基于浅层句法分析的中文语义角色标注研究
2011-06-14孙薇薇穗志方
王 鑫,孙薇薇,穗志方
(1. 北京大学 计算语言学研究所,北京 100871; 2. 萨尔布吕肯大学 计算语言语音学系,德国)
1 引言
近些年来,多种语言上的语义角色标注逐渐成为研究的热点。现有的中文语义角色标注系统一般基于完全句法分析,比如说Sun等[1]、Xue and Palmer[2]、Xue[3]的工作。但由于现有的中文完全句法分析器性能还比较低,基于自动的完全句法分析的中文语义角色标注效果并不理想。目前,基于手工标注句法树的语义角色标注系统的F值达到了0.92,但如果使用自动句法分析器时F值则降低到了0.71[3]。而在英文的语义角色标注系统中,这种变化则是从0.91[4]降低到了0.80[5]。这些数据表明,对于还处于研究初级阶段的中文语义角色标注任务来说,完全句法分析的性能成为影响其性能发展的一个主要因素。同时,我们还认识到完全句法分析的结果是句法树,从中提取的词语之间的句法关系并不一定是语义角色标注所必需的,而有些词语之间的关系分析并不准确,这样就给系统引入了噪音。
在英文中,目前已经有相关尝试将语义角色标注建立在浅层句法分析基础上,并取得了较好效果,如conll 2004共享任务、于江德[6]等。而在中文中,对浅层句法分析的研究也已经取得了一定进展[7],因此可以成为中文语义角色标注的另一种解决思路。
本文将中文语义角色标注建立在浅层句法分析的基础上,首先实现了一个基于组块的浅层句法分析器,而后进行语义角色标注。在句法分析阶段,根据汉语自身特点利用构词法获得词语的“伪中心语素”来模拟词语的中心语素,有效缓解了数据稀疏问题,提高了句法分析器的性能。在语义角色标注阶段,利用构词法获得了目标动词的语素特征,从动词内部结构的角度对动词的特征进行描述。此外,本文还提出了“粗框架”特征来模拟完全句法分析所提供的“子类框架”特征,这种特征是对句子中论元搭配关系的一种新的描述形式。
本文以正确的切词和词性标注结果作为系统输入,在浅层句法分析后,采用两种不同的标注策略即分步标注法和直接标注法完成了语义角色标注,并且都取得了很好的实验效果,其中直接标注法得到的F值达到了0.74。这个结果比现有最好的基于自动完全句法分析的语义角色标注系统的性能(0.71)[3]有较明显的提高。分步标注策略下,系统的召回率是0.71,这个效果同样要明显优于现有的具有最高召回率的语义角色标注系统(0.65)[3]。
2 基于构词法的中文浅层句法分析方法
2.1 浅层句法分析的基本原理及基本特征
本文采用Chen等[7]的组块定义方法,即定义了12种类型的组块,分别为形容词短语(ADJP)、副词短语(ADVP),类别型词语(CLP),“的”字型短语(DNP)、限定型短语(DP)、“得”字型短语(DNP)、地点型短语(LOC)、列表标记(LST)、名词短语(NP)、介词短语(PP)、数量词短语(QP)、动词短语(VP)。结合IOB2表示法,本文将浅层句法分析问题转化为了序列标注问题,参照Chen等[7]选取的特征作为本文实验的基线特征,具体包括:
一元文法的词语和词性特征: w-2,w-1,w,w+1,w+2
二元文法的词语和词性特征: w-2-w-1,w-1-w,w-w+1,w+1-w+2
2.2 构词法信息在浅层句法分析中的应用
2.2.1 构词法信息概述
汉语中最大的语法单位是句子,比句子小的语法单位依次是短语、词、语素。构词法是指由语素构成词的法则,是对既成词的结构作语法分析,说明词内部结构中语素的组成方式。在构词法理论中,词语可分为单纯词和合成词,单纯词由一个语素构成,而合成词有两个或者两个以上语素构成,这些语素构成词语的方式又有多种,包括偏正、主谓、述补等等。例如“播音”属于合成词,其构词方式属于述宾式;“扩大”也属于合成词,其构词方式则属于述补式。
在丰富的构词信息中,目前我们观察到可以利用其中的语素信息对句法分析以及语义角色标注产生帮助。汉语中多数情况下,一个字便构成了一个语素,因此词语可以由多个不同的语素构成,例如“进来”由一个动词中心语素“进”和补语语素“来”构成,“喝水”由一个动词中心语素“喝”和宾语语素“水”构成。而在英语中,词语由字母构成,字母往往不具有单独的含义,因此,英语中的语素单位以及相应的构词法特征没有汉语这样明显和普遍,本文将汉语构词法特征中的语素信息运用到浅层句法分析以及后续的语义角色标注阶段中,并且取得了较好的效果。
2.2.2 可应用于浅层句法分析的构词法特征及其获取方法
一般而言,在合成词中,两个语素的语法地位是不同的,在语法结构中处于中心地位的构词成分称作“中心语素”,在语法结构上处于修饰、补充、说明等次要地位的构词成分(如状语语素,补语语素等)称作“附加语素”。中心语素对于词语句法特征以及语义的表达都起着极其重要的作用。比如“乒乓球”“羽毛球”和“篮球”,这三个词语都有相同的中心语素“球”,当把“球”作为一个特征项时,其统计信息的显著性就会得到增强,从而缓解了句法分析过程中的数据稀疏问题。
汉语中语素构成词语的形式多种多样,包括主谓结构、述宾结构、定中结构等,对于任意一个词语,通过自动的方法准确判定其构成方式,进而分析得到其中心语素是比较困难的。在汉语中名词和动词是最常使用的词语类型,从方便实现的角度考虑,本文提取名词和动词的“伪中心语素”来模拟其中心语素,作为新特征来为句法分析提供更多信息。
对于名词,本文选取其最后一个字作为其伪中心语素,因为据部分统计,名词中约有80%以上属于偏正式的构词方式。对于动词,本文选取首字作为其伪中心语素,原因在于动词中最常见的是动宾、并列、述补三种结构,而在这些结构中动词的第一个字在表达动词句法特征和语义时都起到了关键性的作用。例如 “指出”、“指明”和“指挥”,其第一个字在语法结构中都处于了中心地位。
因此,在中文浅层句法分析阶段,在2.1节提出的基线特征基础上,根据汉语的特点,本文增加名词和动词的伪中心语素作为新特征。
3 基于浅层句法分析的语义角色标注
3.1 基于浅层句法分析的语义角色标注的基本原理和结构
