复杂网络在新闻网页关键词提取中的应用
2012-09-21唐俊
唐俊
(西南交通大学电气工程学院,四川成都610031)
复杂网络在新闻网页关键词提取中的应用
唐俊
(西南交通大学电气工程学院,四川成都610031)
通过分析新闻网页文档的特征,引入节点权重、有向网络加权聚类系数、中心介数等特征量,并结合传统关键词提取算法的一些优点及网页文档的部分特征,提出了一种改进的基于加权复杂网络的新闻网页关键词提取算法,并通过实验证实了该算法的正确性.
关键词自动提取;新闻网页关键词;复杂网络;节点权重
随着互联网的快速发展,网页信息量以惊人的速度爆发式地增长.面对海量新闻,信息技术如何辅助人们快速了解新闻主要内容,节省浏览时间,已经成为一个关注的热点.新闻关键词的自动提取,为该问题提供了一个有效的解决方案,它也是新闻文档的自动分类、舆论热点的自动发现、新闻网站的自动聚类、个性化的智能检索等的基础.现有比较成熟的关键词提取技术主要有:基于词频统计的方法[1]、基于机器学习的方法[2]、基于语言学的分析方法[3],其分别主要从词语的出现频率、词语的训练集、词语的位置与语义等方面进行分析,都存在不同程度的缺陷.近年来,随着复杂网络的快速发展,基于复杂网络的关键词提取算法被众多学者所研究,并取得了一定的成果[4-8],这些成果多从单个角度分析了节点在局部小世界,或者节点在整个网络中的影响,而忽视了个体与总体的辩证统一关系,并且忽视了吸收传统关键词提取方法的一些优点,在算法上也存在一些缺陷.本文通过分析新闻网页文档的特征,引入节点权重、有向网络加权聚类系数、中心介数等特征量,并结合词性、词语在文档中的位置等信息,提出了一种改进的基于有向加权复杂网络的新闻网页关键词自动提取算法.
1 复杂网络相关理论
经科学论证,发现大多数真实的网络都表现为复杂网络.目前,表征复杂网络模型的主要统计参量有:节点的度、度分布、节点度的相关性、聚类系数、平均路径长度、介数、最大连通子图、模块性和团体等,通过对统计参量在网页文档中的物理含义的理解,本文选择对节点的加权度、聚类系数、节点权重、中心介数进行综合利用,并改进了基于加权复杂网络的新闻网页关键词自动提取算法.
定义1:设节点集合V={v1,v2,…,vn},其中n为网络中节点的个数,有向边的集合E={(vi,vj)|vi,vj∈V},边的权值集合We= {weij|(vi,vj)∈E},故有向加权网络G可以表示为G={V,Wv,E,We}.
定义2:节点vi的加权度定义为该节点连接边的权值和,即ij∈
定义3:节点的聚类系数Ci改进定义为节点vi的邻节点vj组成的集合中彼此实际有向连边的权值和∑wejk与概率存在的最大有向连边数A|vj|2乘σ上所有连边权值的平均值A∑LLwekm/|E|的比值,即特殊的,当为无权无向图时,所有连边的权值平均值A∑LLwekm/|E|退化为1,权值和∑wejk退化为邻节点连边数,即该改进定义式包含了一般复杂网络的聚类系数的定义.通过对原聚类系数公式的改进,更能体现有向加权网络中边的有向性和边的权重(边的权重在网页文档中,即相同词语连边的多次出现).
定义4:节点的权值定义为该节点在节点集合V={v1,v2,…,vn}中的相对重要程度.
节点权值的定义类比边的权值定义得到,定义它的用意是表征节点的一些属性,区别不同节点的重要程度,引入到新闻网页复杂网络中的主要意图有:第1,区别网页标题、核心提示等分句中出现的词语节点与普通正文中出现的词语节点彼此间不同程度的重要性;第2,区别不同词性的词语以及常用词等构成的节点在新闻网页复杂网络中的重要程度.通过该参量的引入可以结合传统关键词抽取算法的一些优点,希望能达到更准确的关键词抽取结果.
2 模型构建与抽取算法
复杂网络是复杂系统研究的一个重要手段,学者们从各个领域进行了复杂网络建模、描述与实证,虽然应用领域不同,但思路基本一致,总结这些模型可以得到复杂网络一般建模方法如图1所示.
不难发现,在新闻网页文档中,词是基本的单元,不同词以不同的词性和不同的顺序连接起来便构成了一篇完整的新闻文章,也正是词的不同组合形式传达了形形色色的新闻信息,表达了人们生活的点点滴滴.本文将网页中的词映射为复杂网络中的节点,将词与词之间有序联系映射为节点的有向边,从而就将1个网页文本转化成了1个网络.文本中越重要的词,也就越有可能是关键词,映射到复杂网络也就是寻求重要的节点,在网络拓扑结构中,重要的节点分为以下2类.

