融合成对损失函数与分级图卷积网络的协同排名模型
2024-03-01郑升旻胡林发漆鑫鑫
郑升旻,胡林发,漆鑫鑫
(昆明理工大学 信息工程与自动化学院,云南 昆明 650504)
0 引言
互联网时代,用户在网络上经常面对海量的商品信息,但过量的数据使得用户难以从中筛选出自己所需要的商品。推荐系统[1]通过估计用户对商品的偏好,向用户推荐可能喜欢的商品,以此缓解用户面临的信息过载问题。
实际应用中,众多推荐系统以用户对项目评分的分值表示用户的偏好程度,分值越大表示用户的偏好程度越高,因此传统推荐模型通常采用均方根误差(Root Mean Squared Error,RMSE)作为指标,将评分预测准确度作为优化方向。但是用户获取推荐项目时更关心推荐结果是否符合自己的喜好,而非模型预测的分值。实际应用中推荐系统为用户推荐项目往往是返回给用户一个top⁃k序列,即用户未评分的项目中,模型预测的评分最高的k个项目。由此可见,相较于预测评分的准确度,项目的排名质量更加关键。而评分预测准确度与预测排名质量之间并不一致,准确度更高并不意味着偏好预测排序质量更好[2⁃3]。
为解决这一问题,出现了直接优化排序质量的协同排名模型(Collaborative Ranking),如List⁃MF(Listwise Matrix Factorization)[4]。List⁃MF 将训练排名序列和模型预测排名序列中项目top⁃1 概率的交叉熵作为损失函数来训练排名模型,直接优化预测排名质量。SQL⁃Rank(Stochastic Queuing Listwise Ranking)[3]则考虑具有相同评分的项目之间的位置关系,通过在训练过程中对评分相同的项目随机排序以解决评分相同造成的歧义。但这类直接优化排名的协同排名方法所采用的损失函数具有非凸性,因此只能得到局部最优解,导致预测效果较差[3⁃4]。
近年来,基于成对比较(Pairwise Comparison)的个性化协同排名算法取得了很大的进展。这类方法根据用户评分数据为每个用户构造项目之间的两两相互比较,借此将用户的偏好序列转化为不同项目之间的比较对,通过这种方式将用户偏好排名的优化问题转化为成对比较的分类问题。交替支持向量机(Alternating Support Vector Machine,AltSVM)[5]和Primal⁃CR(Primal Collaborative Ranking)[6]是成对比较类协同排名算法中极富代表性的方法。AltSVM 是一种非凸式协同排名算法,它显式地以因子形式对低秩矩阵进行参数化,并最小化合页损失函数。AltSVM 算法会交替更新用户和项目的潜在因子,算法每一步都可以被表示为一个标准的SVM 对两个因子中的一个进行更新。Primal⁃CR 算法则基于牛顿法快速计算损失函数梯度和Hessian 矩阵,之后利用坐标下降法交替更新用户和服务的隐向量,有效地降低了算法的时间复杂度。在Primal⁃CR 的基础上,Primal⁃CR++[6]基于用户信息多为评分数据的特点,继续改进梯度计算方法和Hessian 向量计算方法,进一步降低了算法的计算速度。
