P-Grid覆盖网络的加速收敛构建算法*
2010-03-16宋玮赵跃龙
宋玮 赵跃龙
(华南理工大学计算机科学与工程学院,广东广州 510006)
结构化 P2P覆盖网络按照一定的逻辑拓扑结构将系统物理层的节点相互连接起来.在覆盖网络提供的加入、路由、查找、退出等基本功能之上可实现不同的应用服务.目前已有的建立在覆盖网络之上的P2P数据存储系统有:使用MIT提出的Chord覆盖网络建立的开放文件存储环境 CFS[1];使用Berkeley提出的Tapestry覆盖网络建立的Ocean-Store[2];使用微软亚洲研究院提出的Xring覆盖网络建立的面向较少更新的存储系统BitVault[3]以及清华大学提出的采用Tourist路由算法建立的面向对象的存储系统Granary[4].覆盖网络层是整个P2P存储系统运行的基础,其特性影响到整个系统的特性,是系统成功与否的关键.
P-Grid覆盖网络是一个分布式信息管理的P2P平台,具有完全分散管理、自组织[5-6]、基于动态 IP的数据管理(更新)[7-8]、分布式负载平衡[9-10]等特点.覆盖网的构建基于随机算法和本地交互,面向低在线率的节点环境,该网络既具有虚拟树的结构,能以树的形式组织资源实现系统的层次化管理,提高资源查找效率,又摆脱了基于树的覆盖网络结构(如MPPBTree[11],BATON[12])中对根节点的依赖,非叶节点并不对应实际的对等节点,各节点最终成为叶节点.整个树的构建过程不需要中心协调,节点随机漫步导致的相遇是树构建的动力,这样一来,树形成的速度(即收敛性)便是一个关键,它严重影响整个系统的性能.文中重点在两种情况下讨论了PGrid的收敛性,改进了原有算法以加快构建速度,为今后建立在其上的应用系统提供更好的支撑.
1 P-Grid概述
1.1 P-Grid数据结构
文献[5-6]描述了P-Grid系统中基于虚拟二叉搜索树的覆盖网络及路由算法.系统中每个对象,包括对等节点和数据对象都拥有一个二进制索引值,对等节点还拥有路径值(表示为path(peer)),表明节点在二叉树中的路径,动态形成于虚拟二叉树的构建过程.每个对等节点根据其路径值对应一个索引值区间;每个对等节点含有两类信息:数据索引信息和路由信息.数据索引信息是存储索引值最大前缀与节点路径值相同的数据对象的索引信息.图 1所示的P-Grid实例中节点4的路径值为010,则存储以 010为前缀的数据对象的索引信息.节点路由信息形成路由表,表中每一层路由项指向树中与该节点在路径值某位上具有相反值的节点信息.如节点 4中第二层路由项 00:7说明路径值第二位与节点4相反的是节点 7.这样当节点 4收到查找索引值00*的请求时,就可以将其转发到节点7.
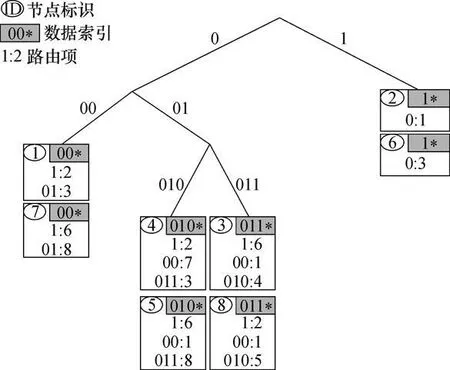
图1 P-Grid实例Fig.1 P-Grid example
1.2 P-Grid构建过程
P-Grid中节点被假设局部随机相遇,而不考虑是何种原因相遇.相遇后根据双方已有的路径值划分并负责索引值空间,路径值做相应的调整.节点路径的初始值表达为*,说明其初始负责全体索引值空间.下面简单描述文献[5]中的P-Grid构建算法.节点相遇有3种情况:(1)两节点原有路径值相同(CASE1).如path(a1)=10,path(a2)=10,则两者对10*空间进一步划分,或者二者互为冗余节点共同负责10*空间;划分后path(a1)=100,负责100*空间; path(a2)=101,负责101*空间.(2)两节点路径值是一个子串关系(CASE2和CASE3).如path(a1)=10, path(a2)=101,此时让path(a1)=100.(3)两节点负责不同的空间(CASE4),如path(a1)=10, path(a2)=01,则两节点根据自身的路由信息,相互把对方推荐给在另一空间的其它节点;若a1的一条路由表项为0:a3,则说明a3负责0*空间,a1将a2推荐给 a3,a2将和 a3根据相遇情况选择处理方式,这有可能再次产生推荐;这样,整个二进制索引值空间被动态地划分并被各对等节点管理.
