决策树分类的属性选择方法的研究
2011-05-15王会青陈俊杰侯晓晶
王会青,陈俊杰,侯晓晶,郭 凯
(太原理工大学计算机科学与技术学院,太原030024)
分类是数据挖掘中一种重要的分析方法,通过学习训练集构造一个分类函数或分类模型,利用分类函数或模型对测试数据集进行分类[1]。分类可用于预测,预测的目的是从历史数据记录中自动推导出对给定数据的趋势描述,从而能对未来数据进行预测。目前分类算法主要有决策树方法、神经网络方法、统计方法等[2],不同方法会产生不同的分类器,分类器的优劣直接影响数据挖掘的效率与准确性。决策树方法是一种经典的分类算法,具有较好地处理缺省数据及带有噪声数据的能力。
ID3算法是由Quinlan提出的一种基于信息熵的决策树学习算法[2]。该算法以信息论为基础,把信息熵作为选择测试属性标准,对训练实例集进行归纳分类。但是在选择测试属性时,ID3算法往往偏向于选择取值较多的属性,而属性值较多的属性却不一定是最优的属性[4]。为了克服ID3算法在选择属性中存在的缺点,引入OneR算法来选择相关属性子集,降低无关属性或重复属性在分类中的影响,优化分类结果。
1 ID3算法
在决策树归纳方法中,通常使用信息增益方法来帮助确定生成每个结点时所应选择的合适属性。该方法选择具有最高信息增益的属性作为当前结点的测试属性,使划分后的训练样本子集进行分类时所需要信息最小,利用该属性划分当前样本集合,使得所产生的每个样本子集中的“不同类别混合程度”降为最低。ID3算法的基本原理为[5]:
设样本集S是s个数据样本的集合,假定有m个不同类Ci(i=1,2,…,m),si是Ci类的样本数,对样本集S所期望的信息值I(s1,s2,…,sm)为:
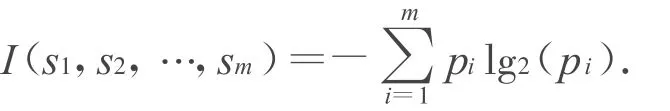
式中,p i是任意样本属于Ci的概率:si/s。
设属性A有v个不同值{a1,a2,…,av},利用属性A可以将样本集S划分为v个子集{S1,S2,…,Sv},其中,Sj包含S中属性A上具有aj值的样本。如果属性A被选为测试属性,则这些子集对应有包含集合S的结点生长出来的分支。
设sij是Sj中Ci类的样本数,则由属性 A划分成子集的熵为:
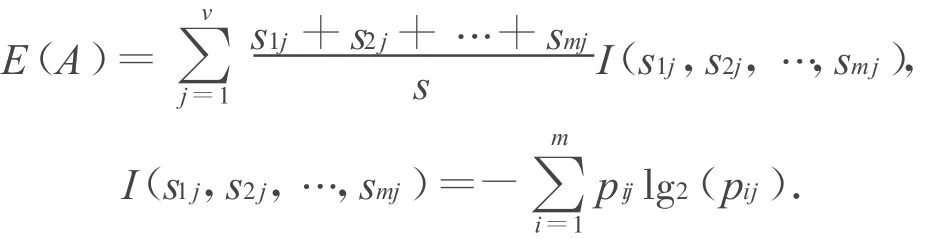
式中,p i,jw为子集Sj中任一个样本属于类别Ci的概率。
根据期望信息和熵值可以得到相应的信息增益值,因此属性A上的分支获得的信息增益值为:
Gain(A)=I(s1,s2,…,sm)-E(A)
ID3算法采用自顶向下的搜索可能的决策空间,以信息增益作为选取最佳属性的度量标准,实现对数据样本的归纳分类。
详细算法[6]描述如下:
输入:训练样本,各属性均取离散数值,可共归纳的候选属性集为:attribute_list;
输出:决策树。
处理流程:
1)创建一个结点N;
2)若该结点中的所有样本均为同一类别C,则返回N作为一个叶结点并标志为类别C;
3)若attribute_list为空,则返回N作为一个叶结点并标记为该结点所含样本中类别个数最多的类别;
4)从attribute_list选择一个信息增益最大的属性test_attribute;
5)并将结点N标记为test_attribute;
6)对于test_attribute中每一个已知取值ai,准备划分结点N所包含的样本集;
7)根据test_attribute=ai条件,从结点N产生相应的一个分支,以表示该测试条件;
8)设si为test_attribute=ai条件所获得的样本集合;
9)若si为空,则将相应叶结点标记为该结点所含样本中类别个数最多的类别;
10)否则将相应的叶结点标记为Generate_decision_tree(si,attribute_list,test_attribute)返回值。
2 属性选择
由于ID3算法要处理多个属性,其中部分属性是无关或者重复属性,因此需要进行属性选择,忽略无关或者重复属性,提高ID3算法的分类性能。本文在ID3算法中引入OneR算法,使生成决策树时属性值较少的属性不会被属性值较多且并不重要的属性淹没,最终使决策树减少了对取值较多属性的依赖性,从而尽可能地减少大数据掩盖小数据的现象发生,解决ID3算法偏向于取值较多属性的偏置问题。
OneR算法是一个简单分类算法,其基本思想是对数据集中的每个属性创建一个单层的分类器,然后比较每个属性在训练集上所有分类器的错误率,最终选择分类效果最好的分类器作为分类策略,其处理流程[7]为:
For每一个属性A
For属性的每个取值VA,按如下方式产生规则:计算属性的每个取值在每一类中的样本数找出每个取值中样本数最多的类别Cmax
产生规则:if A=VA,类别=Cmax.