本文采用两种不同的策略实现了语义角色标注。一种是分步标注法,即首先进行论元识别,确定论元边界,然后进行分类,对选定的论元标注角色。另一种是直接标注法,即将识别和分类过程合并,直接对句法组块标注语义角色。
在不同的标注策略下,本文都首先运用一些在角色标注系统中被广泛使用的特征作为基线特征,而后在基线特征的基础上加入新特征来提高系统的性能。
3.2 基线特征
为了更好地发挥标注策略本身的特点,本文在不同的标注策略下使用了不同的特征集。
表1列出了直接标注法的基线特征集合,包含以下四个方面: 句法组块、目标动词、句法组块和目标动词之间的联系[10]以及以上三方面特征构成的组合特征。
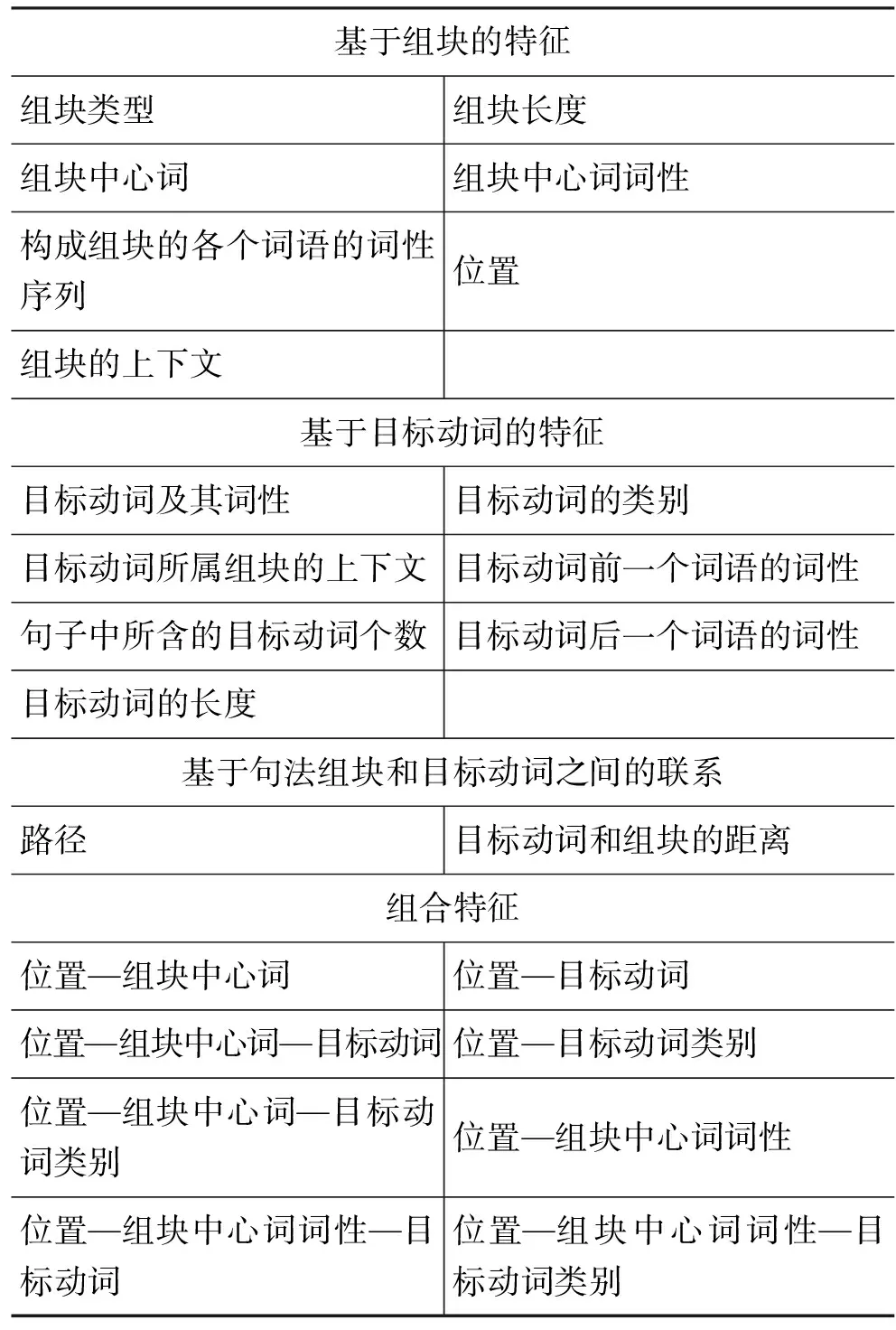
表1 直接标注法基线特征集合
对于分步标注法,其识别阶段所用的特征与直接标注法相同,而对于分类阶段,由于其任务目标与识别阶段不同,而且还可以利用识别阶段所得到的结果,因此采用了不同于识别阶段的特征。表2列出了分步标注法下分类阶段的基线特征集合。
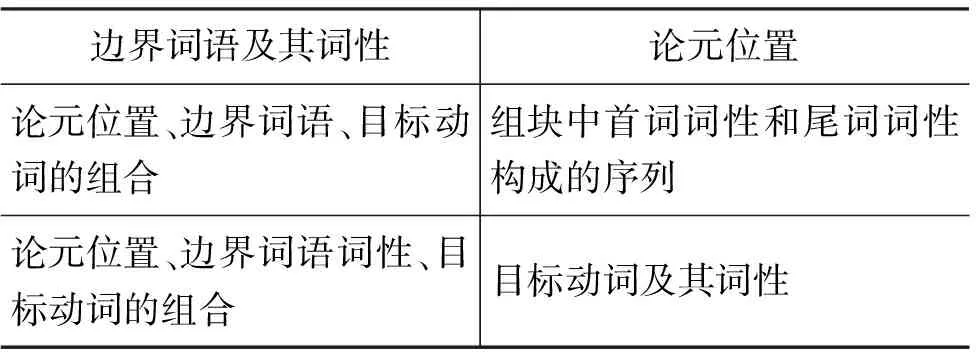
表2 分步标注法分类阶段基线特征集合
3.3 语义角色标注中的新特征
3.3.1 动词语素特征在角色标注中的运用
动词在语义角色标注过程中起着重要的作用,构成动词的语素类型也是多样的,比如中心语素,状语语素,补语语素,宾语语素等。宾语语素是动词中心语素的支配对象,如“打字”中的“字”。补语语素是对动词中心词素起补充说明作用的成分,如“超过”中的“过”。状语语素是修饰限定动词中心语素的成分,如“不够”中的“不”。在语义角色标注中,如果充分利用动词的这些语素特征,则可以更好地发挥动词对于句子中论元数量以及搭配特征的暗示作用,为角色标注提供更多依据。例如,如果在语义角色标注时知道“理发”中“理”是动词中心语素,“发”是“理”的宾语语素,作为“理”的受事,则已经在很大程度上暗示了“理发”所在的句子中不会有其他的受事。
因此,对于每个动词,在语义角色标注中希望获得该动词的中心语素和附加语素作为特征。本文采用了一种基于语素集的方法来获得目标动词的中心语素以及附加语素(状语语素、补语语素、宾语语素之一)。
通过对语料的观察,本文事先归纳了一些出现频率较高的语素,分别构成状语语素集(A),宾语语素集(O)和补语语素集(C)。其中状语语素集中的语素一般出现在状语-动作结构的动词中,起修饰作用;宾语语素集中的语素一般出现在动作—宾语结构中;补语语素集中的语素一般是动作—补语结构的补语部分。表3列出了训练语料里出现频度较高的二字目标动词所包含的附加语素(括号中是语素出现的频度,训练语料中两字目标动词的频度总计21 669,同一个动词在不同句子中出现则频度加一)。
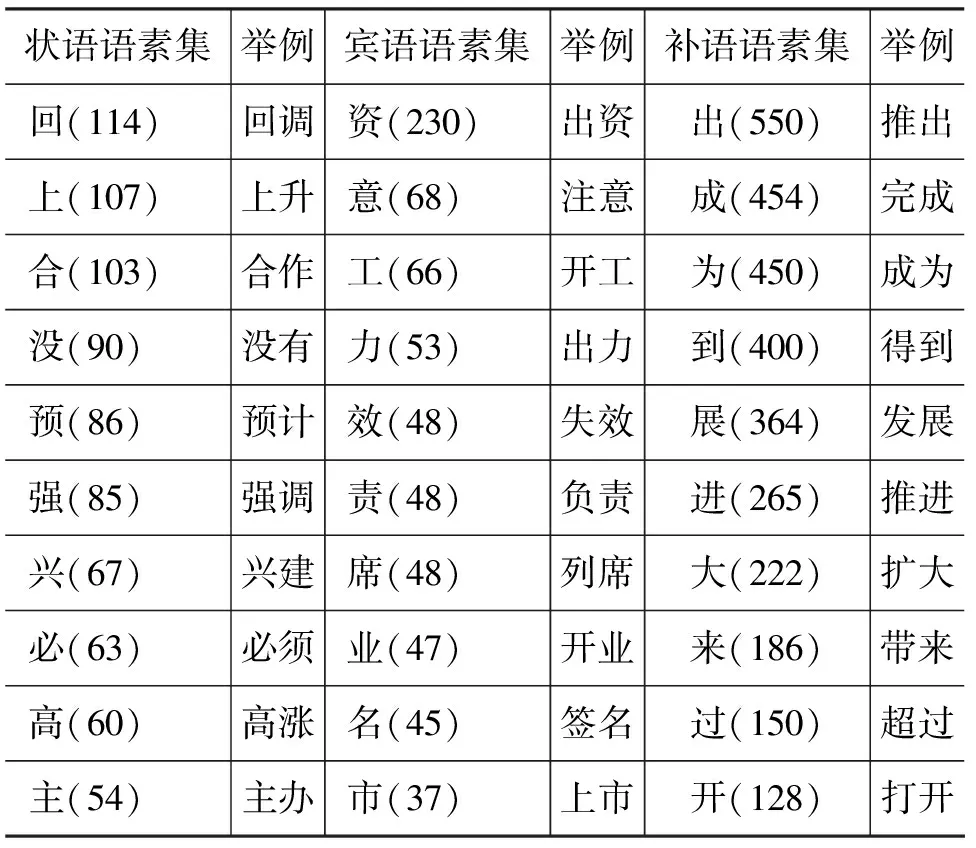
表3 不同语素集合中的典型语素举例