1.3 P-Grid的收敛性
P-Grid的路径长度是动态变化无限制的,这也是它和其它覆盖网络的区别.因此收敛性表现为在节点规模一定的前提下,多少次交互后每个节点的路径不再变化,或是到达指定的长度,或是达到其它的限制条件.文献[5]通过实验指出了 3个参数对交互次数的影响:(1)推荐(递归)深度recmax,即CASE4导致再次推荐的次数.recmax=0表示不推荐,即,若出现CASE4情况相遇节点相互不推荐,这导致整个构建过程的交互次数较多.采用适当的深度值可以使交互成功的概率增大,但递归深度过大反而会导致节点过度细化,而使交互次数增多,文献实验指出recmax=2较好.(2)最大路径长度k.这里并不是将P-Grid的路径长度限制为k,而是指在节点个数允许的情况下,想达到的 k越长则需要的交互次数越多.(3)节点每层路由项中节点的个数refmax,refmax为在CASE4情况下进行节点推荐的最大个数,推荐的个数越多,交互次数越多,文献实验指出当推荐选择一个节点时效果最好.下面讨论的收敛速度的提升是在指定k、recmax、refmax以及推荐个数的基础上进行的.
2 提高收敛速度的改进算法
提高收敛速度的改进算法基于以下两个前提:
(1)忽略节点动态性对构建过程中路由维护带来的影响,将提高两个在线节点交互的有效性与路由维护看成独立的两个内容,不管算法如何改进都无法影响节点的上线和离线行为,所以将节点的动态行为对构建的影响看成是一个不变的量,不再计入评价范围内.
(2)P-Grid不仅仅用于动态的P2P系统,还可以作为任何一个分布式应用需求下的基础结构.PGrid的构建过程在分布式应用中可位于两个不同阶段:第一,在完全新的分布式应用中P-Grid的构建位于初始化阶段,节点专用于该应用,此时节点上不存在任何数据索引信息;第二,在已有的分布式应用中,由于某种原因,要求利用P-Grid重建基础结构,此时节点上将保留原有的共享数据索引信息.下面的讨论与改进将从构建前节点无数据索引和有数据索引两方面进行.
定义1 数据索引的消耗 数据索引在节点上的存储除了带来存储上的消耗.还带来其它的消耗,如某一数据是热点数据,则将为存储它的索引的节点带来较高的访问频率,这可看成对节点的一种消耗.这里并不区分特定的消耗类型,每一个数据索引将因为其自身数据的特点给节点带来不同的消耗.同时假设数据索引的消耗是可分的,即当一个数据索引被复制到另一个节点上时,其消耗也将被分割一部分到该节点;而当一个索引被转移至另一节点时,则其消耗也被转移.
定义2 节点的意愿 每个节点会根据自己的资源现状给出承担数据索引消耗的总意愿,如设置访问次数的上限防止对数据索引的过多的查询.
定义3 节点的负载 存储数据索引值带来的总消耗称为节点的负载.
定义4 节点的初始负载量loadpercentage 节点在进入交互前因为其它原因而具有的负载量,用节点的负载与节点意愿的比值表示.
定义5 Ignore-of-Load构建算法 构建过程中不考虑节点的初始负载量.
定义6 Care-of-Load构建算法 构建过程中考虑节点的意愿及初始负载量.
定义7 数据索引路径符合度satisfy 一个节点存储的数据索引中符合与节点路径具有最大前缀关系的索引个数百分比.节点路径为“*”时路径符合度为1.
定义 8 收敛状态参数 描述交互算法的状态,用于衡量收敛性,采用路径长度k和符合度 satisfy两个参数.在Care-of-Load情况下,受节点意愿的限制,导致本该能转移的数据索引无法转移,因此要求已存在的索引都转移到具有最大前缀关系的节点上所需的交互次数非常大,所以应该设置一定的符合度来描述收敛状态.
定义9 收敛速度 达到指定收敛状态参数值产生的节点交互次数.
