基于Copula模型的降雨量与土壤饱和度的模拟研究*
2010-01-24王沁黄雁勇汤家法向波
王沁,黄雁勇,汤家法,向波
(1.西南交通大学数学学院,四川成都610031;2.西南交通大学土木工程学院,四川成都610031)
对一次泥石流而言,前期有效降水量和当次有效降水量共同决定了泥石流的形成[1],是泥石流预报的重要参数。前期降水的有效部分以土壤水的形式积累在土壤中,所以,流域的土壤饱和度状况,是形成泥石流的关键性水文因素之一。了解土壤饱和度的变化状况,对于泥石流预报中的前期降水条件评估以及理解泥石流的触发水文条件等方面都有重要的科学意义。
Copula连接函数是一种灵活、稳健的相关性分析的工具,它将边缘分布及相关性结构分开处理,度量了变量之间的相关程度和相依模式,与面向均值、方差和线性相关的建模方法不同,对整个联合分布建模提供更多有用信息,在金融领域[2-4]、水文领域[5-9]、概率地震危险性[10]分析等方面得到广泛应用。
Zhang L应用Copula函数对静态与非静态的洪水、降雨和枯水进行了两变量及三变量的频率分析[5],并用Copula函数拟合河道中流速和水深的联合分布,还进行了水质的多变量分析;Salvadori和De Michele[9]基于Copula函数进一步研究了暴雨统计量的联合分布,进而推导出暴雨前某固定时段内降雨量和前期土壤饱和度的分布函数。
本文以云南东川蒋家沟为研究对象,以一个基于小流域水分循环的基本物理过程所开发的土壤饱和度模拟模型为基础[11-12],获得了流域内的土壤饱和度与降水量两个变量的数据。基于土壤饱和度与降水量的样本数据,采用皮尔逊Ⅲ型分布拟合土壤饱和度与降雨量,选用能够较好反映降雨和土壤饱和度之间相关结构的Clayton Copula函数,建立两变量联合分布,分析两变量重现期,模拟了流域内土壤饱和度的变化情况。
1 Copula连接函数与Clayton Copula函数
假设随机变量(X1,X2)的联合分布为H(x1,x2),边缘分布函数分别为Fi(xi)=P(Xi≤xi),那么,存在唯一的连接函数Copula函数C(·)使得[13]:

式中:ui=Fi(xi)=P(Xi≤xi)是边缘分布函数,Ui=F(Xi)服从标准均匀分布。
设(X1,Y1),(X2,Y2)为相互独立,联合分布为H(x1,x2)的二维随机变量,则连接函数Copula的Kendall的秩相关系数为[13]:

Kendall的秩相关系数刻画了两个变量变化趋势是否一致。如果Kendall的秩相关系数为正值,说明两个变量变化趋势是正相关的,一个变量变大,另一个变量变大的趋势大;如果Kendall的秩相关系数为负值,说明两个变量变化趋势是负相关的,一个变量变大,另一个变量变小的可能性大。
Clayton Copula函数族,其连接函数为[13]:

其Kendall的τ为:

运用Copula连接函数构建模型,常采用两步法。第一步,利用某类分布或时间序列分析方法确定边缘分布;第二步,定义一个适当的连接函数Copula,以便能很好地描述出边缘分布的相依结构、相互耦合作用。由此看出,运用连接函数Copula描述多变量之间相互耦合时,可以将边缘分布和相关结构分开来研究,这有助于对很多变量的相互耦合作用进行分析和理解。
2 基本资料和边缘分布分析
流域水文条件变化是一个复杂的过程,降水通常是整个过程的开始,经过截留、渗透、蒸发等若干环节,最终改变土壤饱和状况。由于土壤饱和度的数据难以直接获得,文献[11-12]中,采用了一个基于水分循环物理过程的分布式水文分布模型获得了蒋家沟流域的不同降雨量下土壤饱和度逐日变化的数据[11],数据分布如图1所示,这也是本文分析所使用的数据。

