面向移进—归约句法分析器的单模型系统整合算法
2012-06-29朱慕华朱靖波
马 骥,朱慕华,肖 桐,朱靖波
(东北大学 自然语言处理实验室,辽宁 沈阳 110004)
1 引言
系统整合的主要目的在于通过整合多套不同的系统来得到更好的整体性能。基于系统整合的方法在近年来已经受到广泛的关注,这类方法已经广泛应用于与自然语言处理领域相关的任务中,例如,文本分类[1]、命名实体识别[2]、机器翻译[3-4]和句法分析[5-6]等。一般而言,基于系统整合的方法要解决的两个核心问题为:如何构建多套用于整合的子系统*为描述方便,本文称参与整合的各系统为子系统。;如何将各子系统的输出进行整合从而得到最终结果。对于第一个问题,一种方法是用不同的模型来构建各个子系统,即参与整合的子系统是由不同的模型通过训练得到的。本文称这种方法为基于多模型的系统整合。另一种方法是用同一个模型来构建不同的子系统。本文称这种方法为基于单模型的系统整合。多模型系统整合的缺点在于开发不同模型需要付出较高的时间与人力。而单模型系统相对来说开发代价较低。因此,本文主要研究面向移进—归约句法分析器的单模型系统整合技术。在训练阶段,本文使用基于AdaBoost[7]的子系统生成算法,该方法通过改变训练数据的分布来生成多个移进—归约句法分析器。在解码阶段,本文主要考虑两类特征——子系统置信度和扩展动作序列置信度(第4部分将详细介绍)——并使用这两类特征的线性组合对各子系统的输出进行整合。作者在宾夕法尼亚大学提供的英文树库(Penn English Treebank)上进行实验。实验结果表明,本文中的方法能够显著提高移进—归约句法分析器的性能。
Henderson和Brill[8]对面向Collins Parser[9]的单模型系统整合方法进行过研究,然而关于移进—归约句法分析器,尚没有此类研究。移进—归约句法分析器的特点是在于其速度快。因此通过系统整合来提高移进—归约句法分析器的性能是一件有意义的工作。
2 移进—归约句法分析法
移进—归约句法分析法涉及的两个主要数据结构为:输入队列Q和分析栈S。队列Q中的元素是输入句子中尚未被处理的 <词,词性>对序列。分析栈S中保存着输入串中已经被处理的部分所对应的句法树片段。移进—归约句法分析法自左向右地扫描待分析的句子,并在扫描过程中执行下列动作之一。
• 移进:将Q的队首元素压入栈S,并从Q中删除该元素。
• 一元/二元—XX—归约:生成一个新的元素,该元素的非终结符类型为XX,弹出栈顶的一个/两个元素,并将弹出的元素作为新生成的元素的子树。最后,将新生成的元素插入到栈顶。
当Q为空时,如果S中只有一个元素,则将S中的元素作为输入句子的分析结果,并结束整个分析过程。如果S中包含多于一个元素,则报告对输入句子分析失败。
图1中展示了移进—归约句法分析法的分析过程。初始情况下(图1(a)),S为空,Q中包含待分析句子的<词,词性>对序列。算法第一步执行移进动作,将队首元素

图1 移进—归约句法分析法的分析过程举例
基于移进—归约句法分析法的首个句法分析器是由Sagae和Lavie[10]实现的,其基本思想是从S和Q的状态中抽取特征,然后使用一个分类器根据这些特征来选择要执行的动作。因此,整个句法分析过程可以看成是使用分类器进行一系列移进—归约动作的决策过程,而训练移进—归约句法分析器主要是训练该分类器。用于训练分类器的训练数据是一组<特征向量,动作>对,称为分类样本。例如,与图1所对应的那组分类样本为:
其中,v(a)表示从图1(a)所描述的S和Q的状态中抽取的特征向量。
Sagae和Lavie在文献[10] 中实现的移进—归约句法分析器每一步只选择一个动作来执行,因此一个输入句子仅对应唯一一组动作序列,这种贪婪的策略限制了移进—归约分析法的搜索空间,并且如果某一步选择了错误的动作,则该错误将影响对后续动作的选择。为了克服该缺点,Sagae和Lavie[11]使用了最优优先(best-first search)搜索算法对他们前期的工作进行改进。在分析过程中,分析器每次可以选择尽可能多的动作来对当前的S和Q的状态进行扩展,并将动作执行之后的结果状态存入到一个全局优先级队列中。分析器使用基于最大熵模型的分类器对每个动作进行评分,优先级队列中的每个状态的得分是从初始状态到该状态所执行的动作序列的得分的乘积。该方法扩大了分析器的搜索范围,从而提高了分析器的性能。本文所研究的系统整合方法也是基于Sagae 和 Lavie在文献 [11]中提出的移进—归约句法分析器,具体方法将在余下的章节中进行详细讨论,其中第三部分主要介绍了子系统构建算法,第四部分主要介绍子系统输出整合算法,第五部分介绍实验,第六部分和第七部分则分别为相关工作和对本文的总结。