2.1 Ignore-of-Load构建算法
每次交互引起的路径变化程度以及推荐的成功率影响交互的次数.原有构建算法中路径的改变以“1位”为单位,如:两节点a1、a2相遇,path(a1)= 01001、path(a2)=01,向下划分后路径为path(a1)= 01001、path(a2)=011.对于a2需要更多的交互才能使其路径向下延伸.为了充分利用每次交互的信息,减少交互的次数,给出如下式所示的改进1:
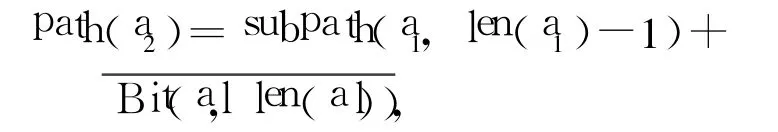
即直接将a2的路径延长为path(a2)=01000,使其最后一位与a1相反,a2与 a1交换前4层的路由.
根据原构建算法,节点p向节点q推荐节点r采用的推荐方式有两种,一种是在 p的路由表中随机选取节点r[5],另一种是选取p的路由表中与q具有最大共同前缀的节点[9],但文献并未对这两种方式做出比较.通过观察节点的路由表的特点,以path(q)=101、path(p)=01为例,若p的路由表第一层为1:a3(111),a4(100),a5(101),a6(10110),可以看出选择推荐a6和a5会使q路径向下划分,而选择a3则在q和 a3的交互过程中需要在第二层进行推荐,若推荐的节点不合适还要进行第三层的推荐,a4比 a3的情况好一点,只需要在第三层推荐一次.根据该特点给出改进2以提高推荐的成功率:
p从路由表中首选一个以 q路径为子串的节点;若没有,则选与q同路径的节点;若再没有,则再选与q具有最大共同前缀的节点;若还是没有,则最后随机选.
2.2 Care-of-Load构建算法
在构建覆盖网络的过程中,数据索引会随着节点路径的形成而转移到具有最大前缀关系的节点上.这里讨论 3种思路,采用路径长度及符合度作为收敛状态参数.
2.2.1 以路径为主导的构建算法
以路径为主导的算法指节点路径的向下延伸与数据索引的转移是独立的,即节点路径向下延伸不受节点意愿和索引消耗的影响,而数据索引的转移则是在每次节点相遇时根据双方的路径和意愿尽量将索引转移到对方.因此该算法的实现直接在2.1节的两个改进上进行,在每个CASE结束后加入数据索引交换环节.最优交换是一个最优组合问题,这里不考虑最优化的问题,只关心尽可能多地进行索引的交换.交换分冗余和转移两种,当两节点路径值相同时,相互冗余数据索引,否则根据对方路径转移.一个数据索引被冗余到目标节点上,意味着减轻源节点一半的消耗,则索引消耗也将被分割一半到目标节点;而一个索引被转移目标节点,则其消耗也被转移.
2.2.2 以数据索引为主导的构建算法
采用2.2.1节的算法每个节点可以很快达到指定的最大路径长度,但符合度低,为了达到指定的符合度则需要花费更多的交互次数.文献[8]给出了考虑数据索引的思路:当两个节点相遇,若每个节点都能将两个节点所拥有的所有数据索引全部放下,则两节点冗余,否则就分区.但该文献假设所有节点是同质的且具有相同的意愿,并且节点的意愿仅体现为愿意管理的数据索引个数,数据索引之间无差别.这里结合节点的意愿和索引消耗对文献[8]的算法进行扩展,形成以数据索引为主导的构建算法.算法中路径的延长不是任何时候都可以进行的,即,原算法CASE1中先进行是否冗余(isRedundent)和是否下分(isDivide)的判断,在CASE2和CASE3中先进行是否延伸路径的判断(isExtend).
isDivide的思路如下:Max(Min)表示两个节点中具有高(低)意愿的节点;Ci是节点i中与两节点路径都不符的索引消耗总和;Preferi表示节点i的意愿;Totall表示两个节点中以path+l为路径的索引消耗总和,path表示两节点的路径(此时路径相同),l∈{0,1}.当存在l∈{0,1}使
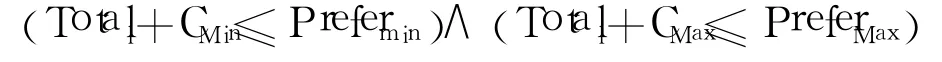
成立时,则可以下分,即下分依赖于即将形成的两个分区中的索引是否可以分别放在两个节点中.
isRedundent的思路如下:Ax表示节点x中与相遇节点共有的且符合路径的数据索引消耗总和,Bx表示节点 x独有且符合路径的数据索引消耗总和, a1和a2表示相遇的两个节点,当下式成立才能进行冗余:
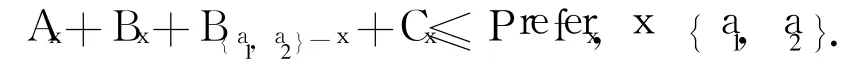
对于isExtend,只有当长路径的节点能够完全接受短路径转过来的索引消耗时,短路径才能向下延伸一位.
