基于特征贡献度的特征选择方法在文本分类中应用
2011-02-08孟佳娜林鸿飞李彦鹏
孟佳娜, 林鸿飞, 李彦鹏
(1.大连理工大学计算机科学与工程系,辽宁大连 116024;2.大连民族学院理学院,辽宁大连 116600)
0 引 言
文本分类是信息检索与数据挖掘领域的研究热点问题,其核心任务为根据给定的训练数据,构造高性能的分类器,实现对新文本的自动分类.在实际应用中,根据预定义类别的数量不同,分类系统可分为两类分类器和多类分类器两种.从文本所属类别的个数来看,文本分类技术又可以分为单标签和多标签两种.
文本分类的主要算法包括朴素贝叶斯方法[1、2]、KNN[3]、最大熵方法[4]、神经网络[5]、支持向量机[6]方法等.最常用的文本特征表示模型是向量空间模型(vector space model,VSM),这种方法将分类文档中出现的全部词条作为特征,将分类空间视为一组正交词条向量所张成的向量空间,原始空间的维数十分巨大,因此,找到一种有效的特征选择方法显得至关重要.文本分类中常用的特征选择方法有文档频率(document frequency,DF)[7]、互信息(mutual information,MI)[7]、χ2统计(chi-square statistic,CHI)[7]及几率比(odds ratio,OR)[8]等.文献[7]比较了一些常用的特征选择方法,并指出χ2统计和信息增益方法是最有效的,其次是文档频率和互信息.文献[8]提出了几率比的特征选择方法,仅使用了多分类的朴素贝叶斯分类器在reuters-21578语料集上进行了实验,并与其他方法进行了比较,同时提出该方法是效果最好的特征选择方法.人们利用这些特征评价函数从不同的知识角度对特征项与文本之间的相关程度进行了研究[9、10],文献[9]使用SVM分类器分析了不同特征选择方法的效果,并提出了一种新的特征选择方法BNS,该方法在一些特定的情况下分类结果优于常用的方法.文献[10]给出了一组特征选择函数需满足的基本约束条件,并基于该约束条件提出了一个构造高性能特征选择方法的通用方法.
上述方法从不同的角度改进了特征选择方法,提高了分类效果,但忽略了特征词在各个类中的分布情况,而特征词在各个类的分布情况会反映特征对区分每个类的贡献.本文提出基于特征词在各个类的分布情况的统计信息,即特征贡献度的一种特征选择方法,这种方法通过计算特征的贡献度值对特征进行选择,倾向于选择出在某一类文档中频繁出现同时在其他类中出现次数少的特征,认为这种特征能够为文本分类提供更有价值的信息.
1 基于特征贡献度(FCD)的特征选择方法
1.1 FCD特征选择方法
为了选择出对分类贡献度大的特征,本文首先用下面的公式计算每个特征的贡献度值:
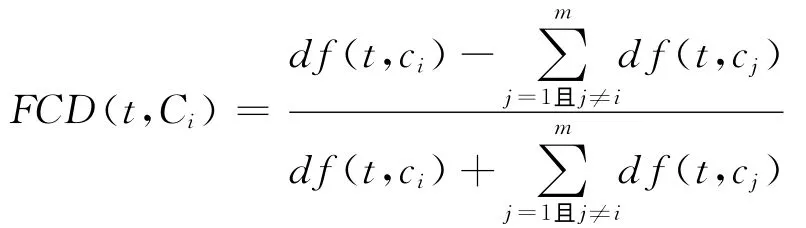
特征t的最终的FCD值计算公式定义为
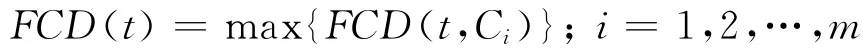
由上式计算的FCD值越大,说明特征对于某一类区别于其他类的区分贡献程度越大,对于分类的指导意义越大;该值越小,说明其对于类别区分的贡献程度越弱,对于分类的指导性越小.本文算法在提取特征时,是按FCD值从大到小的次序依次提取,因此FCD值越高的特征将有更大的机会被选择.
综上所述,本文考虑到特征词在各个类别中的分布情况不同,而特征在各个类的分布情况的统计信息对分类具有指导意义,从而提出了基于特征贡献度的一种特征选择方法,这种方法通过计算特征的贡献度值对特征进行选择,而特征贡献度值能够很好地反映出类别分布情况的统计信息.该方法倾向于选择出在某一类文档中出现次数多同时在其他类中出现次数少的特征,认为这种特征能够为文本分类提供更有价值的信息.
