基于多分类器差异的噪声矫正域适应学习
2024-02-21郑潍雯汪云云
郑潍雯,汪云云
(1.南京邮电大学 计算机学院、软件学院、网络空间安全学院;2.江苏省大数据安全与智能处理重点实验室,江苏 南京 210023)
0 引言
近年来,深度神经网络在图像识别、语义分割和自然语言处理等许多应用中取得了显著成果。然而,相比于传统的机器学习方法,现代深度网络更加依赖于大规模且高质量的人工标记数据,但人为标记大量样本费时费力,对于特定的学习任务又需要相关的专业知识且存在人为主观因素等,会导致标签上的误差。如何利用少量有标签数据,建立一个可靠的模型,帮助无标记的数据进行任务学习,这便是最近备受关注的迁移学习。本文研究重点是迁移学习中的一个重要子问题,即无监督域适应学习(Unsupervised Domain Adaptation,UDA)[1-2]。
UDA 旨在利用相关且有标记的源域(Source Domain)的知识帮助无标记的目标域(Target Domain)学习。源域和目标域数据虽然相关但仍存在明显的分布差异,这会导致模型迁移性能不佳。现阶段大多数UDA 方法主要是学习域间不变知识,从而减小域间分布差异以实现模型迁移,主要包括基于度量的方式[3-4]和基于对抗的方式[5-8]。基于度量的方式主要是利用不同的度量方式,例如最大均值差异(Maximum Mean Discrepancy,MMD)[4]或Wasserstein 距离[9]等以减小源域和目标域之间的边缘或条件分布差异。基于对抗的方式主要是通过特征提取器和域鉴别器之间[6]或是多分类器之间[3]的对抗学习提取出域不变特征以对齐源域和目标域的特征分布,至此便能将源域中的类判别知识迁移应用到目标域中,帮助识别目标域样本完成分类任务。假定收集到的大量带标记的源域数据都完全正确,而这在真实的学习任务中常常难以满足。
在真实场景的UDA 任务中,很难收集大量带有干净标签的源域样本,从众包平台或互联网媒体收集到的源域数据通常不可避免地带有特征层面和标签层面上的噪声。使用带噪的源域数据会极大降低域适应模型的泛化性能,特征噪声会破坏原始数据分布,从而增加域对齐的难度;而标签噪声会恶化分类的预期风险,从而导致目标域样本的错误分类,这使得以前的UDA 方法在带噪环境中很容易失败。最近,一些方法致力于研究噪声域适应学习(Noisy UDA)[10-13],主要可分为两类:一类是采用Small Loss 准则[10-11]将源域样本分为干净、有噪声两部分,然后仅利用干净样本将源域类判别知识迁移到目标域;另一类主要是利用多个分类器的联合学习策略[12-13]筛选出干净样本用于域适应以减少标签噪声在知识迁移过程中的影响,这也是本文所采取的策略。但这些工作往往只关注到样本的标签噪声而忽略了特征噪声也会造成负迁移,并且大多数方法直接丢弃了噪声样本,仅使用干净样本进行训练,因而样本信息利用率低。Noisy UDA 方法在实际应用场景中可以帮助医疗、金融等多个领域进行相关性能提升,例如在医学影像诊断中可应对不同机器产生的噪声或训练数据中的人工标记误差完成影像判断,并可以学习不同脏器影像中的共性并完成跨域识别。
