粗糙集在突发危机事件范例推理中的应用研究
2011-02-20李寅煦
李寅煦
(上海交通大学安泰经济与管理学院, 上海 200052)
0 引 言
粗糙集非常适合应用于知识系统中以处理不完全信息、消除数据冗余、获取逻辑规则并提高检索的效率,因此已被广泛应用到CBR的理论和应用研究中,其中最主要的就是范例属性的约简.利用粗糙集在范例推理系统中进行属性约简已经在多个领域有了成功的应用,比如分类选择、疾病诊断、故障分析以及组合预测等等.突发危机事件,是指突然发生,造成或者可能造成严重社会危害,需要采取应急处置措施予以应对的自然灾害、事故灾难、公共卫生事件和社会安全事件[1].在过去的十几年中,突发危机事件已逐渐成为了一个全球关注的重大问题.本文介绍了粗糙集在突发危机事件范例推理中的应用研究.
1 突发危机事件范例的表示和组织
范例的表示过程是将历史事件信息与专家决策知识相结合,按照转换规则转化为计算机系统可识别、可处理信息的过程.根据知识表示的便捷性、有效性、可扩展性以及应用领域的不同,可以借鉴人工智能领域的多种知识表示方法,如剧本、框架、谓词逻辑、语义网络和面向对象的表示方法等[2].尽管CBR中对范例概念的解释目前还没有统一的说法,但不论采用何种方法,范例的表达都要遵循一定的规则,形成规范的结构,以便检索和匹配.一般来说,最常用、也是最方便的方式是采用范例的特征向量.
对一个典型的范例,进行描述至少需要使用二元组:<问题描述,解描述>.在很多CBR系统中,也有采用三元组表示的:<问题描述,解描述,效果描述>.
考虑到面向对象表示法所具有的封装性、模块性、继承性和易维护性等特征,本文在三元组的基础上采用面向对象的层次结构表示法来实现突发危机范例的表示与存储,以实现范例表示的灵活性与可扩充性.具体而言,对于范例C,用多元组的形式可以表示为C={T,P,S,R},其中T表示范例类型描述,P表示范例问题描述,包括环境属性,危机属性等,S表示范例解决方案描述,R表示对问题采用S后产生的状态或反馈信息,即范例决策结果的描述.
2 范例相似度算法
2.1 范例相似度基本函数
范例间相似性的度量在范例检索中发挥着重要的作用,这也是为什么CBR系统有时也被称为相似性检索系统的原因.按照目前通常采用的范例库组织形式,范例检索一般用最近相邻算法.由于通常用多维属性向量表示范例,因此也称为k-最近相邻算法(K-Nearest Neighbour,KNN)[3].
KNN最近相邻算法最初被用于分类,是一种无参数消极分类方法.对于给定的待检索对象,KNN算法检索得到与其最为相近的范例,并将该范例归入最相近范例的类别中.显然,KNN算法的精确率和可靠性在很大程度上依赖于范例间距离函数的定义,即范例相似度为范例属性相似度的加权聚合.
2.2 基于粗糙集的范例相似度属性加权算法和程序实现
属性加权算法直接关系着范例距离函数的有效性,它的确定对范例检索的效果和效率有着决定性的影响.在文献[3]中可以找到有关属性加权算法的详细介绍和综述.
粗糙集算法可以进行属性约简,是一种属性选择操作[4, 5],但从某种意义上来看,它仍然是一种确定属性重要性,即属性权重的方法.所有基于粗糙集的属性加权算法都基于如下思想,即某属性f将对象x∈U划分到决策类Xi(i=1,…,r(d))这一过程及结果的贡献程度[6].那些可以明确决定将某对象归入某决策类的属性权重为1,而那些与范例归类无关的属性权重为0,可以省去.
基于经典粗糙集的属性加权算法通过设计相关函数考察待加权属性与对象分类之间的相关程度,因此这类加权算法通常从属性的相对约简集和决策类的相对正域着手进行分析,典型的如PRS(Proportional Rough Sets)算法和DRS(Dependence Rough Sets)算法[7].
PRS算法考察属性f在约简集中的出现频率,以此为该属性赋权,即
(1)
其中,R是关系的集合,card表示集合的势.对于没有在任何一个约简集中出现的属性f,其权重μ(f)为0,而在核中出现的属性,其权重μ(f)为1.
DRS算法计算属性的依赖系数,即属性重要度,以此作为属性的权重.