上述协同排名方法一般基于矩阵分解,采用固定的线性函数(如内积)作为交互函数,而这类函数不能拟合非线性关系,但NCF(Neural Collaborative Filtering)[7]等方法已经证实,拟合非线性关系在建模用户和项目交互时具有显著效果。因此,基于生成对抗网络的协同排名模 型(Collaborative Ranking Generative Adversarial Network,CRGAN)[7]选择利用全连接网络作为交互函数。CRGAN 通过生成对抗网络拟合用户的偏好分布,使用多层全连接神经网络作为模型的生成器与判别器。NCPL(Neural Collaborative Preference Learning)[8]则设计了深层和浅层两种交互函数,将两种交互函数输出的向量通过一层全连接层,得到预测得分。其中浅层的交互函数为Hadamard 积,深层的交互函数则包含多层的全连接神经网络。但用户和项目之间的多级邻接关系中具有丰富的交互信息,而上述算法对这些交互信息的挖掘不够充分[9]。
图卷积网络(Graph Convolutional Network,GCN)是一种图结构数据上的特征提取方法,现在已经广泛应用于推荐模型中,如图卷积矩阵补全模型(Graph Convolutional Matrix Completion,GCMC)[10]通过聚合异质邻接节点的信息,直接从二部图中挖掘用户和项目特征;轻量级图卷积模型(Light Graph Convolution Network,LightGCN)[9]通过多层邻接关系中的信息传递构建用户和项目的嵌入表示,并且利用可学习的权重系数来近似实现自连接。相较于传统方法,图卷积网络能够获取用户和项目之间潜在的交互信息,由此得到质量更好的嵌入表[10]。
基于上述研究,本文提出一种融合成对损失函数与分级图卷积网络的协同排名模型(Hierarchical Graph Convolution Network with Pair⁃Wise Loss,HGCN⁃PW),通过分级图卷积挖掘用户⁃项目二部图中异质节点之间的交互信息,再充分利用用户评分数据中隐含的交互关系,提高嵌入向量的质量。
其次,将评分数据构造成项目间的成对比较,基于成对比较优化模型以直接提高模型预测排序的质量。针对分级图卷积网络设计了对应的自连接策略,实现对用户和项目信息的充分利用;并结合内积与神经网络以作为用户与项目间的交互函数,使其得以拟合非线性关系。
1 融合成对损失函数与图卷积网络的协同排名
HGCN⁃PW 包括嵌入传播层和预测层。嵌入传播层中的图卷积层利用分级图卷积直接挖掘异质图上的交互信息,相比挖掘用户与项目交互矩阵可利用更多信息;接着通过全连接层融入辅助信息,得到用户和项目的嵌入向量。预测层根据嵌入向量,结合非线性变换与内积预测用户对项目的偏好程度,再利用成对比较数据训练模型。HGCN⁃PW 的模型框图如图1 所示。

图1 融合成对损失函数与分级图卷积网络的协同排名模型框图
1.1 符号及定义
给定用户集合U和项目集合V,其中m=||U、n=|V|分别表示用户数和项目数,并设定相应的评分信息,以构建相应的评分矩阵R∈Zm×n,评分取值范围为Rij∈{1,2,…,L}。按照评分取值范围,为每一类评分构建分级矩阵Rl∈Zm×n:
式中l∈{1,2,…,L},由分级矩阵可以得到对应的分级邻接矩阵Al:
式中:Al∈Z(m+n)×(m+n),每一个分级邻接矩阵都对应着一个分级交互图。图1 中包含用户和项目两种节点,每条边连接着一个用户节点和一个项目节点,表示用户对项目给出的评分为l,所有分级邻接矩阵集合A={Al|l=1,2,…,L}。用户的特征信息为,项目特征信息为。为统一用户和项目的特征向量维度,本文中将它们记为XU=[,0],XU∈Rm×d,XV=表示用户和项目特征信息,xui和xvj分别表示用户ui和项目vj的特征向量。
为解决协同过滤模型不能直接优化用户偏好序列的问题,本文根据用户评分数据为每个用户构造项目之间非数值的成对比较,基于这些成对比较优化模型。传统的RMSE 独立计算每个预测评分与真实值之间的差距,本质是一种点比较损失函数,因此无法直接优化项目排序。成对比较(Pairwise Comparison)方法将排序转化为项目间成对比较的分类问题:首先由U、V可以构造用户和相应项目的成对比较三元组集合Ω={(i,j,k)|ui∈U;vj,vk∈V,j≠k},(i,j,k)表示用户ui在项目vj、vk中更偏好vj,如果项目vj、vk的优劣关系正确则为正例,错误即为负例。成对比较方法相对于点比较方法考虑到了项目间的相对位置关系,更加符合优化用户偏好排名的需要。具体的,可根据评分矩阵R为Ω中每个三元组赋予标签:
式中:Ri,j>Ri,k表示用户ui给项目vj的评分比项目vk高,即用户ui在项目vj、vk中更偏好vj;为1 表示对应的三元组(i,j,k)为正例,反之为负例;Y={}表示Ω中所有成对比较的标签。模型的优化目标是减少错误分类的成对比较数量。
1.2 嵌入传播层
1.2.1 异质交互图中的信息传递
GCMC 中所采用的图卷积操作为:对图中每个节点执行只考虑一阶邻域的局部图卷积操作。这种局部图卷积可以被看作是一种异质节点之间的消息传递[11],节点的特征向量作为节点信息,以向量形式在交互图中沿着边传递和转换,这样的卷积方式可以通过叠加图卷积层简便地将图卷积范围扩展到高阶邻域。因此本文采用同样的图卷积策略,根据边类型构造不同的交互图,为不同交互图上分配不同的卷积权值参数矩阵,以实现不同的边上具有不同的消息传递方式,即分级图卷积。从项目节点vj到用户节点ui,沿着评分为l的边所传递的信息可表示为:
式中:cij是正则化常量,值为,Nui是用户ui节点的邻接节点集合,Nvj是项目vj节点的邻接节点集合;Wl是分值l对应的卷积权值参数矩阵,表示邻接矩阵Al对应的交互图上的消息转换规则。由用户节点ui到项目节点vj的信息传递为:
在缺失节点特征或者节点特征不足以区分各个不同节点时,以节点序号独热编码(one⁃hot encoding)作为节点特征,输入图卷积层就可获得良好的效果[10]。但不同分级矩阵下的各用户和项目相关的评分数量往往相差较多,而在以独热编码为节点特征输入图卷积层时,会导致Wl的某些列被优化的频率明显低于其他列。因此,需要在不同l对应的Wl之间采取某种形式的权重共享,以缓解这一优化问题。本文采用文献[12]所提出的权重共享方案:
1.2.2 节点的信息聚合与自连接
消息传递后,需要聚合节点收到的消息。对于用户ui,首先将其在邻接矩阵Al上所有邻接点Nui,l的消息求和,得到该节点在Al对应的交互图上的消息向量μui,l;接着将所有交互图上的消息向量聚合为用户的中间向量,具体为:
式中:accum(·)表示聚合操作,可以通过堆叠stack(·)实现,即将多个向量串联成一个向量,或者通过sum(·)实现,即对所有向量求和;σ(·)则代表一个激活函数,可选择ReLU=max(0,·)或其他形式。
GCMC 中直接用hui替换原节点信息,但是这种更新方式并未考虑节点自身信息的作用,当图卷积层多于一层时,相当于丢弃上一层图卷积所聚合的邻接点信息。因此为保证节点自身信息充分表达,需要在聚合邻接节点信息的同时考虑自连接信息。自连接信息的加入方式[9]是:将邻接矩阵与单位矩阵相加,以在图卷积操作中实现自连接,但是本文将评分矩阵转化成多个分级矩阵,直接在每个分级邻接矩阵中加入单位矩阵,这将会使得图卷积过程中重复加入自身节点信息。因此本文不修改分级邻接矩阵,直接对节点的特征向量执行一次特征变换,将其作为自连接信息加入图卷积操作中,其中特征变换矩阵选择权重共享矩阵TL。项目节点也执行同样操作。
图卷积层最终输出的用户中间向量为:
式中:μui⁃self为节点的特征向量经过一次特征变换后的自连接向量。给定用户⁃项目评分矩阵R∈Zm×n,用户和项目的特征信息为。嵌入传播层的矩阵形式为:
1.3 预测层
预测层利用嵌入传播层输出的嵌入矩阵ZU、ZV,预测用户⁃项目排名得分矩阵,即用户和项目之间的交互函数。传统的协同过滤方法中,通常使用内积作为交互函数,但内积作为交互函数有着无法拟合非线性关系的明显缺陷。因此本文在内积的基础上,通过增加非线性激活函数,使得预测层具有拟合非线性关系的能力。同时,由于本文方法只是利用预测分值来得到项目排序,不需要保证预测分值的准确度,因此加入Sigmoid 层控制分值预测范围。预测层公式如下:
式中:f1是以ReLU 为激活函数的隐层;f2是以Sigmoid 为激活函数的隐层;是模型预测的排名得分矩阵,包括所有用户对所有项目的预测得分,根据预测得分由高到低排序可得用户的预测偏好排名。
1.4 模型训练
与直接优化RMSE 不同,本文基于成对比较数据来优化每个用户对不同项目的偏好排名。因此需要先计算同一用户不同项目间预测得分的差值:
式中m为预定义的得分差值间距。
2 实验及结果分析
为了验证HGCN⁃PW 的性能,采用Pytorch 框架,在Ubuntu 20.04 64 位操作系统,PyCharm 2020,IntelⓇCoreTMi7⁃9700F CPU @3.0 GHz,8 GB 内存,RTX 2060 GPU,Python 3.8 的环境下进行对比实验。
2.1 实验数据集
本文在一些常见的协同过滤基准数据集上,将HGCN⁃PW 与其他模型相比较,所采用的数据集包含用户对项目(如电影)的评分。实验数据集情况如表1所示。
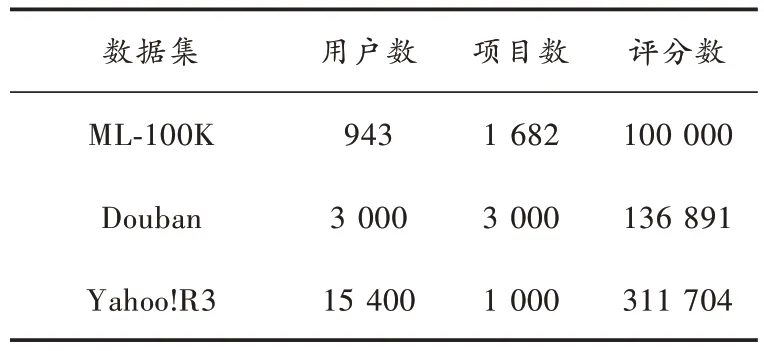
表1 数据集基本信息
表1 中:ML⁃100K 数据集[10]包含用户和项目的辅助信息(如用户的年龄、职业、项目的时间、类型等);Douban 数据集是由文献[13]提供的Douban 数据集的子集,包括3 000 用户和3 000 项目,并将用户间的社交关系作为辅助信息;Yahoo!R3 为雅虎音乐的评分数据集,没有辅助信息[3]。
