维吾尔语词法中音变现象的自动还原模型
2012-10-15麦热哈巴艾力姜文斌吐尔根依布拉音
麦热哈巴·艾力,姜文斌,吐尔根·依布拉音
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐830046;2.中国科学院 计算技术研究所,北京100190)
1 引言
维吾尔语属于阿尔泰语系突厥语族,是典型的黏着语,其特点是词干可接多层(可以是零层)词缀,呈现出丰富而复杂的形态变化。维吾尔语词干在接词缀时按维吾尔语语音和谐规律有些语音会发生弱化、脱落、增音等现象,例如,mektep(学校),mektipim(我的学校),mektipidin(从他的学校),mektipiningki(是他的学校的)等,都是同一个词干mektep(学校)后分别接_im(第一人称单数)、_i(第三人称单数)+din(从格)、_i+ning(领属格)+ki(替代人(物))等词缀而来,其形态发生变化的同时词干中最后一个元音e弱化成i。本文中,我们把这三种情况(弱化、脱落、增音)统称为音变现象。维吾尔语词缀类型、数目都较多,例如,名词词缀达到50个,而动词词缀的数量最多,远多于200个,这么多数量的词缀以及词缀的多层连接使得维吾尔语的一个词呈现出很多不同的形式,这给计算机处理维吾尔语带来很多不便,所以词干与词缀的切分是非常必要的。
词干、词缀的切分又叫做词干提取,是词干、词缀连接的逆过程。所以在词缀连接过程中所发生的音变现象需要找出它的原始形式即还原。可以说还原是提高词干提取正确率的重要条件。目前为止,对于维吾尔语音变现象还原方法的研究可以分为基于规则的方法[1-3]和基于统计的方法[4-6]两种。基于规则的方法中研究者主要以词干、词缀连接过程中所遵守的语音和谐规律作为还原的依据,但还原过程并不是生成过程的简单逆过程,有些语音的变化依赖的条件较复杂,还原时会有一定的困难继而容易产生歧义。虽然研究者利用创建词干库的方法试图进行消歧,但是词干库的覆盖面以及还原后所产生的多个候选同时存在于词干库等情况一直成为此方法的弊端;还有些研究者利用统计方法来展开研究,虽然较好的克服了以上问题,但是对于多种音变现象同时出现、变化复杂等情况还是未能得到很好的解决。
针对以上问题,本文提出维吾尔语音变现象的自动还原模型。此模型的思路是,维吾尔语词被看作是所包含语音的线性序列,先假设音变现象会发生在每个语音上,那么构成一个词的语音序列中每一个语音就可以有n(0≤n≤31)个原形候选,找到它们的原形就类似于词序列自动标注,再利用序列标注的方法即可解决还原问题。
2 维吾尔语变音显现以及还原问题
维吾尔语词缀种类多、数目多,而且可以多层缀接,在缀接过程中由于语音和谐规律某些语音会发生弱化、增音、脱落等音变现象,构成同一个词干的多种不同形态。例如:
(1)弱化现象。
