基于决策树的英语专业学业影响因素的关联规则挖掘
2010-01-16滕广青张良军
滕广青,张良军,张 凡
(浙江外国语学院,浙江 杭州 310012)
基于决策树的英语专业学业影响因素的关联规则挖掘
滕广青,张良军,张 凡
(浙江外国语学院,浙江 杭州 310012)
利用决策树数据挖掘技术对英语专业学生相关数据信息开展了实验研究,提出了基于实验数据集的决策树挖掘模型,并据此提取了英语专业学业影响因素的关联规则.
数据挖掘;决策树;英语专业;关联规则
1 引 言
“数据挖掘 (DataMining,DM)”这一术语目前在学术界还没有一个公认的、权威的定义,但我们一般可以简单的认为数据挖掘是从大量的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在而有用的信息和知识的过程[1].数据挖掘所探寻的是一种已有的、只是隐藏在数据中、暂时没有被发现的知识.数据挖掘技术是近年来发展最快、应用最为广泛的前沿性技术之一,其基础理论日臻成熟,应用范围越来越广泛.研究重点逐渐从发现方法等理论研究转向系统应用研究,注重多种发现策略和技术的集成,以及多种学科之间的相互渗透.作为处理海量数据的有效方法,数据挖掘被越来越多地应用到教育领域的研究中来.国外最早将数据挖掘技术应用于教育管理中的学生注册、教学设施管理、听课管理等方面[2].近年来,国内部分学者也开始尝试利用数据挖掘技术探索教育领域中的一些问题,如优化多媒体教学策略[3]、提取网络学习关联规则[4]、建立教育决策支持系统[5]、编程语言的选择[6]、课程与成绩的依存性[7]、教学评价[8]等等,并取得了一些进展.本研究采用决策树数据挖掘技术,探寻英语专业学业影响因素的关联规则,从技术应用的层面对利用信息技术研究英语专业教育领域相关问题进行了尝试.
2 针对英语专业学生数据信息的决策树数据挖掘
2.1 数据源管理
对于大学本科英语专业的学业影响因素而言,人们往往会有一些习惯性的认识,例如:(1)高考成绩好的学生,人们往往认为其大学四年平均学分绩点会高;(2)部分地区的方言也许会影响外语学习;(3)由外语类学校升入大学的学生,似乎在大学的相应外语专业会有较大的优势;(4)一般而言,英语等级考试成绩与学生的学业成绩没有必然联系等.
由此,本研究选择国内某 211高校英语专业 2002级 108名本科毕业生 (50%的数据用于挖掘试验,50%的数据用于验证)相关数据作为数据源,同时选择表 1中所列示的字段作为数据挖掘字段,以每个毕业生的平均学分绩点作为学生的学业水平指标进行挖掘.

表1 用于数据挖掘的字段及说明
2.2 数据预处理
由于学生的相关教育信息来自于不同操作平台的不同数据库,操作平台与数据库管理系统的异构,数据结构与数据类型、字段长度的异构,以及数据污染、数据缺失等问题都给数据挖掘带来很大障碍.因此,在数据挖掘之前必须对数据进行预处理.
在进行数据预处理时一般要考虑以下几个方面的问题:(1)数据清洗 现实系统中的数据往往是不“干净”的.例如,来自学生管理系统和教务管理系统的不同数据表中学生的生源所在地信息中可能会出现江西、江西省等这样一些名词.这些名词代表的是同一个生源所在地,但计算机并不理解.因此,必须对数据进行清洗,从而解决一致性问题.(2)数据缺失 数据的取值过程中会发生缺失现象.在我国现行高等教育体制下,可能会由于高考补录、入学一年后转专业、休学等原因造成数据缺失.而有些数据挖掘方法要求被挖掘数据是完整的数据记录,这样就很难从中得到有用的信息,或以此为依据进行预测.
此外,在进行数据预处理的过程中,还需要注意一些特殊字段的取舍.通常情况下类似姓名这样的字段和在数据表中具有不重复 (唯一)的值的字段往往被数据挖掘专家去掉.否则挖掘的结果可能会得到“平均学分绩点在 3.5以上的学生都是姓张的学生”这样的结论.尽管对于训练集这可能是一个事实,但显然这一结论并不具备任何现实意义.
2.3 数据挖掘
本研究采用MicrosoftAnalysis Services提供的决策树 (Decision Tree)数据挖掘引擎对上述数据源进行挖掘,最终得到可视化的挖掘结果见图 1和图 2.
