Boosting算法对卵巢癌代谢组数据的应用研究*
2012-09-07武振宇贾慧珣
武振宇 贾慧珣 朱 骥△
Boosting算法对卵巢癌代谢组数据的应用研究*
武振宇1贾慧珣2朱 骥2△
目的 应用Boosting算法建立模型,对卵巢癌和非卵巢癌(卵巢囊肿和子宫肌瘤)患者的尿液代谢组数据进行分析,提取出具有生物学意义的代谢组分,为卵巢癌的早期诊断及疾病机理提供线索。方法 将决策树与Boosting算法相结合,对患者的临床样品代谢组数据进行分析,并对代谢组分进行逐步筛选,得到鉴别卵巢癌患者的重要代谢组分。结果 由Boosting模型得到的排序靠前的10个差异代谢组分,能够将卵巢癌与对照组患者进行较好的判别分类,其ROC曲线下面积达到了0.944。结论 Boosting模型可以有效地应用于卵巢癌代谢组数据,在保证较高的分类正确率的同时可以得到对分类起作用的重要的代谢组分。
代谢组学 Boosting 特征筛选
*:国家青年科学基金项目资助(81001286);“中央高校基本科研业务费专项资金”资助
1.复旦大学公共卫生学院卫生统计教研室(200032)
2.复旦大学附属肿瘤医院临床资料统计室
△通讯作者:朱骥
卵巢癌是妇科常见的恶性肿瘤之一,大约有1.4%的女性会患病,其病死率很高,对妇女生命造成严重威胁,国内外临床资料统计显示其五年生存率仅25% ~30%。如果发现及时,90%的病人都能存活;若发现晚,癌细胞扩散到卵巢,存活率就低于30%。所以早期诊断治疗对于卵巢癌患者提高5年生存率具有十分重要的意义。
代谢组学研究研究特点是采用高通量检测技术,对生物体代谢情况进行整体的测量。图1是一种代谢产物的总离子色谱图和相应的量化表,上半部分是代谢组研究中检测得到的代谢产物离子色谱图,每一个峰代表某一保留时间上的一组代谢产物。下半部分是由色谱图得到的代谢产物的量化结果。每一列代表一个观测对象,每一行代表一个保留时间上测得的代谢产物。

图1 代谢产物的总离子色谱图和相应的量化表
利用代谢物(如尿液、血液)进行疾病的诊断,方法简便、无创、患者易于接受。生物体的代谢物可能包含几千甚至几万个生物特征的信息,但限于研究成本,样本例数通常只有数十例。因此具有生物学意义的特征筛选对于高维代谢组学数据分析来说显得尤为重要。Boosting方法作为集成算法中的一员,一直以其优异的性能吸引着广大研究者。本研究的目的是对卵巢癌患者的代谢产物(尿液)的分析,其主要目的是筛选出能够区分卵巢癌病人与非卵巢癌病人的生物标志物以及对样本进行分类,通过比较正常和疾病状态下代谢产物谱的差异,研究疾病的发生机理,为卵巢癌的临床早期诊断、治疗以及预后判断提供重要依据和支持。
资料与方法
1.资料来源
本资料来源于2009年7月至2009年12月在哈尔滨医科大学附属肿瘤医院收集37例首次发现并经病理确诊为卵巢癌患者(病例组)的尿样(10ml),同时收集患有卵巢囊肿和子宫肌瘤患者(对照组)共51例的尿样。将所有尿样(共88例)进行预处理后,应用高效液质联用仪进行分析,得到23447个代谢组分。
2.研究目的和方法
(1)研究目的
①卵巢癌分类模型的建立,即采用机器学习的方法从已知的数据集中抽象出一个分类模型,使该模型能够很好地拟合当前分类结果并能解释其意义,对疾病的预测具有指导意义。② 对卵巢癌患者代谢产物的组分进行分析,即从患者尿液分离出的23447个代谢组分中筛选出对疾病分类起重要作用的重要组分,为卵巢癌的研究打下基础,使模型能够对临床的诊断、治疗及预后等实践工作进行指导并具有解释意义。
(2)研究方法—Boosting方法