End For
计算所有规则的错误率,
End For
选择错误率最小的规则。
3 实验与分析
实验以开源的数据挖掘平台Weka中分类平台和UCI数据集为基础。Weka是基于JAVA的工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理、分类、回归、聚类、关联规则以及在新的交互式界面上的可视化。在决策树算法中,决策树的复杂度和分类精度是需要考虑的两个最重要因素。常用的评价指标有:模型准确性和预测准确性,描述分类模型准确预测新的或未知的数据类的能力。
实验1 采用气候训练集[8],如表1所示。
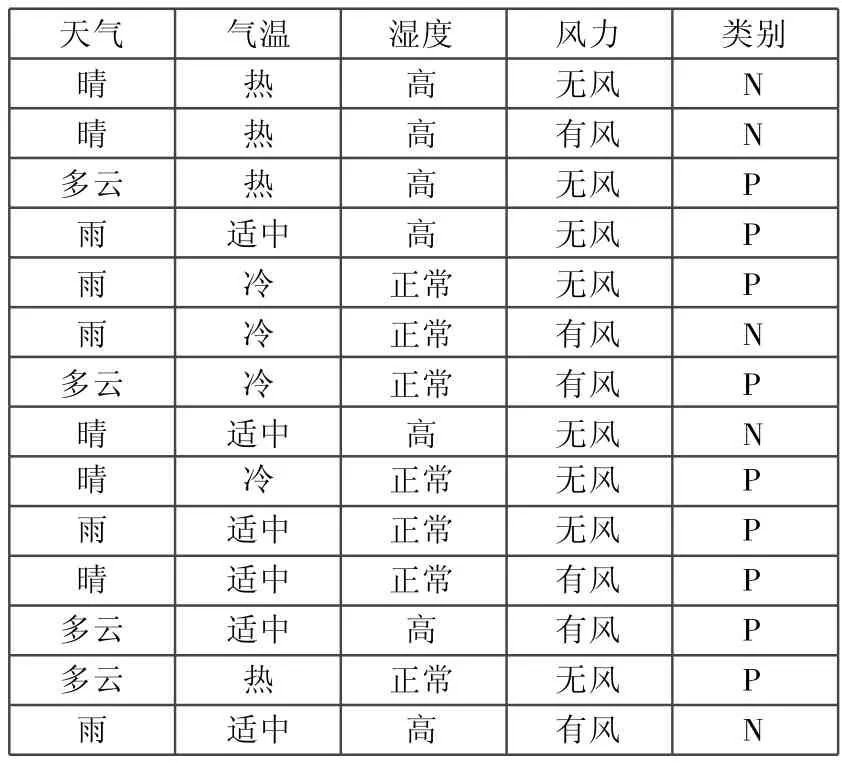
表1 气候数据集
通过OneR算法对气候数据集的各个属性进行筛选后,得到的评估参数如表2所示。

表2 评估参数
通过比较可知,风力和气温的错误率高于天气和湿度的错误率,需要降低风力和气温属性在分类中的重要性,相对地提高天气和湿度属性在分类中的作用。通过反复测试,经OneR算法选择天气、湿度和风力属性作为ID3算法的分类属性。
从ID3分类算法的模型准确率、未知率和运行时间方面,ID3算法和优化后ID3算法得到的分类结果如表3所示。
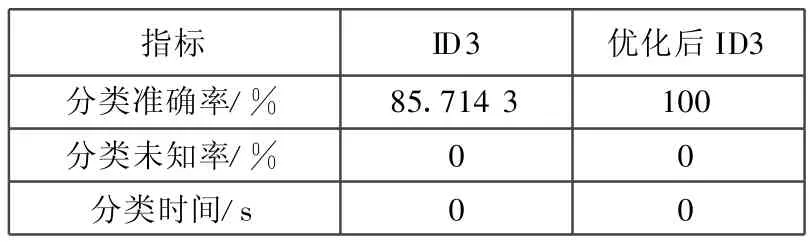
表3 分类结果比较
从表3中可以直观地看出,优化后的ID3算法降低了气温属性在分类中的重要性,有效地提高了算法的分类准确率。
实验2 从样本个数、属性个数、类的个数,类的取值分布四个方面,在UCI数据库中选取5个数据集,包括 mushroom,lymphography,splice,promoters和zoo,作为测试数据,UCI数据集描述如表4所示。
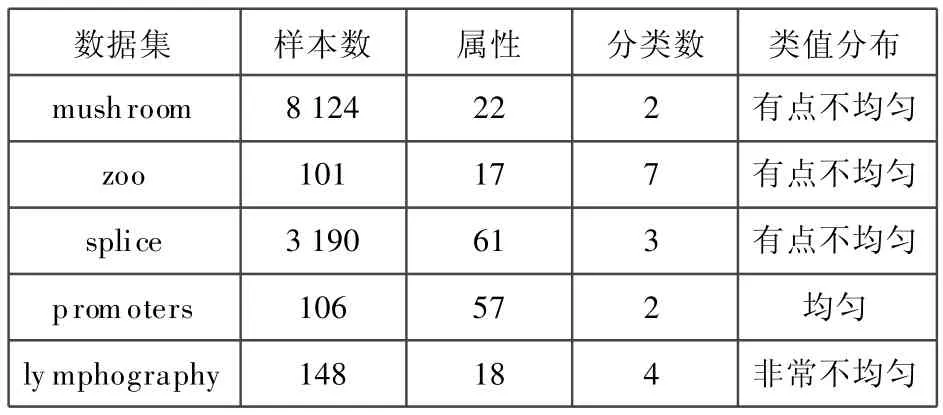
表4 UCI数据集
采用10次交叉验证的方法,在5个UCI数据集上分别采用ID3算法和优化后的ID3算法进行分类,分类结果如表5所示。