3 单模型系统整合的子系统构建
本部分介绍基于AdaBoost的子系统生成算法,该算法的主要思想是通过更新训练数据的分布,来构建各子系统。在对该算法的具体细节进行描述之前,首先介绍该算法所涉及几个主要符号的含义。
本文用Psen表示训练语料中的句子的分布,Psmp表示从训练语料中抽取的分类样本的分布,SR表示移进—归约句法分析器。SR在训练语料中的第i个句子上取得的F1-score用score(i)表示。SR在整个训练语料中取得的平均性能用r来表示。
子系统生成算法通过迭代的更新Psen和Psmp,来构建各个子系统,其(第t轮)迭代的基本过程为:算法首先根据当前分类样本的分布Psmpt来训练一个最大熵分类器,从而构建一个移进—归约句法分析器SRt,然后使用SRt对训练语料中的句子进行句法分析。根据SRt在训练语料中的每个句子上取得的分数scoret(i),以及SRt在整个训练语料上取得的平均性能rt来更新训练语料中的句子的权重*本文用p(i)表示第i个样本的权重或概率,P表示分布。样本的分布可以通过对每个样本的权重进行归一化而得到。,从而得到训练语料的句子的新分布 Psent+1。由于训练一个移进—归约句法分析器的主要目的是训练该分析器中用于对移进-归约动作进行决策的分类器。因此,算法根据分布Psent+1,调整从语料中抽取的分类样本权重,从而得到新的分类样本的分布Psmpt+1。
图2中给出了整个子系统构建算法的伪代码,3.1和3.2将详细讨论Psen和Psmp的更新过程。3.3还将介绍如何修改最大熵模型的学习算法,使新的学习算法(WeightedMELearn)能够考虑每个样本的权重。
3.1 更新Psen
本小结主要讨论如何在每一轮迭代过程中调整训练语料中句子的分布Psen(图2中步骤(4))。其具体过程如下:假设在第t轮迭代中,算法首先使用在该轮构建的移进—归约句法分析器SRt对训练语料中的句子进行句法分析,SRt会在一部分句子中取得相对较低的F1-score。为了让下一轮构建的句法分析器能够更好地处理这部分句子,更新句子权重的准则为:SRt在某句子中的得分越低,该句子的权重增长幅度就越大。
式(3)给出了更新第i个句子的权重的计算方法,其中Zt为归一化因子。由式(3)可知,每个句子的权重的更新幅度主要由两部分决定:损失因子errort(i),和步长因子βt。
定义SRt在第i个句子上的性能损失errort(i) 为,
(4)
其中,scoret(i)表示SRt在训练语料中第i个句子上取得的得分(F1-score)。由式(4)可知,SRt在该句子上的得分越低,损失因子就越大,因此对该句子的权重的增大幅度就越大。
步长因子βt的计算主要基于以下原则:对于性能相对较高的句法分析器仍然无法正确处理的句子应该给予更多的重视。定义SRt在整个训练语料上取得的平均性能rt为其在训练语料的每个句子上得分的期望,如式(1),然后根据rt的值,计算βt,如式(2)所示。由式(2)可知,SRt的平均性能越高,则步长因子βt越大。
3.2 根据Psen,更新Psmp
假设sj为训练语料中第j个句子并且SRt在该句子上的性能损失大于0,即errort(j)>0。对于如何更新从sj中抽取的分类样本的权重(注:对从训练语料的每个句子中抽取的全部分类样本的权重进行归一化即可得到分类样本的分布Psmp),本文使用了两种不同的方案。

图2 基于AdaBoost的子系统构建算法
方案一,从sj中抽取的全部分类样本的权重都将被更新,方案一设置这些分类样本的权重与sj的权重相同。
方案二,仅更新SRt对sj进行句法分析过程中的第一个错误决策所对应的分类样本的权重,并设置该分类样本的权重与sj的权重相同。方案二与Collins和Roark在文献[12]中提出的“early update”类似,使用这种方案主要是由于移进—归约句法分析法的每一步的决策都会对后续动作的决策产生影响,第一个错误决策的出现往往会导致更多后续的错误决策。因此,句法分析过程中的第一个决策错误所对应的分类样本应该受到更多的重视。
