在线预测的灰色支持向量回归方法
2011-09-05蒋辉
蒋 辉
(1.中国人民大学 统计学院,北京 100872;2.惠州学院数学系,广东惠州 516007)
0 引言
在对系统数据进行预测时,批量学习(Batch Learning)要求训练数据模式(样本点)在学习之前一次性得到(满足批量性),新的数据模式的到达对依托原有样本集的预测结果不产生影响。然而,现实系统的复杂性和未来的发展趋势往往通过数据新的变化表现出来,这要求在预测过程中不断更新已有的样本集,将新的数据信息纳入到样本集中,同时剔除最原始的信息,打破批量学习模式下样本集固定的局限。因此,在系统的预测过程中,每收集到一个新的数据模式就必须立刻对其进行学习,学习的效果体现在后续预测中,这种学习即为在线学习[5,9,10]。从实际情况看,这是一种更为自然的学习方式,许多实际问题都符合此种模式。例如,股指的动态预测,由于社会经济变化的不确定因素繁多,必须对所获得的新数据及时更新预测,使新数据对后续预测产生影响;像目标定位或追踪,周围环境或追踪目标随时都在变化,这就要求随时调整设备的运行方式。现实生活中这类现象比较常见,因此,在线预测的研究具有广阔的应用前景。
灰色系统理论中,灰色预测控制的原理具有极强的在线性。它采样瞬态建模,即每采集一个新数据同时舍弃一个最旧的数据,建立一个新模型,更新一组模型参数,所以控制的过程就是不断采集和舍弃数据、不断建模、不断更新参数、不断预测、不断提高新模型下预测值的过程,实际上也就是用模型参数的不断更新来适应系统行为的不断变化和外界环境的不断干扰,增强模型对环境的适应性。然而,灰色预测模型的精度一直是人们关心的重要问题。为了提高其预测精度,专家学者们进行了大量的研究,并取得了一些比较理想的成果[7,12,13]。
对于在线预测,国内外从在线核学习机的角度进行研究的专家学者不少,他们不仅研究了如何提高在线预测的精度,同时也考虑了如何降低计算代价,开发了许多在线学习的优良算法,并在理论与实践上获得了成功[2,4,11]。但是,目前尚未见到将灰色在线预测和支持向量机结合起来进行研究的文献。本文拟根据当前统计学习理论的研究成果,将在线自适应灰色预测与支持向量回归有机结合起来,对经济时间序列的在线预测精度和计算代价进行探讨。
1 在线自适应灰色预测模型






发展系数α1和灰作用量μ1的最小二乘估计由(4)决定

当新数据模式不断到达,采取以上方法不断构建模型,可得到模型序列:

式(5)称为在线自适应灰色预测模型,用OL-GM(Online-GM(1,1))来表示。
2 在线自适应灰色支持向量回归预测模型
灰色预测的精度一直是人们关心的问题。为提高在线自适应灰色预测模型的精度,可在每一模型的残差序列上运用支持向量回归机来修正残差以达到提高整个预测效果的目的。
2.1 支持向量回归(SVR)
支持向量机(Support Vector Regression,SVR)于20世纪90年代初提出,是建立在统计学理论最新进展基础上的新一代学习系统[3]。随着社会经济的迅猛发展,这种技术得到了深入研究和广泛应用。至今在许多应用领域中,支持向量机足以提供最佳的学习性能,而且在机器学习与数据挖掘中已被确立为一种标准工具。它利用核函数,将输入向量按预定的某一非线性变换映射到高维特征空间并构造线性函数的假设空间,然后在构造的假设空间中寻找最优假设。选择何种变换进而确定特征空间是支持向量机的关键,直接决定需要学习的目标函数的复杂程度,从而决定学习任务的难度以及学习机的泛化能力。支持向量机最初用于解决分类问题[1],后来成功应用于回归问题,特别在大样本经济数据的预测中应用广泛[6,8,14]。


对拉格朗日函数求偏导易知最优假设可以如下表示:


2.2 残差修正的支持向量回归方法
对于灰色预测模型,可在模型的残差序列上运用支持向量回归机来提高各模型的精度。根据模型(1)的拟合值和原始序列数据,可获得该模型的残差序列e0=(e0(1),e0(2),...,e0(n))。以模型值、原始值和数据所在时刻为三维输入样本,以残差值为输出样本构造支持向量回归机对灰色预测模型进行残差修正得到下列复合预测模型:是复合模型的最终预测值是由支持向量回归得到的残差修正项。是三维输入向量。



是新数据序列构建的复合模型的最终预测值;f1(ψ1(t))是由支持向量回归得到的残差修正项。是三维输入向量。
根据二次规划的KKT条件,只有部分ai或a*i取非零值,与之对应的输入向量称为支持向量。偏置项b可由下式计算:
当新数据继续到达,采取以上方法继续构建复合模型,可得到模型序列:

式(12)称为在线自适应灰色支持向量回归预测模型,用OL-GM-SVR(Online-GM(1,1)Support Vector Regression)来表示。
3 实证分析
为了检验OL-GM-SVR模型的精度并与OL-GM模型进行比较,本节将在两个数据集上进行试验。第一个数据集是某市1985~1994年各月工业生产总值(Monthly Gross Output Value of Industry,MGOVI),数据来源于文献[15](图1左),它包含120个数据点,本文中将其称为小样本数据集;第二个数据集是来自上海证券交易所的一支股票收盘价格的历史数据(SHDSP)(图1右),它包含1047个数据点,本文中属中大规模数据集。支持向量回归机均采用高斯径向基核(13):

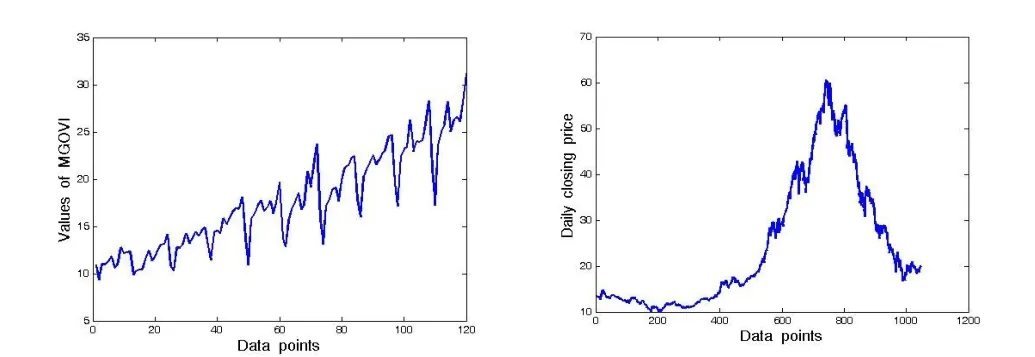
图1 试验原始数据(左:MGOVI;右:SHDSP)
为使结果可比,有必要设定测试集。对MGOVI,用后30个数据模式进行测试;对SHDSP,用后300个数据模式进行测试。对预测精度的度量,两个数据集均采用NMSE和MREB,计算方法如下:

为比较试验集中预测精度与稳定性,统一设定主要超参数。对MGOVI,取σ=50 ;对SHDSP,取σ=30.其他参数,根据试验情况进行调整以获得最佳性能。
试验主要考察OL-GM、OL-GM-SVR在数据集MGOVI和SHDSP上的预测精度与学习时间。在灰色建模时,由于选择不同的数据长度对模型的预测效果不同,同时考虑到过少的数据在进行误差支持向量回归中会导致过学习,因此,将数据长度范围设定为10≤n≤30,并选择n=10,15,20,25,30等5种情况的试验结果列于表1,同时,为了能直观地反映数据长度对预测效果的影响,在图2中作出了OL-GMSVR与OL-GM的预测效果(MREB)比较曲线。

图2 模型OL-GM-SVR与OL-GM预测效果比较
两数据测试集上试验结果表明:无论灰色建模数据长度n的值怎样选择,模型OL-GM-SVR的预测精度比OL-GM均有明显的提高,相应地,由于计算量的增大,模型OL-GM-SVR的计算时间也明显地增加。另外,对于模型OL-GM,选择灰色建模数据长度对预测精度影响比较明显。就n选择的范围而言,对于小规模数据集MGOVI,n的大小与精度的优劣没有明显的依从关系(图2左),且学习时间较少;从中大规模的数据集(SHDSP)来看,n越大,OL-GM的精度越低(图2右)。最后,OL-GM-SVR精度与灰色建模数据的长度选择关系不大,各数据集上精度比较平稳;但是,所耗费的学习时间随着n的增大而明显增多(支持向量回归中数据规模的增大从而导致计算量迅速增长)。