Microsoft的决策树算法是基于分类的概念.该算法构建了一个决策树,根据训练集中各列的取值预测某一列值.因此,树中的每个节点代表了该列的特殊情况.树的分叉节点的位置设定由该算法作出决定,不同深度的节点可能代表每列不同的情况[9].决策树挖掘模型的图形像一株放倒的树,左边是树根,右边是树枝.图 1是根据训练集产生的英语专业学业影响因素的决策树数据挖掘模型 (Data MiningModel),用于显示数据是如何在树型结构里分类和组织的.这是一种由“IF T H E N”规则创建的分层,可以用来对信息分层.决策树的优点之一就是用直观的规则来描述节点.每一个节点用颜色来表示节点中事例的密度,颜色越深,对应节点中包含的事例数就越多,属性值就越大.树中每一个节点和分支都包含有该节点或分支的主要属性特征,可以得到其所包含事例的更多信息.图 1中的模型显示,学生毕业时的“平均学分绩点”(PointAverage of Credit)的属性决定于二年级时的“专业四级考试成绩等级”(Grade)的属性,即根据专业四级成绩等级分为两个分支“优秀”(Grade=1)和“非优秀”(Grade≠1).当“专业四级考试成绩等级”(Grade)不等于“1”(优秀)时,又取决于高考时的“考生类别”(Category)的属性,即根据考生类别分为“外语类”考生和“非外语类”考生.在树的每一个层级上,MicrosoftAnalysis Services的决策树数据挖掘引擎都依据产生小于先验熵的最小条件熵的因素进行分叉.

图1 英语专业学业影响因素的决策树挖掘模型
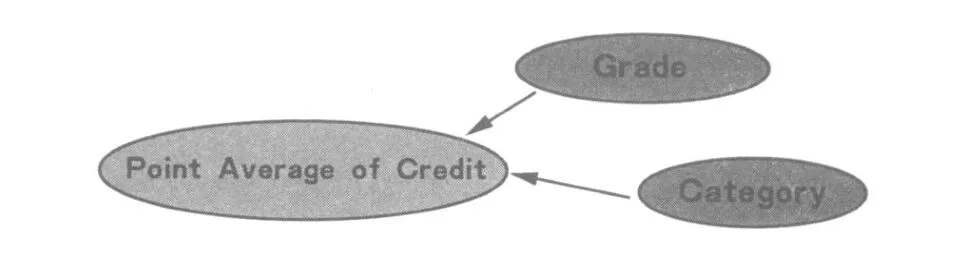
图2 英语专业学业影响因素相关性网络
图2是英语专业学生学业影响因素相关性网络 (DependencyNetwork),它能够反映数据挖掘模型中对象间的相关性和从属性.在相关性网络中,数据挖掘模型被描述成属性的网络.通过模型的相关属性可以识别数据的相关性和预测性.相关性网络通过不同与决策树数据挖掘模型的视角显示了决策树模型中各因素的粗粒度的关联关系,能够指导进一步提取细粒度的关联规则.图 2中的两个箭头表明“专业四级考试成绩等级”(Grade)和“考生类别”(Category)属性预测了“平均学分绩点”(Point Average of Credit)属性,即英语专业毕业生最终的学分绩点 (学业成绩)主要与“专业四级考试成绩等级”和“考生类别”发生关联,或者说受二者影响.相反,人们所熟悉的高考成绩、地域方言 (生源地)等属性则没有对“平均学分绩点”产生预测,即在实验数据集中,高考成绩、地域方言等不会影响学业成绩.
3 英语专业学业影响因素关联规则的提取
挖掘结果将毕业生平均学分绩点分为 2.495、3.325、3.625、3.915四个有效层级,并针对模型中的各个节点产生出各层级详细信息,如表 2所示.

表2 决策树挖掘模型各节点相关信息
表2中“Grade=1”列的数据对应实验数据源中“专业四级考试成绩为优秀”(Grade=1)的节点.对该列数据进行分析可以得到:“专业四级考试成绩为优秀者”(Grade=1)这一组中51.85%的学生的平均学分绩点接近于 3.915;29.63%的学生的平均学分绩点接近于 3.625;只有少数学生平均学分绩点偏低.或者说,如果某个学生在二年级时专业四级考试成绩为优秀,则有 51.85%的可能性其毕业时的平均学分绩点会是接近于 3.915;有 29.63%的可能性其毕业时的平均学分绩点接近于 3.625.提取关联规则为:
IF学生在二年级时的专业四级考试成绩为优秀;
THEN毕业时有 51.85%的概率其平均成绩会接近 89分 (平均学分绩点 3.9);同时有超过 29.63%的概率其平均成绩会接近 86分 (平均学分绩点 3.6);只有少数学生平均成绩偏低.
