朴素贝叶斯算法和SVM算法在Web文本分类中的效率分析
2013-03-30詹毅
詹 毅
(成都大学旅游文化产业学院,四川 成都 610106)
朴素贝叶斯算法和SVM算法在Web文本分类中的效率分析
詹 毅
(成都大学旅游文化产业学院,四川 成都 610106)
为分析对比朴素贝叶斯算法和SVM算法在Web文本分类中的效率及其适用的范围,构建了一个Web分类系统,此分类系统将已分类的Web网页作为训练集,利用分类算法构建Web分类器,通过Web测试集评价两类算法在Web文本分类中的性能体现,为Web文本分类算法选择提供一定的参考依据.
Web分类系统;朴素贝叶斯算法;SVM算法;效率分析
0 引 言
随着互联网上海量文本信息的增加,数据挖掘扩展到了Web数据挖掘,文本挖掘也随之扩展到了Web文本挖掘.Web文本分类技术是Web文本挖掘的重要分支之一,而文本分类算法的选择对Web文本分类技术至关重要.本研究通过构建Web分类系统,将朴素贝叶斯算法和支持向量机算法(Support Vector Machine,SVM)在自建的Web分类系统中进行测试对比,探讨2类算法在Web分类过程中的特性及适用范围.
1 Web分类系统总体设计
为选择一个对网页内容已分类的Web网站,本研究选取网易门户网站(www.163.com).从该网站下载数据,并将其分为训练集和测试集,然后利用朴素贝叶斯算法和SVM算法对其进行建模和测试,最终评价2种算法的性能.分类系统总体流程设计如图1所示.
2 Web数据采集及处理
2.1 Web数据预采集
采用Hatem Mostafa编写的开源Net Crawler[1]作为网络爬虫(Spider),从网易下载Sports,Life,Finance等7个分类下的共约80 000个HTML文件,并对它们进行数据预处理.数据处理流程如图2所示,具体步骤为:

图1 Web分类系统数据流程设计图

图2 数据预处理流程图
1)使用网络爬虫下载网易7个分类下足够数量的HTML文件;
2)利用开源软件SgmlReader[2]和部分人工处理的方法将每个正常HTML文件转换为符合XML格式的XML文件;
3)对每个XML文档提取其主题信息;
4)利用中科院ICTCLAS分词器[3]将提取出的文本信息进行分词,并以向量空间模型的形式储存.
在步骤4)时,可根据不同的文本分类算法对单词做进一步的统计,生成不同的向量模型.使用朴素贝叶斯分类过程中,由于算法需要“单词—词频”数组对及“单词—类别”对应的频率矩阵,其对空间要求相对较小但对查找速度要求较高,故本研究采用.NET类库中的Hashtable存储上述向量,而在SVM算法中必须生成“文档—词频向量”向量矩阵,需利用二维数组满足相应要求,对存储空间要求较高.
2.2 算法建模
2.2.1 朴素贝叶斯算法建模.
朴素贝叶斯算法描述[4]如下:

1)收集Docs中所有的单词;
2)vocabulary←Docs中文本文档出现的所有单词集合;
3)计算概率P(Vj)和 P(wk|Vj):
①对V分类集中的每一个目标值Vj有,
docs←Docs中类标签的Vj的文档子集,

n←在docs中不同单词的总数,
②对vocabulary中每一个单词wk有,
nk←单词wk在docsj中出现的次数
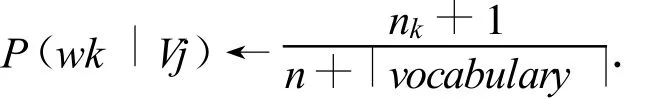
实现过程中,利用Hashtable存储 vocabulary,利用j个HashTable以 <wk,nk>的格式存储每个分类下的词频统计信息,得到n,nk,|vocabulary|,最终求出P(wk|Vj).将所有w对应所有V的P(wk|Vj)值储存为一个K行J列的矩阵,为下一步测试数据做准备,其中,K是所有wk总数,J是所有Vj总数.