1)加权度较大、聚类系数较高的节点.加权度越大,说明与其连接的节点越多,其在网络中就越重要,映射到新闻网页中即该词出现的频率越高,这也是文献[1]基于词频统计方法主要的研究对象.聚类系数越高,说明该节点的邻节点组成的集合中彼此实际的连边数越多,说明邻节点彼此之间联系越紧密,局部范围内聚集性越强,映射到新闻网页中即该词的邻居节点对应的词语之间联系越紧密,可能体现了原文的某个小主题,而该单词则是该主题的主题词.
2)介数高的节点.介数的定义在前文已经提及,它指的是网络中通过该节点最短路径的数目.显然,介数越高,说明通过该介数的最短路径越多,一定程度上影响着全文的平均最短路径,因此该节点越重要.
综合考虑前面提及的复杂网络模型的主要统计参量及其物理意义,本文选择复杂网络中的聚类系数和介数作为网络统计参量,但网页文档作为一个特殊复杂网络有其本身的一些特点,在传统复杂网络中并不能很好得以体现.例如:传统复杂网络中,网络的权值代表该边的重要程度,其最短路径为连通2个节点边的权值和的最小值.在实际的文档网络中边的权值代表2个词的连接次数,间接代表着节点的重要性,因此其最短路径显然不能以权值和来衡量,事实上,恰恰相反的是权值越大距离越近,因此,在最短路径的计算中需要改进为权值倒数的和才能正确体现文档网络的特征;再如,传统复杂网络初始对各个节点视为同等重要,但在现实的网页文档中,有些节点显然更重要,如网页标题、相关主题链接、重要的网页标记如网易网页标记<description>等中出现的词,另外,词语的词性显然在不同程度上体现了词语的重要性,这在传统分析方法中也得到了较好的应用,对这些节点的特点本文引入节点权重予以描述,初始时,充分利用已知信息对不同节点赋予不同权值.结合网页文档的这些特征,本文提出了基于有向加权复杂网络的新闻网页关键词自动提取算法如下:
输入待处理的本地网页文档存储路径;
输出网页文档的K个关键词;
Step 1解析网页标题、正文等相关信息.各个门户网站的网页格式不尽一致,对不同的门户网站分析其网页模板形式,再通过广泛应用的HTMLParser包或正则表达式即可解析获取网页正文、标题、重要标记等信息;
Step 2对网页文档进行预处理.通过正则表达式判断原文是否含有中文字符,如果有则认为是中文文档,并采用中文分词程序将Step 1解析的结果进行分词,对去停用词等预处理后的分词结果,按出现的位置(如标题及各重要标记)和词性对词节点赋予初始权值wv;
Step 3构建有向加权网络.将上一步得到的词语进行数字编码,将编码结果作为节点,同时建立索引表,而网络的边采用文献[4]中的距离2作为词语关联关系的距离,即对每个句子循环判断,如果一个词后续距离k=1或k=2的位置上有词语,则建立权重为1的有向边,边的方向由前续节点指向后续节点,如果相同词语有相同方向的连接,则对网络权重加1;
Step 4计算各个节点加权度及聚类系数.按前述节点加权度及聚类系数的定义计算各节点的值,并对其进行归一化,再进行降序排列,获得加权度及聚类系数综合值相对较高的前N个节点,综合特征值的计算式为:
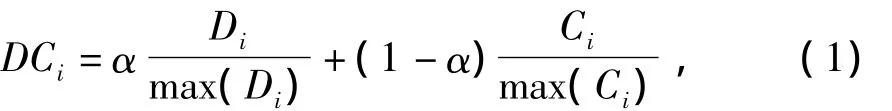
其中,α∈(0,1),本文α取0.5.
Step 5计算中心介数.上一步获得的N个节点视为中心网络节点,寻找中心网络两两节点之间的最短路径,统计计算被经过所有节点的归一化中心介数B*i;
Step 6生成网页的K个关键词:

其中,β∈(0,1),wvi∈(0,1),本文β取0.5.式(2)中DCi为Step 4获得的各个节点的加权度与聚类系数综合值,wvi为Step 2中求得的各节点权重.由该公式计算各个节点的最终重要程度值,并进行降序排列,取前K个节点序号查找索引表获得关键词.
3 数据获取与仿真分析
本文数据来源于国内外著名的门户网站新闻模块,通过构建基于Heritrix的垂直搜索引擎,直接获取搜狐、网易、腾讯网的新闻网页.这些网站的网页都以模块化形式产生,能友好支持专业爬虫工具,并基本涵盖了重要的有价值的新闻.实验首先基于Heritrix-1.14.0构建网络爬虫,从指定的网站上爬取网页信息保存到本地构成网页集;然后分析各个网站新闻模块的特点,结合HTMLParser和正则表达式分别提取出各个网页的新闻标题、新闻内容等,为下一步对不同节点赋予节点权重做准备.
解析各部分内容后,使用Java版Ictclas对各个网页进行分词、标注词性.表1给出了对一则题为《交通银行发布声明称用户资料外泄属谣言》的网页标题的分词结果.

表1 网页标题的分词结果
最后,建立各个网页的复杂网络模型,计算模型中各参数值,降序排列计算所得综合值,以前K个词作为网页关键词.表2给出了对表1所对应网页新闻进行建模、分析、计算所得综合值降序排列的部分结果.从处理结果易知,以这些节点作为关键词已基本能代表原新闻的大意,说明了本算法有一定的实用性.

表2 部分关键词排序结果截图
不失一般性,本文选择爬取的50篇新闻进行分析,引入召回率、准确率等特征量作为评价.

其中EKi为第i篇新闻自动抽取的关键词集合,Ti为第i篇新闻的标题,N为分析的新闻篇数(实验中为50),KEYi为第i篇新闻的核心词语.由于Web信息的特殊性,核心词语并没有在新闻中给出,这给自动提取关键词的客观评价带来了困难,本实验中新闻的核心词语是对新闻标题或者网站给出的核心提示进行分词,去除介词、连词等词性后得到的词语,通过实验计算获得的召回率和准确率数据如图2.

由图2可知,随着抽取关键词个数的不断增加,候选词不断增多,导致准确率达到一定高度后反倒降低,而随着候选词的增加,正确的关键词越来越多,召回率持续上升.因此,抽取关键词的个数有着一定的范围,对不同的文档这个值有一定的波动.对由表1对应的网页新闻所获得的召回率和准确率数据存在一定的缺陷,准确率曲线前4个点都是100%,反映到关键词上即“银行”、“交通”、“称”、“用户”等节点都是正确反映原文内容的节点,而后3个图反映的是一般情况,即一般情况下排名第1的节点并不一定在新闻标题中,图中显示一般为第4~7个离散点的值才为峰值,即准确率在抽词数为4~7个时才达到最高.由召回率曲线趋势可以发现表1对应的网页新闻的召回率存在一定的跳跃性,而后3个图变化的趋势显然要光滑,这说明随着文档数的增加,单个节点对召回率的影响要明显下降,从而呈现出渐变的特性.易知对50篇新闻的处理结果更具有一般性,对该处理结果单独分析,见图3.