3.3 加权训练样本的参数估计
本小节主要介绍如何修改最大熵模型的学习算法,使得修改后的学习算法能够根据训练数据的权重来调整最大熵模型的参数。令{(xi,yi)}为一组独立同分布的训练样本,其中xi表示第i个样本的特征向量,yi为该样本的类别。传统的最大熵模型学习算法[13]通过最大化式(5)定义的样本集的对数—似然值来确定最大熵模型的参数。
(5)
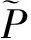
(6)
(7)
其中w(xi,yi)表示训练样本(xi,yi)的权重。则整个训练样本的对数—似然值为:
(8)
通过使用如L-BFGS[14]等方法优化目标函数(8)即可得到最大熵模型的参数的极大似然估计值。
4 子系统整合
本章主要介绍将各个子系统的输出进行整合的方法。假设对m个子系统进行系统整合,则对于测试集上的任何一个句子,首先用待整合的m个子系统分别对该句子进行句法分析,生成m棵句法树,然后用一个线性模型对这m棵句法树进行评分,并将得分最高的句法树作为最终结果。令t表示一棵句法树,则t的最终得分为:
(9)
αi为第i个特征的权重,权重的值可以使用最小错误率训练方法(文献[15])来确定(将MERT的错误率函数定义为1-F1-score)。
式(9)中的线性模型主要包含两类特征:第一类特征称为子系统置信度(类似于Zhang 等在文献[16]中提出的模型置信度),用pi(t)表示,即第i个子系统对句法树t的置信度。该置信度的计算方法如下:假设
(10)
第二类特征为扩展动作序列置信度pas(t)(与统计机器翻译中使用的语言模型特征类似),表示由a1,...,ak组成一个扩展动作序列的概率。其中aj是对动作aj的扩展,其定义如下:
(11)
POS(aj)表示被aj移进的元素的词性。我们通过观察发现,如果将原始的动作序列进行扩展以后,扩展的动作之间往往存在某些模式或联系。例如,生成由两个名词组成的名词短语的动作序列为:
移进_NN, 移进_NN, 二元—NP—归约
因此,使用pas(t)的目的就是希望通过对扩展动作序列的分布建模。从而对给定的一组扩展动作,可以从概率的角度来判断这组扩展动作生成一颗句法树的可能性。本文使用N元语言模型对扩展动作序列进行建模,在训练阶段,使用从训练集中抽取的扩展动作序列对语言模型进行参数估计。训练结束以后,就可以使用该模型计算t的扩展动作序列置信度pas(t),例如,当N=2时,图1(f)中的句法树的扩展动作序列置信度为:
pas(t)=l(移近_JJ)×l(移近_JJ|移近_JJ)×
l(二元-ADJP-规约|移近_JJ)×
l(移近_NNS|二元—ADJP-规约)×

(12)
其中,l为语言模型定义的条件分布。
5 实验
5.1 基准系统及实验数据
本文使用宾夕法尼亚大学英文树库(Penn English Treebank)作为实验数据,并主要使用以下三个部分:02-21节作为训练集,主要用于训练移进—归约句法分析器和N语言模型。22节作为开发集,主要用于训练式(9)中各个特征的权重。23节作为测试集。我们删除了训练集和开发集中所有句法树的功能节点及空节点,并使用Collins在文献[17]中介绍的方法对句法树进行词汇化。
本文实现了文献[11]中提出的移进—归约句法分析器作为本文实验的基准系统,该基准系统的再测试集上的F1得分为 87.10。但文献[11]中使用的分类器*http://www-tsujii.is.s.u-tokyo.ac.jp/~tsuruoka/maxent/的训练时间大于40小时,这使得迭代的训练多套系统在时间上不可行。本文因此改用Zhang[18]开发的最大熵工具作为对移进—归约动作进行决策的分类器,基于该分类器的移近规约句法分析器的性能为86.13,但该分类器的训练时间较短,一般在三小时以内,使得迭代的训练多套子系统变得可行。对于子系统生成部分,我们使用3.3节中提到的方法对最大熵模型的学习部分进行修改,使最大熵的学习部分能够同时考虑训练样本数量及权重。对于N元语言模型,本文使用了基于Katz[19]的平滑方法的语言模型工具,利用该工具对扩展动作序列进行建模。
由于移进—归约句法分析器的输入是带有词性标注的句子,因此我们使用SVMTool[20]作为本实验的词性标注器,该工具在测试集上的准确率为96.81%。本文使用EVALB作为实验性能的评价工具。