a)元音弱化:qelem(笔)+im(第一人称单数)=qelimim(我的笔) (其中元音e弱化成i)
b)辅音弱化。kel(来)+ip+idim(系助动词,第一人称过去式)=këliwidim(我一来…)(其中辅音p弱化成w)
(2)增音。arzu(愿望)+um(第一人称单数)=arzuyum(我的愿望) (词干后增加了辅音y)
(3)脱落音。
burun(鼻子)+i(第三人称单数)=burni(他的鼻子)(词干中第二个元音u被脱落)
kel(拿)+ip(p型副动词)+tu(为转述式,过去时,第三人称单(复)数)=keptu(他来了)(l和i被脱落)
(4)有些情况下多种现象同时发生。
chal(弹)+ip +tu +iken(系助动词)=chëptiken(听说他弹了)(a弱化成ë,l,第一个i,u被脱落)
词干提取是以上生成过程的逆过程。由于音变现象的存在,在对维吾尔语进行词干提取时往往会发生一些歧义以及更复杂的情况。可归纳为以下几种情况。
(1)词干的还原带来的歧义

(2)词缀带来的歧义

(3)需还原多个语音,往往出现在合成词中,切分时需还原成两个词。

从以上分析可以看出,还原操作不是语音和谐规律的简单逆向应用,使用规则有时很难消除这些现象;统计方法虽然可以弥补规则方法的缺点,但是对于复杂变化现象还是表现不佳。
3 维吾尔语变音现象的自动还原模型
首先确定本文中使用的几个术语。
术语1 词的当前形式。是指在句子中出现的,已有n(0≤n≤lenw)个语音发生了变化的词,本文用wcur来表示;
术语2 词的原始形式。指词中所有语音都为原始形式即未发生变化的词,本文用worg来表示;
例如,“我的本子”词的当前形式和原始形式分别为:wcur=deptirim worg=depterim。
针对还原操作所存在的以上问题,我们提出了这样一个模型:把维吾尔语词看成它所包含语音的线性序列,先假设音变现象会发生在每个语音上,那么词中每个语音就会有n(0≤n≤31)个原形候选。如果我们能够事先知道每一个语音可能的原形候选(可包括自己),那么对当前词的原操相当于从这个候选中找到最优的一个。这个过程类似于自动标注问题,而从候选中找到最优的一个就相当于它的解码过程,则完全可以利用序列标注的方法解决此问题。
还原模型中最重要的环节是枚举出每个语音相应的原形候选,这也是模型的重点和难点,我们从最短编辑距离算法得到了启发,从而提出了词内字母对齐的算法。通过此方法即可得到每个语音可能的原形候选,那么对给定的一个词进行还原相当于从每个语音原形的候选中找出“最为合理”的一个,而“最为合理”可以用概率值对其计算出来。
3.1 词内字母对齐算法
词内字母对齐算法的目的是找出词内每一个语音所有可能的原形候选。为了描述方便,以下我们将语音替换成它的文字形式——字母。