表1 OL-GM-SVR与OL-GM在测试集上的预测精度与学习时间
4 结论
现实系统的复杂性和可变性使在线自适应预测成为当今研究的一个热点。实际上,在线自适应预测更符合预测问题的本质,一边获取信息,同时运用以前的预测结果一边进行预测,这样才能适应新的变化和环境的不断干扰,增强预测技术对环境的适应性。
本文主要从预测精度和计算代价两方面讨论了经济时间序列数据的在线预测模式,提出了灰色在线自适应预测模型(OL-GM)和灰色在线自适应支持向量回归预测模型(OL-GM-SVR)。通过对两个真实经济时间序列数据进行试验,结果表明:模型OL-GM能以较快的速度对经济时间序列进行动态预测,灰色建模数据长度的选择对模型的预测精度有较大的影响;而模型OL-GM-SVR以较多的学习时间能获得预测精度的明显提高,在选取合适灰色建模数据长度情况下,学习时间能迅速减少,其预测精度比较平稳,受建模数据长度的影响较小。本研究为经济时间序列的在线预测问题提供了一种新的思路,所作研究不仅适应于经济预测领域,也可为其他相关预测提供参考。
[1]Burges C J C.A Tutorial on Support Vector Machines for Pattern Recognition[J].Data Mining and Knowledge Discovery,1998,(2).
[2]Cheng Li,Vishwanathan S V N,Schuurmans Dale,et al.Implicit Online Learning With Kernels[J].Advances in Neural Information Processing Systems,2006,(19).
[3]邓乃扬,田英杰.数据挖掘的新方法—支持向量机[M].北京:科学出版社,2004.
[4]He W.Limited Stochastic Meta-Descent for Kernel-Based Online Learning[J].Neural Computation,2009,21(9).
[5]He W,Jiang H.Implicit Update vs Explicit Update[C].In:Proceedings of the 2008 IEEE WorldCongress on Computational Intelligence,Hong Kong:IEEE,2008.
[6]Huang Z,Chen H,Hsu C,Chen W,Wu S.Credit Rating Analysis with Support Vector Machines and Neural Networks:A Market Comparative Study[J].Decision Support Systems,2004,(37).
[7]Jiang H,Wang Z.GMRVVm-SVR Model for Financial Time Series Forecasting[J].Expert Systems with Applications,2010,(37).
[8]蒋辉,王志忠.灰色局部支持向量回归机及应用[J].控制与决策,2010,25(3).
[9]蒋辉.王志忠.基于灰色系统的支持向量回归预测方法[J].经济数学,2009,26(2).
[10]Kim K.Financial Time Series Forecasting Using Support Vector Machines[J].Neurocomputing,2003,(55).
[11]Kivinen J,Warmuth M K.Exponentiated Gradient Versus Gradient Descent for Linear Predictors[J].Information and Computation,1997,132(1).
[12]Kivinen J,Smola A J,Williamson R C.Online Learning with Kernels[A].In T.G.Dietterich,S.Becker,and Z[J].Ghahramani,Editors[M].Advances in Neural Information Processing Systems,2002.
[13]Kivinen J,Smola A J,Williamson R C.Online Learning with Kernels[J].IEEE Transactions on Signal Processing,2010,100(10).
[14]梁庆卫,宋保维,吴朝晖.鱼雷使用维护费用灰色模型[J].系统与仿真学报,2006,(1).
[15]Sun J Z.The Grey Composite Prediction Based on Support Vector Regression[A]In:Proceedings of 2007 IEEE International Conference onGreySystems and Intelligent Services[M].Nanjing,China,2007.
[16]Tay F E H,Cao L J.Modified Support Vector Machines in Financial Time Series Forecasting[J].Neurocomputing,2002,(8).
[17]王振龙,顾岚.时间序列分析[M].北京:中国统计出版社,2002.
[18]熊和金,徐华中.灰色控制[M].北京:国防工业出版社,2005.