(2)
其中,R为条件属性C对决策属性D的相对约简集,D=U/D,两者皆可从原始数据中计算得到.POSR(D)是根据约简集R所表示知识得到的关于决策属性D的相对正域,POS(R-{f})(D)表示在约简集R中除去属性f后根据剩余属性所表示知识得到的关于决策属性D的相对正域.
计算相对正域及其变化非常复杂,计算代价很高,因此在实际应用中并不常见.但经过分析可以发现,基于粗糙集对范例属性进行加权,主要考察的是属性对信息系统的分类能力,即辨识不同范例的能力,而计算相对正域的变化只是度量分类能力的一种方法.
从属性约简的计算过程中可以看出,在相似辨识矩阵中,出现最小势矩阵元素中的属性一定是核属性,而出现在势较小的元素中的属性则更可能出现在约简集中.由此可见,可利用相似辨识矩阵及势为属性加权.那些在低势元素中出现频率较高的元素对范例分类的贡献较大,将被赋予较高的权[8].
首先,根据预先定义的各属性相似度阈值,加权算法对范例进行两两比较,构建相似辨识矩阵.然后,算法考察各条件属性在相似辨识矩阵SDn×n中出现的位置和频率,并以此为各属性进行打分,在最低势矩阵元素中出现频率最高的属性拥有最高的权重分数.最后对所有属性的权重分数进行规范化,使其和为1.打分时,考虑的因素包括出现位置(矩阵元素的势,势低则分数高)和出现频率(频率高则分数高).
在属性约简算法中,如果属性被添加到约简集RED(C)中,则该属性将从相似辨识矩阵中删去.类似地,基于相似辨识矩阵的属性加权算法考察属性在矩阵中出现的位置和频率,如果对于某一势水平中,属性a的出现频率比属性b高,那么属性a比属性b更为重要,不必再在更高的势中进行进一步的比较.因此,在具体操作过程中属性权重的分配是基于相对关系确定的.在确定最高权重属性后,其他属性的分值以差值的方式表示.例如:如果包含属性a的矩阵元素的最低的势为3(假设相应的分值权重为5),则出现的频率为5;若属性b在同级别元素中出现频率为2次,那么两者间的分值差则为5×(5-2)=15;若属性b在同级别元素中也出现了5次,那么将在高一级别矩阵元素中进行比较.
(1) 构建一个n×(n+1)矩阵Fr用于存储各属性在相似辨识矩阵中出现的位置和频率,其中n为条件属性的个数,参数的初始值均为0.
i=j=l=m=0; k=1;
for (i=1; i<=n; i++)
{ for (j=1; j<=n; j++) { l=card(i,j);
遍历相似辨识矩阵所有元素 SD(i,j);
while (属性 x 出现)
{for (m=1; m<=k; m++)
{if (x==Fr(m,n+1)) break;
} /* 在Fr中寻找属性x */
if (m==k)
{Fr(m,n+1)=x; k++;
} /* 属性x不包含在Fr中,添加 */
Fr(m,l)++;
}
}
}
(2) 对矩阵Fr进行整理排序.
n--;
While (n>0)
{j=1;
for (i=1; i<=n; i++)
{比较行i和行(i+1);
{整行交换行i和行(i+1);
j=i;
}
n=j; /* 行j以后的行已整理完成 */
}
}
我们定义行i > 行(i+1)成立,当:
for (j=1; j<=n; j++)
{ if (Fr(i,j)>Fr(i+1,j))
根据饵料鱼不同的配套模式、设计单产量、上市季节等不同,翘嘴鳜“华康1号”养殖可分为饵料鱼专池饲养和饵料鱼、鳜鱼混养两种模式。它可以按照鳜鱼共性的技术标准、操作规范和生产流程进行养殖,诸如清塘、苗种消毒,或单一品种精养,或多品种立体混养或者轮捕轮放,饲料投喂,开展病害防治以及防灾减灾,同时该鱼养殖也有个性要求。
{ 命题成立;
break;
}
}
(3) 计算各属性的权重分数.