5.2 实验结果及分析
第一组实验使用五元语言模型对所有子系统的输出进行整合,实验结果如表1所示。其中“开发集”和“测试集”分别表示在开发集及测试集上取得的性能,“方案1”和“方案2”分别表示使用3.2介绍的方案1和方案2来更新分类样本的权重所取得的性能。'T(M)'表示取得最佳性能时,参与整合的子系统的个数为M。从表1中可以看出,对于开发集,基于方案1和方案2的系统整合后的性能分别比基准系统的性能提高了2.09和2.16个点,这说明了本文中提出的系统整合方法的有效性。对于测试集,基于方案1和方案2的系统整合后的性能则分别比基准系统的性能提高了1.47和1.94个点,这表明方案2更能有效的调整分类样本的权重,从而获得更好的系统整合性能。

表1 系统整合在测试集和开发集上的性能
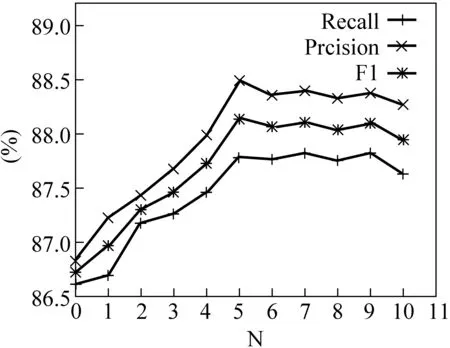
图3 系统整合的性能随N的变化曲线
第二组实验主要是为了研究N元语言模型对系统整合的影响。在该组实验中,我们选择不同的N值,然后记录下整合后的系统在测试集上取得的性能*在该组实验中,我们使用3.2节的方案2来更新分类样本的权重,并使用12个子系统进行整合,该设置是第一组实验中取得最高性能时的设置。,实验结果如图3所示。从图3中可以看出,当N从1增大到5时,整合系统的性能随N的增加而提高,这表明使用基于N元语言模型的扩展动作序列置信度能够对最终结果的选择带来帮助。当N为5时,系统的性能达到最高,这表明使用5元语言模型对系统整合的帮助最大。当N从5增大到10的时候,整合系统的性能随N的增大而下降。这主要是由于随着N逐渐增大,数据稀疏问题越发严重,导致系统整合的性能逐渐下降。
为了进一步研究扩展动作序列置信度对句法分析器的影响,本文将扩展动作置信度整合到基准系统(单系统)当中,并在开发集上利用MERT调整基准系统以及扩展动作置信度的权重。整合后的系统在开发集和测试集上的F1得分分别为85.55和87.36,表明扩展动作置信度的有效性。
6 相关工作
对于短语结构句法分析的系统整合的研究工作,早在上个世纪就已经开始。Henderson 和 Brill 在文献[5]中提出了两种不同的整合方法。第一种方法是将各个子系统输出的句法树进行相似度打分,得分最高的句法树作为最终结果。第二种方法是将各个子系统输出的句法树拆成一序列元组(constituent),通过统计每个元组出现的次数来判断该元组是否可能出现在最终结果的句法树中,其判断的标准为:如果一个元组在半数以上的句法树中出现,则该元组可能出现在最终结果中。Sagae和Lavie在文献[6]中将这种方法做了进一步扩展,他们使用一个阈值来选择可能出现在最终句法树中的元组。Zhang等人[16]从子系统的输出中选择一棵最优句法树作为最终结果,并使用模型置信度作为句法树质量的评价标准之一。以上方法与本文中方法的最主要区别在于,以上方法的系统整合都属于多模型系统整合,而本文中的系统整合则是基于单个模型。
Henderson 和Brill[8]研究了基于Collins Parser的单模型系统整合,他们首先基于Adaboost,调整语料中的句子的权重,从而生成多套子系统,在解码阶段,他们使用文献[5]中提出的元组选择的方法对子系统的输出进行整合。然而,本文是对移进—归约句法分析器进行单模型系统整合。此外本文中提出的权重更新方法同时考虑到句子的权重和分类样本的权重,而且本文中的基于线性模型的系统整合方法能够同时考虑系统置信度和扩展动作序列置信度等特征。
7 总结
本文提出了一种面向移进—归约句法分析器的单模型系统整合的方法。在子系统生成阶段,根据移进—归约句法分析器的特点,本文提出了两种不同的权重更新方法来生成多套子系统。在子系统输出整合阶段,通过使用线性模型对各子系统输出的句法树进行评价,从而选出最终结果。此外,本文通过实验对比分析了两种权重更新方法的有效性以及线性模型中使用的特征对系统整合的影响。
[1] Yoav Freund,Robert Schapire. BoosTexter: A Boosting-based for Text Categorization[C]Proceedings of Machine Learning. 2000. 39:135-168.
