混沌算子模型在人口预测中的应用
2011-05-10邹晓玫修春波
邹晓玫,修春波
(1.天津商业大学 法学院,天津300134;2.南开大学 周恩来政府管理学院,天津300071;3.天津工业大学 电气工程与自动化学院,天津300160)
0 引言
中国是世界人口第一大国,人口问题一直是关系中国发展的重要因素之一。人口数量以及人口增长趋势的正确预测对于人口和宏观调控政策的制定具有重要的指导意义。目前,用于人口预测的数学模型有很多,如一元线性回归法、自回归法、指数函数法、幂函数法、多元回归模型法、灰色系统法、神经网络方法等。这些方法通常是采用拟合历史数据的方法建立近似的数学模型。
由于人口系统十分复杂,其变化与生育、死亡、疾病、环境、社会、经济等诸多因素有关。简单的数据拟合方法很难揭示其内在的本质,因此上述模型的建立具有一定的局限性。
本文提出一种新的混沌算子模型用于预测我国人口数量。该模型通过不断训练控制参数逐渐逼近人口系统的动力学行为,从而得到良好的预测结果。
1 模型的建立
根据已有人口数据建立人口模型十分困难,这主要是由于人口系统是一个非常复杂的非线性动力系统,有多种因素直接或间接地对该系统产生影响,这些因素之间也存在着各种复杂的耦合关系,无法解析表达。另外,目前已有的人口数据量少,数据信息不全面,数据的采样间隔大,通常两个相邻的数据之间的采样间隔为1年。几个相邻的数据跨越几年的时间。在这几年中,社会环境和自然环境可能发生了巨大的变化,人口模型也可能已经发生了本质的改变。也就是说,人口模型实质上是一个随着时间的推移不断变化的动态模型,本质上无法用一成不变的静态数学模型对其进行描述。
据此,本文提出一种新的预测模型,预测模型由多个混沌算子加权和的形式构成。通过不断调整混沌算子的控制参数,来改变各个混沌算子的动力学行为。最终使得预测模型的动力学特性逐渐趋近于人口系统的动力学特性,并不断随之变化,从而实现人口数据的预测。
混沌映射具有丰富的动力学特性,例如式(1)的映射即为一个混沌映射,调节控制参数α可使该映射产生不同的动力学行为。图1给出了控制参数α变化时该映射的Lyapunov指数图。Lyapunov指数大于0时意味着混沌的发生,且Lyapunov指数越大,混沌度也越大。

图1 函数xn+1=sinαxn的Lyapunov指数随α变化图
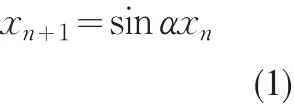
本文将式(1)映射选为混沌算子,采用多个混沌算子加权和的形式构造出如下的预测模型:

其中y为模型的预测值,xj为模型的第j个输入,zi为第i个混沌算子的总输入,αi为第i个混沌算子的控制参数。wi2为第i个混沌算子的加权系数,wji1为第j个输入与第i个混沌算子的连接系数。M为混沌算子的数量,m为输入数据个数。为了简化模型,权值系数设置为:wi2=1/M,wji1=1。这样,预测模型的动力学行为就完全由混沌算子的控制参数决定。调整每个混沌算子控制参数的大小,可使得每个混沌算子具有不同的动力学特性,从而可使得预测模型表现出不同的动力学行为。利用已知数据可构造出预测模型的训练样本,通过不断调整混沌算子控制参数,可使得预测模型逐渐逼近待预测系统的动力学行为,并保持其随之变化,从而完成时间序列的预测功能。
2 人口数量的预测
设已知的人口数据为{x1,x2,…,xn},预测的步长为p,则可构造出(n-m+1-p)个训练样本,第i个训练样本为:Xi=[(xi,xi+1,…,xi+m-1)(xi+m-1+p)],其中(xi,xi+1,…,xi+m-1)为第 i个训练样本的输入数据,(xi+m-1+p)为第i个训练样本的期望输出。
由于混沌算子具有复杂的动力学行为特性,通常的学习算法很难实现混沌算子参数的调整,这里采用一种简单的试凑法完成混沌算子参数的训练。具体描述如下:
Step1.初始化参数。样本序号k=1,混沌算子序号l=1,在(0,1)范围内随机初始化混沌算子参数αi。
Step2.输入第k个训练样本,计算预测模型的输出及其与期望值之间的误差。
Step3.正向调节第l个混沌算子参数值。增大该混沌算子参数,即