2.2.3 具有符合度调整的构建算法
在2.2.2节算法中,尽管符合度相对较高,但路径的延伸过程非常慢,若每个节点的意愿足够大将导致一个节点放置所有的数据索引,而这样的结果对于构建P-Grid意义不大.因为P-Grid路由结构的建立是本研究的主要任务,构建过程会影响索引的分布,这里仅仅期望索引能随构建过程达到一个较好的调整.
为了在收敛速度及符合度间获得一个平衡,对2.2.1节算法进行改进,形成具有符合度调整的算法.算法中的函数Peer.FindPeer()用于在节点交互结束后各自依据自身的路由信息尽量将索引转移到合适的节点,以此提升符合度.Peer.FindPeer()算法如下:


通过分析可知一个节点中需要转移的索引所具有的特点,如路径为 0101的节点,其不合路径的数据索引可分为 1、00、011、0100 4类,这正好与每层路由表项的前缀是一致的.因此可以考虑在路由表中选择节点进行索引的转移以提高符合度,但由转移导致的交互也应该统计进入交互总数.此外存在一个现象,即节点a、b经过CASE1、CASE2、CASE3向下延伸后,a的最后一层路由表项往往只有一个节点b,或是b的最后一层路由表项只有一个节点a,此时再次进行转移意义不大,需要利用倒数第二层表项来提高符合度.以a(0101)节点为例,若倒数第二层路由表项为011:a3(011),且a3的最后一层路由为010:a4(010),a5(0101),a6(0100),则若能挑出a6,将a上形如 0100的索引转过去,将会提高a的符合度.
3 算法分析
3.1 Ignore-of-Load算法中路由更新相关问题
每个节点由于承担路由功能而成为路由表项中的一员,节点的路径是推荐的依据.路由的更新来自于两节点交互时充分交换最新信息.这里不讨论如何设计出更好、更新的算法,侧重分析在采用与原算法相同的更新算法下,Ignore-of-Load构建算法是否会加重更新的负担,以及未及时更新的路由信息是否对推荐产生影响.
(1)路由更新的负担与节点路径改变的概率相关.考虑到节点路径的改变导致路由需要更新,将路由更新的负担定义为整个系统中单位时间内路径改变的节点个数.设每个节点在每次相遇中改变路径的概率是s,在一定的时间段t内,有n个节点相遇,则单位时间内改变路径的节点为ns/t个.在节点相遇频率不变的情况下,s越大,则更新负担越大.
(2)原算法一次相遇中节点路径改变的概率为1/2len(p),改进 1不影响路径改变概率.设节点 p的路径为l1l2…llen,lj(0,1),j[1,len],节点路径的改变来自于与同路径或前缀为 l1l2…llen的节点相遇.设索引值均匀分布,节点相遇的概率平等,不存在过多的节点负责某些分区,则与相遇的节点第一位相同的概率为1/2,在第一位相同的情况下第二位相同的概率为1/22,这样在前len-1位相同下最后一位相同的概率为 1/2len(p),则路径改变的概率为1/2len(p).
按照改进 1的延伸方法也不能导致负责某些特定分区的节点增多,如对于path(a1)=01与path(a2)= 01001相遇,使path(a1)=01000,这并不意味着负责0100区域的节点增多,因为根据P-Grid结构若存在path(a2)=01001,则必然会存在路径为1*、00*、011*、0101*的节点,而节点相遇的概率是一样的,这样仍然不存在过多的节点负责某些分区,从而不影响路径改变概率.
从上面可知路径改变的概率不变,这样改进 1不会加重更新的负担.
(3)延时更新的节点路径不会导致改进 2低于原算法的收敛速度.节点路径的变化是在前一次的路径基础上向下延伸,必定存在前缀关系.这样对于未及时更新的节点,在改进 2中只是降低了它被推荐的可能性.以path(q)=101、path(p)=01为例,若p当前的路由表第一层为1:a3(111),a4(100), a5(101),a6(10);而 a6(10)实际的路径为a6(10110),这样根据改进 2,a5被优先选择,但这种选择仍然优于原算法随机方法或原算法最大前缀方法.因此改进算法不会低于原算法的收敛速度.
