一种基于数字图像处理的精确车牌识别系统
2013-07-09周慧娟
向 荣 周慧娟
(浙江大学数字技术及仪器研究所 杭州 310027)
0 引 言
机动车牌照作为机动车车辆的惟一标识,在车辆标识、车辆管理中发挥着关键作用.因而车牌识别系统(license plate recognition,LPR)作为智能交通系统的核心组成部分在停车场管理系统、高速公路超速自动化管理系统、公路布控、电子警察和小区车辆门禁系统等领域有着极其广泛的应用前景[1].从车牌识别系统进入中国以来,国内有大量的学者在从事这方面的研究,提出了很多新颖快速的算法.但就目前实际商用以及实验室的识别率来看,目前中国车牌识别系统的准确性还有待提高.因此,本文基于大量的实际车牌图像的测试,提出了一种高识别率的车牌识别系统.该系统中在定位以及倾斜校正中提出了若干新算法,最后的实验结果表明,这些算法效果显著,整个系统对随机背景下车牌的正确识别率达到了90%以上.
1 系统设计与实现
车牌识别技术主要利用每一辆汽车牌照的惟一性和互异性2个特点,将采集到的车辆图像经过一系列的处理,识别出车牌号码.按照模块设计原则,该识别系统分为车牌定位、倾斜校正、字符分割以及字符识别4个模块.各个模块之间功能相对独立,依次串联成整个识别系统,整体框图见图1.
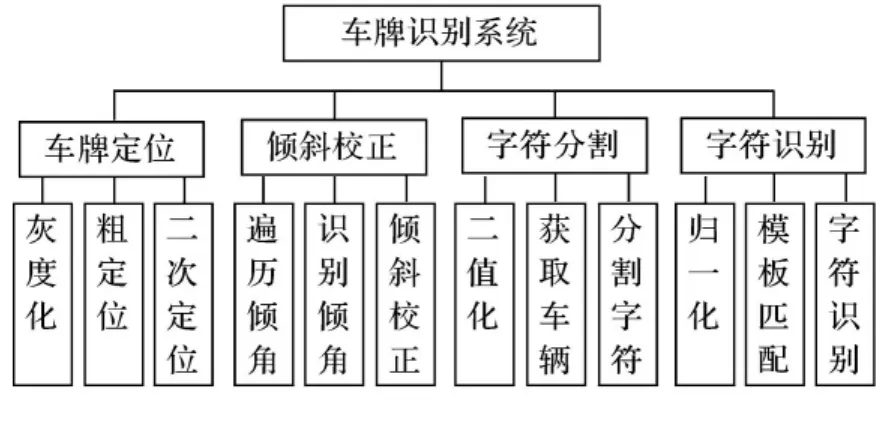
图1 车牌识别系统总体框图
1.1 车牌定位
车牌定位之前,要首先将彩色图像灰度化,考虑到我国车牌的背景颜色与字符颜色的对比特点,本系统采用了独创的区分度更大的灰度化公式
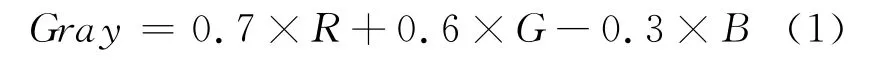
本系统采用3级定位,逐步求精,现分述如下.
1)粗定位 在粗定位阶段,依次进行Gauss-Laplace边缘检测,阈值二值化,连通域滤波处理,最后利用车牌区域的边缘信息进行粗定位,粗定位算法过程如下:(1)搜索水平方向跳变数与每行字符点总数;(2)跳变数差分,搜索车牌上下边;(3)将取间隔大于车牌高度的相邻两边为上下边候选组;(4)将过于接近的上下边组从候选车牌可能组中剔除;(5)扫描可能的车牌上下边的车牌字符垂直投影并进行邻域3列均值滤波;(6)用一个宽度为60像素,高度为候选车牌上下边距的抽样框进行垂直投影值扫描,得出左右边界;(7)利用牌宽高比的先验知识将候选组中车牌宽高比不符合一定范围内的比例关系的组进行滤除.
2)二次定位 在二次定位阶段,依次进行水平顶帽变换,去噪处理,力图将车牌的准确位置确定出来.二次定位算法过程如下:(1)逐行扫描并统计处跳变数;(2)对跳变数矩阵进行邻域平均,使用[-3,2,1]模板对每行跳变数进行卷积操作,再用[1,2,-3]模板对每行跳变数进行卷积操作,检测出该车牌候选组的上下边;(3)再从左往右扫描,将每列的水平跳变点数累加.然后再次从左向右扫描,将跳变数进行左右邻域均值处理,取出大于某个阈值的列为该车牌候选组的左边界,同样的方式得到右边界[2].
3)最终定位 最终定位是在倾斜校正后完成,它的作用是获取精确的车牌信息,力求将所有字符区域识别出来而不带来任何其他的干扰.在倾斜校正后,对其进行改进的Otsu二值化处理.最终定位过程如下:(1)求出每行背景像素所占的百分比;(2)求出每行水平跳变数以及相邻上下行间的跳变数的差;(3)按照17×1的模板进行水平腐蚀,求出相邻两行的前景像素值的特征;(4)再次进行水平顶帽变换,并求出上下两行的跳变数,采用[-3,2,1]与[1,2,-3]模板进行邻域跳变数卷积操作;(5)对(1),(2),(3),(4)步中求得的特征值进行融合,从而求出车牌的精确上下边界;(6)扫描以车牌既定高度的1/3为宽,车牌高度为高的抽样框内的垂直投影,确定最终车牌左右边界.最终定位完毕.结果参见图2.
图2 二次定位
1.2 倾斜校正
在车牌水平的情况下,车牌的水平投影具有2个明显的波谷,这是由车牌字符与边框中间的间隙形成.本文考虑采用水平投影方差为判断依据,求出倾斜角度并进行校正.该算法的具体过程如下:(1)将车牌以1°为单位,以逆时针方向为正,依次倾斜-15°~15°;(2)求出每次倾斜后每行的投影点数;(3)求出每行投影点数的均值和方差;(4)搜索方差最大时的倾斜角度;(5)调用C#的函数RotateTransform来对图形对象进行旋转进行倾斜校正,处理效果见图3.