1.2 举 例
为说明本文方法进行特征选择的具体情况,下面举一个例子进行说明.表1列出了在一个简单的文本语料集中特征的FCD值比较.其中,第1列表示语料集中出现的几个特征,第2、3、4列分别表示该特征在三类文档中出现的文档数,第5列为特征在数据集中出现的总文档数,最后一列为特征的FCD值.对于特征“corn”来说,它在所有文档中只在corn类中出现过,此时,FCD(corn,corn)=(50-0)/(50+0)=1,同时,FCD(corn,{interest,trade})=(0-50)/(0+50)=-1,所以FCD(corn)=max{1,-1,-1}=1;对于特征“engineer”来说,它在所有文档中的每一类中出现的次数相同,FCD(engineer,{corn,interest,trade})=(20-40)/(20+40)=-0.33,所以FCD(engineer)=-0.33;最后,考虑特征“database”,FCD(database,corn)=-30/40=-0.75,FCD(database,interest)=10/40=0.25,FCD(database,trade)=-20/40=-0.5,所以FCD(database)=0.25.
从以上例子可以看出,特征“corn”的FCD值最高,此特征对于类别区分的贡献度最大;特征“engineer”的FCD值最低,此特征对于类别区分的贡献度最小.本文方法正是依据选择那些对于分类贡献度大的特征来达到提高分类效果的目的的.
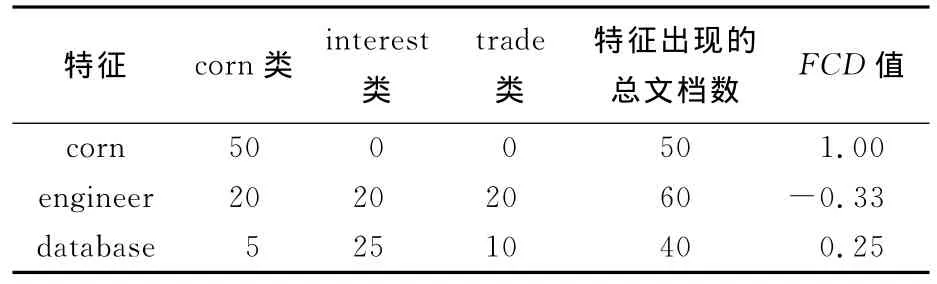
表1 在一个简单的语料集上特征的FCD值比较Tab.1 Comparison between features FCD value in a simple corpus
2 实验结果
本文选择支持向量机(SVM)算法作为分类器,SVM是Vapnik提出的一种在缺乏先验知识的条件下,以最小化结构风险为目标,对有限样本进行学习的统计学习方法.Joachims于1998年将其引入自动文本分类研究领域,取得了非常理想的文本分类效果[11、12].为了说明本文方法的有效性,将其和一些常用的特征选择方法进行了比较.主要包括χ2统计法、文档频率、几率比及互信息选择方法,实验对比结果在后文给出.
2.1 语料集
实验中使用了20Newsgroups[13]和reuters-21578[11]两个语料集.20Newsgroups语料集是由互联网用户在Usenet上张贴的19 997条消息组成的.这些消息分布在20个不同的新闻组中,每个新闻组对应一个文本类别.实验中使用了其20news-bydate-matlab语料集,该语料集详细的数据统计见表2.取其中的10个类别作为实验语料集,5 633篇文档作为训练集,3 742篇文档作为测试集.实验所采用的第2个语料集是reuters-21578,使用由David Lewis搜集的Mod Apte子集,包含reuters-21578最大的10个类,分别是acq、corn、crude、earn、grain、interest、money-fx、ship、trade、wheat.实验中随机选择训练文档7 193篇,测试文档2 787篇.训练集中类的分布是不均衡的,最大类有文档2 877篇,最小类只有181篇.