Noisy UDA 通常有域偏移和源域特征或标签被破坏这两个问题导致目标域分类性能不佳,针对此学习场景,本文提出了基于多分类器差异的噪声矫正域适应学习模型(Noise Correction Domain Adaptation based on Classifiers Discrepancy,NCDA)。首先,利用多分类器之间输出结果的差异性,结合本文提出的精确分类方式,可将源域数据分为干净、带有特征噪声、带有标签噪声的样本;其次,对两种噪声分别进行矫正,之后结合干净样本一起投入到类判别知识的学习中,并先最大化多分类器之间的差异使得类别边界清晰,再最小化多分类器损失约束其一致性;最后,采用随机分类器的思想[14]优化多分类器参数,将其参数看作一个分布进行优化,避免网络中的两个分类器趋同,增加了多分类器对于样本判别的多样性,使得整个域适应网络更加具有鲁棒性。NCDA 方法的主要贡献点可总结如下:①提出对带噪源域样本进行精确分类,区分特征噪声与标签噪声,并针对不同噪声种类定制矫正方案,复用矫正后的样本,以提高样本利用率;②利用随机分类器的思想优化网络参数,将分类器的参数看作一个分布去优化,可以增加分类器的多样性以避免两个分类器趋同而导致模型失效的问题;③针对噪声域适应问题,提出了NCDA,在Office-31、Office-Home、Bing-Caltech 数据集上与无监督域适应方法和噪声域适应方法进行对比,实验证明了该方法的有效性和鲁棒性。
1 相关工作
1.1 无监督域适应
无监督域适应学习主要是利用一个或多个不同但相关且有标记的源域知识迁移到无标记的目标域。近年来,UDA 正处于蓬勃发展的阶段,其方法可大致可分为3 类:基于度量的方式、基于对抗网络的方式、基于重构的方法。在域适应发展早期阶段,大多采用基于度量的方式以减小源域和目标域的数据分布差异。这类方法主要针对源域与目标域数据的边缘分布、条件分布以及联合分布进行对齐,以此减小域间偏移实现知识迁移。常用到的域间差异度量方法有最大均值差异(MMD)[4]、Wasserstein 距离[9]、相关性对齐[15]、KL 散度[16]、JS 散度[17]等。后来,受对抗学习实践启发,文献[6]提出一种对抗性域适应神经网络,用特征提取器和域鉴别器之间的对抗学习提取出域不变特征并拉近源域和目标域之间的特征分布。自此开始,一系列关于对抗性学习的域适应研究[42-43]被相继提出。文献[7]将条件分布信息融入对抗自适应模型,文献[18]从图片的像素级别和特征级别分别执行对抗与适应学习以实现知识迁移,文献[3]采用多个分类器实现对抗学习,实现两域数据在条件分布上对齐。最后一类基于重构的方法主要是受到文献[19]的启发,采用生成的方式,使得生成器学习并能输出类源域样本或类目标域样本,达到风格迁移[20]或是数据分布平衡[21]的作用,学习域间不变特征,减小域间差异,从而实现知识迁移。
1.2 噪声域适应学习
噪声场景下的研究由于模糊的特征及错误的标签信息会严重影响深度神经网络的泛化性能。先前处理噪声的方法主要是通过设计鲁棒的损失函数[22-25],或是在学习过程中过滤掉噪声样本[26-30]以解决噪声。当在域适应学习中引入噪声设定时,学习问题会变得更加复杂,因为目标域样本伪标签的不可靠性不仅会由于域偏移引起,还会由于源域噪声引起。为了减小噪声样本的影响,目前对于噪声域适应问题的学习策略主要分为两类。一类策略是遵循Small Loss 准则将分类器筛选出的低置信样本标记为标签噪声样本然后剔除掉,仅收集干净的源域样本进行域适应。例如:文献[10]提出一种可迁移的课程学习方式,以增强干净源域样本的正迁移,从而减轻噪声带来的负迁移影响;文献[11]选择保留了特征损坏的数据并在对抗网络中使用代理分布改进课程学习方式。