这种基于语素集获得目标动词中心语素以及附加语素的方法具体而言,就是在角色标注阶段,根据每个目标动词的字数,各个字的位置,字所属的语素集合得到构成这个动词的语素类型。令W为输入的目标动词W= C1…Cn,N代表其包含的字数,输出为中心语素h, 状语语素a, 补语语素c以及宾语语素o,提取动词语素的方法如下所示。
h=c=a=o=null
If N=4 and C1=C2and C3=C4then return Verb formation of W'= C1C3;
Else if N =3 and C2=C3then return h=C1, c= C2;
Else if N =2 and C1=C2then return h=C1;
Else if Cn∈C return h=C1..n-1,c= Cn
Else if Cn∈O return h= C1..n-1, o= Cn
Else if C1∈A return h= C2…Cn,a= C1
Else return h=C1;
当要提取某个动词的构成语素时,需要判定动词的首字和尾字所属的语素集合,如果首字或尾字属于某个附加语素集合,则令这个匹配到的字作为附加语素,剩下部分作为中心语素。例如对于“建成”,“成”出现在动词的末尾,并且属于补语语素集,因此“建成”的补语语素是“成”,中心语素是“建”。另外,由于并列结构也是汉语动词所常见的结构形式(如“签署”),也就是说动词的首字和尾字都没有包含在附加语素集合中,此种情况下,本文按照2.2.2节中的处理方法,提取动词的第一个字作为其中心语素,附加语素标记为空“-”。 此外,由于动词中所含的字数不同,本文根据动词构词上的特点,也进行了针对性的处理。例如对于长度为3的词语并且是叠词,如第二个和第三个字相同,则可以认为这个词由中心语素与补语语素构成。例如“笑哈哈”,可以分析得到中心语素是“笑”,补语语素是“哈”。
3.3.2 粗框架特征在角色标注中的运用
在完全句法分析中,从句法树上提取的子类框架特征,即由动词本身、动词父亲以及动词兄弟组成的信息,由于其有效表示了论元之间句法配置关系,因此对于语义角色标注是很重要的。在浅层句法分析中,由于没有完全句法分析的句法层级信息,不能直接获得子类框架。在基于浅层句法分析的语义角色标注中,需要寻找一种特征可以尽量模拟子类框架所要描述的论元之间、论元和动词之间的搭配信息。这种特征的有效性,可以从一个侧面反映将语义角色标注建立在浅层句法分析基础上的可能性。我们发现在浅层句法分析结果中可以提取一种“粗框架”特征,即由识别阶段所得的论元以及目标动词组成的序列。例如在句子“团委召开会议”中,目标动词是“召开”,子类框架可以表示为VP—>VV、NP;当候选目标论元为“会议”时,粗框架为XP+VV+!XP,其中第一个XP表示“团委”,VV表示“召开”,!XP表示“会议”。这样的信息本质上已经反映了子类框架所要描述的论元之间、论元和动词之间的搭配信息,因此可以较好地逼近子类框架特征,后面的实验结果也说明了这一点。