图1 蒋家沟流域的不同降雨量下土壤饱和度的变化趋势图
从图1可以看出,流域的土壤平均饱和度从雨季开始呈上升趋势,一直到7月中下旬开始达到一个比较高的数值,一直到8月底都维持在较高的水平之上,但随着降水的变动而剧烈变化,到9月份随着降水的减少逐渐降低,最后稳定在一个较低的水平。所以,降水与流域的土壤平均饱和度二者存在着紧密的关系,但这种关系并不是简单的增加过程,而是复杂的非线性过程。
在水文分析计算,常采对数正态分布、指数分布、Gumbel分布及皮尔逊Ⅲ型分布等来分析洪峰、洪量等变量。本文采用均值参数为零的皮尔逊Ⅲ型(即三参数Gamma分布)分析土壤饱和度。参数估计的结果为:偏态系数(s)为1.005 2,变差系数为66.710 4,其QQ图如图2所示。
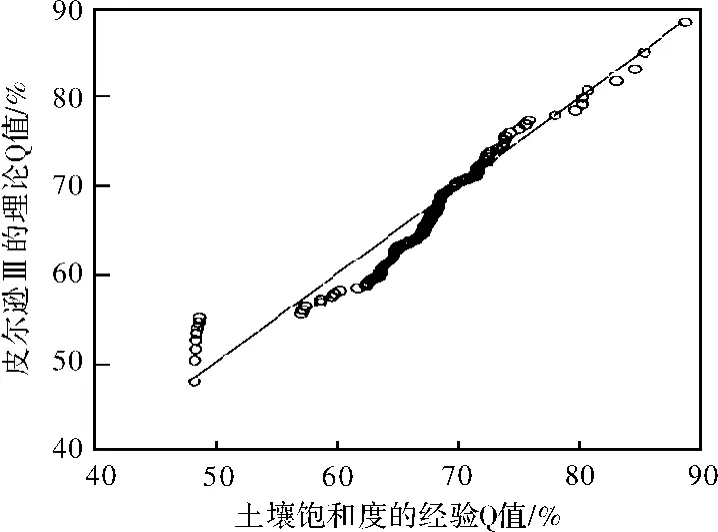
图2 皮尔逊Ⅲ型与土壤饱和度的QQ图
图2说明了利用偏态系数(s)为1.005 2,变差系数为66.710 4的均值参数为零的皮尔逊Ⅲ型能较好拟合土壤饱和度。
采用均值参数为零的皮尔逊Ⅲ型(即三参数Gamma分布)来分析雨量,其相应结果如表1所示。其累积分布图如图3所示。

表1 皮尔逊Ⅲ型分析雨量的相应结果

图3 皮尔逊Ⅲ型与雨量的累积分布函数比较
K-S拟合优度检验方法的相伴概率和累积分布图都说明了,利用均值参数为零的皮尔逊Ⅲ型分布来分析雨量是比较恰当的。
3 联合分布函数
根据饱和度和雨量的资料,首先求得样本Kendall的秩相关系数,即:


利用土壤饱和度与雨量的样本数据求出Clayton连接函数的参数为:

为了检验Clayton连接函数连接土壤饱和度与雨量的拟合精度,比较经验连接函数与理论连接函数的累积概率。
假定(X1,Y1),(X2,Y2),…,(Xn,Yn)来自饱和度与雨量的联合分布H(x,y),设U=F(x),V=G(y)是均匀分布,则:

则M(ω)的经验估计为:
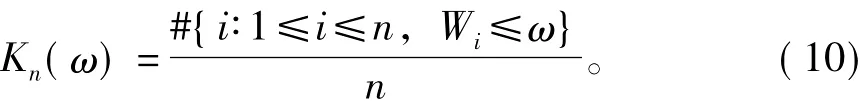
而其理论估计为:
采用无抗舍养、无抗放养、有抗舍养和有抗放养等方式进行固始鸡养殖,测定不同养殖阶段鸡腿肉、胸肉和肝脏中氨基酸及其组成,以研究不同养殖方法对其鸡肉品质的影响。结果表明,在舍养条件下有抗养殖与无抗养殖比较,随着养殖时间的延长,无抗养殖在鸡胸肉和腿肉中总氨基酸略高于有抗养殖,而呈鲜味和必需氨基酸有抗养殖略高;放养条件下有抗养殖与无抗养殖比较,总氨基酸、呈鲜味氨基酸、必需和非必需氨基酸,无抗养殖均略高。