另一类策略是使用多个分类器的联合学习策略过滤掉带有噪声标签的源域样本。例如:文献[13]根据两个同等网络输出的不一致性进行互样本选择,挑选出可靠的源域样本进行之后的域适应学习;文献[12]研究了目标域包含未知类的通用型域适应学习,并优化了两个分类器之间的差异以检测噪声源样本;文献[31]针对噪声源域无关域适应问题,利用预生成标签和自监督学习中[32]自生成标签之间的关系对预训练模型进行微调。但以上方法都是丢弃掉检测出的噪声样本,仅使用干净样本进行训练,并且都忽视了特征层面噪声对网络带来的负迁移影响。
不同于以往方法,本文关注到不同噪声种类对域迁移的不同影响,实现了噪声样本的精确分类、矫正与回收。此外,本文还使用了随机分类器的思想,减少了学习过程中双分类器趋同对最终训练结果的影响。
2 NCDA方法
本文针对Noisy UDA 提出基于多分类器差异的噪声矫正域适应学习模型NCDA,其整体框架如图1所示。

Fig.1 Overall framework of NCDA图1 NCDA整体框架
2.1 NCDA整体流程
为方便描述,首先给出本文所用到的符号定义。有噪声标签源域数据和无标签目标域数据分别表示为。其中,s和t分别表示源域和目标域,Ns和Nt则表示源域和目标域的样本个数,K表示源域标签的种类数量。源域和目标域虽相关,但它们仍然有域间差异即两域的数据分布不同,即Ps(x) ≠Pt(x)。
为解决Noisy UDA 的问题,需要训练目标网络使其能在源域样本标签带噪声的有监督学习下正确分类出源域样本,再进一步对齐源域和目标域的数据分布从而完成域迁移。本文所提出的NCDA 方法的网络结构如图2 所示,整体网络主要由一个特征生成器G和两个分类器F1、F2组成。这两个分类器在小批量级别用相同的数据进行训练,但它们是用不同的参数随机初始化。带噪源域和目标域样本x依次进入特征生成器G和分类器F1、F2中,生成K维向量p1(y|x)和p2(y|x),它们分别表示两个分类器对样本K种标签的预测概率结果。最终,以分类器对样本预测向量的最大概率输出pk(y|x)作为其伪标签:
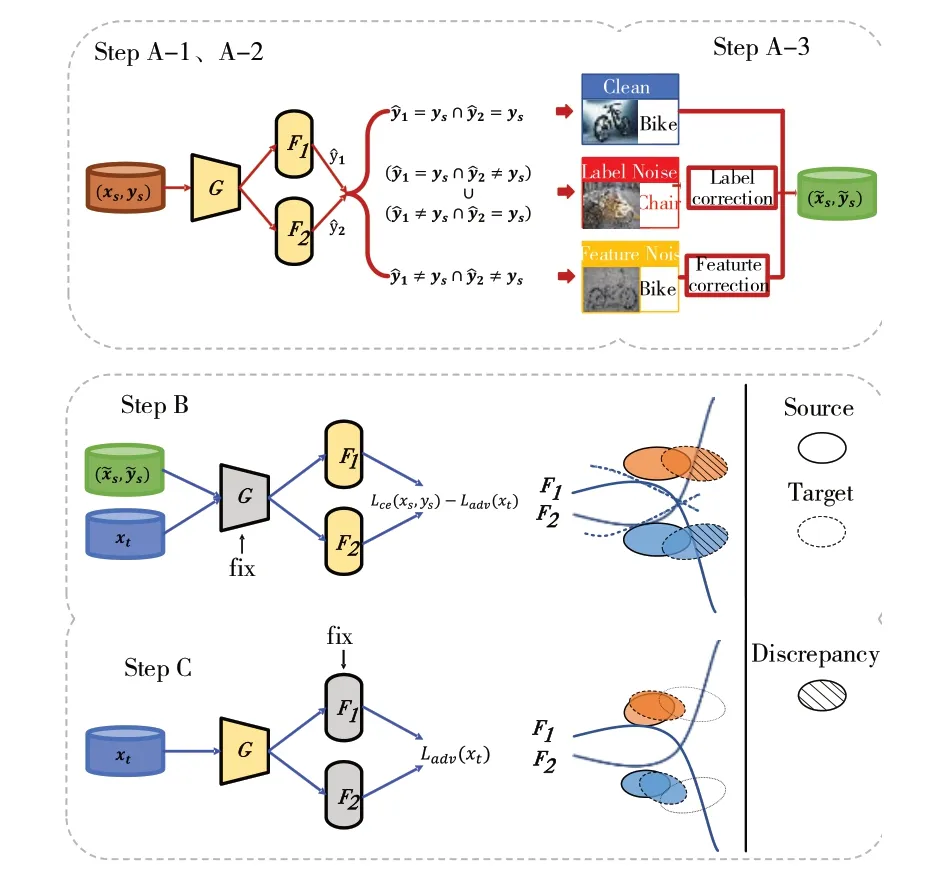
Fig.2 Network structure of NCDA图2 NCDA的网络结构
由于不同分类器的学习差异,对不同的带噪样本会生成不同的分类决策边界。由此,本文关注到不同分类器之间的分类差异,它们对干净无噪声的源域样本会有与给定标签一致的分类结果,而对带有特征噪声或是标签噪声的样本分类结果通常是不一致的,精确的分类方式将在下文具体介绍。因此,根据两个分类器的分类结果是否一致,可以检测出带有噪声的源域样本,之后根据其噪声类型作不同方式的矫正。针对特征噪声,采用mixup[34]的方式矫正靠近最邻近的聚类中心;针对标签噪声,则将标签矫正改为最邻近的类中心标签,以此回收样本利用于下一步的域适应流程。除目前流行的过滤噪声样本的小损失准则外,还选择了对多分类器预测差异较小的样本以更新每个小批量中的网络。与文献[3]相似,之后进一步最小化了正确标记的源样本的差异,从而最大化了两个分类器的一致性,以获得更好的结果。最后为优化网络,本文采用随机分类器的思想,将分类器的参数当作一个分布进行更新,避免网络中的两个分类器趋同,增强了鲁棒性。
2.2 噪声精确分类与矫正域适应过程