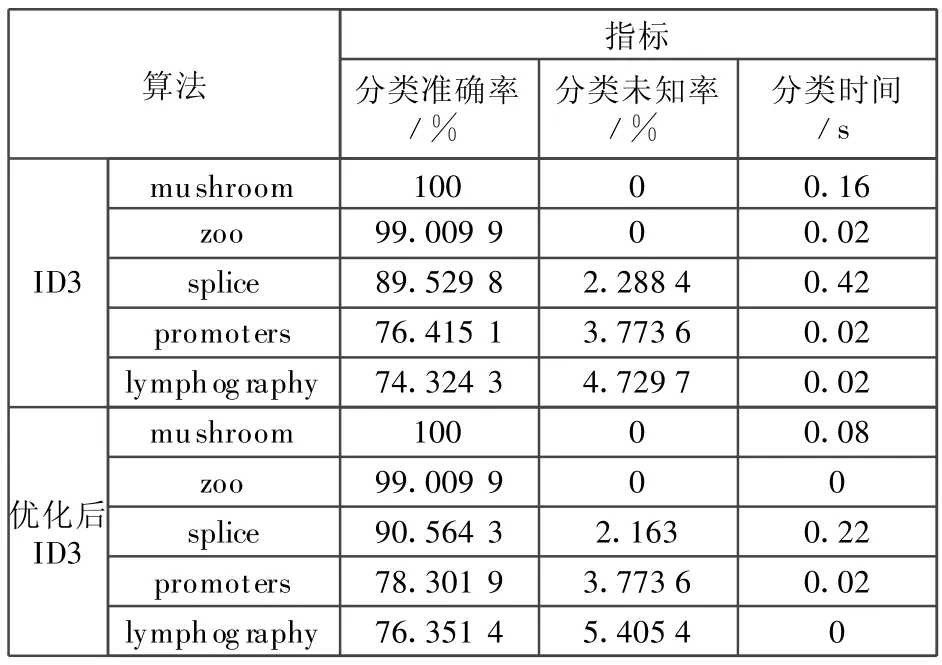
表5 分类结果比较
根据表5的实验结果,与ID3算法相比,优化后的ID3算法在分类准确率上都有所提高,除数据集lymphography外,其他四个数据集的分类未知率都有所降低,且运行时间基本上降低了50%以上,一定程度上降低了无关属性或者重复属性对分类的影响,克服了ID3算法取值偏置的缺陷,提高了ID3算法的性能和效率。
4 结束语
ID3算法是决策树生成算法中提出最早最经典的算法,为了避免噪声和干扰属性对数据分类的影响,在建立决策树之前应先进行属性选择。针对ID3算法中存在的不足,引入OneR算法用于测试属性的选择,减少了ID3算法中对取值较多的属性的依赖性,改善分类结果。实验结果表明,与ID3算法相比改进后的方案有较高的准确率,克服了ID3算法取值偏置问题,优化了分类结果。但是,ID3算法只能对静态数据集提取静态的分类规则,如何解决变化的数据集及规则提取问题是未来研究的重点。
[1] 罗可,林睦纲,郗东妹.数据挖掘中分类算法综述[J].计算机工程,2005,31(1):3-6.
[2] 栾丽华,吉根林.决策树分类技术研究[J].计算机工程,2004,30(9):94-96.
[3] 王苗,柴瑞敏.一种改进的决策树分类属性选择方法[J].计算机工程与应用,2010,46(8):127-129.
[4] 毛国君,段立娟,王实,等.数据挖掘原理与算法[M].北京:清华大学出版社,2007:123-123.
[5] 朱明.数据挖掘[M].合肥:中国科学技术大学出版社,2002:67-68.
[6] HOLTE RC.Very simple classification rules perform well on most commonly used datasets[J].Machine learning,1993,l1(1):63-91.
[7] 陈文伟,黄金才,赵新昱.数据挖掘技术[M].北京:北京工业大学出版社,2002:20-20.