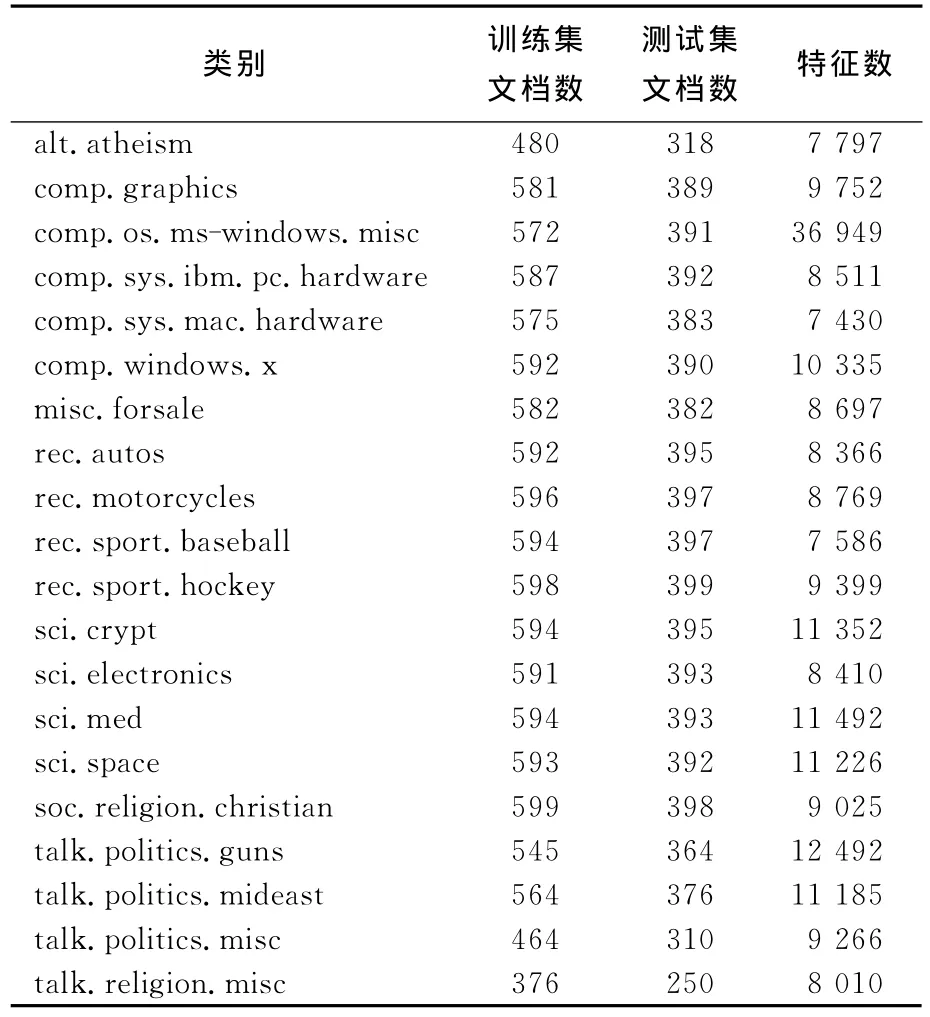
表2 20Newsgroups的bydate-matlab版本的语料集的数据统计Tab.2 Data statistics of 20Newsgroups corpus in bydate-matlab version
2.2 评价方法
文本分类的评价方法和准则不尽相同,本文使用宏平均F1(macro-averagingF1)和微平均F1(micro-averagingF1)[14]的评价方法.首先介绍查全率、查准率和F-Measure.查全率r和查准率p分别定义为
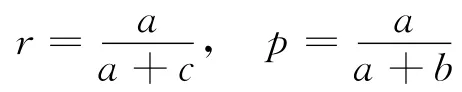
其中a表示分类器认为属于这个类而实际也属于该类的文档数,b表示分类器认为属于这个类而实际不属于该类的文档数,c表示分类器认为不属于这个类而实际属于该类的文档数.

