一种新型的网络社区高影响力主题提取方法
2011-02-20吴亚男
吴亚男, 杨 云
(陕西科技大学电气与信息工程学院, 陕西 西安 710021)
0 前 言
Internet上的虚拟社区、网络社区,如BBS/论坛、贴吧、公告栏、群组讨论、在线聊天、交友、个人空间等,其作用是为了增进世界各地人们之间的交互.现今互联网的猛速发展和信息日益的开放化、透明化,使得网络社区中人气指数高涨,数据日益庞大.人们通过网络社区这一平台表达自己的观点与见解,而对社区中热点或大众最为关心的话题的分析也显得尤为重要,要从每天的海量信息中提炼出高影响力和有潜在价值的话题并非是一件很容易的事情.
而我们较为传统的判断方法主要是从主题的几个指标来看:点击率(浏览数)、回帖数、讨论周期、下载存储次数.利用此方法可以取得较好的效果.但也存在某些缺陷[1]:(1)无法从主题内容中分析,只是简单的数字统计;(2)没有对主题进行聚类,从而发现社区中若干相关主题组成当前热门话题;(3)没有考虑到重要词语在回复链上的传播作用.
为了较好地解决传统高影响力主题计算方法所存在的不足,我们从社区各个主题的内容出发,即从帖子间的回复内容着手,提出对高影响力词语进行聚类,从而达到对热点话题的聚类与提取,并设计出高影响力主题发现的原型系统,该系统能够较好地从网络社区中提取出高影响力主题.
1 系统的架构与设计
1.1 社区信息预处理
在中文里,语言的最小单位是字,而能表达出一定含义的最小单位则是词语.当然,也存在某些单字词.以文本形式存在的信息是以标点符号对句子进行分割,而词语之间也同样需要分割.目前较为常用的分词方法有3大类:一是基于规则的方法;二是基于统计的方法;三是综合法.虽然这些方法在词语的分割方面都发挥着不小的作用,但仍然面临着词语切分歧义和未登录词识别两大难题.为了能够减少词语切分歧义、提高词语分词的准确率,本文提出了一种基于隐马尔可夫模型的双向最大字符串匹配分词法.具体实施步骤如下:首先,按照双向最大匹配法将待分析的中文字符串与机器词典中的词条进行逐一匹配,由左至右扫描每一个字符串,若扫描时存在几种组合形式的词语,则选择字数较多的词语;同理,再按照由右至左的方式进行匹配,可得到两种匹配的结果,然后采用隐马尔可夫模型(HMM)对两种匹配结果进行比较并消除歧义,最终得到比较准确的分词结果[2,3].

图1 文本信息预处理过程示意图
另外,停用词处理是文本信息抽取过程中的一个重要前提,处理好停用词可以提高特征词选择的速度与质量.停用词主要是指对文本信息没有实际价值且出现频繁的词语,如“的、很、而且”等副词和连词.因此在对词语进行分割后还需要对其进行词性的标记.通常,一个句子是由名词、冠词、动词、代词、副词、形容词、介词和连词等组成,其中最能表达文本含义的词性为名词和动词,但是冠词、动词、代词等其他词性的词汇也会频繁出现在文本中,这类停用词需要被过滤掉,动词与名词则作为本文特征词的候选项而保留.
基于以上描述,可以得出社区信息预处理过程如图1所示.
1.2 特征词的选择
1.2.1 词语权重定义
传统比较常见的权重计算方法有特征频度权重函数、TFC函数、TF-IDF、组合权重和熵权重等.本文对词语权重的计算主要基于TF-IDF方法并结合网络社区信息的特点进行修改.一个完整的主题包括标题+内容+回复内容.显然,出现在标题中的词语要比在内容中更为重要,而内容中的词语要比回复中重要,因此可根据情况给不同的位置分别定义影响因子.此外,本文为方便计算将词语的权重值域规范到[0,1].基于上述理解,对词语在每个主题中的权重进行如下定义[4]:
(1)
其中,frequency(c,T)表示词语c在主题T中出现的频率,N表示社区主题的总个数,nc代表在词语c所属版面中包含词语c的主题个数,loc为词语在主题出现位置的影响因子且值域在[0,1]范围.因此,高权词的集合C={c∣QcTi≥δ,1≤i≤n }.
1.2.2 帖子间影响力
同一主题下,帖子间也存在密切的关系.设帖子y是对x的回复,帖子z是对y的回复,计算帖子x对帖子y的影响力为:
(2)
(3)

“网络是我们在全世界需要盟友和合作伙伴的地方。”然而,数据访问和共享可能打破个人与政府或企业原本建立的信任关系,由于大数据时代的元数据比以往任何时候都更容易创建,并且与其他数据形成聚合,突破隐私规则的束缚变得轻而易举,从而使人们丧失对隐私规则的预期。
(4)
这样依次类推可获得回复链中所有帖子间的影响力.