2.2.2 SVM算法建模.
SVM算法作为新一代机器学习算法,近年来被成功地应用到很多模式识别问题中,其在数学上表示为求解一个二次规划问题[5].因此,SVM算法可以利用Matlab中的quadprog函数实现建模.在选择核函数K(x1,x2)=(x1*x2+1)2后(该核函数是分类系统中较常用的一个核函数,也有文献中指出文本分类多是线性可分的,可以使用线性核函数[6]),利用文献[5]中的算法,可编写Matlab程序实现SVM算法建模.
3 文本分类算法评估
3.1 文本分类算法评估依据
对分类算法的性能评估其主要依据来自于各分类算法对测试集的评估结果,根据文档测试集的实际真实类别Oc和分类算法所分类识别的类别Pc之间的关系,可形成如表1所示的混淆矩阵[4].其中,数据集的类别用c1,c2,…,cm表示,数据a(Oci,Pcj)表示真实类别为Oci,分类识别类型为Pcj的实例数量.

表1 分类混淆矩阵
从表1中可以看出,对角线所示的数字为分类正确的实例个数,最理想的分类算法应是除对角线上的数据不为0外,其余所有各个位置全部为0.
通常,算法C的精确度ACC(C)可以定义为,
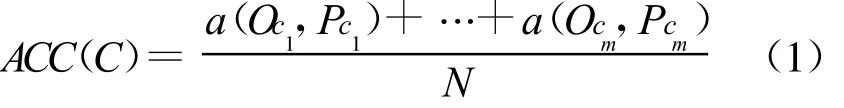
式中,N为实例的总个数.
对于每个单独类,还可以定义2个度量值,即召回率(查全率)和准确率(精度).
召回率(Recall)是实际为ci类别的所有实例中被分类算法正确分类为ci的比例,
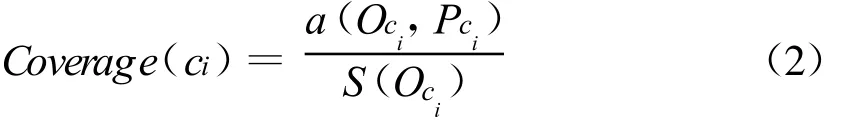
准确率(Precision)是所有被分类算法识别为 ci类的实例(包括实例类别为其他类而错分到ci中实例)中确实是分类为ci的实例所占的比例,
一般期望召回率和准确率同时都尽可能高,这2个指标高,则说明该分类算法更有效.如果用一个指标来平衡这2个指标,则可以定义 F1测度.F1测度是一种综合了准确率与召回率的指标.只有当2个值均比较大的时候,对应的F1测度才比较大,它是比单一的召回率和准确率更具有代表性的指标.
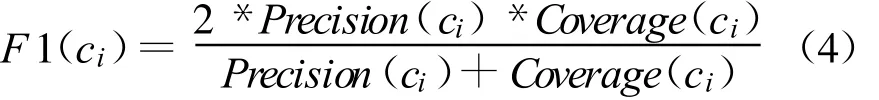
实际上,F1测度就是概率与统计中F指数的常用形式(β=1).F指数定义为,
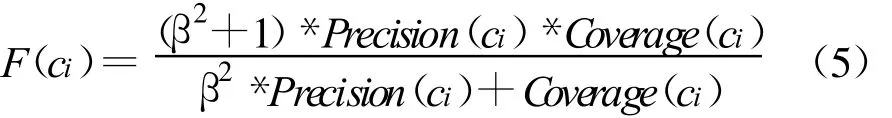
式中,β是权重,且 β>0.
3.2 朴素贝叶斯算法与SVM算法评估
3.2.1 朴素贝叶斯算法评估.
朴素贝叶斯的测试算法[4]如下,
//Doc为待分类的目标文档,ai表示Doc中第i个单词.
2)返回v.
朴素贝叶斯分类测试根据朴素贝叶斯建模得到的P矩阵,查找若干矩阵值并求和且比较和大小,这一过程完成较快.同时,空间占用率也只有O(K*J+T*K)的大小,其中,K 是vocabualry中的单词数目,J是分类总数,T是测试文档总数.事实上很少有一个文档包含了vocabulary中的所有单词,所以实际的空间占用会比T*K少得多.