假设一个词的两种形式分别为wcur、worg,词内字母的对齐原则为:以当前词中字母为准,依次对齐wcur、worg中的字母,直到将wcur、worg中的所有字母互相对齐完为止,对齐的结果为一对一、一对多、一对空。其中“一对多”中“多”方的长度我们控制为2,这个值是经验值,可根据情况调整。字母对齐情况可由表1所示。
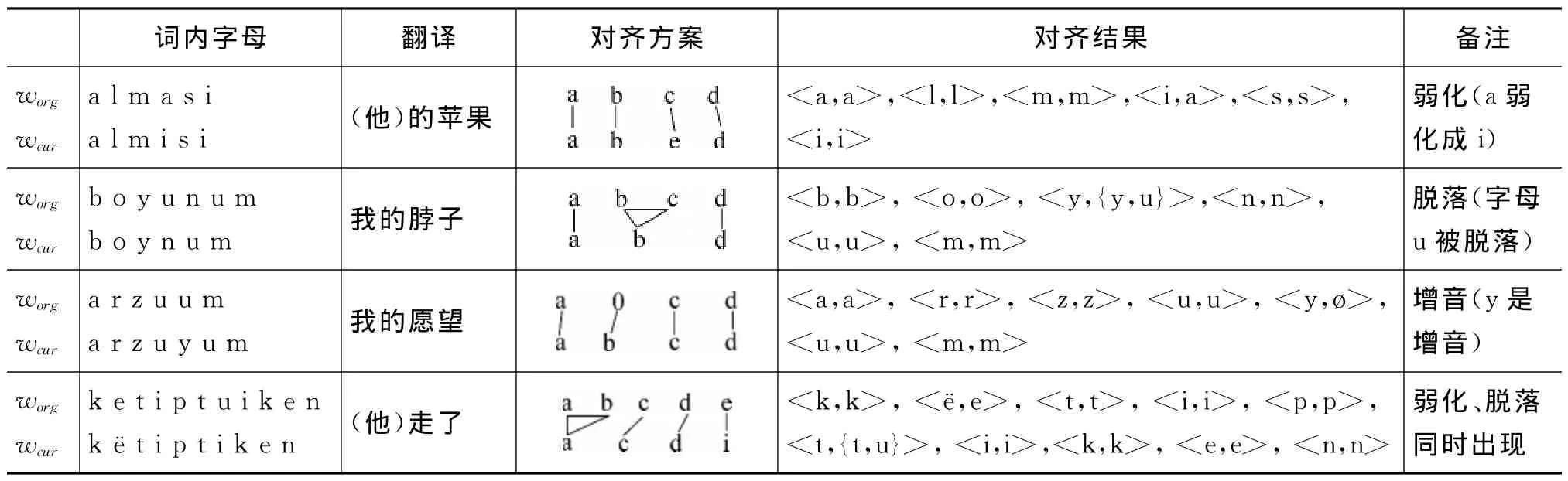
表1 词内字母对齐情况
利用动态规划算法来实现了词内字母对齐模块,其算法如下:


算法中主要匹配工作是由maxMatch函数完成,其功能是依次比较wcur,worg中的每个字母,最大程度地匹配,尽量找出词中发生音变的字母对,并将这些配对项压入栈。栈中每个项为一个字母当前形式与对应的原形。
3.2 特征模版的选择以及最大熵训练
找出发生音变字母对后,方可利用机器学习的方法归纳出维吾尔语中每个字母可能的原形候选。
我们利用最大熵模型对训练语料进行了训练。训练语料库中包括每个词的当前形式和人工还原的原始形式。特征模版的选择上,为了不失一般性,我们选择了当前字母以及前后两个字母变化的情况,如表2所示(下页)。
3.3 自动还原过程的解码
对给定的一个词进行还原的操作即成为解码过程,其实质就是从原形候选中选“最可能”的一个作为原形,即:待还原的词所包含的字母互相被隔开,将其变成字母线性序列,根据训练得到的知识枚举出每个字母可能的原形候选,再利用动态规划算法找出各后选中其概率值之积为大者,而概率值就是最大熵训练的结果。
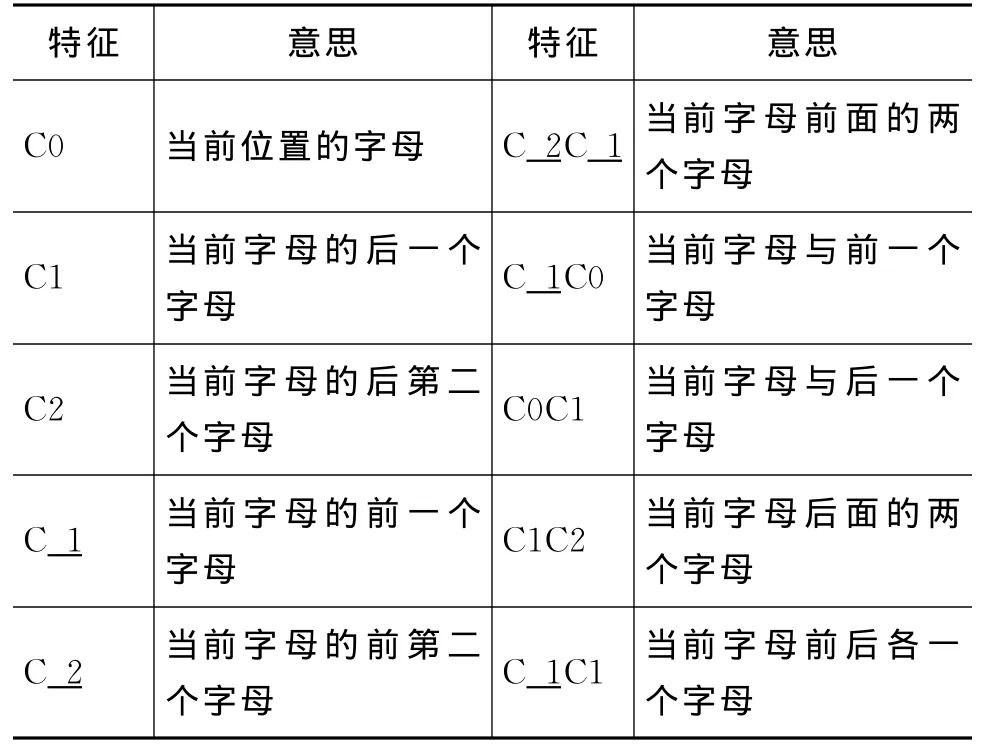
表2 选择原始形式中字母位置的特征模板
4 实验及分析
我们在新疆多语种信息技术重点实验室手工标注的《维吾尔语百万词词法分析语料库》上进行试验。此语料库收集了维吾尔语文小说《故乡3》全书、农业杂志《棉花技术》、《小麦》的部分内容,《党的17大报告》、《知识——力量》、《新疆社科》等报告、杂志的部分内容,包括67 114个完整的句子,牵扯到文学、科技、文献等多个领域。语料被手工进行词干与词缀切分、还原并进行了三级标注。我们随机抽取各5%的句子分别用做开发集和测试集,剩余的用做训练集。
我们开发了一套维吾尔语词法分析器,其中引入了本文所介绍的还原模块,为了全面地描述还原模型的功能,我们设计了多种实验,从不同的侧面进行了分析讨论。
4.1 实验设计
实验1 还原模型对维吾尔语词法分析器中的作用
此实验的目的是测试还原模块对我们开发的词法分析器结果的影响。为了测试这一点,在词法分析器中我们对开发集分别进行了两次词法分析操作,第一次打开了自动还原模块,其结果记为w1;第二次关闭自动还原模块,其结果记为w2;词法分析器的功能包括词的还原,词干、词缀切分以及标注,而此实验中我们暂时忽略了分析器的标注功能。评价自动词法分析的结果时我们规定如果词干、词缀被正确切分且词缀与词缀互相正确切分时算是正确。两次实验的结果为图1所示。