3.2 改进算法产生二叉树的特性
特性1 Ignore-of-Load构建算法、以路径为主导的构建算法及具有符合度调整的Care-of-Load构建算法产生的是一棵完全二叉树.指定最大路径长度,在节点数量足够的情况下,短路径的节点总会与长路径的节点相遇从而延伸直到所有的节点都达到最大路径,并且根据P-Grid的构建特性,节点路径的每一位上都至少存在一个节点与之具有相反位.
特性2 Ignore-of-Load构建算法、以路径为主导的构建算法及具有符合度调整的Care-of-Load构建算法最终产生前缀码.与特性 1的分析类似,如果存在一个节点,它是另一个节点的前缀,则说明构建还未完成,前一个节点必定会向下延伸,且最后一位相反.
特性3 以数据为主的Care-of-Load构建算法不保证产生前缀码.原因在于路径的向下延伸受节点意愿的制约,使得路径停留在某个长度.
3.3 数据索引查找成功率
设路径长度为k,节点数为N,则第h层各分区拥有的平均节点数为N/2h,h[0,k],定义T为单个节点拥有的符合路径的索引占其负责分区的总索引数比例,一般使refmax≤N/2h并对所有层取相同值,节点在线概率为Pr,则Care-of-Load构建算法中对数据索引的查找成功率为(1-(1-Pr)refmax)k× T.当不考虑节点的离线情况时Pr=1,则成功查找率由T决定.
最坏情况下的成功查找次数为log2(N/r′)× refmaxΘ(log2N),r′为负责最低层分区的节点平均个数.
4 模拟实验
模拟实验采用P2P模拟器Peersim[13],PeerSim是一个Java编写的模拟P2P Overlay的软件.使用Peersim提供的占用较少资源的Cycle-based的模拟方式,模拟实验共同参数定义为:recmax=2,最大路径长度k=6,refmax=10,推荐时采用1个节点.
4.1 Ignore-of-Load构建算法的模拟实验
节点规模 N分别为 400、600、1000时,对原算法随机版、原算法最大前缀版及 3个改进算法(改进 3为 1和 2的组合)分别执行 100次后的平均交互次数如图2所示.
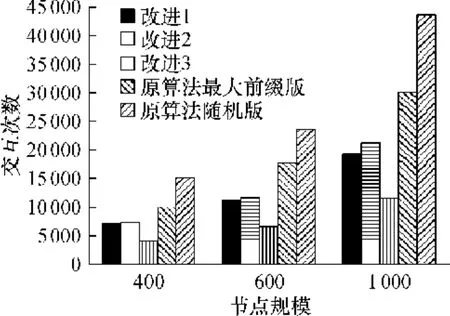
图2 5种Ignore-of-Load算法的交互次数Fig.2 Number of communications times of five Ignore-of-Load algorithms
由图 2可见,3个改进算法带来的效果是非常明显的.特别是改进 3,交互次数的减少量超过原算法最大前缀版的50%.
4.2 Care-of-Load构建算法的模拟实验
数据索引的消耗以及数据索引的副本个数采用平均分布和Zip f分布,在不同的分布下分别比较3种Care-of-Load构建算法在交互过程中的交互次数及查找失败率.
4.2.1 平均分布
节点规模 N=400,每个节点的意愿数量级为103,平均分布在[1000,10000]之间,数据索引规模M=1000,数量级为 102,平均分布在[100,1 000]之间,数据索引在每个节点中存储的概率是平等的.
3个算法在一次构建过程中平均路径长度及符合度的变化趋势如图 3所示,设随机进行 20000次交互.

图3 3种Care-of-Load构建算法平均路径长度及平均符合度的变化趋势Fig.3 Average path length and average satisfaction of three Care-of-Load algorithms
从图 3可见,以路径为主导的算法在路径的延伸上很快,但符合度的下降也很迅速;以索引为主导的算法正好相反;具有符合度调整的算法效果是两者的折中,并且符合度可以达到最好.同时由图 3可见,3种算法中,数据的转移跟不上路径延伸的速度,当路径达到指定长度后,接下来的交互仅仅是在进行数据索引的交换,而这个过程是缓慢的.
3种算法在不同的loadpercentage下同时达到指定路径长度和符合度(satisfy=0.8)所需的交互次数如图4所示.考虑到以数据索引为主导的算法在路径延伸上的缺陷,参数设置为当loadpercentage= 0.2,0.3,0.4时,指定k=2.8,4,5;loadpercentage= 0.5,0.6,0.7,0.8时,k=5.5.以路径为主导的算法和具有符合度调整的算法k=6.