为了尽可能减少噪声对域迁移过程带来的负面影响,NCDA 使用检测噪声并矫正的方式,具体流程主要包括3个步骤,如图2 所示。在本文实验中,这3 个步骤在小批量的训练水平下重复进行。
Step A-1:在有标记的噪声源域样本监督下进行网络预训练。由于在训练初始阶段小损失样本大多标签正确[26,33],为了减少错误噪声标签对预训练的影响,本文在此阶段仅使用小损失实例训练特征提取器和分类器。训练过程使用常见的交叉熵损失,其定义如下:
Step A-2:噪声精确分类准则。由于特征噪声是在特征层面改变了样本点的分布,使其远离了类中心,靠近类间决策边界,因此多分类器通常会对特征噪声样本有不一致的预测结果。而标签噪声只是错误标记了样本,并没有改变其特征分布,故在某一类聚集处出现的个别另一类样本通常就是标签噪声样本,多分类器对这类样本有一致但不同于样本原标签的分类结果。最后,多分类器对于干净样本会有一致且与原标签相同的预测结果。至此,根据原标签与两个分类器预测结果的关系可将源域数据集分为3类:
其中,DCL、DFN、DLN分别表示源域根据上述精确分类准则划分出的3 个子集,即干净源域子集、特征噪声源域子集、标签噪声源域子集。
Step A-3:针对不同的噪声类别,NCDA 根据其特性采取了不同的聚类矫正方式。首先,根据干净源域子集DCL样本标签将其划分K个类簇(k=1,...,K),每个类簇的类中心向量ck可计算如下:
对于噪声样本,计算其与各个类中心的最小欧式距离,以确定其最近邻类中心ck*:
面对特征噪声子集DFN,采用mixup 矫正方式在特征层面将样本往其最近邻类中心拉近。矫正后的特征计算如下:
其中,λ为扰动权重,在实践过程中,根据当前模型的学习进度对其进行动态调整,最终将λ逐渐减小至0。由此,在训练初期,大部分特征噪声被弱化从而获得更好的域对齐效果,而随着训练的进行,当模型趋于稳定时,适当的特征噪声可以作为扰动提高模型鲁棒性。而针对标签噪声子集DLN,其错误标签会被修正为最近邻类中心所属类别k*。矫正完成之后,所有样本将再次投入网络中进行训练,在每轮训练中,最近邻类中心ck*都由式(5)重新计算更新。
Step B:需对齐源域和目标域的分布以实现域适应,分为B、C 两部分。首先固定特征生成器G,训练F1和F2两个分类器以最大化对目标域样本预测的差异,如图2 中的Step B 所示。同时,还需要最小化源域的有监督学习损失以保证分类器决策的可靠,可使源域类边界最大程度清晰。训练目标如下:
其中,本文利用两个分类器的概率输出之间的L1距离作为差异损失(Discrepancy Loss):
Step C:固定分类器F1和F2以训练特征生成器G,这一步骤对应图2 中的Step C。在固定分类器的情况下,更新特征生成器以最小化两个分类器对目标域样本预测的差异,以此实现源域和目标域分布的对齐。训练目标如下:
在本文方法中,以上A、B、C 3 个步骤交替进行,B、C两部分实则也是形成了特征生成器和分类器之间的对抗学习以实现域适应。为获得更好的域对齐效果,以上步骤会在小批量数据集下重复n次,在本文实验中设定n=4。
2.3 随机分类器思想优化域适应