表2为利用7 000*7个训练集训练后的朴素贝叶斯分类器对3 500*7个测试集的测试结果.
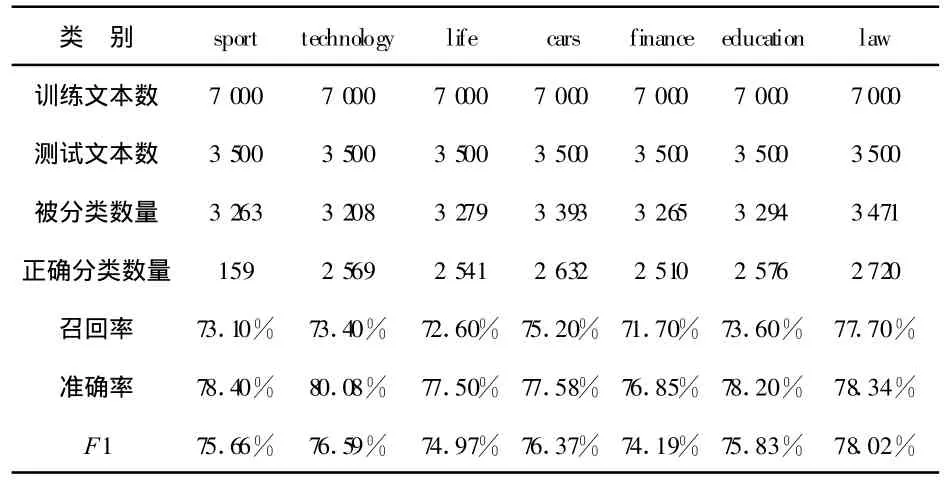
表2 朴素贝叶斯分类器测试结果
由表2数据可知,在处理24 500个文档的情况下,朴素贝叶斯分类器的平均召回率达到73.60%,平均准确率达到78.03%.
3.2.2 SVM算法评估.
因为用于SVM的分类方法一次只能划分正类和负类,所以需要对业务需求中的7个分类逐一进行分类.本研究采取一类对余类的多类算法[7],以其中一个类别为正类,其他为负类来训练SVM,并使用其对测试集进行测试,在计算正确率时使用如下公式,

在部署实施此分类系统时,判断任一篇未知类别文档分类的方法是:假定它属于分类1,以分类1为正类,其他类为负类来训练SVM分类器;测试未知类别文档类型,若类型为正,则未知类别文档类别为1,否则假定它属于分类2.重复上述过程,直至找到它为正的类别,或者在所有类别都被假设而无一为正后,认为该文档类型是无法分类的文档类型.
本研究经过编写Matlab决策函数对1 217个文档进行训练后,对916个文档进行了测试,测试结果如表3所示.
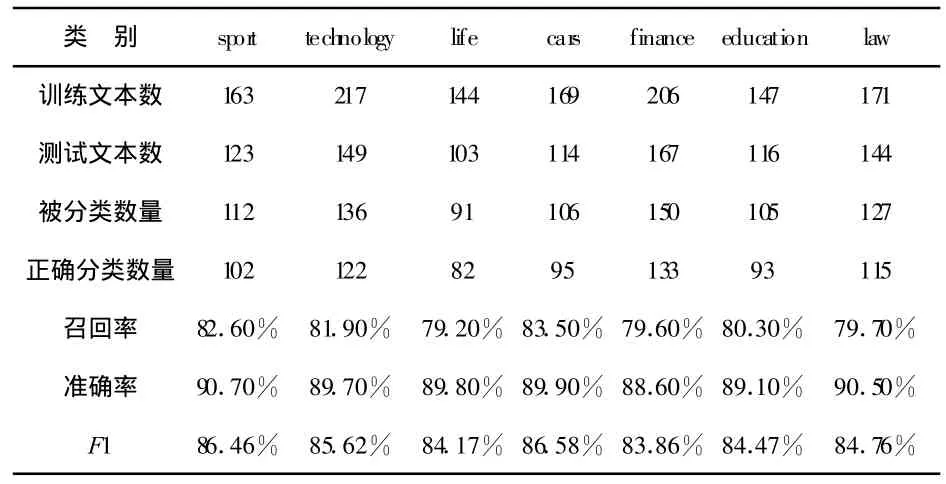
表3 SVM分类测试结果
表3结果显示,全部文档都被标记了分类,准确率平均为89.79%,召回率平均为80.97%,F1测度的平均值为85.13%.