式中:φ为阿基米德连接函数的生成元。分别计算M(ω)的经验估计与理论估计,从而画出PP图(图4)。
图4说明了利用Clayton连接函数来分析土壤饱和度与雨量之间的相依关系是比较恰当的。
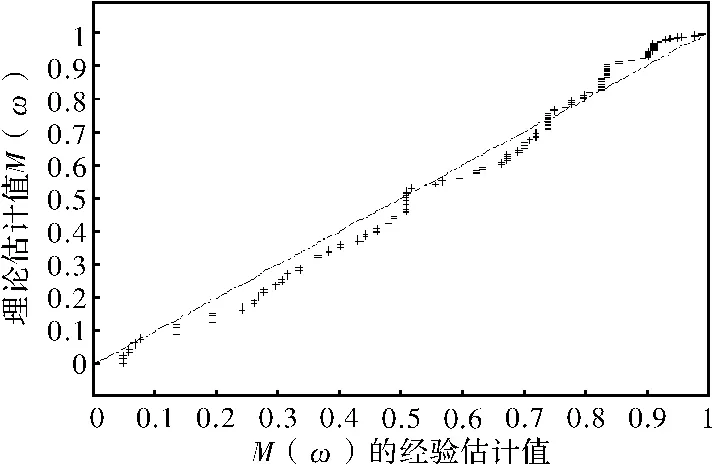
图4 M(ω)的经验值与M(ω)的理论值的PP图

表2 Clayton连接函数的拟合优度检验结果
从拟合优度检验的结果可以看出,利用Clayton连接函数能细致刻画了雨量与土壤饱和度之间的相依关系,能捕捉雨量与土壤饱和度之间的相依机制。
4 联合重现期和随机模拟
定义变量饱和度X和雨量Y的联合重现期:

定义另一种联合重现期:
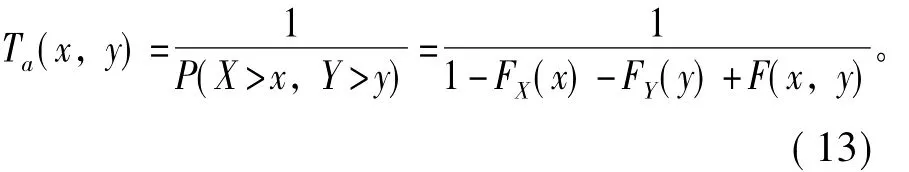
分别计算不同频率p下所对应的阀值xp,yp,然后根据Clayton连接函数计算(xp,yp)的联合重现期To(xp,yp)、Ta(xp,yp),相应结果见表3。
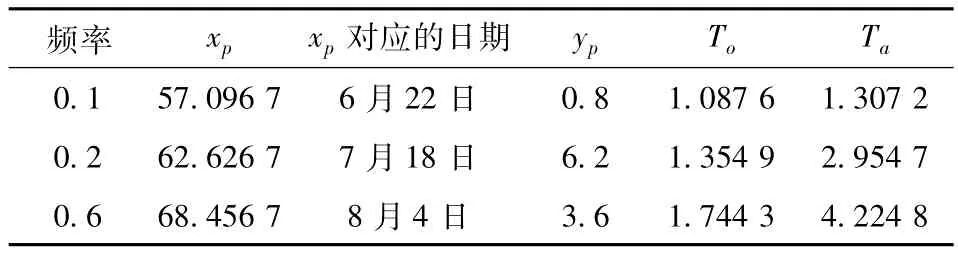
表3 联合重现期To(xp,yp)与Ta(xp,yp)
从表3的计算计算结果以及xp对应的日期,可知To(x0.2,y0.2)≈15个月,Ta(x0.2,y0.2)≈32个月,即在7月18日后发生土壤饱和度X>57.096 7或雨量Y>0.8的联合重现期是15个月左右;发生土壤饱和度X>57.096 7同时雨量Y>0.8的联合重现期是32个月左右。在7月18日后经历了15个月和32个月后的时段内可能是蒋家沟泥石流的高发时段。
由于在实际中,饱和度的数据较难得到。所以,可以通过相应Clayton连接函数来模拟产生饱和度的数据。随机模拟的步骤如下:
(1)令V=G(y),其中G是雨量的分布函数,即表2中的皮尔逊Ⅲ型分布;
(2)产生服从标准均匀分布的随机变量W,即W服从[0,1]上均匀分布;
(4)令BHD=F-1(U),其中F-1为饱和度分布函数的逆函数,即表1中的皮尔逊Ⅲ型分布的逆函数。
利用Clayton连接函数做随机模拟,得到饱和度的模拟数据,其相应结果如图5所示。
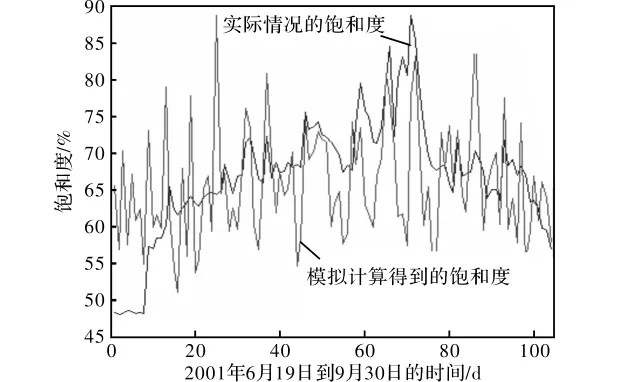
图5 模拟产生的饱和度数据与实际饱和度的比较图
为了检验模拟产生的结果好不好,采用平均偏差与均方误差作为评价指标。平均偏差Bias与均方误差Rmse的计算结果如下:

式中:Xi,分别为估计值和真实值。
从平均偏差Bias与均方误差Rmse的结果可以看出,利用Clayton连接函数做随机模拟法产生的饱和度数据能够较真实地反映实际的饱和度。
5 小结
本文利用皮尔逊Ⅲ型分布分别对土壤饱和度与雨量进行了拟合,选用能够较好反映土壤饱和度与雨量之间的Clayton连接函数,建立了两变量联合分布。其主要结论如下:
(1)拟合优度指标表明皮尔逊Ⅲ型分布能较好地拟合土壤饱和度与雨量。
(2)经验连接函数与理论连接函数的PP图,以及K-S检验方法都表明土壤饱和度与雨量之间的相依机制为Clayton连接函数。
(3)从Clayton连接函数出发,获得饱和度和雨量的各种组合的联合重现期,为预测泥石流的发生提供了一种新方法。
(4)从Clayton连接函数出发,随机模拟了饱和度,为某些尚不能测量饱和度的地区提供一种根据雨量预测土壤饱和度的变化的新方法。
[1]韦方强,胡凯衡,陈杰.泥石流预报中前期有效降水量的确定[J].山地学报,2005,23(4):453-457.
[2]Patton AJ.Modeling time-varying exchange rate dependence using the conditional copula[C]//Working Paper of Department of Economics.San Diego:University of California,2001.
[3]Patton AJ.Estimation of copula models for time series of possibly different lengths[C]//Working Paper of Department of Economics.San Diego:University of California,2001.
[4]Rodriguez J C.Measuring financial contagion:a copula approach[C]//Working Paper of European Institute for Statistics Probability,Operation Research and their Applications,Eurandom,2003.
[5]Zhang L.Multivariate hydrological frequency analysis and risk mapping[D].Louisiana:Louisiana State University,2005.
[6]Salvatore G,Francesco S.Asymmetric copula in multivariate flood frequency analysis[J].Advances in Water Resources,2006,29:1155-1167.
[7]肖义.基于Copula函数的多变量水文分析计算研究[D].武汉:武汉大学,2007.
[8]肖义,郭生练,熊立华,等.一种新的洪水过程随机模拟方法研究[J].四川大学学报:工学版,2007,39(2):55-60.
[9]Salvadori G,De Michele C.Statistical characterization of temporal structure of storms[J].Advances in Water Resources,2006,29(6):827-842.
[10]李彦恒,史保平,张健.联结(Copula)函数在概率地震危险性分析中的应用[J].地震学报,2008,30(3):292-301.
[11]汤家法.蒋家沟流域土壤湿度变化模拟研究[J].山地学报,2009,27(2):217-222.
[12]汤家法.蒋家沟泥石流激发土壤水分条件的模拟与分析[J].地质灾害与环境保护,2009,20(3):90-95.
[13]Roger B′Neslen.An introduction to copulas[M].New York:Springer Verlag,1999.