Boosting算法〔2-3〕基于其他机器学习算法之上的用来提高算法精度和性能的方法。起初并不需要构造一个拟合精度高、预测能力好的算法,只要一个效果比随机猜测略好的粗糙算法即可。通过不断调用这个基算法来改变样本分布和赋予判别模型不同的权重得以实现,最终获得一个拟合和预测误差都相当好的组合预测模型。
Boosting严格意义上不是一个具体的学习算法,它需要给定一个弱学习算法和一个训练序列。初始化时给每个训练例赋权重为1/N。然后用选定的弱学习算法进行第一次训练,给训练失败的训练例赋以更大的权重,也就意味着在后面的学习中集中对此类训练例进行学习。经过T次训练后得到一个训练序列h1,h2,…,hT,其中hi有权重,预测效果好的预测函数权重较大,反之较小。最终的预测函数H采用有权重的投票方式产生。
Adaboost算法〔3-4〕
假定具有N个带分类标签的样品序列<(x1,y1),…,(xn,yN)>,其中xi∈X,yi∈{-1,+1},N个样品点权重的分布为D,基础弱学习算法记为Weaklearner,迭代次数为T。
① 初始化:D1(i)=1/N,其中i=1,2,…,N,对t=1,…,T循环执行:
②用分布Dt训练基础学习器;
③得到弱分类器ht;
④计算ht训练误差εt,
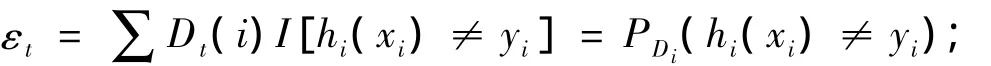

⑥重新计算样品的权重:
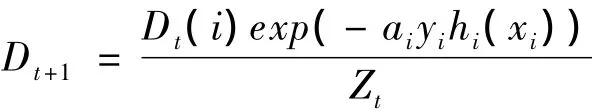
其中Zt=∑Dt(i)exp(-atyihi(xi))是归一化因子(Dt+1为分布);
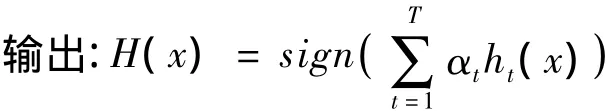
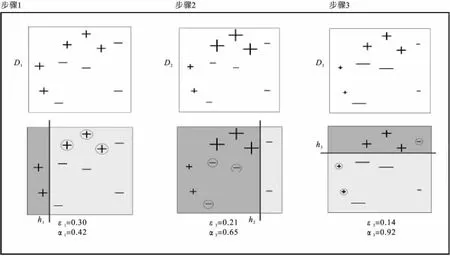
图2 使用简单的线性模型作为弱分类器的Boosting算法运算过程
Boosting算法进行变量重要性评价原理〔5-6〕
由于决策树具有能预测变量的重要性的优点,可以对分类起作用的变量进行重要性评价,因此考虑使用决策树作为基函数。对于Boosting算法,在给定训练样本和损失函数L(y,H)的前提下,其目的是找到一个决策树模型的线性组合,使得该组合可以对损失函数进行极小化优化,即H(X)=argH(x)minEy,xL(y,H(x)),优化的过程一般沿着目标函数的梯度最速下降方向。最终得到的H(X)实际上是多个决策树的线性组合。单个决策树的变量重要性评分为由节点到分裂后的节点间误差平方和的减少量,推广到多个决策树的问题上,即可以把每颗树中该变量的重要性评分求均值。
模拟试验
按代谢组数据的特点构造类似的数据,考察Boosting算法与决策树结合后的判别分类模型对此类数据变量重要性度量的效果,设定5个对分类有作用的差异变量X1,X2,X3,X4,X5,两组样本含量设为n1=n2=30,两类真实的区分度用ROC曲线下面积θ衡量,分别设置为θ=0.85,0.95,0.99。根据类间区分度来确定差异变量的均数,为简单起见,方差均设为==1,其中X1与X2两个变量的相关系数设为ρ=0.5。加入1000个无差异的正态变量作为干扰,产生混合样本。应用Boosting方法构建的模型对变量重要性进行度量。重复上述步骤500次,表1给出的是预先设置的差异变量的频数分布情况。结果显示,θ=0.85在时获得的结果不够理想,而在两种较高的区分度下,正确地将差异变量筛选到前10位的百分率分别达到了98.6%甚至于100.0%,结果令人满意。

表1 设定的5个差异变量在变量重要性评价分析中的频数分布
实例分析
病例入选标准,纳入病例应为无代谢疾病(糖尿病、高血脂、甲亢、甲减等)的卵巢癌、良性卵巢囊肿和无癌症及卵巢疾病的对照女性。