表4列出了角色标注阶段加入的新特征,具体包括语素类特征(中心语素和附加语素)以及“粗框架”类特征两个方面。其中语素类特征被用到了直接标注法、分步标注法的识别和分类阶段,粗框架类特征则被用到了分步标注法的分类阶段。

表4 角色标注阶段的新特征集合
4 实验分析
4.1 实验设置
4.1.1 数据
本文选择CPB1.0和CTB5.0作为实验的基本数据。这些数据被分为三部分: chtb_081—chtb_899作为训练集,chtb_041—chtb_080作为开发集,chtb_001—chtb_040以及chtb_900—chtb_931作为测试集。这样的数据设置方法与Xue[3]相同。同时,本文采用conll-2005共享任务提供的srl-eval脚本从三个方面即准确率、召回率和F值来对系统性能进行评测。
4.1.2 分类器
在浅层句法分析、直接标注法以及分步标注法的识别阶段,本文选用Tiny SVM以及YamCha软件包(Kudo and Matsumoto[8-9])。参数设置为核函数d=2,采用配对(pair-wise)方法解决多分类问题。对于分步标注法的分类阶段,本文选用线性的SVM分类器SVMlin,采用一对多方法解决多分类问题。
4.2 浅层句法分析实验结果
表5中第一行是实验的基线结果,即采用Chen[7]所提到的特征时的实验结果。第二行是加入“伪中心语素”特征之后的测试结果,从而证明了词语的语素信息对于浅层句法分析的积极意义。这样的效果已经与目前在英文上基于组块的句法分析的最好系统效果(F=0.94)相当。虽然由于语言种类不同,组块的定义方法不同,测试集合上的数据量不同等,单纯的数值比较并不十分公平,但这样的结果已经说明了系统所采用的基于组块的浅层句法分析方法的有效性。
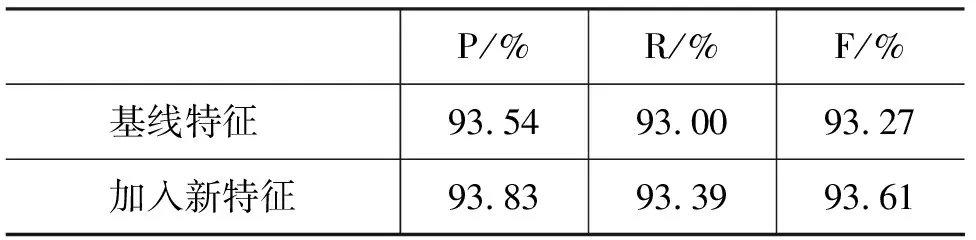
表5 浅层句法分析过程中的性能比较
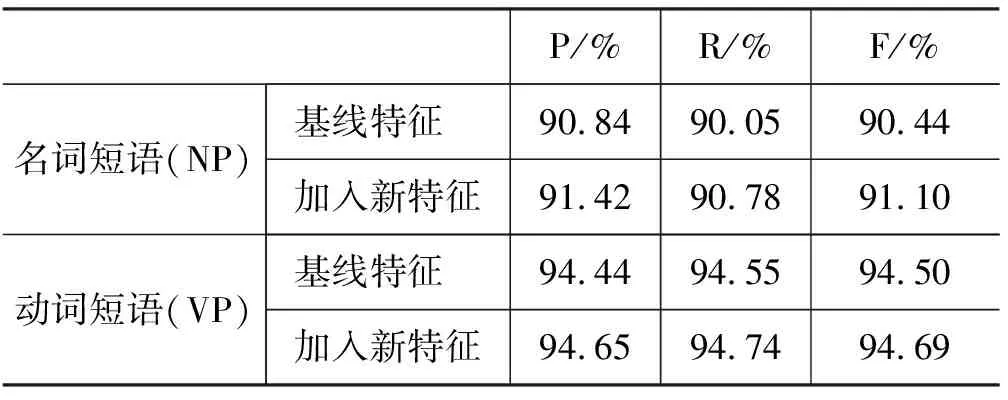
表6 名词短语和动词短语的句法分析评测结果
在汉语中存在着大量的名词短语和动词短语,表6列出了系统在这两种类型短语组块上的测试结果。结果表明,语素特征对于名词短语的标注任务会更有帮助,而对于动词短语的标注所起到的促进作用不是很明显。其中部分原因可能是因为许多标注错误是由于动词短语对句子中其他成分的长依赖关系造成的,这种情况下作为局部特征的语素特征的加入对于标注很难起到有效的促进作用。比如有以下两个句子:
[VP因此获得胜利]
[ADVP因此][VP大量出现]的是以前不曾遇到的
这两个句子中“因此”的上下文是相似的,而在第二句话中只有分类器知道“因此”后面是一个从句才能正确地标注出“因此”的短语标志“ADVP”,这样的信息是语素特征所没能提供的,因此加入语素特征后对于正确识别出“因此”的句法功能没能起到明显的作用。
4.3 直接标注法实验结果
表7列出了在加入目标动词语素类特征前后直接标注策略下系统的性能变化。可以发现,语素类特征对于系统性能的提高主要表现在召回率上,这也再次验证了语素特征在缓解数据稀疏问题上的作用。