for (j=1; j<=n; j++)
{if (Fr(n,j)==0)
{ score(n)=Fr(n,j+1)*(n-j);
break;
}
}
for (i=n-1; i>0; i--)
{for (j=n; j>0; j--)
{if (Fr(i,j)==0)
for (k=j+1; k<=n; k++)
{while (Fr(i,j+1)-Fr(i+1,j+1)<>0)
score(i)=score(i+1)+(Fr(i,j+1)-Fr(i+1,j+1))*(n-j);
}
break;
}
}
if (j==0) /*第i行中已没有空元素*/
{for (k=j+1; k<=n; k++)
{while (Fr(i,j+1)-Fr(i+1,j+1)<>0)
score(i)=score(i+1)+(Fr(i,j+1)-Fr(i+1,j+1))*(n-j);
}
}
}
(4) 将各属性分值规范化,使属性权重和为1,即
(3)
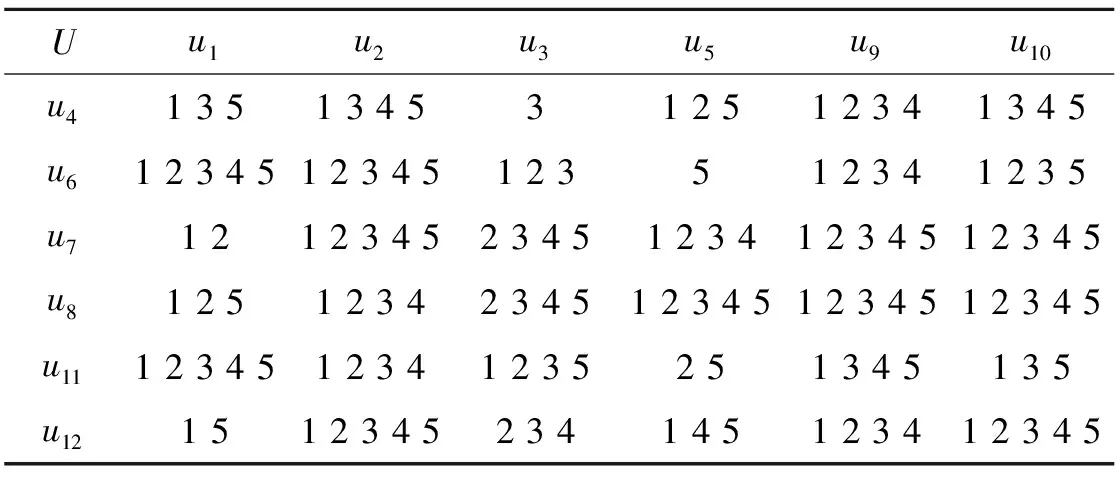
表1 信息系统S的相似辨识矩阵
下面我们通过一个实例说明上述加权算法.假设信息系统S=
由此,我们可统计各属性在相似辨识矩阵中出现的位置和频率,如表2所示.
此表阅读方法如下:属性a3在势为3的矩阵元素中出现的次数为4,则表中对应的位置数值为4.相似辨识矩阵中元素的势最低为1,最高为5.势为1的元素分值为5,势升高时分值依次降低,势为5时分值为1.计分过程从表中最后一行开始.属性a4出现的元素势最高为3,出现频率为2,则其分值为3×2=6.由于属性a2出现在势为2中的元素中,而属性a4没有,因此其分值差为4×(2-0)=8,属性a2分值为14.由于属性a1和属性a2在更高的势中出现频率相同,在势为2的元素中出现频率仍相同,在势为3的元素中进行比较,因此分值差为3×(6-4)=6,属性a1分值为20.依次类推,属性a1和属性a5的分值分别为25和33.将属性分值规范化后,可得各属性权重分别为0.204 1,0.142 9,0.255 1,0.061 2和0.336 7.

表2 基于相似辨识矩阵的属性权重计分表
由相似辨识矩阵中,我们可以计算得出核属性为{a3,a5},约简集为{a1,a3,a5}或{a2,a3,a5}.核属性权重最高,约简集中其余属性权重次之,其它属性权重最小.如有必要,被约简属性可以不做加权.如上述示例中,属性a4不在约简集中,被删去,这样其它属性的权重依次为0.217 4,0.152 2,0.271 7和0.358 7.
2 粗糙集在突发危机事件范例约简中的应用举例
以水灾为例,结合范例库示范粗糙集在突发危机事件范例约简中的应用.
本文基于自然基金项目,已构建了一个突发危机事件案例库,其中记录了100多条各种类型的防汛应急范例.由于本例重点研究粗糙集的范例检索和匹配,因而并没有将范例的决策属性列出.我们取其中20个范例构建信息系统,并基于此表进行范例推理过程的演示.
根据本节中描述的算法,在进行范例检索之前的准备工作依次包括:范例属性相似度度量、相似辨识矩阵构建、范例属性约简以及范例属性加权.
以范例A0001和范例A0002为例,我们举例说明范例属性相似度度量方法.