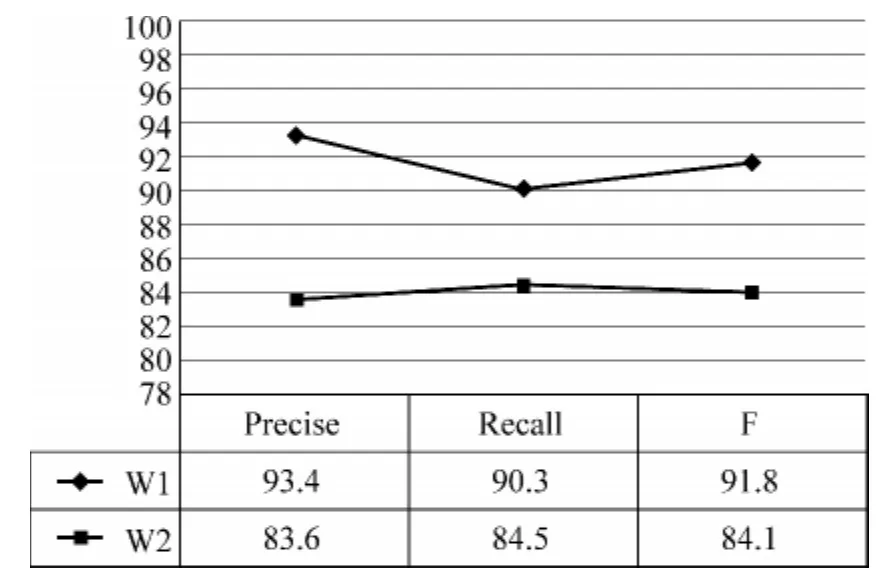
图1 自动还原模块对词法分析器结果的应用
测试结果表明,系统中加自动还原模块后其F值达到91.8%,比不加此模块的F值84.1%提高了7.7%;准确率和召回率也都有相应的提高,说明自动还原模块在词干提取操作中起到了积极的作用。
实验2 测试还原模块对维吾尔语不同词类还原的影响
维吾尔语词类共有12种,其中动词、名词、形容词、代词和副词的出现频率高、词缀类型较多,音变现象相对多发生。此实验的目的为测试自动还原模块对这些词类词法分析结果的影响。我们在开发集上分别做了两个实验:关闭自动还原模型和打开自动还原模型。这次把测试的重点放在了各词类中被提取词干的正确性,而忽略了词缀。其结果如表3所示。
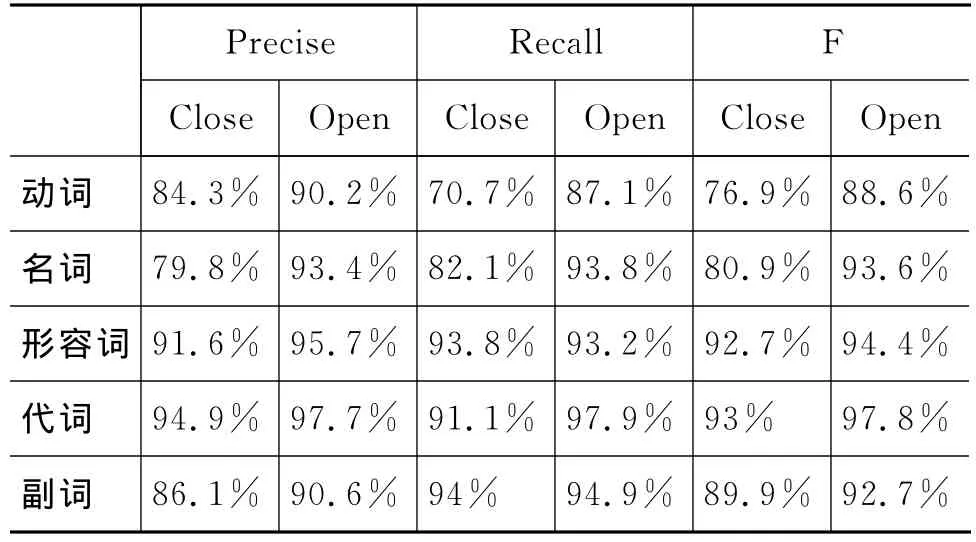
表3 还原模块对不同词类词干还原的影响
表中可以看出,词法分析其中打开自动还原模型后,各词类词干提取的正确率都有了向上走的趋势,而且有些词类这个趋势的幅度较大,例如,名词、动词。同时,动词词干提取的F值为88.6%,属于其他词类中最低的。这是因为维吾尔语动词词缀数目多,连接到词干后的音变现象最复杂,合成词的还原也是处理较难的一个问题。
实验3 测试语料规模对还原模块的影响
此实验的目的是测试语料扩建会否提高还原模块的性能。为此,我们固定开发集和测试集不变,而从训练集中每次提取不同规模的子集以训练还原模块,并考察该系统在测试集上的表现。整个训练集含67 114条句子,我们从中取出50%、20%、10%、6%、4%及2%等不同规模的子集,并按照由小到大的次序训练还原模块,并对测试集进行词法分析。与实验1相似,这次的评价标准仍然是词干和词缀的正确切分。图2为系统性能随训练数据增加的变化曲线。
通过图2所示的训练集规模—系统性能曲线我们发现,随着训练集语句数量的增加,系统性能有提高的趋势。这在训练语料规模较小的时候尤其明显,例如,训练集从1 344句扩大到4 028句时,词干提取的F值从80%上升到85%。随着语料规模的继续扩大,系统性能的提升幅度趋于缓和,例如,训练集从33 550句扩大到60 402句时,F值从91.3%提升到91.9%。这带给我们两方面的启示,其一,通过进一步扩建语料库以提升性能仍然是有意义的;其二,语料规模继续增加到一定程度后,系统通过语料扩建提升性能的性价比会越来越低,此时,可以研究用语言学知识来增强模型。这也是我们今后在改善模型性能时需考虑的方面。
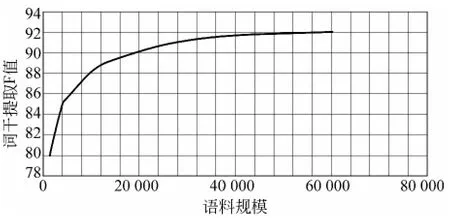
图2 训练集规模—系统性能曲线
4.2 分析
我们对于还原模块失效的词进行了分析。我们随即抽了904个被还原的词,从中人工检查后找出101个被错误还原的词,对其进行错误分类统计的结果为表4所示。