其中β是一个调整参数,用于以不同的权重综合查全率和查准率.当β=1时,查全率和查准率被平等对待,如下式所示,这时F-Measure又被称为
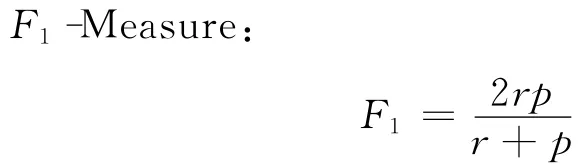
上面提出的查全率、查准率及F1-Measure都是针对单个类的分类情况而言的,当需要评价某个分类算法时,还需要将所有类上的结果综合起来得到平均的结果.综合的方法通常有两种,分别为宏平均F1和微平均F1,即
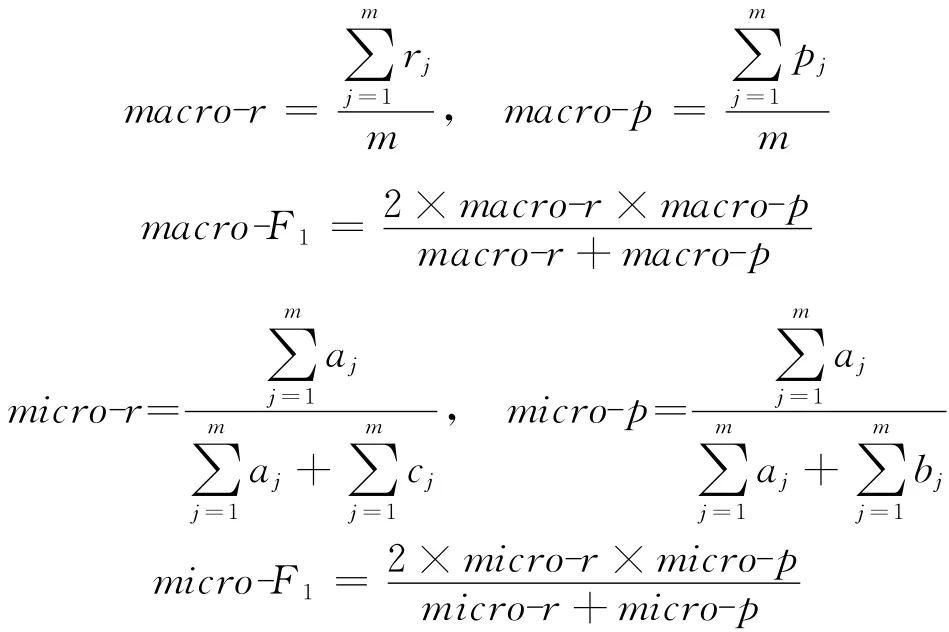
2.3 实验结果和分析
图1和2分别列出了在20Newsgroups语料集上使用各种特征选择方法的宏平均F1和微平均F1分类结果,从分类结果中可以看出,在选择10 000个特征时,FCD方法在所有列出的特征选择方法中分类效果最不好,其次是互信息方法;此时文档频率方法效果最好,其次是χ2统计方法,这可能与FCD方法和互信息方法选择了大量的低频词有关,而文档频率方法选择的都是出现频率最高的特征;在特征数逐步增大的过程中,FCD方法分类效果提高得非常明显,在特征数达到35 000时,分类效果最好,而文档频率方法在特征数增加时,其分类效果提高得很小,而互信息方法在特征数增大时,分类效果提高得比较明显.在特征数增大到一定程度时,FCD方法分类效果下降,这与其他的特征选择方法的结果相同.图3和4列出了在reuters-21578语料集上使用各种特征选择方法在SVM分类器上的宏平均F1和微平均F分类结果,从分类结果中可以看出,FCD方法在特征数增大时,分类效果提高得比较缓慢,而OR和MI方法则提高得最为显著.表3列出了所有特征选择方法在语料集上的宏平均F1和微平均F1的最大值,综合两个语料集上的分类结果来看,FCD方法在所列出的几种特征选择方法中为所有分类器效果最好的,这也验证了该方法的分类有效性.