由于在Windows操作系统下,使用R语言构建BTS对变量的个数有一定的限制,因此首先应用单变量分析方法(SAM)做预处理后,然后再用BTS模型进行分析。经过SAM方法分析后,选取SAM得分排在前2000的代谢组分进行分析,应用Boosting组合模型对经过预处理的卵巢癌代谢组数据进行了分析,利用无放回的随机抽样方法,将样本分成两部分,其中2/3为训练样本,1/3为测试样本,按此方法随机组成1000个训练样本和1000个测试样本,建立组合分类器,最后综合评价分类效果。评价采用灵敏度(Se)、特异度(Sp)、和ROC曲线下面积(AUC)三种指标,其中AUC值为主要评价指标。
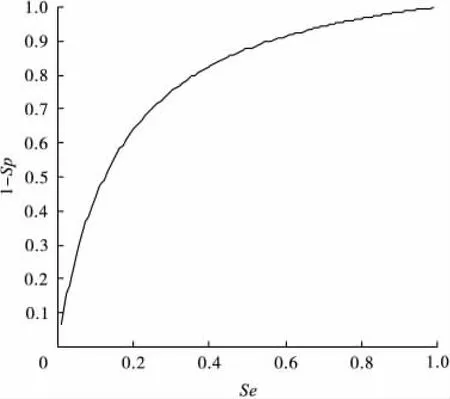
图3 在保留了2000个代谢组分的情况下Boosting模型对卵巢癌数据分类的ROC曲线
预测效果的ROC曲线见图3。可以看出,在保留了2000个代谢组分的情况下,对外部测试集获得了较为理想的判别分类结果,其灵敏度(Se)和特异度(Sp)分别为0.733和0.724,而ROC曲线下面积(AUC)则达到0.801。判别分类效果不甚理想,可能是由于噪声变量(或对分类无作用的代谢组分)太多引起的。
应用Boosting模型进行分类的同时,筛选出排序靠前的对分类起作用的变量。筛选标准是将1000次分类中筛选进来的变量出现的概率≥80% 的变量提取出来,共提出30个变量。将筛选出的这30个变量对卵巢癌数据的外部验证集进行1000次分类判别,得到的分类结果(AUC值)的频数图如下,由图4可以看出分类能力显著提高。可见这30个变量中一定存在对分类起作用的信息。
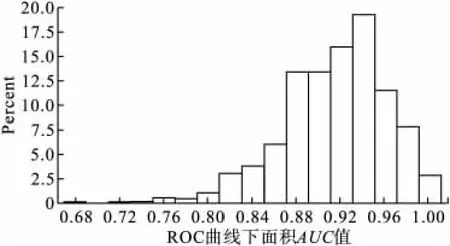
图4 应用筛选出的30个变量进行1000次分类得到的AUC值的频数图
为了筛选出最佳对分类起作用的变量,进行了进一步的变量提取工作。将30个变量按照变量重要性评分逐渐递减,并用分类结果作验证。从表2和图5可以看出,当截取到10个变量的时候,分类判别能力达到理想的效果。可见这10个代谢组分可能是区分卵巢癌患者与对照组患者的重要标志物。
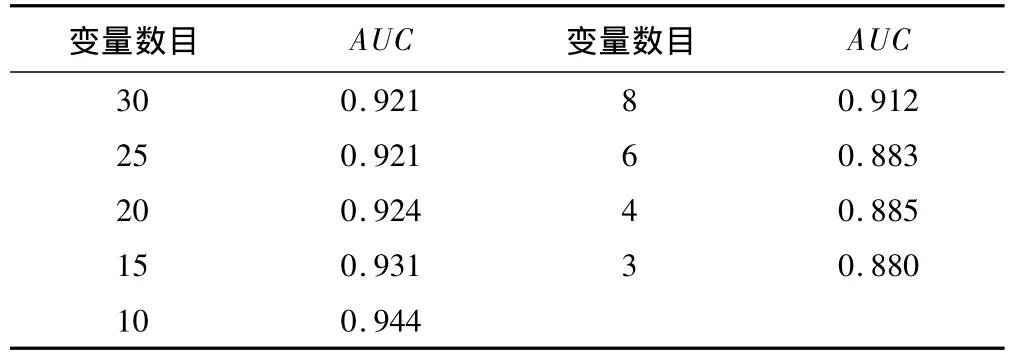
表2 随着变量数目的减少分类结果AUC值的变化
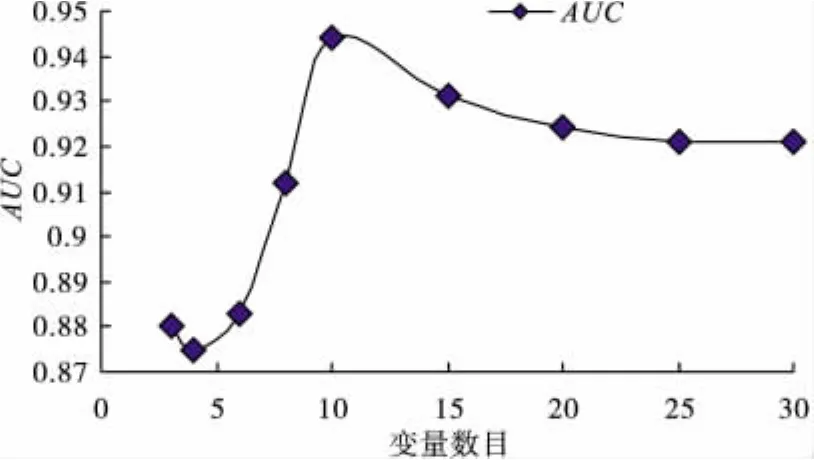
图5 随着变量数目的减少分类结果AUC值的变化
讨 论
1.卵巢癌的早期诊断与早期治疗是改善预后的关键。在疾病早期肿瘤仅局限于卵巢时难以诊断,所以寻找有实用价值的诊断方法成了近年来的研究热点。代谢组学的研究近年来蓬勃发展,如果我们仅通过患者的代谢物(血液或尿液)即能够做出正确的诊断,不仅给临床的诊断工作带来极大的便利,也为患者减轻做病理所带来的痛苦。所以运用代谢物来鉴别肿瘤的良恶性将是一件很有意义的工作。
2.本研究采用分类决策树作为基础算法,应用Boosting方法建模,在模拟数据和实际数据的应用中均取得了理想的结果。在对卵巢癌代谢组实际数据的分析中,该模型能够在分类的同时给出差异表达代谢组分的变量重要性评分,并由进一步的分类验证可以看出,该模型预测的准确性也能够令人满意,为临床上对卵巢癌患者的诊断和治疗提供了一定的依据。
3.此方法筛选出的10个代谢组分,通过HMDB数据库的查询,多数可能为磷脂类的物质,但由于大量同分异构体的存在,为了确保究竟是何种代谢组分,应该将物质打碎进一步做二级质谱以确定是何种代谢组分,这部分试验尚在进行之中。
1.Jerome F,Trevor H,Robert T.Additive logistic regression:a statistical view of Boosting.The annals of Statistics,2000,28:337-407.