图3 倾斜校正
1.3 字符分割
本文提出一种将车牌标准尺寸的先验知识与车牌垂直投影特征的后验知识相结合的分割思想.具体步骤如下:(1)根据车牌标准尺寸,计算每一个字符的列标与车牌宽度的比例;(2)将比例系数乘以定位车牌子图像的宽,求出车牌中的字符边界大致位置,以该位置在某一邻域内进行搜索.根据车牌字符的垂直投影,判断精确的车牌字符边界,同时还要验证车牌中是否存在“1”;(3)依据所求车牌字符边界,将车牌字符分割成为7个字符子图像;(4)将子图像归一化为35×70的尺寸[3-5].
1.4 字符识别
本文采用了多种统计模式识别综合法,首先采用了模板匹配的方法,计算字符与模板中最为相似的即为识别结果.匹配过程的数学描述为
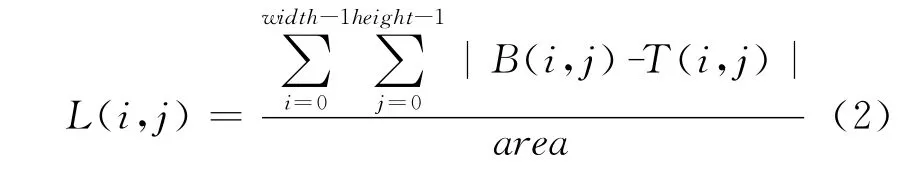
由于模板匹配对相似的字符之间的识别率很差,如“8”和“B”,“O”和“Q”,“5”和“S”,“Z”和“2”,等等.仔细比对这些相似的车牌字符可以发现,虽然从形状上很难区分这些相似字,但是英文字符的4个角通常与数字有着很大的不同.利用这一点,本系统使用4个角的小区域相似度来对模板匹配进行修正.整个识别过程如下:(1)利用上述计算公式算出车牌字符与每一个模板的相似百分比;(2)同时计算车牌字符与每个模板的4个角的相似度,将加权后的角相似度加上相似百分比作为判定依据,将最大的相似百分比作为识别结果.
2 结果与分析
测试样本为随机背景含车牌的图片200张,其中图片的分辨率从5万~80万像素不等,车牌倾斜角度各异,光线明暗程度有别,图4为经过定位和分割的部分车牌识别结果.

图4 定位及分割结果
由图4可见,本系统提出的3级定位策略有效降低了定位的虚警率,最终定位的大多数区域为精确的车牌区域.另外,粗定位以后的略微放大车牌定位区域,也在一定程度上降低了第一次定位中的偏差,而在后续定位中达到将车牌区域准确的切分出来.在保留字符完整的同时,切分到字符的边缘,这样的定位结果为之后的分割提供了十分有利的处理目标,定位准确率为93.5%.
从图4还可以发现,本系统的分割结果相较于其他系统无疑精确很多.特别要指出的是,对于“1”字符的分割一直是个易错点,图4充分证明了本系统的分割策略行之有效,分割效果良好.
图5是从本系统的结果显示区截取的图像.前19幅均识别无误,但最后一幅出现了识别错误.在这些错误中,大部分是相似字的识别错误,在最后一幅图中,汉字二值化的结果不够清晰,结果也发生了很大的偏差,这是由二值化阈值不当造成.最终识别准确率为91%.

图5 识别结果
3 结束语
本文以Visual Studio为开发工具,C#为开发语言完成了一套完整的车牌识别系统的设计开发,并对车牌识别中传统算法中存在的不足进行了分析,提出了一些新的识别方法.实验证明,整个系统可识别的图像分辨率从5万~80万像素不等,车牌倾斜角度各异,光线明暗程度有别,单幅图像识别时间在0.7~2s以内.该算法满足实际需要,具有一定可靠性与可用性.在接下来的研究工作中,本课题还可在以下几个方面进行深入的研究.考虑与图像采集端进行综合设计,以便更好的发挥先验知识的定位效果,最终有利于形成算法产品化,实用化.优化现有的识别算法,使得系统的准确率更高,鲁棒性更好.在系统实时性方面,尽量简化冗余步骤,使速度更快,更具实用化.
[1]白晶心.车牌识别系统的实现[D].北京:北京邮电大学,2009.
[2]王 叶.车牌识别系统中字符切分和识别技术的研究[D].北京:北京邮电大学,2009.
[3]ACONCI J A,CARVALHO E R,RAUBER T R.A complete system for vehicle plate localization,Segmentation and recognition in real life scene[J].IEEE Latin America Transactions,2009,7(5):110-119.
[4]何铁军,张 宁,黄 卫.车牌识别算法的研究与实现[J].公路交通科技,2006,23(8):147-149.
[5]刘 兴,蒋天发.智能车牌识别系统中消除图像干扰的方法[J].武汉理工大学学报:交通科学与工程版,2005,29(5):805-806.