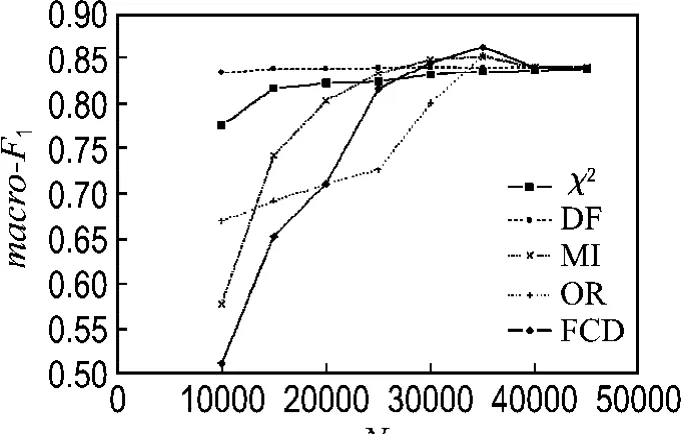
图1 有关的特征选择方法在20Newsgroups语料集上的宏平均F1值Fig.1 Macro-F1 values of relative feature selection methods in 20Newsgroups corpus
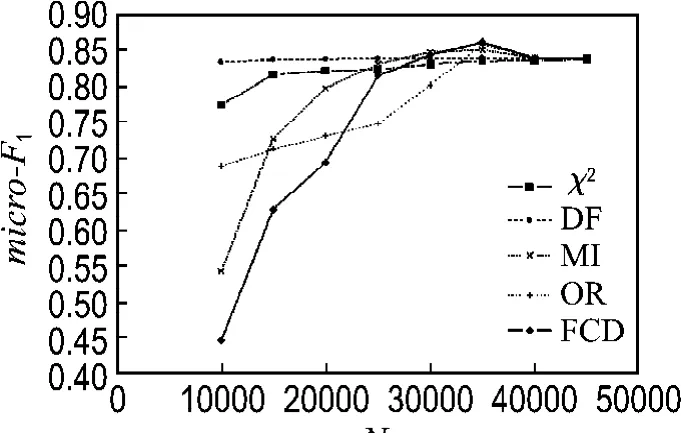
图2 有关的特征选择方法在20Newsgroups语料集上的微平均F1Fig.2 Micro-F1 values of relative feature selection methods in 20Newsgroups corpus
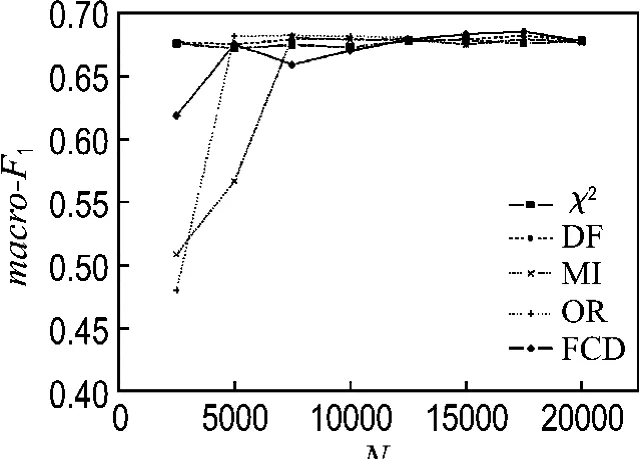
图3 有关的特征选择方法在reuters-21578语料集上的宏平均F1Fig.3 Macro-F1 values of relative feature selection methods in reuters 21578 corpus
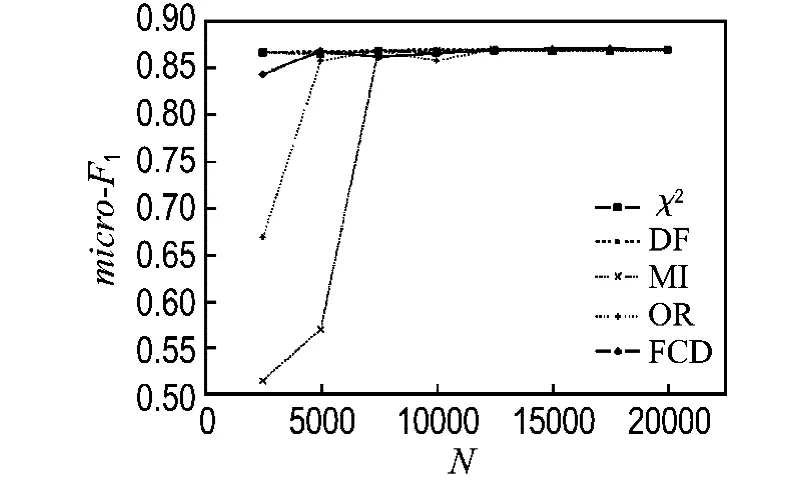
图4 有关的特征选择方法在reuters-21578语料集上的微平均F1Fig.4 Micro-F1 values of relative feature selection methods in reuters-21578 corpus
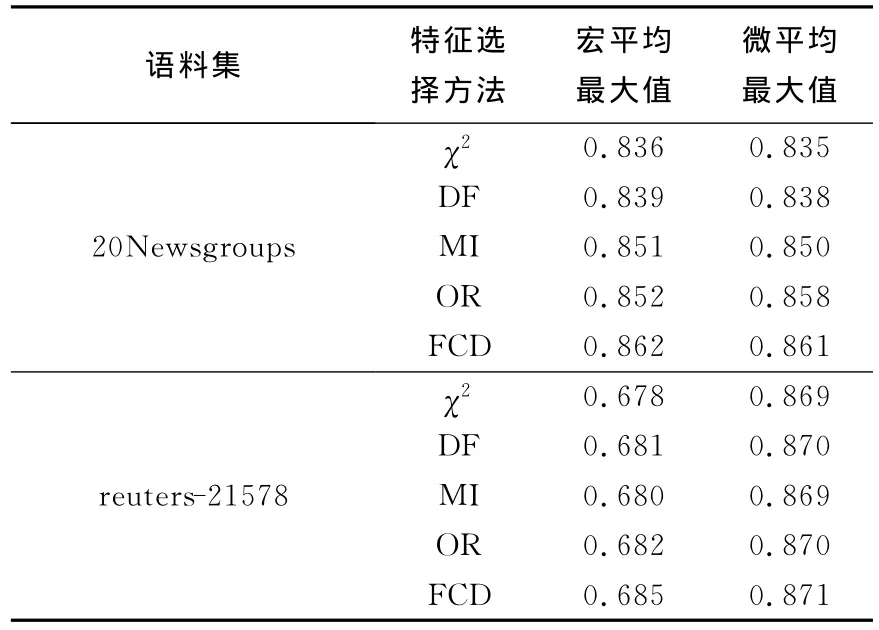
表3 有关的特征选择方法在两个语料集上的效果统计Tab.3 Performance statistic using relative feature selection methods in two text corpuses
3 结 语
文本分类是信息检索、信息过滤和搜索引擎工作的技术基础.文本特征的高维性是影响各种分类器分类精度和效率的一个重要因素,如何进行有效的特征降维成为文本分类的一个研究热点.因为文本分类是一个分类问题,所以类别信息对于特征选择是很重要的.本文提出了一种称之为FCD的特征选择方法,该方法利用特征的统计结果将对于类别区分具有高贡献度的特征过滤出来,实验结果表明该方法与其他几种常用的特征选择方法相比简单、有效,该结果在20Newsgroups和reuters-21578语料集上得到了验证.
未来的工作将集中在将该方法用于具有更多特征和文档的大语料集上,同时FCD方法没有考虑何时特征和类别共现,何时特征和类别不共现,如果将该统计结果加入到特征选择方法中,可能分类效果会得到提高.
[1]MITEHELL T.Machine Learning[M].New York:McGraw-Hill,1997
[2]MCCALLUM A,NIGAM K.A comparison of event models for Nave Bayes text classification[C]//Proceedings of the AAAI-98 Workshop on Learning for Text Categorization.Wisconsin:AAAI Press,1998
[3]COVER T M,HART P E.Nearest neighbor pattern classification[J].IEEE Transactions on Information Theory,1967,13(1):21-27
[4]ADWAIT R.Maximum entropy models for natural language ambiguity resolution[D].Pennsylvania:University of Pennsylvania,1998