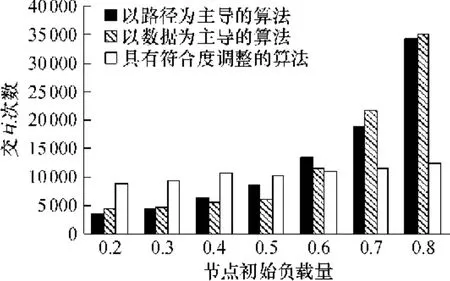
图4 3种Care-of-Load构建算法的交互次数Fig.4 Number of communications of three Care-of-Load algorithms
图4所示结果说明:(1)当loadpercentage≤0.5时,以路径为主导的算法的交互次数偏小,其原因之一为较小的loadpercentage使得当路径达到指定长度时,无需过多的交互用于数据索引的交换,但随着loadpercentage的增加,需要大量的交互用于数据索引的交换;原因之二为构建过程的终止条件satisfy=0.8是一个较容易达到的条件,若将satisfy设置得更高(如satisfy=0.9),则该算法不如具有符合度调整的算法(见图5).另外在loadpercentage偏大时表现良好的算法才有意义,因为较小的loadpercentage无法体现出初始负载对构建过程带来的影响. (2)当loadpercentage≤0.5时,以数据索引为主导的算法的交互次数偏小,但存在 2.2.3节中所述的缺陷,每个节点将放置所有的数据索引,而这样的结果对于构建P-Grid意义不大.(3)具有符合度调整的算法在具有较大loadpercentage时表现良好,因为通过符合度的调整,使得节点交互具有针对性.
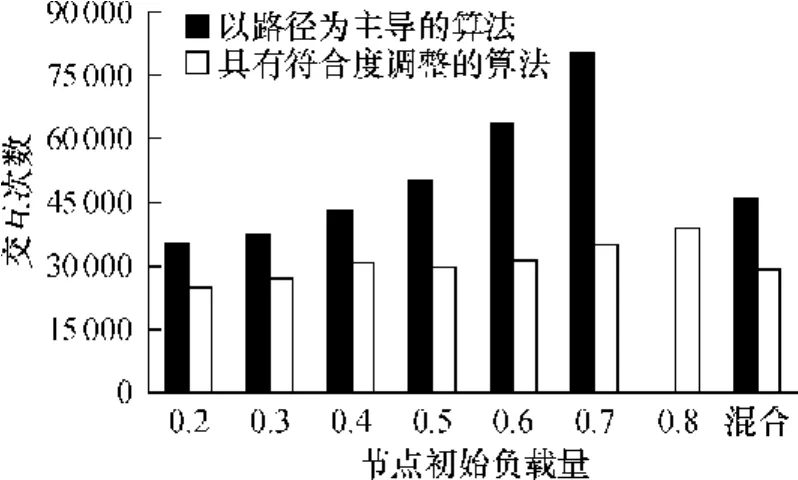
图5 Zipf分布下的交互次数Fig.5 Number of communications Zipf distribution
以数据为主导的算法和具有符合度调整的算法对初始数据索引的查找失败率如表1所示.loadpercentage的取值在0.2~0.8之间,并采用了一个混合比例即每个节点的loadpercentage随机在0.2~0.8之间取值;每个初始值下两类算法各产生 20个P-Grid结构,对每个结构查询 2000次,统计失败的次数;为了比较两类算法对查找的影响,设节点总是在线.表1中A和C表示以数据为主导的算法失败次数和节点拥有索引占分区平均比例,即 3.3节中定义的T;B和D表示具有符合度调整的算法失败次数和节点拥有索引占分区平均比例.表 1所示结果说明:(1)查找失败率与节点拥有索引占分区平均比例相关,如119≈2000×(1-0.92);(2)当loadpercentage为0.2~0.4时,A与C的值不符合(1)的结论,原因在于,其路径长度不超过 4,分区拥有的索引多,但因为剩余意愿大,所以每个节点都极大地放置了该分区的索引,使得整体查找失败率减少;(3)随着loadpercentage的增加,具有符合度调整的算法表现出较好的查找效果,原因在于有针对性地转移了数据.