表4 被错误还原的种类
经过分析发现错误主要出现在:(1)经常被还原的字母,例如:ë,i等;(2)形态比较接近;(3)形态变化复杂的词。出现此错误的原因可能:(1)模型的适应能力还不够强,所学到的知识不够全面;(2)所使用的特征模板没能更好地体现维吾尔语语音和谐规律的特点。针对这个问题,我们可采取增大训练语料的规模以及优化特征模版等方法,一边给系统提供更丰富的发生音变现象的上下文,一边将语音和谐规律的规则引入到特征模板上。我们将此问题作为优化系统的任务之中。
5 总结与展望
本文为维吾尔语音变现象的还原建立了一种模型,此模型不再单独地考虑音变语音的规则以及其发生的条件,而是将音变现象泛化,从而将还原问题转化为类似于序列自动标注问题,再利用成熟的标注方法解决了还原问题并在实际试验中得到了较好的效果。
然而,就像上面的分析,当前模型还有一些不足之处需一步改进。例如,词内字母对齐算法。目前算法实现起来较复杂,有些经验值还需多做实验重新制定,同时在简化算法复杂度方面也值得进一步研究。再者,我们可以适当地扩建语料,以及将语料内容多样化,从而使得模型适应多种环境。此外,实验2提醒我们维吾尔语动词的还原有待于进一步研究。如何利用语言学规则来提高是我们下一步研究的内容。同时,可喜的是,此还原模型不依赖于任何规则,与语言无关。通过此特性,我们完全有理由考虑将其扩展到其他有变化形式的语言。这也是我们下一步研究的另一个方面。表5是此系统还原的结果一览。

表5 系统还原的词举例
[1]早克热·卡德尔,艾山·吾买尔,吐尔根·依布拉音,等.维吾尔语名词构形词缀有限状态自动机的构造[J].中文信息学报,2009,23(6):116-121.
[2]米热古丽·艾力,米吉提·阿不力米提,艾斯卡尔·艾木都拉.基于词法分析的维吾尔语元音弱化算法研究[J].中文信息学报,2008,22(4):43-47.
[3]古丽拉·阿东别克,米吉提·阿布力米提.维吾尔语词切分方法初探 [J].中文信息学报.2004,18(6):61-66.
[4]Aishan Wumaier,Tuergen Yibulayin,Zaokere Kadeer.Shengwei Tian Conditional Random Fields Combined FSM Stemming Method for Uyghur Proceeding[C]//2nd IEEE International Confrence on Computer and information Technology(ICCSIT 2009 )2009.8:295-299.
[5]Aisha Batuer,Maosong Sun.A statistical method for Uyghur tokenization[C]//International Conference on Natural Language Processing and Knowledge Engineering.2009.9 :1-5.