1.2.3 词语对帖子的影响力
设在主题T中存在一条回复路径L={x,y,z,…,u,v,w},帖子x对帖子w的影响力为kxw,并将词语对主题T的影响力值确定在[0,1],计算词语对主题T的影响力为:

(5)
因此,可计算出词语c在整个社区D中的影响力(设D由n个主题组成):
(6)
接下来,我们结合词语的权重值和在论坛中的影响力两个因素来提取出高频词.得到的高频词放入集合H中,H={c∣inf(c|D)≥θ,c∈C}.
1.2.4 无向图G的构建
由顶点和边构成无向图G={V,E},高频词集合H用来确定图G的顶点.词语之间的紧密关系确定无向图G的边.判断词语间是否存在紧密联系,需计算任意两个词语间的关联度Rela(c1,c2),且词语c1,c2∈H,则它们在论坛D中的关联度为:
(7)
通过上述计算方法可以得到任意两词语间的关联度,若它们的关联度大于一定的阈值,则认为它们具有高度的相关度并在词语间用边连接.E={e(c1,c2)∣Rela(c1,c2)≥Ω, c1,c2∈H}.高度相关的词语一般存在两种情况:一种情况是两个词语属于同义词,意思很接近;第二是它们在主题当中的同现概率较大.若几个高度相关词语的组合能够构成一个词组或是短语,则也具有参考价值.然而,在主题中也会存在一些

表1 设置系统参数值
特殊的词语,它们在社区中的出现不一定很频繁,却具有极高代表性并与高频词语关系图G具有紧密的联系,此类特殊词语为潜在关键词.潜在关键词的进一步挖掘需将非高频词与无向图G进行同现趋势度计算[5].
(8)
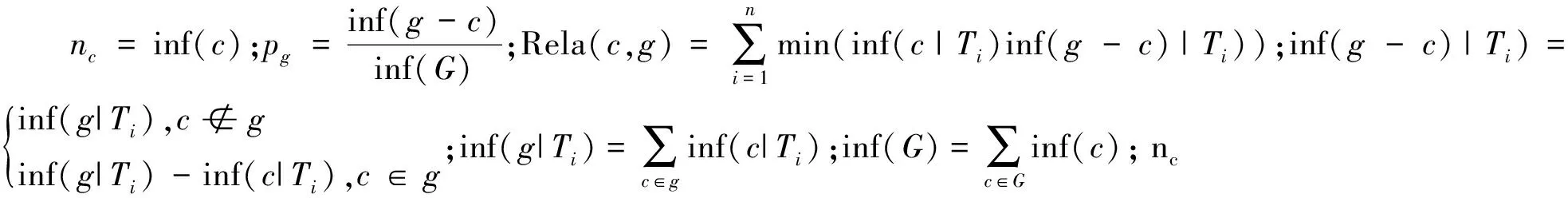
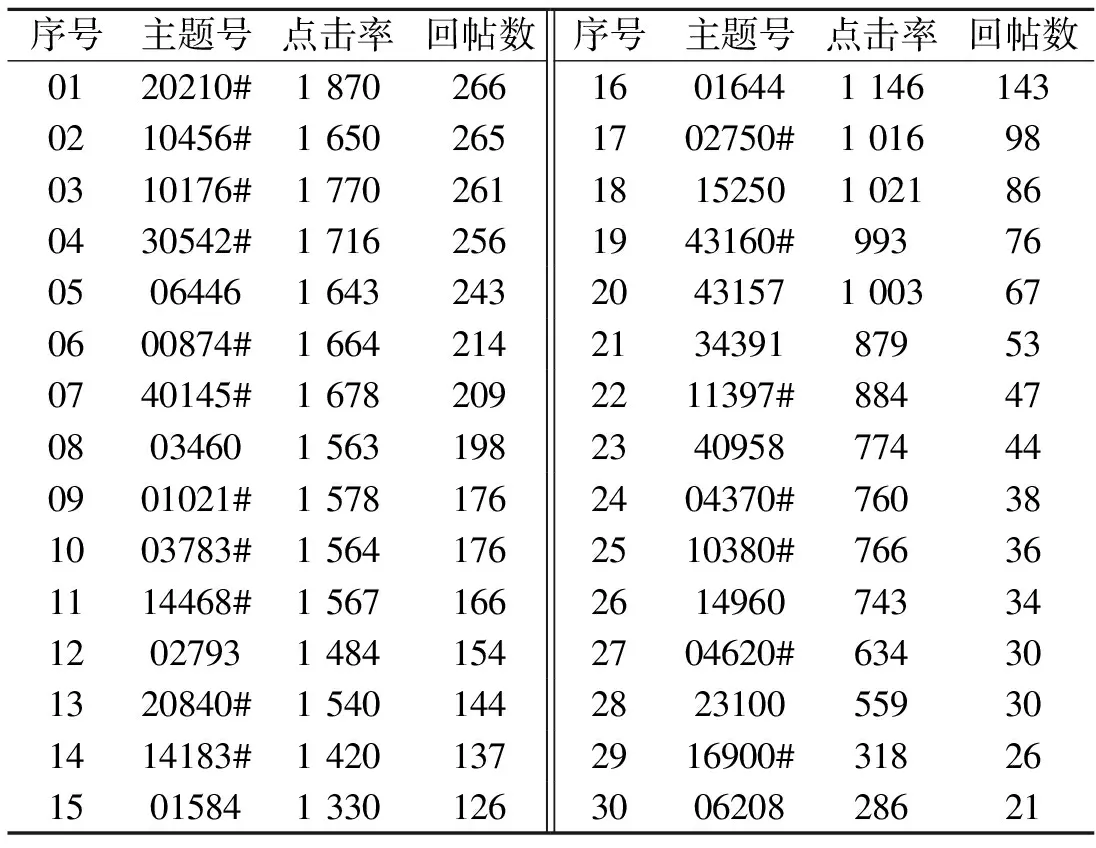
表2 传统法提取2010年3月2日的前30个热点话题
1.3 高影响力主题的发现
最终构成的无向图G是由若干个完全子图构成,G′= g1′∪g2′∪……∪gn′,其中每一个完全子图都能代表一类热点话题,从而提取出较高影响力的主题.结合传统的数据统计方式再对提取出的高影响力主题进行排序.