“死亡人口”属于精确数值属性.考虑到范例A0007“印度洋海啸”事件死亡人数近30万,是一个例外事件,若将其考虑在内将影响相似度的度量结果,因此本属性值域定义为[0,1 126].范例A0001和A0002在属性“死亡人口”上的相似度为SIMa7=1-(121-117)/1 126=0.996 4.
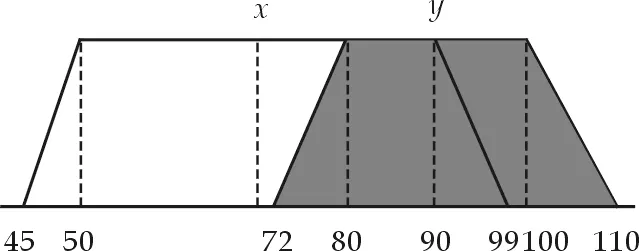
图1 “降水量”属性的梯形表示
“灾害类型”为精确符号属性,范例A0001和A0002在此范例上相似度为1.
“降雨量”属于模糊区间属性.属性值域为[0,650].范例A0001和A0002属性取值分别为80~100和50~90,两者用梯形表示如图1所示.

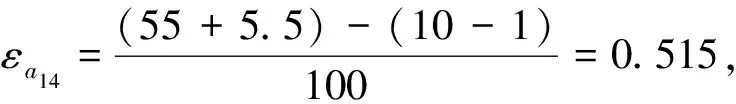

由此,根据预先定义的范例属性相似度阈值,可以确定范例A0001和A0002在属性a8和a14上不相似,相似辨识矩阵对应元素SD1,2={a8,a14}.
6 结束语
上述研究表明,基于粗糙集的算法有助于更高效地获得高精确度的相似案例,可应用于如下两个方面:
(1) 范例库维护. 当信息系统中的信息容量(即对象数)不同时,粗糙集将得到不同的约简结果.为了保证不损失范例库中的信息,范例以全量范例的形式保存(即保存范例的所有属性信息),而在每次进行范例库维护之前需重新计算范例的属性约简,从而既提高了效率,又健全了系统.
(2) 范例检索. 由于突发危机事件应急决策信息水平低、有限决策时限短等特殊情况,在进行危机范例检索时,如果要求决策者输入所有的范例属性值才能进行范例检索,则显然是不实际的.粗糙集在保证检索效果和效率的前提下减少检索时必要的范例属性数目,对于面向突发危机事件应急决策支持的范例推理系统而言意义重大.
具体来说,当决策者面对新的突发危机事件问题,需要决定是否采取某行动(即范例的某一决策属性SK)以及如何采取该行动(即决策属性的SK取值),那么通过构建决策信息系统,并利用粗糙集对其进行处理,决策者就能够相应地了解到在过去的实践中,在哪些情况下采取了该行动,具体都是如何操作的.这样,如果新的突发危机事件问题与历史范例相匹配,就能实施同样的方案;即使没有完全匹配的信息,通过分析相似范例,也能在该决策属性与范例其他条件属性之间建立逻辑关系,协助决策者对行动方案进行选择.
因此,基于粗糙集的范例推理能有效地提高系统的效率,帮助更高效地获得高精确度的相似案例,从而提高突发危机事件决策的效用.
参考文献
[1] 国务院突发危机应急管理所. 国家突发公共事件总体应急预案[M]. 北京: 中国法制出版社, 2006:1-1.
[2] 史忠直. 知识发现[M]. 北京: 清华大学出版社, 2002: 3-4.
[3] Wettschereck, D., D. Aha, T. Mohri. A review and empirical evaluation of feature weighting methods for a class of lazy learning algorithms[J]. Artificial Intelligence Review, 1997, 11(1):273-314.
[4] Aamodt, A.. Knowledge-intensive case-based reasoning in creek[J]. Advances in Case-Based Reasoning, 2004,(5): 793-850.
[5] B rner, K.. Structural similarity as guidance in case-based design[J]. Topics in Case-Based Reasoning, 1994, (5):197-208.
[6] Brown, M.. An underlying memory model to support case retrieval[J]. Topics in Case-Based Reasoning, 1994,(1):132-143.
[7] Salam, M., E. Golobardes. Analysing rough sets weighting methods for case-based reasoning systems[J]. Inteligencia artificial, 2002,(6): 15-16.
[8] Tao, J.,S. Huizhang. Feature Selection and Weighting Method Based on Similarity Rough Set for CBR[R]. Service Operations and Logistics, and Informatics, 2007:948-952.