[2] Andrew Borthwick, John Sterling, Eugene Agichtein, et al. Exploiting Diverse Knowledge Sources via Maximum Entropy in Named Entity Recognition[C]//Proceedings of the Six Workshop on Very Large Corpora, 1998: 152-160.
[3] Evgeny Matusov, Nicola Ueffing, Hermann Ney. Computing consensus translation from multiple machine translation systems using enhanced hypotheses alignment[C]//Proceedings of EACL 2006: 33-40.
[4] Tong Xiao, Jingbo Zhu, Muhua Zhu,et al. AdaBoost-based System Combination for Machine Translation[C]//Proceedings of ACL 2010: 739-748.
[5] John Henderson, Eric Brill. Exploiting diversity in natural language processing: combining parsers[C]//Proceedings of EMNLP 1999: 187-194.
[6] Kenji Sagae, Alon Lavie. Parser combination by reparsing[C]//Proceedings of HLT-NAACL 2006: 129-132.
[7] Yoav Freund, Robert Schapire. A decision theoretic generalization of on-line learning and an application to boosing[J]. Journal of Computer and System Sciences, 1997, 55(1): 119-139.
[8] John Henderson, Eric Brill. Bagging and Boosting a Treebank Parser[C]//Proceedings of ANLP 2000:34-41.
[9] Michael Collins. Three generative, lexicalised models for statistical parsing[C]//Proceedings of ACL 1997:16-23.
[10] Kenji Sagae, Alon Lavie. A Classifier-based Parser with Linear Run-Time Complexity[C]//Proceedings of IWPT 2005.
[11] Kenji Sagae, Alon Lavie. A Best-First Probabilistic Shift-Reduce Parser[C]//Proceedings of ACL-COLING 2006 (poster).
[12] Michael Collins, Brain Roark. Incremental Parsing with the perceptron algorithm[C]//Proceedings of ACL 2004:111-118.
[13] A comparison of algorithms for maximum entropy parameter estimation[C]//Proceedings of CoNLL-2002:49-55.
[14] Dong C. Liu, Jorge Nocedal. On the limited memory BFGS method for large scale Optimization[C]//Proceedings of Mathematical Programming, 45:503-528.
[15] Franz J. Och. Minimum Error Rate Training in Statistical Machine Translation[C]//Proceedings of ACL 2003: 160-167.
[16] Hui Zhang, Min Zhang, Chew Lim Tan, et al. K-Best Combination of Syntactic Parsers[C]//Proceedings of EMNLP 2009: 1552-1560.
[17] Michael Collins. 1999. Head-Driven Statistical Models for Natural Language Parsing[D]. Phd thesis, University of Pennsylvania.
[18] Le Zhang. Maximum Entropy Modeling Toolkit for Python and C++ Reference Manual[CP/OL]. http://homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html.
[19] Katz, S. M. Estimation of probabilities from sparse data for the language model component of a speech recogniser[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 35(3): 400-401.
[20] Jesús Giménez, Lluís Márquez. SVMTool: A general POS tagger generator based on Support Vector Machines[C]//Porceedings of LREC 2004:43-46.