其中,λ为调解尺度,c为(0,1)之间的随机数。
计算此时预测模型的输出与期望值之间的误差,如果误差减小,则继续按照式(4)向正方向调节该混沌算子参数值。如果误差增大,则停止调节,并将该混沌算子参数值恢复为调节之前的值。
Step4.采用Step3中类似的方法,利用式(5)反方向调节混沌算子参数值。

Step5.l=l+1,如果l≤M,则返回Step3继续调节下一个混沌算子参数。如果l>M,则转至Step6。
Step6.l=1,k=k+1,如果k≤(n-m+1-p),则返回Step2继续训练参数。如果k>(n-m+1-p),则完成样本训练,转Step7。
Step7.输入(xk+1,xk+2,…,xk+m),计算预测模型的输出值即为预测结果。
预测模型根据训练样本的误差逐一调节混沌算子控制参数,使得预测模型逐步逼近预测序列的动力学特性,并随之不断改变。这比单一的静态拟和数据相比增强了自适应性。对于采样间隔长、动力学特性随时改变的系统来说将具有良好的预测性能。
3 预测结果分析
利用《中国人口统计年鉴》和《中华人民共和国2009年国民经济和社会发展统计公报》上的数据,对中国人口总数进行预测分析。所得预测结果和误差曲线如图2和图3所示。
从预测结果可见,在预测初期,由于预测模型的控制参数为随机选取,训练不够充分,因此预测误差较大,随着训练过程的进行,预测模型的控制参数逐渐得到调整和训练,预测模型的动力学特性逐渐与被预测系统的动力学特性相接近,因此误差逐渐减小,预测效果逐渐得到改善,并得到较高的预测精度。

图2 全国人口总数预测结果
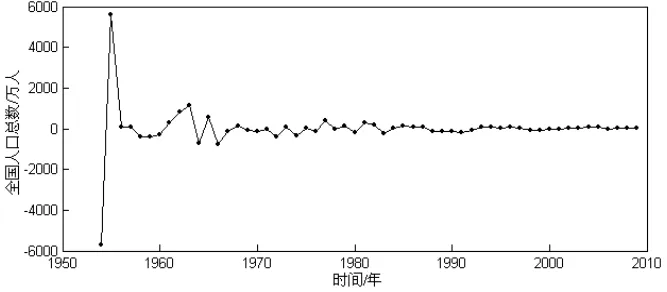
图3 全国人口总数预测误差
采用不同的预测方法对2006年-2008年的人口总数进行预测,所得预测结果如表1所示。

表1 不同预测方法的对比结果
从表1可见,本文方法可较好地实现对我国人口数据的预测,与现有的其他方法相比,预测精度更高。这是由于本文所提的预测模型在训练过程中不断调整控制参数,可使预测模型逐渐逼近已知序列的动力学特性,并随着其动力学特性的改变而一致变化,因此可获得更准确的预测结果。
采用本文预测方法对我国未来几年的人口数据进行预测,所得结果如表2:

表2 对未来几年人口数据预测结果
从预测结果可见,未来几年我国人口数量仍然处于上升的趋势,到2015年将达到13.7亿左右。
4 结论
本文提出了一种混沌算子预测模型,并应用其对我国人口数据进行预测,预测结果表明,该模型具有较高的预测精度。可应用其对我国未来几年人口数量进行有效预测。对于人口政策以及宏观调控政策的制定具有积极的参考价值。
[1]张锦宗,朱瑜馨,周杰.基于BP网络与空间统计分析的山东人口空间分布模式预测研究[J].测绘科学,2009,34(6).
[2]田飞.21世纪初人口场景预测研究回顾[J].人口与发展,2010,16(2).
[3]涂雄苓,徐海云.ARIMA与指数平滑法在我国人口预测中的比较研究[J].统计与决策,2009,(16).
[4]李国成,吴涛,徐沈.灰色人工神经网络人口总量预测模型及应用[J].计算机工程与应用,2009,45(16).
[5]朱艳伟,张永利.中国人口增长预测模型及其改进[J].统计与决策,2010,(16).
