基于网络设备的网页过滤的设计
2011-05-22文敬斌杨忠孝
文敬斌,杨忠孝,孙 林
(①电子科技大学自动化工程学院,四川 成都 611731;②迈普通信技术股份有限公司研究院,四川 成都 610041)
0 引言
在网页过滤技术中,URL过滤是普遍采用的过滤方式,因为其设计实现非常简单,速度快、效率高;但是互联网是动态的,每天有数以万计的新的网页出现,URL名单的更新速度往往跟不上;如果单纯的采用URL过滤,会造成过滤的遗漏[1-2]。
内容过滤能够实现实时的网页内容防护,过滤比较准确,但是因为内容过滤过程比较复杂,处理量如果过大,会造成用户上网的明显延迟。
设计的方法是基于网络层的网页过滤方法,在网络设备上实现对网页的过滤。采用URL过滤与内容过滤相结合的方式,取安全与性能的折中。
1 网页过滤总体框架
一台主机要访问Web服务器,首先与Web服务器进行三次握手,建立TCP连接;然后向Web服务器发送请求报文,其中包含用户访问的URL,Web服务器在收到请求报文后,会发送应答报文给客户主机,因此过滤流程框架可按如下设计:
①在网络设备中监听用户的数据包,检测到 HTTP请求报文[3],则分析该报文中嵌入的网页地址信息(即URL),提取出URL信息,对其进行在黑白名单中进行匹配分析,根据匹配结果给予是否通过;
②内容过滤采用“第一次放过”的策略,即第一次对未知 URL的返回报文仅做内容检查。收集服务器返回的 HTTP响应报文,提取出应用层信息,组成完整的 HTML文档,进行内容过滤,根据判定结果进行相应的操作,整体过滤步骤如图1所示。