2.2 评价指标及对比算法
本文采用的评价指标包括归一化折损累计增益NDCG 和预测成对比较错误率(Pairwise Error)[6]。其中用户ui的NDCG@K定义为:
式中:πi为用户ui根据预测得分由高到低对项目排序得到的排名;πi(k)为πi中排第k位的项目序号;Rij表示用户ui对项目vj的真实评分;表示根据用户ui的真实评分最大化DCG@K的项目顺序;NDCG@K以预测排名的DCG 值与理想的最大化DCG 之比表示预测排名的质量,数值越接近1,预测效果越好。这种方法只计算预测排名中的前K个项目,并且由于衰减项,排名越靠前的项目权重越大。
Pairwise Error 定义为:
式(18)表示在测试数据集Γ的所有成对比较中,模型预测错误的成对偏好比较的比例。
AltSVM、PrimalCR、PrimalCR++是近年来成对比较类协同排名算法中极富代表性的方法,三种方法凭借其优秀的推荐效果而常被作为协同排名的基线方法[3]。CRGAN、NCPL 是基于神经网络的协同排名模型中的最新方法,因此本文选取这5 种方法为对比方法。
2.3 实验设置
与文献[6]相同,对于实验中用到的数据集,首先筛选出评分数超过20的用户,然后每个用户随机选取20个评分作为测试集,剩余的评分数据作为训练集。在所有实验中,用户和项目的特征信息都用其序号对应的独热编码表示,模型嵌入传播层部分由两层图卷积层组成,第一层使用串联聚合消息,第二层采用求和聚合消息,两层网络都加入自连接,失活率都设置为0.7,激活函数都采用LeakyReLU。优化器使用Adam[14],学习率为0.001。模型两层图卷积层的维度分别为64 和32,每一轮训练随机选取固定数量的成对比较数据,用于计算损失值。本文所有实验中成对比较数据数量均设置为2 048,得分间距差值m设置为1.5。ML⁃100K 数据集运行500 轮迭代,Douban、Yahoo!R3 运行300 轮迭代。
2.4 性能对比
为了评估HGCN⁃PW 的性能,本文将其与目前成对比较类CR 算法中的AltSVM 和PrimalCR、PrimalCR++、CRGAN、NCPL 在相同环境下进行比较,NDCG@10 作为评价指标。在4 个数据集上分别进行10 次实验,取其平均值作为实验结果。NDCG@10 对比实验结果如表2 所示,Pairwise Error 对比实验结果如表3 所示。
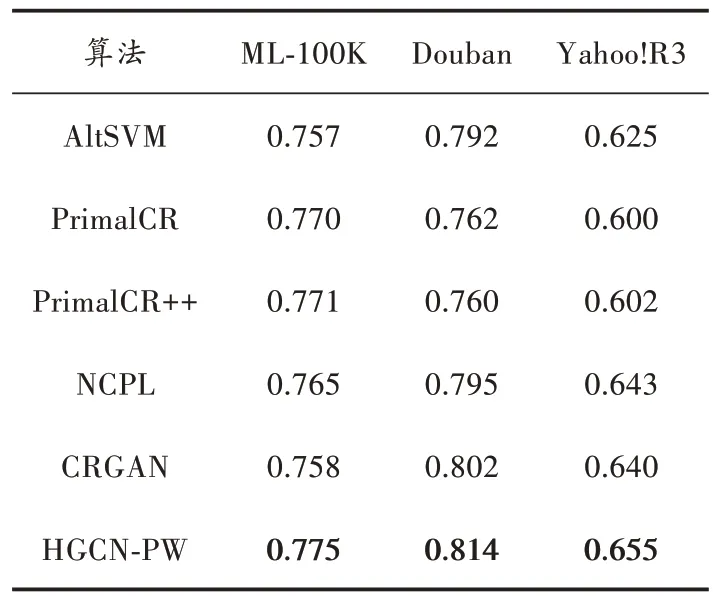
表2 NDCG@10 对比实验结果

表3 Pairwise Error 对比试验结果
由表2、表3 可知,本文所提出的HGCN⁃PW 算法相较其他方法有着显著的优势,在ML⁃100K、Douban、Yahoo!R3 数据集上都获得了最佳的效果。HGCN⁃PW通过异质节点之间的消息传递挖掘用户⁃项目交互,两层卷积层增加了卷积范围,使得模型对用户和项目的潜在特征具有更强的表达能力;同时,在利用用户和项目的嵌入向量计算内积之前,将两者输入带非线性激活函数的全连接层,令模型的交互函数具有内积无法比拟的非线性拟合能力。正是由于这两点,HGCN⁃PW 的性能显著优于其他算法。
2.5 损失函数有效性