3.2.3 算法性能比较.
朴素贝叶斯算法和SVM算法所做对比测试中的性能参数如表4所示.
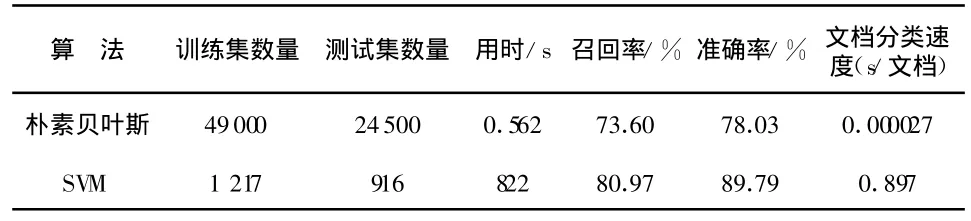
表4 朴素贝叶斯与SVM性能比较
4 结 论
综合全部实验对比结果,在召回率和准确率上SVM算法有较大优势,但是在分类速度和训练集、测试集大小上,朴素贝叶斯算法则拥有明显优势.因此,在处理大规模的文档且对分类精度要求相对不是很严格的情况下,朴素贝叶斯算法更为适用.反之在处理小规模文档且对精确度要求较高的情形下SVM算法更为适用.另外,如果分类任务是在两类之中分出一类,SVM算法更为方便,反之如果是多类任务的划分,则朴素贝叶斯算法更为方便.
[1] HatemMostafa.NetCrawler[CP/OL].[2006-3-19].http://www.codeproject.com/KB/IP/Crawler.aspx,2012-10-11.
[2] Chris Lovett.SgmlReader[CP/OL].[2010-3-14].http://wiki.developer.mindtouch.com/SgmlReader,2012-10-11.
[3] 张华平.ICTCLAS[CP/OL].[2012-7-3].http://ictclas.org,2012-10-11.
[4] 胡可云.数据挖掘理论与应用[M].北京:清华大学出版社,2008.
[5] 董婷.支持向量机分类算法在MATLAB环境下的实现[J].榆林学院学报,2008,18(4):94-96.
[6] 孙强,李建华,李生红.基于 Python的文本分类系统开发研究[J].计算机应用与软件,2011,28(3):13-14.
[7] 邓乃扬,田英杰.数据挖掘中的新方法——支持向量机[M].北京:科学出版社,2004.
[8] 陈叶旺,余金山.一种改进的朴素贝叶斯文本分类方法[J].华侨大学学报,2011,32(4):401-404.
[9] 段莹.支持向量机在文本分类中的应用[J].计算机与数字工程,2012,40(7):87-88.
Efficiency Analysis of Naive Bayes Algorithm and SVM Algorithm in Web Text Classification
ZHAN Yi
(School of Tourism and Culture Industry,Chengdu University,Chengdu 610106,China)
A web classification system is built to analyze and compare the efficiency and scope of Naive Bayes algorithm and SVM algorithm in web text classification.The classified Web pages are used for training sets.The Web text classifier is built by using classification algorithm.The performance of both algorithms in the web text classification is evaluated by the web test set,which provides some reference for selection of web text classification algorithms.
web classification system;Naive Bayes algorithm;SVM algorithm;efficiency analysis
TP391.1
A
1004-5422(2013)01-0050-04
2012-11-14.
詹 毅(1983—),男,硕士,从事计算机模拟与仿真技术研究.
book=46,ebook=46