2.Schwenk H,Bengio Y.Boosting networks and neural computation,2000,12(8):1869-1887.
3.Servane Gey,Jean-Michel Poggi.Boosting and instability for regression trees.Computational Statistics& Data Analysis,2006,50:533-550.
4.Freund Y,Schapire R.Decision theoretic generalization of on-line learning and an application to boosting.Journal of Computer and System Science,1995,55(1):119-139.
5.李霞,何丽云,刘超.Boosting算法及其在中医亚健康数据分类中的应用.中国卫生统计,2008,25(2):158-161.
6.Dao Li-li,Hu ke-yun,Lu Yu-chang.Improved stumps combined by boosting for text categorization.Journal of Software,2002,13(8):1361-1367.
The Study of Boosting Algorithm Applied to Ovarian Cancer Metabonomics Data
Wu Zhenyu,Jia Huixun,Zhu Ji.Department of Biostatistics,Fudan University(200032),Shanghai
ObjectiveBoosting model was built to analyze the metabonomics data from ovarian cancer and ovarian cyst patients urine.Some biological metabolites were also extracted from the data,which would provide some clues to the early diagnosis.MethodsBoosting and decision tress were combined to analyze the metabnomics data and the important metabolites were achieved according to their importance scores.ResultsThe top ten metabolites were extracted and the area under ROC curve was 0.944,which provided a better classification results than the original dataset.ConclusionBoosting could be effectively applied to the classification of ovarian cancer metabnomics data,important features could also be extracted at the same time.
Metabnomics data;Boosting;Feature selection
