改进的关联规则算法在数据挖掘中的探讨
2012-01-25韩卫媛李文成
杨 艳,韩卫媛,李文成
(1.济源职业技术学院,济源 454650;2.河南济源钢铁公司 信息中心,济源 459000)
0 引言
数据挖掘是数据库中的知识发现,是指从存放在数据库、数据仓库或其他信息库中的大量数据中自动地发现相关模式、提取有潜在价值的信息、挖掘知识的过程,从CRM 的角度,数据挖掘应用就是从大量数据中挖掘出隐含的、对决策有潜在价值的知识和规则,能够根据已有的信息对未来发生行为做出结果预测,为企业经营决策、市场策划提供依据。CRM中的应用中比较典型的数据挖掘方法有关联分析、序列模式分析、分类和预测分析、聚类分析、演变分析等。
1 关联规则挖掘的一般步骤
关联规则挖掘的步骤为:
1)预处理与挖掘任务有关的数据。根据具体问题的要求对数据库进行相应的操作,从而构成规格化的数据库D。
2)根据D,通过迭代检索出事务数据库中的频繁项目集L,即支持度不低于用户设定的最小支持度的项目集,即频繁项目集。
3)利用频繁项目集L构造出满足用户最小可信度的规则,形成规则集并用可视化方法进行输出。
2 算法改进——改进的频繁项目集算法
在本文中,引入参数c,在旧数据集中发现频繁项目集的过程中,保留那些支持度大于或等于minsup/c(minsup为最小支持度)的频繁项目集,每次数据库中增加新的数据集时,只考虑以前产生的支持度大于或等于minsup/c的频繁项目集和当前增加的数据集,扫描支持度大于或等于minsup/c的频繁项目集的时间比扫描整个旧数据集的时间要短得多。设原有交易数据库中的数据集记为D,新增加的数据集记为d,则整个交易数据库为(D+d),它的基本思想是:
假设已经采用Apriori算法获得数据集D的支持度大于或等于minsup/c的频繁项目集L'(D),L'(D)中的各个项目集的支持数count及用于计算这个项目集的交易总数countall(如有两个交易集D1和D2,对于某个项目集L1,它在D1是频繁项目集,而在D2不是频繁项目集,则L.countall=D1,如果L1在D1及(D1+D2)中都是频繁项目集,则Ll.countall=|D1|+|D2|,以下是在增加新的数据集d后的算法的基本思想:
1)根据新数据集d和L'(D)得到支持度大于或等于(minsup/c)的频繁项目集,加入到(D+d)的支持度大于或等于(minsup/c)的频繁项目集L'(D+d)中。对于项目集L1,Ll ☒ L'(D),则Ll.support=(Ll.count(d)+Ll.count(D))/(Ll.countall(D)+|d|),把支持度I.support≥minsup/c)的项目集Ll加入(D+d)的频繁项目集L'(D+d)。
2)遍历新数据集d,用Apriori算法计算新数据集d中的支持度大于或等于(minsup/c)的频繁项目集L' (d),这一步中项目集的支持度的计算方法不同于(1),d中的项目集L1的计算方法为Ll.support= Ll.count(d)/|d|。
3)对于项目集 Ll,Ll ☒ L'(d)且 Ll ☒ L'(D 十 d),则把L1加入到L'(D+d)中。
4)用Apriori算法在得到的支持度大于或等于(minsup/c)的频繁项目集L'(D十d)中找出支持度大于或等于minsup的频繁项目集,即L(D+d)。
3 改进的关联规则算法在数据挖掘中的实际应用
我们选取某钢铁公司的销售数据作为我们的研究对象,来分析关联规则应用于该系统的过程:
3.1 定义问题