表2中“Grade≠1”列的数据对应决策树挖掘模型 (图 1)中的第二个子节点“专业四级考试成绩非优秀者”(Grade≠1)的节点.该节点主要集中了平均学分绩点相对较低者,平均学分绩点接近于 3.325的占 39.13%,平均学分绩点接近于 2.495的占 36.96%.
在“专业四级考试成绩非优秀者”(Grade≠1)节点,模型依据学生参加高考时的“考生类别”(Category)是否等于“外语”进一步产生分叉.表 2中“Category=外语”列的数据对应实验数据源中“考生类别为外语类考生”(Category=外语)的节点.对该列数据进行分析可以得到:“考生类别为外语类考生”(Category=外语)这一组中 66.67%的学生的平均学分绩点接近于 2.495;13.33%的学生的平均学分绩点接近于 3.325;只有少数学生平均学分绩点略高.或者说,如果某个学生在二年级时专业四级考试成绩不为优秀 (包括良好、合格、不合格,此条件由“Grade≠1”上层节点产生),且参加高考时的“考生类别”为外语类考生 (Category=外语),则有 66.67%的可能性其毕业时的平均学分绩点会是接近于 2.495;有 13.33%的可能性其毕业时的平均学分绩点接近于 3.325.提取关联规则为:
IF学生在二年级时的专业四级考试成绩不为优秀;
AND高考时考生类别为外语类考生;
THEN毕业时有 66.67%的概率其平均成绩会在 75分 (平均学分绩点 2.5)左右.有13.33%的概率其平均成绩会在 83分 (平均学分绩点 3.3)左右;只有少数学生平均成绩略高.
表2中“Category≠外语”列的数据对应实验数据源中“考生类别为非外语类考生”(Category≠外语,包括理工、文史、普通等)的节点.对该列数据进行分析可以得到:“考生类别为非外语类考生”(Category≠外语)这一组中 22.22%的学生的平均学分绩点接近于 2.495;47.22%的学生的平均学分绩点接近于 3.325;16.67%的学生的平均学分绩点接近于 3.625;11.11%的学生的平均学分绩点接近于 3.915.或者说,如果某个学生在二年级时专业四级考试成绩不为优秀 (包括良好、合格、不合格,此条件由“Grade≠1”上层节点产生),且参加高考时的“考生类别”为非外语类考生 (Category≠外语),则有 47.22%的可能性其毕业时的平均学分绩点会是接近于 3.325;有 22.22%的可能性其毕业时的平均学分绩点接近于 2.495;有16.67%的可能性其毕业时的平均学分绩点接近于 3.625;有 11.11%的可能性其毕业时的平均学分绩点接近于 3.915.提取关联规则为:
IF学生在二年级时的专业四级考试成绩不为优秀;
AND高考时考生类别为非外语类 (包括理工、文史、普通等)考生;
THEN四年级毕业时有 47.22%的概率其平均成绩会在 83分 (平均学分绩点 3.3)左右,有 22.22%的概率其平均成绩会在 75分 (平均学分绩点 2.5)左右,有 16.67%的概率其平均成绩会在 86分 (平均学分绩点 3.6)左右,有 11.11%的概率其平均成绩会在 89分 (平均学分绩点 3.9)左右.
对以上挖掘结果使用校验集的数据进行验证,弥合率达到 90%以上.
4 挖掘结果的现实意义
通过以上基于教育信息的数据挖掘项目研究,可以得到以下结论,对于同一批次录取的英语专业学生而言:(1)高考成绩、生源所在地等因素并不决定或直接影响大学英语专业学生最终的平均学分绩点;(2)大学本科段以前在外语类学校毕业的学生 (外语类考生),在大学的相应外语专业中并不一定具有优势;(3)英语专业的专业四级考试成绩能够对学生最终的学业成绩产生预测.
从表面来看,上述结论有些出乎意料,一定程度上超越了人们目前对英语专业学业影响因素的认识范畴.因此需要对这些信息进行分析.
作为第一条结论,性别和生源地对学业成绩不产生影响一般能够被普遍接受,但也许有相当一部分人还是相信高考成绩会影响学业成绩的.事实上,我国目前高中段主要完成的是基础教育,进入大学后进行的则是专业教育,二者在本质上有很大区别.进入大学后,大部分学生处于同一起跑线 (录取分数档次差距不大).大学中的许多专业在一定程度上受学生在某一领域中天赋和努力情况的影响程度要高于受基本文化素质的影响程度 (除非在基本文化素质方面个体差异较大).加之学生入学前由于生理、情绪等诸多原因可能造成高考成绩没有真实反映学生实际水平,而入学后由于学习环境、生活经历、课程内容、学习方法等变化会在心理上产生不同程度的影响,因此高考成绩并不决定或直接影响学生最终的平均学分绩点也就不足为奇了.