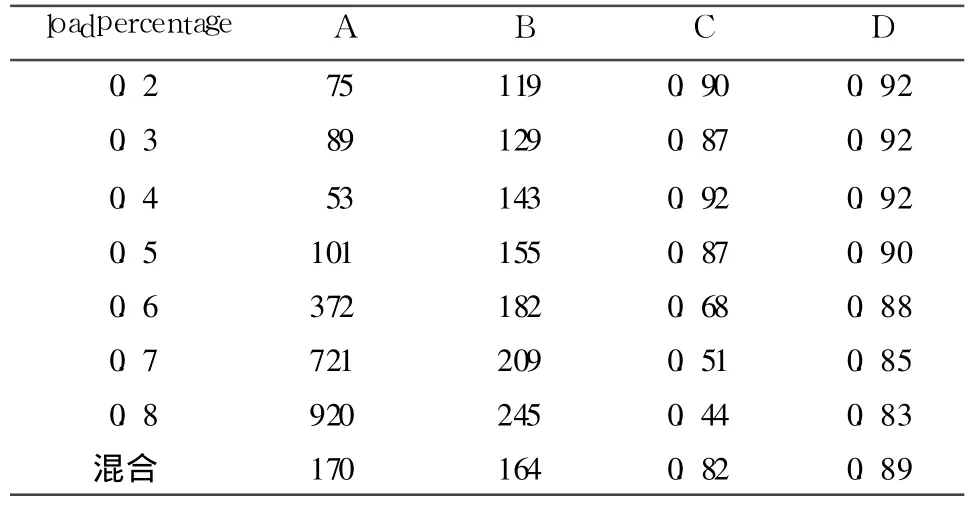
表1 平均分布下的查找失败率Table 1 Search failure rate in average distribution
4.2.2 Zipf分布
文献[14]总结出 P2P环境下副本的数量和流行程度遵循Zipf分布.模仿文献[15]产生Zipf分布数据的方式,选定一个特定的文档将其中出现的不同的单词个数(1793)作为数据索引个数,单词出现的频率(不超过850)作为索引的消耗,并且同时作为索引的副本个数,使得数据索引的消耗以及索引的副本个数符合Zipf分布.设置节点规模为1 000,数据索引规模M=1793.3种算法的平均路径长度及符合度的变化趋势与平均分布下的趋势一致,这里不再给出图形结果.
比较以路径为主导的算法和具有符合度调整的算法在不同的loadpercentage下,同时达到指定k=6和satisfy=0.9所需的交互次数如图5所示.根据2.2.3节中的分析,这里不再比较以数据为主导的算法,因为最终的平均路径长度都在 2到 3的范围内,这样的构建意义不大.
由图 5可见,具有符合度调整的算法的效果较好.当loadpercentage=0.8时,以路径为主导的算法交互次数已超过 100000次,因此未在图上显示.
具有符合度调整的算法对初始数据索引的查找失败率如表 2所示.同前,这里不再比较以数据为主导的算法的失败率.
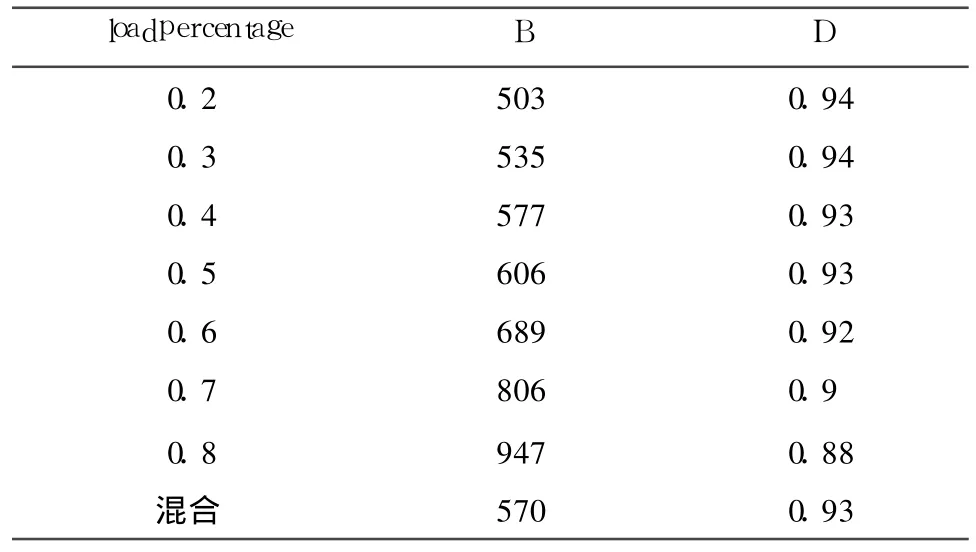
表2 Zip f分布下的查找失败率Table 2 Search failure rate in Zip f distribution
loadpercentage的取值在0.2~0.8之间,并采用了一个混合比例.每个初始值下两类算法各产生 20个P-Grid结构,对每个结构查询 10000次,统计失败的次数.表 2中符号定义与表1相同.从实验结果可知,具有符合度调整的算法的查找失败率与 T相关,并且查找成功率在90%左右.
