有资源的相关度,节点的相关度大,它们进行联系和互访的可能性就会增加,这一点为路由选择提供了参考,下面给出节点兴趣相似度的定义。
1.2 节点兴趣相似度
对于网络中每个节点所拥有的资源,其特征可以通过相应的关键字来标识,参照TF*IDF加权技术[11]为资源关键字赋予相应的权重。关键字 Ki在资源 Sj中的重要度用权重 Wij来表示,Sj=(W1j,W2j,…,Wnj)和 q=(W1q,W2q,…,Wnq)作为资源Sj和搜索请求Q的向量表示,则Sj和Q间的相似度计算公式如式(1)所示,
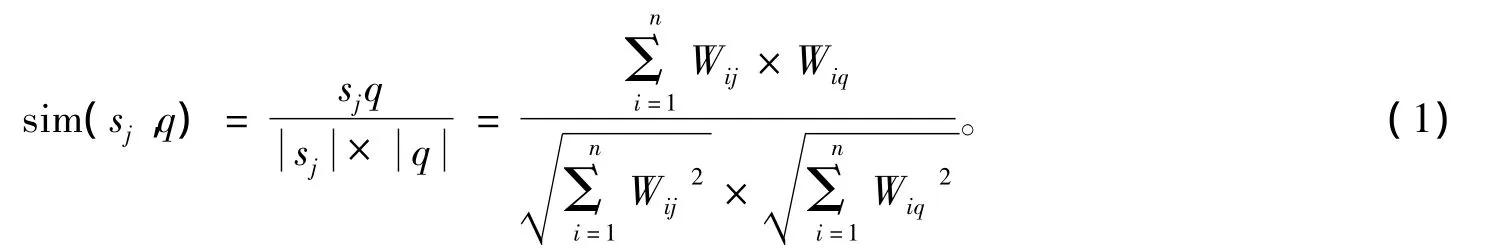
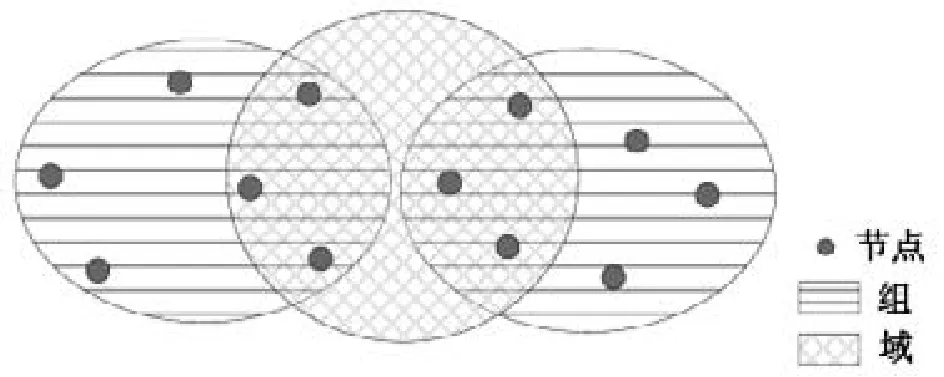
图1 组和域的划分
在现实的网络环境中,若节点Di在某一时间里多次发起对资源Sk的请求,在以后的时间里节点Di对Sk再次发起请求的可能性很大,拥有资源Sk的节点Dj对节点Di再次响应的可能性增大。若节点Di在单位时间里从Dj获取请求响应的次数为Nij,取节点Di和Dj中资源数的较小值m,则Di和Dj的资源向量分别表示为 dki=(W1i,W2i,…,Wni)和 dkj=(W1j,W2j,…,Wnj),在式(1)的基础上,给出节点 Di和 Dj的兴趣相似度h(i,j)如式(2)所示,
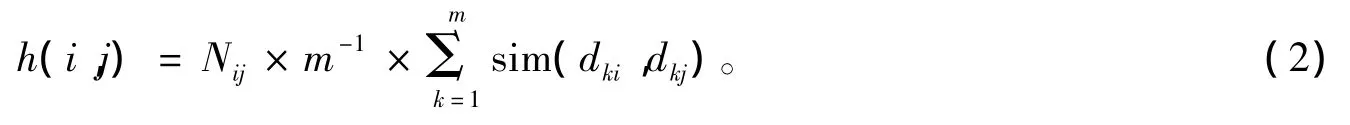
由于资源发现过程中Nij是动态变化的,节点所维护的兴趣相似度索引也随之变化,在域规模固定的前提下,域中节点根据索引表的变化进行调整,动态优化系统拓扑,使系统中兴趣相似度高的节点聚类在同一域中。
1.3 发现策略
前面分析的网络模型中,域的节点规模显然小于组的节点规模,同一域中的节点可能被划分在同一组,也可能被划分到不同的组,资源发现时,请求消息首先在本域内的同组节点中传递;若同组域内发现失效,则在域内其他组的节点中进行消息传递;若域内组间发现仍失效,考虑选择互访频繁的友好邻域进行跨域搜索,具体方法如下:
(Ⅰ)搜索发起者Dq首先访问所在域的超节点S1,查询S1的节点信息索引表,表中记录了该域的节点数目,域内普通节点ID,节点所在组ID等信息,通过信息索引表确定S1中Dq所在组的节点,并在这些节点中采用k阶随机走发现方法搜索请求资源。如果资源发现成功,进行相应的一系列动态调整,如更新Dq与目标节点的兴趣相似度值等,为邻居节点调整提供依据。
(Ⅱ)域内同组搜索失效的情况下,查询S1中的组超节点索引表,表中存有该域包含的所有组超节点,这些组超节点按照与S1的物理距离递增排列,选择距S1较近的域内组进行和域内同组搜索相同的资源发现过程。
(Ⅲ)如果S1域内的所有组均发现失效,则查询S1的域友好度索引表(相邻域表),相邻域表中记录了在S1的组超节点索引表里所记录的所有域中与域S1互访频繁的域,即与域S1友好度高的域,这些域按访问频率递减排列,通过相邻域表,转向域友好度最高的域,继续根据具体情况选择上述两种方式之一进行搜索,直至获取资源或发现失败。