表7 直接标注法中语素类特征对系统性能的影响
4.4 分步标注法实验结果
表8列出了在加入粗框架类和语素类特征前后分步标注策略下系统准确率的变化。可以发现,新特征的加入使标注效果无论在开发集上还是在测试集上都得到了提高。粗框架类特征有利于更有效地利用识别阶段的标注结果,由于其提供了一种句子整体结构上的信息,因此使标注效果得到了明显的提高。

表8 分类阶段粗框架类和语素类特征对系统性能的影响
4.5 实验总结
表9列出了两种不同策略下的角色标注系统以及现有最好的基于自动句法分析的角色标注系统的性能。可以看出,无论是直接标注法还是分步标注法,得到的标注效果都优于现有的基于自动句法分析的最好角色标注系统, 这就验证了基于浅层句法分析的语义角色标注系统的有效性。
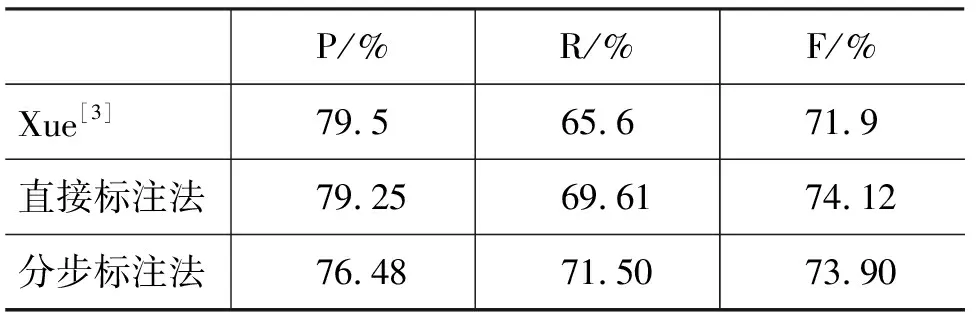
表9 角色标注实验结果
观察可以发现,两种不同的标注策略在F值上并没有太大差别。相比而言,直接标注法取得了更高的精确率,分步标注法则有更高的召回率。这可能是因为分步标注法的识别阶段可以更有效地区别论元和非论元,因而识别出了更多的论元,提高了召回率。表中第一行是Xue[3]在完全句法分析基础上角色标注的实验结果。比较可以发现这个结果在精确率上有很好的表现,这可能是因为其充分利用了句法树上各个句法成分之间的关系,得到了对角色分类更加有效的特征,因而可以更加准确地分辨角色类型。
5 结束语
本文搭建了一个基于浅层句法分析的中文语义角色标注系统,比现有最好的基于自动完全句法分析的语义角色标注系统的性能(0.71)[3]有了明显提高。具体而言,本文首先构造了一个拥有较高性能的句法分析器,在此阶段根据汉语自身特点尤其是构词法,提取了名词和动词的伪中心语素特征来缓解数据稀疏问题;在语义角色标注过程中,提取了目标动词语素特征和粗框架等,有效描述了句子中论元之间以及论元与动词之间的搭配关系。实验结果表明,基于浅层句法分析的角色标注方法为中文语义角色标注提供了一种新的解决思路,同时本文所提取的语素特征以及粗框架等对于提高整个语义角色标注系统的性能起到了很好的促进作用。
[1] Sun, Honglin, Daniel Jurafsky. Sha1low Semantic Parsing of Chinese[C]//Proceedings of the Human Language Techno1ogy Conference 0f the North American Chapter of the Associati0n for Computational Linguistics.Bnston. USA: 2004.
[2] Nianwen Xue and Martha Palmer. Automatic semantic role labeling for Chinese verbs[C]//Proceedings of the 19th International Joint Conference on Artificial Intelligence, 2005.