根据CRM的具体目标来设置数据挖掘的目标。我们设置要挖掘的目标是通过对交易数据库的分析,来发现哪些产品商品被客户一起购买,利用该结果来制定相应的策略,从而提高厂家的销售收入。
3.2 建立销售数据仓库
我们取“交易”作为主题,而对于其他的主题这里不作考虑,接下去就围绕交易数据来建立数据仓库。
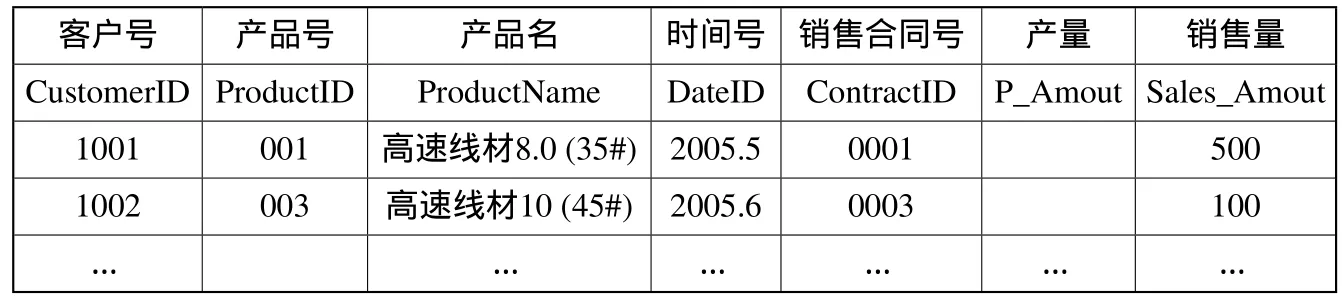
表1 交易数据信息
3.3 数据挖掘过程
3.3.1 设置目标数据
我们用Num来表示交易的序号,具有相同的CustomerID和DateId,那么它们将属于一个单一的购买订单的交易,在客户用户购买一个项目的每条记录都有的交易货物productID,这对应于交易数据库中的销售合同ContractID。产品编号productID对应于交易数据库中的货物。我们根据客户购买的时间DateID,把它分为不同的时间段,如取定某个日期,对于date小于该日期的数据作为旧数据,用Flag=1来表示,date大于该日期的数据作为新数据,用Flag=2来表示。按这样的标准转换后,我们就得到了可用关联规则挖掘算法进行挖掘的数据。
3.3.2 决定最小支持度和最小可信度
这一步是为特定的数据挖掘过程决定最小支持度和可信度,这两个因素一般由用户决定。数据挖掘应用过程中,用户选择不同的最小支持度和可信度来得到的关联规则,然后比较不同的挖掘结果,从而选择合适的最小支持度和最小可信度。在本例支持度为0.002,可信度为0.15。
3.3.3 执行关联规则挖掘算法
1)用Apriori算法生成旧数据集D的频繁项目集
(1)产生支持度大于或等于(minsup/c)的频繁项目集,
(2)产生支持度大于或等于(minsup/c)的频繁k(k≥2)项集。在第k-1遍遍历的过程中,Ck是所有频繁k项集的一个超集,它是由第k-1遍的频繁项目集Lk产生在以上过程中,完成了q的联合和剪枝两个步骤,例如,L3={{001,002,003),(001,002,004),{001,003,004),{001,003,005),{002,003,004)),那么联合后得到的候选集的集合C4就是{{1,2,3,4},{1,3,4,5}}。
(3)紧接对得到的候选集的集合Ck进行剪枝,如果有任何一个Ck中元素的(k-I)项子集不在Lk-1中,那么我们就必须从Ck中删除这个元素。在以上的例子中,虽然{1,3,4,5}是C4的一个元素,但因为它的一个3项子集{3,4,5}不在L3,所以必须把{1,3,4,5}从C4删除。
通过以上步骤后,我们得到了支持度大于或等于(minsup/c)的频繁项目集L'(D),如果我们要获得支持度大于或等于minsup,那么就可以在以上得到的支持度大于或等于(minsup/c)的频繁项H集基础上,再次利用Apriori算法就可获得支持度大于或等于minsup的频繁项目集L(D)。
2)根据L(D)遍历新数据集d生成频繁项目集
在我们得到旧数据集的支持度大于或等于(minsup/c)的频繁项目集后,我们以它和新数据集d作为新的挖掘对象,采用Apriori算法进行挖掘,这个过程我们也分成频繁1项集和频繁k(k≥2)项集的生成两个部分:
(1)支持度大于或等于(minsup/c)频繁1项集的生成。
计算新数据集d的各个1项集的在d中的出现次数和支持度,放在表中,如下所示:

(2)支持度大于或等于(minsup/c)频繁k(k≥2)项集的生成。
用Apriori中产生候选集的方法,根据频繁(k-1)项集产生Ck,然后采用频繁1项集的产生方法生成频繁k项集。
3)新数据集d的频繁项目集的生成
新数据集d的支持度大于或等于(minsuplc)的频繁项目集L'(d)的生成过程和旧数据集D的一样,这里就不再介绍。