2 实验与分析
本文实验数据来源中华网军事论坛,这是一个具有大量用户和数据信息的论坛.论坛平均每日增加的原帖数达100~150,而每天增加的回贴数可达2 000左右.
利用本文系统提取社区中2010年3月2日的高影响力主题,该系统的参数值设置如表1所示,再利用传统的方法选择出2010年2日至4日3天的热点话题,主要通过社区中主题的点击率、回帖数进行选择[6].
表2中“#”号表明两种不同方法的相同主题,可以发现其中有16个共同的高影响力主题,相似度达60%.
其中表3中“*”表示2010年3月4日的热点话题已在本文系统结果2010年3月1日的高影响力主题中出现,说明该系统方法能够提前预计出高影响力主题的趋势.
3 结束语
本文通过对特征词语的提取并深度挖掘出潜在关键词,寻找它们的内在关联,从而对高影响力主题进行聚类.该原型系统很好地弥补了传统方法的不足,从主题内容上反映了其影响力和关注度,既对当前的数据信息做出了分析和处理,同时也能对近期的信息走向进行预测和基本判断.然而,本文系统仍有必要进一步优化.首先,本文系统的设计过程中涉及到很多参数,如何合理的设计参数关系到最终结果的准确率,只有经过多次实验才能很好的调试参数的值.其次,如果在该系统中适当融入一些人机交互操作,则可使得社区中提取出的高影响力主题更加准确、高效.
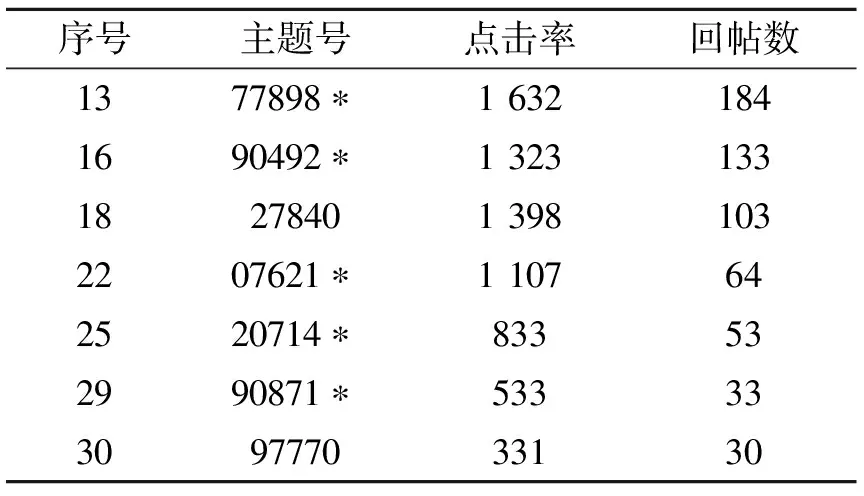
表3 传统法提取2010年3月4日增加的高影响力主题
参考文献
[1] 蒋 凡.BBS中主题发现原型系统的设计与实现[J].计算机工程与应用,2005,(31):151-153.
[2] 李媛媛.基于潜在语义索引的文本特征词权重计算方法[J].计算机应用,2008,28(6):1 460-1 466.
[3] 李星毅.基于单词相似度的文本聚类[J].计算机工程与设计,2009,30(8):1 966-1 968.
[4] 李晓红.中文文本分类中的特征词抽取方法[J].计算机工程与设计,2009,30(17):4 127-4 129.
[5] 杨林波,王士同. 基于类别分布特征的快速文本分类方法[J].计算机工程与设计,2009,30(5):1 267-1 269.
[6] 高俊波.在线论坛中潜在影响力主题的发现研究[J].计算机应用, 2008,28(1):140-142.