[3] Nianwen Xue. Labeling Chinese Predicates with Semantic roles [J]. Computational Linguistics, 2008,34(2):225-255.
[4] Sameer S. Pradhan, Wayne Ward, and James H. Martin. Towards robust semantic role labeling[J]. Comput. Linguist. 2008,34(2):289-310.
[5] Mihai Surdeanu, Lluís Mrquez, Xavier Carreras, and Pere Comas. Combination strategies for semantic role labeling. J. Artif. Intell. Res. (JAIR)[J]. 2007,29:105-151.
[6] 于江德,樊孝忠,庞文博,余正涛. 基于条件随机场的语义角色标注[J]. 东南大学学报, 2007, 23(3):361-364.
[7] Wenliang Chen, Yujie Zhang, and Hitoshi Isahara. An empirical study of chinese chunking[C]//Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions. Sydney, Australia:2006: 97-104.
[8] Taku Kudo and Yuji Matsumoto. Use of support vector learning for chunk identification[C] //Proceedings of the 2nd workshop on Learning language in logic and the 4th conference on Computational natural language learning. Morristown, NJ, USA.:2000: 142-144.
[9] Taku Kudo and Yuji Matsumoto.Chunking with support vector machines. [C]//NAACL ’01: Second meeting of the North American Chapter of the Association for Computational Linguistics on Language technologies 2001, Morristown, NJ, USA:2001:1-8.
[10] 刘怀军,车万翔,刘挺.中文语义角色标注的特征工程[J].中文信息学报, 2007,21(1):79-84.