最出乎意料的应该是第二条结论.按常规理解,在大学前就特别注重外语学习,进入大学后又从事外语专业学习的这类学生,应该比其他普通高中毕业生至少在外语学习方面具有较大的优势.但事实是由于过早的专业化有可能使这部分学生在综合文化素质方面产生缺陷,而普通高中毕业生原本并不存在的综合文化素质优势则有可能成为相对于外语类考生的相对优势.而且现在外语学习环境较若干年前已发生了很大变化,从前外语学习资源相对匮乏的情况下,外语类考生由于较早进入专门化学校学习具有一定优势.而今外语学习资源极大丰富,除了录音磁带、影像光盘,还有网上 BBC、CNN在线直播,连幼儿外语学习班中都随时可见外籍教师的身影.这一切使得外语类考生原本存在的早期专业优势被逐渐淡化了.因此,就目前情况看,过早的专业化分科并不一定利于外语的学习.
第三条结论在目前非英语专业大学英语四级考试已与毕业资格脱钩的情况下似乎显得不合时宜.然而,应该看到非英语专业普通大学英语四级考试与英语专业四级考试之间的本质区别.前者与学生所学专业知识的联系程度有限,因此非英语专业的大学英语四级考试成绩与学生的学业成绩没有必然联系是容易理解的.但英语专业的等级考试的考核内容与专业知识结合紧密,特别是近年来在原有着重对语言技能考核的基础上增加了对知识性内容的考核.因此,英语专业的专业四级考试成绩能够对学生最终的学业成绩产生预测.
5 结 语
以上的分析仅仅是决策树数据挖掘技术在英语教学领域中应用的一次尝试.随着数据挖掘技术的不断发展和教育领域信息化建设的不断深入,基于数据挖掘的相关教育问题的研究也会越来越引起人们的重视.尽管数据挖掘原本是作为一项技术出现的,但由于数据挖掘本身独有的理念给人们处理解决各类问题都提供了一个新的思路和方法,在这一点上数据挖掘一定程度上等同于一种方法论[10],数据挖掘技术的应用将会为数字时代的高等教育相关领域的研究提供一条新的途径.
[1]Han J W,Micheline K.DataMining:Concepts and Techniques[M].San Francisco:Morgan Kauf mann,2001:5.
[2]Ralph K,Margy R.TheDataWarehouse Toolkit:the Complete Guide to DimensionalModeling[M].New York:JohnW iley&Sons,2002:247-252.
[3]刘飞兵.运用数据挖掘技术优化大学英语多媒体教学[J].外语电化教学,2006(10):72-74.
[4]孙玉荣,罗立宇,黄慧华.数据挖掘在网络教学中的应用 [J].现代教育技术,2009,19(6):104-106.
[5]张德新,崔巍,蒋天发.基于数据仓库和数据挖掘的教育决策支持系统 [J].武汉大学学报:工学版,2003,36(4):129-131.
[6]陈登科,胡翠华.数据挖掘技术在远程教育中的应用[J].情报科学,2003,21(4):445-448.
[7]李芸,瞿伟,张文.数据挖掘技术在研究生教育管理工作中的应用 [J].西安建筑科技大学学报:社会科学版 ,2009,28(4):70-74.
[8]杨永斌.数据挖掘技术在教育中的应用研究[J].计算机科学,2006,33(12):284-286.
[9]MicrosoftDecision Trees[EB/OL].[2010-06-06].http://msdn.microsoft.com/en-us/library/aa178242%28SQL.80%29.aspx.
[10]滕广青,毛英爽.国外数据挖掘应用研究与发展分析[J].统计研究,2005(12):68-70.
Associ ation RulesM i ni ng about Factors on EnglishMajor Based on Decision Tree
TENG Guangqing,ZHANG Liangjun,ZHANG Fan
(Zhejiang International StudiesUniversity,Hangzhou 310012,China)
This paper processes the experimental reseach about data infor mation on English major by decision tree data mining. It proposes the decision tree data mining model based on experimental dataset,and extracts the association rules about English teaching.
data mining;decision tree;English major;association rules
TP331
A
1671-6574(2010)04-0097-06
2010-06-16
滕广青 (1970-),男,吉林长春人,浙江外国语学院国际工商管理学院副教授,管理学硕士;张良军 (1970-),男,黑龙江齐齐哈尔人,浙江外国语学院外国语学院副教授,文学硕士;张凡(1963-),女,江西南昌人,浙江外国语学院图书馆助理馆员.