消息路由过程中,每跳步3次检测Dq是否获取资源,已获取则停止转发,避免产生过多消息冗余;每次发现目标或失败,都需要对相应节点所维护的各索引信息进行更新,动态调整网络拓扑。
2 仿真分析
对等网络资源发现方法的性能可以从搜索时间、带宽利用率、消息冗余等多方面衡量。在前文构造的无结构对等网的基础上,着重从搜索时间和消息冗余这两方面对DPIS的查询性能进行评价。使用Java语言在模拟环境下产生不同节点规模的网络拓扑,设定节点平均连接度为10,执行周期为200,每个周期加入100个新节点,随机选取节点发起查询请求,以平均查询时延和消息数量为主要测度,为便于观察,将Flooding和分组后的随机漫步G-Random Walk方法作为基准,与DPIS方法进行对比分析。
图2是不同网络规模下发起相同资源请求的平均查询时延比较。随着节点数量的增加,盲目搜索的标准泛洪方法Flooding需要将查询请求向邻居节点的邻居节点进行转发,这个过程中,延长了搜索路径的长度,产生大量冗余,查询时延明显增加。GRandom仅考虑了节点的位置因素,目标节点通常并不会在同组内的节点中出现,即使随机漫步选择了部分邻居节点进行消息转发,仍有较大的网络消耗,节点规模在1 000个左右时,平均查询时延为0.6~0.7 s。DPIS的局部路由采用k阶随机走,平均时延曲线走势与G-Random Walk相似,由于根据兴趣相似度将节点划归在组和域内,目标节点通常与发起查询请求的节点具有接近的兴趣相似度,搜索范围缩小至同组同域内,搜索路径迅速缩短,路由跳数减少,随着节点规模的增大,在节点数接近1 000个时,平均查询时延为0.4~0.5 s。
消息转发数量从另一方面体现网络带宽利用率,查询消息被转发的次数决定了网络中产生的总消息量,相同查询请求的前提下,总消息量少,说明目标节点在较少的路由跳数内被找到,网络中产生的消息冗余较少,查询性能较高。为进一步研究验证DPIS的查询性能,采用不同的网络规模,查看标准泛洪、分组随机漫步和DPIS方法中产生的消息转发数量,对比网络资源消耗量。
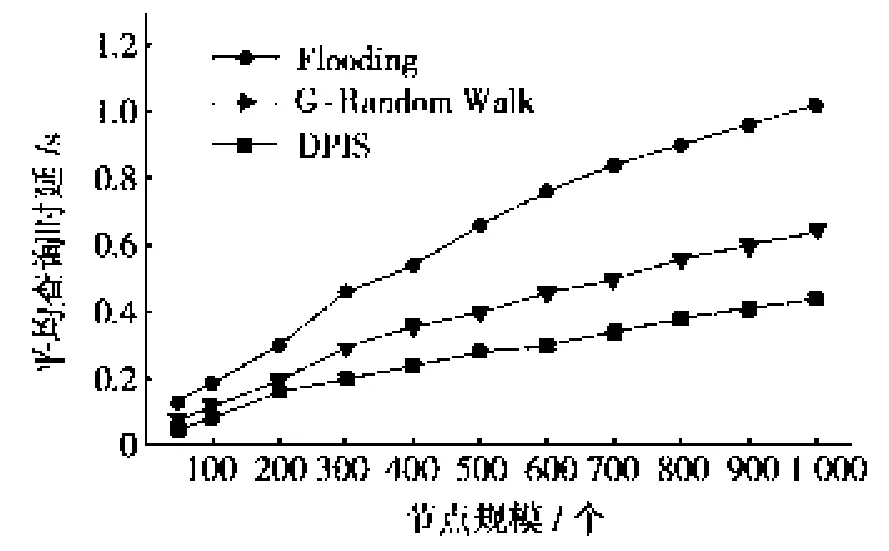
图2 平均查询时延比较
在不同节点规模下网络中消息转发数量的比较结果如图3所示。Flooding搜索过程中节点向所有邻居节点转发消息,节点数量增加至接近200时,网络规模较小,此时消息数量增长较慢,随着节点规模不断增大,消息数量急剧增加。G-Random Walk在组内选择部分邻居节点转发消息,网络规模对消息数量影响比标准泛洪明显减少,节点数量增至近1 000个时,消息数量接近15 000个。DPIS方法考虑拓扑匹配,同时将节点按兴趣相似度划分域,查询在域内进行,路由跳数得到控制,减少了冗余消息转发,在节点规模增加的情况下,消息转发数量维持在相对稳定的范围内,较G-Random中下降了近50%,与标准泛洪相比,网络中产生的消息数量明显下降,当节点规模增至1 000个,冗余减少达80%。由此可见,在较大规模的无结构对等网络中,DPIS搜索具有控制冗余和减少搜索时延的优越性,提高了搜索效率。