由图3可以清楚地获知该50篇新闻在抽取4个关键词时准确率最高,最高值达到近70%,并且当抽取10~15个节点时召回率达到70%~80%.由此可以印证由本文算法自动抽取的关键词基本能反映原文大意,而且由于日常习语、网络用词的存在,自动抽取关键词的准确率在客观上应该会略高于实验数据反映的情况,如实验数据中的词语“西南交通大学”与“西南交大”的差异显然会降低新闻的召回率和准确率的统计数据,但这些关键词却能体现原文大意,被人所识别.

为了进一步验证本算法的效果,本文分别采用TF方法(term frequency,词频权重计算方法)和文献[5]的方法对相同的50篇新闻进行了对比实验,实验结果如图4所示.
TF方法的主要思想是利用词在文档中出现的频率来衡量词对文档的重要程度,改进的TF方法在考虑局部范围内词对文档的重要程度的基础上,还考虑了词在全局范围内的影响.而文献[5]利用度和聚集系数对文档进行了关键词的抽取.本文在综合考虑了度、聚集系数、介数等基础上,还结合了部分语言学的分析方法,通过引入节点权重,将词性、节点位置等信息融入,通过图4对比可以看出,本文方法较前2种方法有一定的提高.
4 结语
理论分析与实验结果表明本文算法是正确、有效的,通过该算法抽取的关键词基本能体现原新闻大意,从而为进一步的新闻去重、新闻聚类、辨识不良网站等奠定了前提与基础.另外,由于分词程序的一些缺陷给实验结果带来了一定的影响,在进一步研究中将予以改进.在理论分析的基础上,本文还通过Java的数据结构实现了复杂网络图的存储及各个特征参数的计算,为复杂网络进一步在网络信息应用研究中提供了实现工具,这也将为本文算法的应用提供更广阔的空间.
[1]尹倩,胡学钢,谢飞,等.基于密度聚类模式的中文新闻网页关键词提取[J].广西师范大学学报:自然科学版,2009,27(1):201-204.
[2]IKONOMAKIS M,KOTSIANTIS S,TAMPAKAS V.Text classification usingmachinelearningtechniques[J].WSEAS Transactions on Computers,2005,4(8):966-974.
[3]BO Jin,TENG Hong-fei,SHI Yan-jun,et al.Chinese patent mining based on sememe statistics and key-phrase extraction[C]//Proc of ADMA Conference.China:Harbin,2007:516–523.
[4]马力,焦李成,白琳,等.基于小世界模型的复合关键词提取方法研究[J].中文信息学报,2009,23(3):122-128.
[5]赵鹏,蔡庆生,王清毅,等.一种基于复杂网络特征的中文文档关键词抽取算法[J].模式识别与人工智能,2007,20(6):827-831.
[6]MATSUO Y,OHSAWA Y,ISHIZUKA M.Keyword:extracting keywords in a document as a small world[J].Lecture Notes in Computer Science,2001,2226:271-281.
[7]CANCHO R F I,SOLE R V.The small world of human language[C]//Proceedings of The Royal Society of London.London,2001,268:2261-2265.
[8]ZHANG K,XU H,TANG J,et al.Keyword extraction using support vector machine[C]//Proceedings of the Seventh International Conference on Web-Age information Management(WAIM2006).Hong Kong,2006:85-96.
(责任编辑庄红林)
Application of Complex Networks to Keyword Extraction of News Web Pages
TANG Jun
(School of Electrical Engineering,Southwest Jiaotong University,Chengdu 610031,China)
The characteristics of the news web pages documents and the node weights are analyzed,the clustering coefficient of the directed network weight and the center section are introduced.With absorbing the advantages of traditional algorithms,an improved algorithm for the automatic extraction of news keywords based on the weighted complex networks is proposed,and the experiment has proved that this algorithm is correct.
automatic extraction of news keywords;news web page keywords;complex networks;node weights
TP 391
A
1672-8513(2012)04-0305-04
10.3969/j.issn.1672-8513.2012.04.019
2012-03-29.
唐俊(1986-),男,硕士研究生.主要研究方向:网络信息技术及复杂网络.