损失函数的优化以最小化损失为目标。过去的许多工作[5⁃6]已经表明,采用合页损失函数,最小化损失能有效地优化模型,提高预测排名质量。不同于传统的成对比较类协同排名算法,HGCN⁃PW 利用图卷积获取用户与项目的嵌入,再通过神经网络预测排名得分矩阵,并且每一轮训练选取不同的成对比较数据,因此仍然需要讨论最小化损失是否能够优化HGCN⁃PW 模型,使其输出一个好的排名。出于这个原因,在ML⁃100K 数据集上,本文在模型优化迭代过程中同时展示损失值和NDCG@10 的变化。为便于展示,对损失值进行归一化(Min⁃Max Normalization)处理,结果如图2 所示。
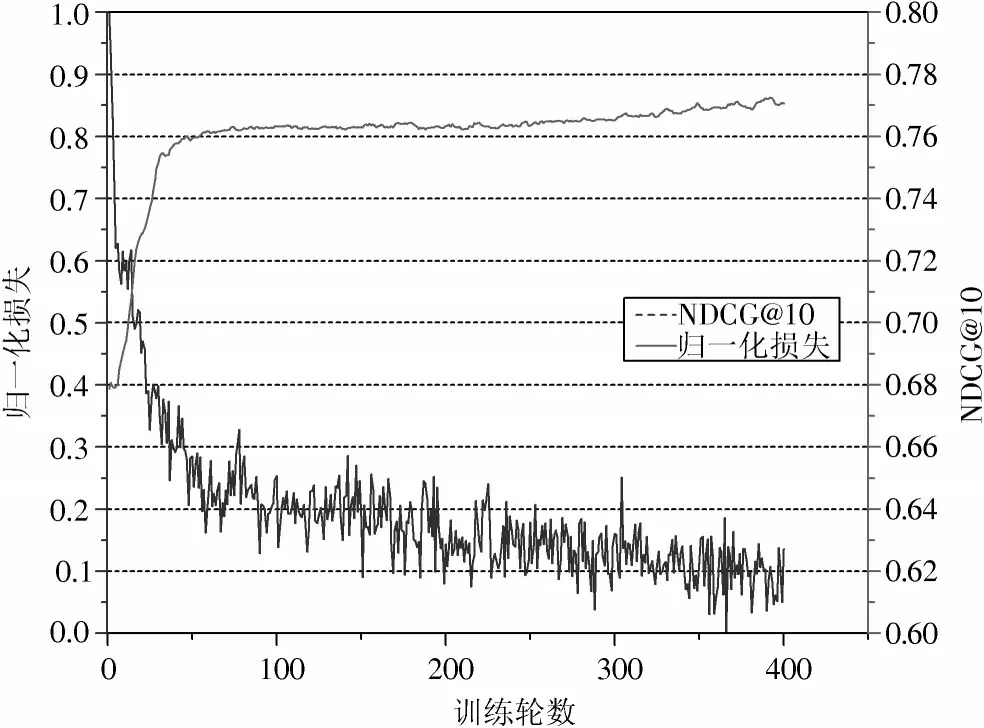
图2 HGCN⁃PW 通过最小化合页损失以优化NDCG@10 的有效性
由图2 可知:在优化损失函数时,随着损失值下降,模型的预测排名质量不断上升,在开始的50 个轮次左右,模型所采样的成对比较三元组之间区别较大,因此排名质量上升较快;随着训练的进行,模型采样所得三元组中的用户或项目开始与之前三元组中的用户或项目产生重复,因此排名质量上升速度变慢。同时,实验中NDCG@10 在大约450 次迭代后成为近似最优,表明HGCN⁃PW 基于成对比较数据优化排名质量是有效的。
2.6 预测层消融实验
为验证预测层中非线性激活层的作用,本文选取ML⁃100K、Douban、Yahoo!R3 数据集作为实验数据集,设计了如下消融实验:
1)PDT,仅使用内积预测排名得分矩阵。
2)PDT⁃R,嵌入表示经带ReLU 激活函数的全连接层后计算内积。
3)PDT⁃S,嵌入表示经带Sigmoid 激活函数的全连接层后计算内积。
4)PDT⁃RS,嵌入表示连续经过ReLU 和Sigmoid 作为激活函数的全连接层后计算内积。
HGCN⁃PW 的参数设置与前文保持一致,不同情况下的模型表现如表4 所示。
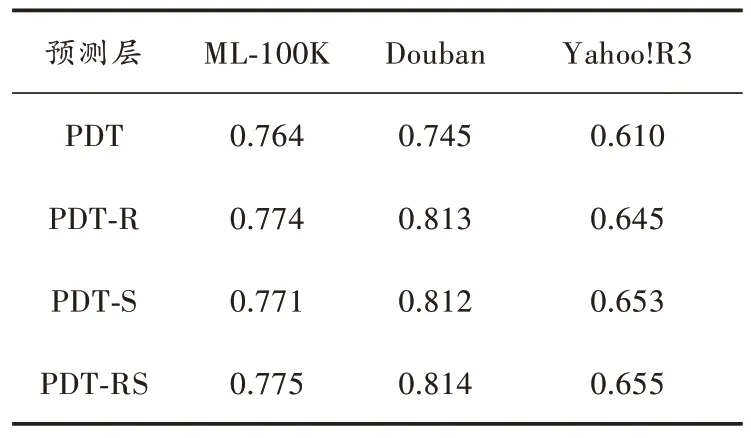
表4 预测层消融实验结果
如表4 中所示,在所有数据集上仅使用内积的预测表现最差,加入带非线性激活函数的全连接层后,模型预测效果有显著提升。具体的,在实验所用的3 个数据集上,PDT⁃R 相较于内积NDCG@10 分别提升1.3%、9.1%、5.7%,PDT⁃S 相较于内积分别提升0.9%、8.9%、7.0%。将两种激活函数都加入预测层后,PDT⁃RS 相较于内积分别提升1.4%、9.2%、7.3%,预测质量达到最优。由此可以看出,加入非线性激活层之后,预测层得以拟合非线性关系,因此预测表现更好。结合不同的非线性激活函数便可以使得模型达到最佳预测效果。
3 结语
现有的协同排名算法对于用户与项目间的交互信息挖掘不足且难以拟合非线性关系,针对这一问题,文中提出一种融合成对损失函数与图卷积网络的协同排名模型(HGCN⁃PW)。模型根据用户评分信息构建分级评分矩阵和成对比较数据;接着通过分级图卷积挖掘用户⁃项目二部图中节点的异质交互信息,并利用特殊的自连接策略,得到相应的用户、项目嵌入矩阵;之后将2 个矩阵输入神经网络预测层得到预测排名得分矩阵;再基于成对比较数据,利用合页损失函数训练模型。HGCN⁃PW 在ML⁃100K、Douban、Yahoo!R3 数据集上相较于现有的同类方法均体现出明显优势。