图1 过滤模型
2 URL过滤
2.1 相关定义
白(黑)名单:在该名单中的 URL,必定是合(非)法的地址信息;未在该名单中的网址的合法性未知。
2.2 黑白名单机制的设计
URL过滤框架的设计是基于两个事实:
①因特网统计表明,超过 80%的用户经常访问的是 20%的网页内容;
②大多数用户在多数时间内访问的是合法信息的网页。
基于上述事实一,设计白名单时,仅存放经常访问的合法网站地址信息。这样设计可以保证在进行URL匹配时,能够快速高效地判断该网页地址是否在高频白名单中。对于一段时间内访问频率不高的网页,采用老化机制将其从名单中移除。
基于上述事实二,设计将URL白名单放在黑名单之前,若采用黑名单在前的方式,将会浪费大量时间去查找黑名单,而在大多数时间内,这些查找是不必要的。
2.3 URL过滤
URL过滤过程有:
①检测通过网络设备的报文,发现是HTTP的GET方法请求报文,提取其中携带的URL信息,若与高频名单中的条目匹配,表示该URL为合法,给予通过,并将该条目的统计计数加1;
②若在白名单中没有匹配,则继续和黑名单中的条目进行匹配。如果匹配成功,则断开该TCP链接,并且该匹配条目的统计计数加1;
③若匹配失败,则进行内容,根据内容过滤的结果将URL添加到相应名单中。
2.4 黑白名单老化机制
黑白名单老化机制步骤如下:
①计算名单中URL条目访问次数的平均值M,计算公式如公式1:
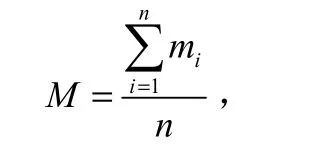
其中n为表中的URL条目数,im为第i个条目的统计计数值;
②将老化阈值设为该平均值;
③遍历所有的URL条目,检查每个URL条目的统计计数,若高于老化阈值,则将其保留在名单中,并且将统计计数值0,如果低于老化阈值,则将其剔除。
3 内容过滤
3.1 响应报文的获取与重组
由于网络的复杂性,返回的 HTTP响应报文可能不是有序的到达网络设备的,因此在网络设备上需要对到达的响应报文进行有序的重组。根据请求报文的五元组信息,收集该请求对应的HTTP响应报文;由于可能乱序,根据ACK字段和Seq字段对报文进行排序重组。在重组中建立的数据结构图2所示。
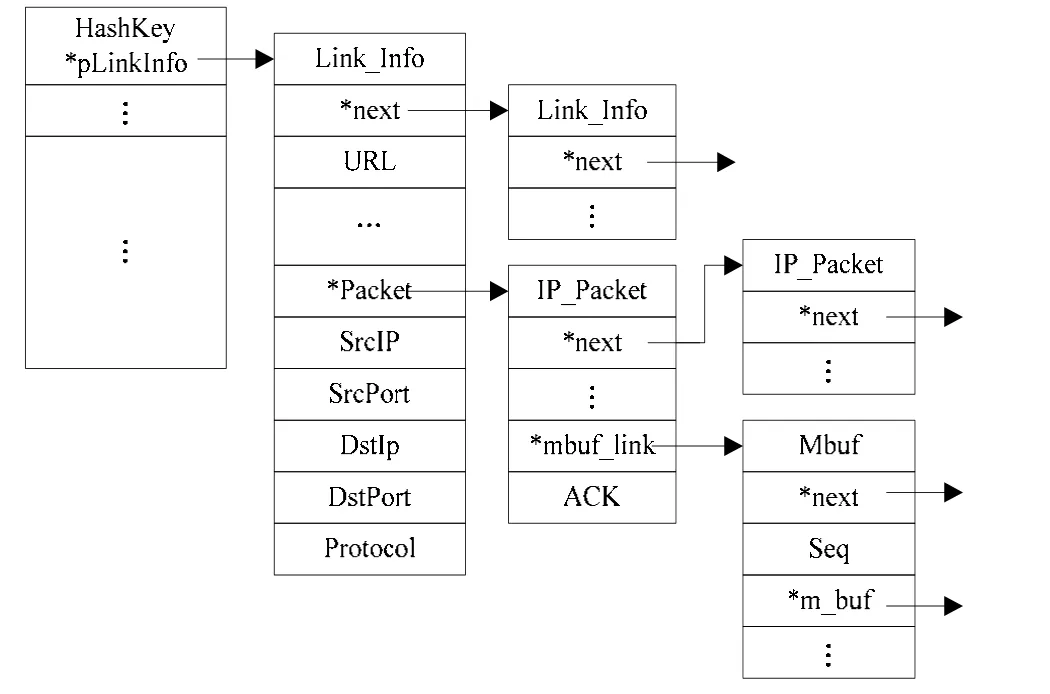
图2 重组使用的数据结构
3.2 文本的表示
目前常用的文本表示模型有许多种,常用的有:布尔逻辑模型、概率模型和向量空间模型等。在向量空间模型,文本内容被形式化为多维空间中的一个点,把对文本内容的处理简化为向量空间中向量运算,使问题的复杂性大为降低。权重的计算既可用规则的方法手工完成,又可通过统计的方法自动完成,便于融合统计和规则两种方法。
向量空间模型用项的向量空间来表示文档信息,项是指用来表示文档内容特征的基本语言单位(字、词、词组或短语等),也称为特征词,文档可以用项的集合来表示。一个网页可以由特征以及其权值表示[4],如下