5 结语
(1)P-Grid构建算法的收敛速度是影响建立在其上系统性能的关键因素,文中针对构建的两种初始情况Ignore-of-Load和Care-of-Load,对原构建算法进行改进;改进的算法能保持原算法的分散性和自组织性,且不增加路由更新的负担.
(2)模拟实验结果表明,Ignore-of-Load构建算法能减少原算法交互次数的50%以上;具有符合度调整的Care-of-Load构建算法在交互次数上表现良好,并且对数据索引的查找成功率在90%左右.
[1] Dabek F,Kaashoek M,Karger D.W ide-area cooperative storage with CFS[C]∥ACM Symposium on Operating Systems Princip les.New York:ACM,2001:202-215.
[2] Kubiatowicz J,Wells C,Zhao Ben.Oceanstore:an architecture for global-scale persistent storage[J].ACM SIgpan Notices,2000,35(11):190-201.
[3] Zhang Zheng,Lian Qiao,Lin Shi-ding.Bitvault:a highly reliab le distributed data retention p latform[J].ACM SIGOPSOperating Systems Review,2007,41(2):27-36.
[4] 胡进锋,洪春辉,郑纬民.一种面向对象的Internet存储服务系统Granary[J].计算机研究与发展,2007,44 (6):1071-1079.
Hu Jin-feng,Hong Chun-hui,Zheng Wei-min.Granary:an architecture of object oriented internet storage service [J].Journal of Computer Research and Development, 2007,44(6):1071-1079.
[5] Karl Aberer.P-Grid:a self-organizing access structure for P2P information system s[C]∥Proceedings of the 9th International Conference on Cooperative Information Systems.Berlin/Heidelberg:Springer,2001:179-194.
[6] Karl A,Magdalena P.Im proving data access in P2P systems[J].IEEE Internet Computing,2002,6(1):58-67.
[7] Karl A,Anwitaman D,Manfred H.Effcient,self-contained handling of identity in Peer-to-Peer systems[J].IEEE Transactions on Knowledge and Data Engineering,2004, 16(7):858-869.
[8] Manfred H,Anwitaman D,Karl A.Handling identity in Peer-to-Peer systems[C]∥Proceedings of the 14th International Workshop on Database and Expert Systems App lications.Washington:IEEE Computer Society,2003: 942-946.
[9] Karl A,Anwitaman D,Manfred H.Multifaceted simultaneous load balancing in DHT-based P2P systems:a new game with old balls and bins[EB/OL].(2005-01-01). http:∥www.p-grid.org/publications/papers/SelfStar2005. pdf.
[10] Karl A,Anwitaman D,Manfred H.The quest for balancing peer load in structured Peer-to-Peer systems[EB/OL]. (2003-01-01).http:∥www.p-grid.org/pub lications/ papers/TR-IC-2003-32.pdf.
[11] Xu Li-bo,Wu Guo-xin,You Feng-qin.A structured P2P system withmatch path and probability balance tree[C]∥Proceedings of the First International Multi-Symposiums on Computer and Computational Sciences:Volume 2. Washington:IEEEComputer Society,2006:167-174.
[12] Jagadish H V,Beng C O,Quang H V.BATON:a balanced tree structure for Peer-to-Peer networks[C]∥Proceedings of the 31st International Conference on Very large Data Bases.Norway-Trondheim:VLDB Endowment,2005:661-672.
[13] Márk J,Alberto M,Gian P J,et al.PeerSim:a Peer-to-Peer simulator[EB/OL].(2009-01-01).http:∥peersim.sourceforge.net/.
[14] 张泰乐,查冰,王劲林.对等网络上数据分布模型的分析[J].电子技术应用,2006,32(1):46-47.
Zhang Tai-le,Zha Bin,Wang Jin-lin.Analysis of content distribution in P2P files-share system[J].Application of Electronic Technique,2006,32(1):46-47.
[15] 刘德辉,周宁,尹刚,等.QFMA:一种支持负载均衡的多属性资源定位方法 [J].计算机学报,2008,31 (8):1376-1382.
Liu De-Hui,Zhou Ning,Yin Gang,et al.QFMA:an approach for multi-attribute resource addressing with load balancing[J].Chinese Journal of Computers,2008,31 (8):1376-1382.