在NCDA 的模型中使用两个分类器对目标域样本预测结果的差异进行损失计算,虽然这种方式在目前Noisy UDA 问题的各种基准上可产生相对更好的识别性能,但有几个基本问题常被忽略,即:多分类器差异这种模型设计中的最佳分类器个数是几个?为什么目前的方法大多使用两个分类器而非更多?直觉上,使用更多的分类器可以多角度识别更全面的特征分布[35],但直接在网络中添加更多个分类器的方式不仅会导致更多的网络参数、更高的计算复杂度,还会显著增加模型的参数量,导致模型过拟合的风险。因此,为优化多分类器,并且规避以上问题,本文采用了随机分类器[14]的思想,用两个分类器模拟近似无限个分类器集成到本文目前网络中。所要做的实则是改变分类器参数的优化方式,不再以传统方法中的具体单个变量表示参数,而是学习一个分布,两个分类器的参数是从学得的分布中采样表示。这种采样方式可以使两个分类器在不增加网络参数的前提下,尽可能多样地得模拟多个参数组合,即多个分类器以学习模型。
在NCDA 网络中的分类器是用高斯分布建模N(μ,σ),之后在训练中优化这个分布。本文将分类器权重向量视为随机变量,分布的平均值μ用作最终分类器的权重,而方差σ表示不同分类器的差异程度。在每次训练迭代中,从当前分布中随机抽样两个不同的新分类器,最终模拟大量分类器在整个训练过程中进行多次迭代。即分类器F1和F2可优化为从分布N(μ,σ)中采样的两个独立样本点,再通过重参数化技巧[36],公式可简化如下:
其中,θ1和θ2是从标准高斯中提取的两个独立样本,⊙表示元素乘积,α是σ的对角线。
因此,NCDA 网络可以用比以前多得多的分类器进行训练。这样的方式可以在训练Step A 步骤中避免两个分类器在训练中逐渐趋同,而导致对于噪声样本预测一致,无法进行精确分类的情况。还可以在训练Step B、Step C步骤中多样化分类器的决策边界,提升了网络模型的精确性和鲁棒性。
3 实验与结果分析
3.1 实验数据
本文所提出的NCDA 方法在3 个数据集上展现了其有效性,分别是:Office-31、Office-Home 和Bing-Caltech。Office-31 是包含31 类的4 652 张图片的标准域适应数据集,有Amazon(A)、Webcam(W)和DSLR(D)3 个域。Office-Home 是包含65 个类别、15 599 张图片的标准域适应数据集,由Artistic(Ar)、Clipart(Cl)、Product(Pr)和Real-World(Rw)这4 个较大域差异的域组成。为了引入噪声,本文按照文献[11]中的规则引入了3 种噪声,即:标签噪声、特征噪声以及这两种的混合噪声。标签噪声主要根据噪声率将图片的标签随机更改为其他类,特征噪声则是依据概率将图片进行高斯模糊或椒盐噪声损坏,混合噪声是将噪声率的50%即标签噪声,50%即特征噪声结合起来。Bing-Caltech 是一个由Bing 和Caltech-256 两个域组成的真实噪声数据集,它包含丰富的标签噪声与特征噪声。本文将Bing 作为噪声源域,将Caltech-256 作为干净的目标域。在所有实验中,依次应用模型从一个域迁移到另一个域。
3.2 比较方法
将本文方法NCDA 与最先进的噪声处理方法和标准无监督域适应方法进行比较,包括ResNet-50[37]、Self-Paced Learning(SPL)[38]、MentorNet[28]、Deep Adaptation Network(DAN)[4]、Residual Transfer Network(RTN)[39]、Domain Adversarial Neural Network(DANN)[6]、Margin Disparity Discrepancy based algorithm(MDD)[40]、Transferable Curriculum Learning(TCL)[10]、Robust Domain Adaptation(RDA)[11]。其中,SPL 和MentorNet 是噪声标签处理方法,为了更好地体现NCDA 方法中每一步处理的具体作TCL 和RDA 是噪声领域自适应方法,其他为标准领域自适应方法。