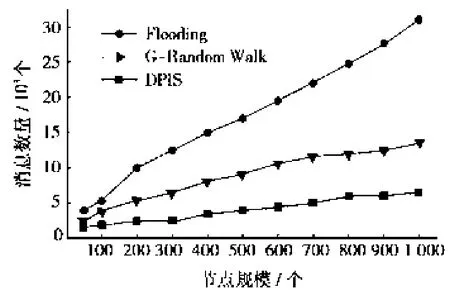
图3 消息数量比较
3 结论
无结构对等网络中的盲目搜索通过在网络中传播查询信息,把信息不断扩散至每个节点,这种搜索策略具有高覆盖率、易于实现等特点,但它同时产生大量冗余消息,限制了带宽利用。针对无结构对等网络资源发现中存在的问题,提出了一种基于节点兴趣相似度的资源发现方法,根据物理位置对节点分组,将兴趣相似的节点聚类形成域,在资源发现过程中动态调整网络拓扑,优化发现性能。通过仿真与两种盲目搜索方法的性能进行了比较,并分析了仿真结果,但无结构覆盖网络搜索中资源的准确定位,提高查全率等问题仍需在以后工作中进一步研究。
[1]陈贵海,李振华.对等网络:结构、应用与设计[M].北京:清华大学出版社,2007.
[2]李运娣,冯勇.基于DHT的P2P搜索定位技术研究[J].计算机应用研究,2006,23(10):226-228
[3]Ripeanu M.Peer-to-Peer Architecture Case Study:Gnutella Network[C]//Proceedings of 1st International Conference on Peer-to-Peer Computing.2001:99-100.
[4]徐浩,欧阳松.无结构P2P系统的重叠网拓扑优化[J].计算机工程与应用,2010,46(22):144-146.
[5]吴开贵,曾家国,吴长泽,等.基于预算机制的非结构化P2P网络搜索算法[J].计算机应用,2010,30(5):1166-1170.
[6]朱桂明,郭得科,金士尧.基于副本复制和Bloom Filter的P2P概率路由算法[J].软件学报,2011,22(4):773-781.
[7]张茉莉,张延园,唐焱,等.利用P2P网络的拓朴特征提高其路由性能[J].河南科技大学学报:自然科学版,2006,27(5):42-44.
[8]Song J,Lei G,Zhang X D.Light Flooding:Minizing Redundant Message and Maximizing the Scope of Peer-to-Peer Search[J].IEEE Transactions on Parallel and Distributed Systems,2008,19(5):601-614.
[9]刘智勇,郑滔,伍伟绩.基于随机漫步的信任路径搜索算法[J].计算机工程,2009,35(18):156-158.
[10]Lv Q,Cao P,Cohen E,et al.Search and Replication in Unstructured Peer-to-Peer Networks[C]//Proceedings of the 16th ACM International Conference on Supercomputing.2002.
[11]陈旭,陈德华,乐嘉锦.基于语义相关度排序的政务信息资源检索算法[J].计算机工程与应用,2011,47(25):121-125.