[5]NG Hwee-tou,GOH Wei-boon,LOW Kok-leong.Feature selection,perceptron learning,and a usability case study for text categorization[C]//Proceedings of the 20th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press 1997
[6]VAPNIK V.The Nature of Statistical Leaning Theory[M].New York:Springer-Verlag,1995
[7]YANG Y,PEDERSEN J.A comparative study on feature selection in text categorization[C]//Proceedings of the 14thInternational Conference on Machine Learning(ICML′97).Nashville:Morgan Kaufmann Publishers,1997
[8]MLADENIC D,GROBELNIK M.Features selection for unbalanced class distribution and Nave Bayes[C]//Proceedings of the 16thInternational Conference on Machine Learning.Slovenia:Morgan Kaufmann Publishers,1999
[9]FORMAN G.An extensive empirical study of feature selection metrics for text classification[J].Journal of Machine Learning Research,2003,3(7-8):1289-1305
[10]徐 燕,李锦涛,王 斌,等.基于区分类别能力的高性能特征选择方法[J].软件学报,2008,19(1):82-89
[11]JOACHIMS T.Text categorization with support vector machines:Leaning with many relevant features[C]//Machine Learning:ECML-98.Chemnitz:Springer,1998
[12]JOACHIMS T.Making large-scale SVM learning practical[M]//Advances in Kernel Methods:Support Vector Learning.Cambridge:MIT Press,1999
[13]LANG K.NewsWeeder:Learning to filter netnews[C]//Proceedings of the 12th International Conference on Machine Learning.San Francisco:Morgan Kaufmann Publisher,1995
[14]YANG Yi-ming.An evaluation of statistical approaches to text categorization[J].Journal of Information Retrieval,1999,1(1-2):67-88