其中ix为文本向量空间中的一个特征,iw为该特征的权值。
3.3 特征的选取
一个文本携带大量的信息,基于计算的复杂性考虑,只能在文本信息中提取出其中一些比较重要的特征;并且对于实际的性能要求,文本中的关键信息足以反映一个文本特征。像一个文本中出现的“的”、“有”等一些词是一些通用词,不能体现某些文本的特征,因此需要事先对文本进行预处理,去除掉这些词。
3.4 TF-IDF权值计算
TF-IDF计算公式:
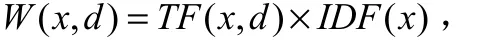
其中 TF( x, d)表示特征x在网页d中出现的频率,I D F( x)表示为,N是总共的训练样本数, d f( x)为包含特征x的样本数。
3.5 改进的权值计算公式
从TF-IDF计算公式可以看出,TF-IDF计算公式是将一个样本简单的分解为若干特征,只是针对文本的内容,没有从文本的结构组成上考虑各特征的权值。
[5-6]。考虑到HTML的这种结构化特性,对TF-IDF权值计算进行一些改进。
以下是设计的一个简单的位置——权值等级对应表,权值的选择可由实际情况具体而定。

表1 特征位置与权值对应表
一个词在一个网页中出现的频率越高,表示该词在这个网页中更重要。根据 IDF,一个词的重要与包含它的网页数量成反比。一个特征x在第i个等级中的频率如下表示:

其中xiN 表示某个词x出现在等级i中间的次数,xN 表示词x出现在该网页中总的次数。
权值的计算

其中iW为特征等级为i时,对应的加权系数。
3.6 KNN算法
K-近邻法的原理:在训练样本集中,找出与待分类的网页相邻最近的K个训练样本,找出K个近邻中样本数最多的类别c,就判断待分类样本为c类。这里采用相似度作为计算距离的依据,相似的计算根据两个样本之间的夹角的余弦值来判断。

根据此公式,计算出待测样本 x与所有训练样本的距离,从而找出与x距离最近的K个训练样本,根据这K个样本的所属类别,确定待测样本x的所属类别。
3.7 内容过滤流程
为了不给用户造成比较明显的延迟,采用“第一次放过”的策略。先并不拦截该响应报文,只是复制一份应用层信息,在整个响应报文传输完成之后,对复制的一份完整报文进行内容过滤操作;如果判断报文内容是非法的,则将对应的请求报文的 URL信息添加到黑名单中,如果检查认为是合法的,则允许该连接持续,并将URL信息添加到白名单中。
4 结语
通过实验分析,在过滤时间上,URL过滤阶段白名单匹配速度提高了53%,在黑名单的匹配中,速度提高了80%。在内容过滤阶段,由于采用的“第一次放过”策略,不会给用户带来延迟。既能在一定程度满足网络延迟的要求,又能改善用户的互联网环境。但仍然存在一些需要改进的地方:该过滤系统是部署在网络设备之上,网络设备作为网络节点,担负着繁重的数据交换任务,考虑到这些,没有对返回的报文进行实时的分析,而是采用“第一次放过”的过滤策略;此外,采用向量空间模型来表示,其缺点在于特征项之间线性无关的假设,因此可以考虑特征项之间的关联性等,对该文本表示模型进行更加精确的表示。
[1]刘辉,秦耕,王发茂.分布式网络信息过滤系统研究与实现[J].通信技术,2008,41(02):52-53.
[2]关超,蒋建中,郭军利. 基于姿态模型的图像内容过滤防火墙的研究[J].通信技术,2009,42(02):244-246.
[3]FIELDING R, GETTYS J, FRYSTYK H. Hypertext Transfer Protocol-- HTTP/1.1.RFC2616[S]. [s.l.]:The Internet Society,1999.
[4]XUE Linshi, YING Zhao, XIANG Jundong.Web Page Categorization Based on k-NN and SVM Hybrid Pattern Recognition Algorithm[R].China:Fifth International Conference on Fuzzy Systems and Knowledge Discovery,2008:523-527.
[5]MA Dan, WANG Hanhu, CHEN Mei. A Two-level KNN based Teaching Web Pages Classification Model[R].China: International Conference on Networking and Digital Society,2009:190-193.
[6]XUE Weimin, HUANG Weitong, LU Yuchang. Web Page Classification Based on SVM[R]. China:Proceedings of the 6th World Congress on Intelligent Control and Automation,2006: 6111-6114.