4)把d中不同于频繁项目集加入L'(D+d)
在得到d的频繁项目集L'(d)之后,把项目集1,1EL'(d)且1eL'(D+d)插入到L'(D+d)中,这一步实现比较简单,这里也不作介绍。
5)根据L'(D+d)求出L(D+d)
通过以上几个步骤我们就得到了支持度大于等于(minsup(c)的频繁项目集,在这个频繁项目集的基础上我们再次采用Apriori算法得到支持度大于或等于minsup的频繁项目集。
对于每个频繁项目集,我们要找到所有的关联规则,如对于频繁项目集{004,005,006},可能 的 关 联 规 则 为 {004}=:>{005,006},{005}=>{005,006},{006}=>{004,005},{004,005}=>{006},{004,006}=>{005},{005,006}=>{004},并 且 删 除 可信度小于最小可信度的关联规则,如关联规则{004,005}=>{006}的可信度为confidence({004,00 5}=>{006})=support({004,005,007})/support({004,0 05})=0.002/0.028=0.071。在这个例子中,我们取最小可信度minconf=0.15,则我们就得到关联规则存储表如表2所示。

表2 关联规则存储表
将产品代号用产品名称替换后得到表3。
我们可得到规则:
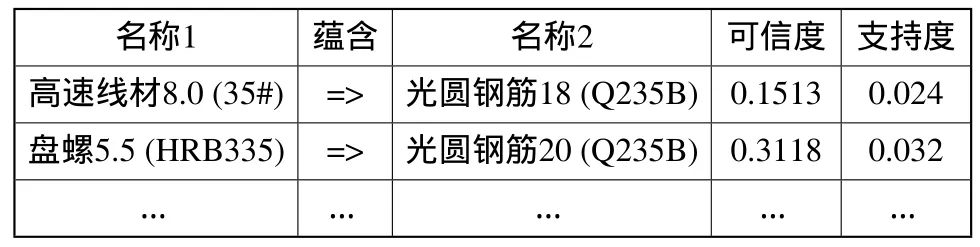
表3 替换产品名称
高速线材8.0(35#)=>光圆钢筋18(Q235B)可信度为:0.1513,支持度为:0.024

盘螺5.5(HRB335)=>光圆钢筋20(Q235B)可信度为:0.3118,支持度为:0.032
4 关联规则的表示和评价
关联规则可以用关联表来表示,也可以用形象的二维或三维的图来表示。如其中的一条关联规则表示如下:
规则1:钢锭15吨(m45锰钢)=>钢锭30吨((ti13钛钢),可信度为0.1513,支持度为0.024。该规则可以这样理解:在交易数据库中,每1000笔交易中有24笔的交易,客户同时订购了钢锭15吨(m45锰钢)和钢锭30吨((ti13钛钢),并且每1000笔订购钢锭15吨(m45锰钢)的交易中,有151笔交易同时订购了钢锭30吨((ti13钛钢)。
以上的改进的关联规则算法能够在实际中建议生产部门,销售部门相应改变政策,进行合理的客户决策,以增加产品收入。能够留住老客户,从客户赚取更多的利润,并且对客户的反馈数据进行跟踪,从而产生具有竞争性的市场策略。
[1]AlexBerson构建面向CRM的数据挖掘应用[M].北京: 人民邮电出版社,2001.
[2]蒋斌.数据挖掘技术在客户关系管理中的运用[J].云南大学学报(自然科学版),2006,28.
[3]吕美,姬浩.数据挖掘技术在ERP风险防范中的应用研究[J].商场现代化,2006,12.
[4]曾玲,熊才权,胡恬.关联规则在空间数据挖掘中的研究[J].计算机与数字工程,2005,33(6).
[5]侯伟,杨炳儒.多关系关联规则算法综述[J].计算机工程与应用,2007,43(23).
[6]张毅驰,朱巧明.改进的关联规则算法及其应用[J].计算机系统应用,2007,10.
[7]周艳山.数据挖掘中关联规则界法的研究及应用[J],2005,3:28.
[8]彭仪普,熊拥军.关联规则挖掘Apnd算法优化研究[J].计算机工程,2006,32(05).
[9]范文建,戴齐,陈明.基于粗糙集的关联规则算法的研究[J].福建电脑,2006,4.