[6]M.Ablimit,M.Eli,T.Kawahara.Partly supervised Uyghur morpheme segmentation[C]//Proceedings of Oriental-COSOCODA Workshop.2008:71-76.
[7]Lawrence.R.Rabiner.A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition[C]//Proceedings of IEEE,1989:257-286.
[8]McCallum,A.,Freitag,D.,Pereira,F.Maximum entropy Markov models for information extraction and segmentation[C]//Proceedings of ICML,2000:591-598.
[9]Hwee Tou Ng,Jin Kiat Low.Chinese part-of-speech tagging:One-at-a-time or all-at-once?Wordbased or character-based? [C]//Proceedings of EMNLP,2004.
[10]Wenbin Jiang,Liang Huang,Yajuan Lv,et al.A cascaded linear model for joint Chinese word segmentation and part-of-speech tagging [C]//Proceedings of the 46th ACL,2008.
[11]阿依克孜·卡德尔,开沙尔·卡德尔,吐尔根·依布拉音.面向自然语言信息处理的维吾尔语名词形态分析研究[J].中文信息学报,2006,20(3):43-48.
[12]阿孜古丽·夏力甫.维吾尔语动词附加语素的复杂特征研究[J].中文信息学报,2008,22(3):105-109.
[13]力提甫·托乎提.电脑处理维吾尔语语音和谐律的可能性[J].中央民族大学学报,2004,(5):108-113.
[14]玛依热·依布拉音,米吉提·阿不里米提,艾斯卡尔·艾木都拉.基于最小编辑距离的维语词语检错与纠错研究[J].中文信息学报.2008,22(3):110-114.
[15]田生伟,吐尔根·依布拉音,禹龙.EBMT中高效的维吾尔语单词散列表构造算法[J].中文信息学报,2009,23(4):124-128.
[16]阿孜古丽·夏力甫.论维吾尔语SUBS+NP结构的形式化描述[J].中文信息学报,2011,25(2):117-121.