3.3 实验设置
本文网络结构和训练参数参考先前噪声域适应方法[11]的标准实验设置,使用带噪有标记的源域样本和未标记的目标域样本进行训练时,遵循UDA[6]中的标准,所有对比方法在Pytorch 深度框架中复现。为公平比较,所有方法设置相同超参数、预处理和特征提取网络。对于图像识别任务,将所有图像缩放至256×256。本文使用ImageNet[41]上预训练的ResNet-50 作为特征提取器,并在分类层之前使用完全连接的瓶颈层。在预训练阶段将每轮样本数设置为30,小损失阈值γ通常由先前文献[10-11]中的噪声经验或先验知识确定。并且,固定分离比p=0.08,将γ设置为大多数任务中第(N×p)个实例的损失。按照文献[37]中的标准方案,本文初始学习率设置为2e-3,在网络训练迭代周期90轮中的每30轮中将学习率衰减0.1。
3.4 结果分析
表1、表2 展示了本文方法在Office-31、Office-Home和Bing-Caltech 上的性能对比。可以发现:①在Office-31上,NCDA 的效果比其他噪声域适应处理方法在混合噪声任务上更胜一筹,平均比RDA 方法高出1.4%,比TCL 方法高出6.3%;②在Office-Home 上,NCDA 方法在Ar→Cl、Pr2→Cl、Pr→Ar、Rw→Cl 这4 个困难的域迁移任务上都取得了明显提升,这也促使NCDA 方法在总体上优于其他方法,说明NCDA 在迁移时更具可迁移性和鲁棒性;③在Bing-Caltech 上,NCDA 方法大幅度优于目前最先进的深度域适应方法DAN、DANN 等,因为这些方法的源域受到噪声影响导致迁移泛化性能不佳,同时也优于TCL、RDA 这类噪声域适应方法,展示了本文精确分类检测噪声、矫正噪声的优势;④NCDA 在预测精度上展示了比现有大多数标准无监督域适应方法和噪声域适应处理方法更好、更稳定的效果,这体现了NCDA 方法的优越性,也表示了本文对源域样本噪声的有效的精确分类检测和矫正,提升模型的预测准确性的同时也保证了其鲁棒性。用,本文在Office-31 数据集引入40%的混合噪声,消融实验结果如表3 所示。可以看出,放弃特征噪声与标签噪声的矫正均会导致性能下降。因此,在学习过程中处理标签噪声和特征噪声是合理的。此外,相比传统双分类器方法,使用随机分类器思想对于UDA 的多分类器方法的优化也是有效的。

Table 1 Target domain classification accuracy of Office-31 in a 40%mixed noise scenario表1 Office-31在40%混合噪声场景下的目标域分类准确率(%)

Table 2 Target domain classification accuracy of Office-Home and Bing-Caltech in a 40% mixed noise scenario表2 Office-Home、Bing-Caltech在40%混合噪声场景下的目标域分类准确率(%)
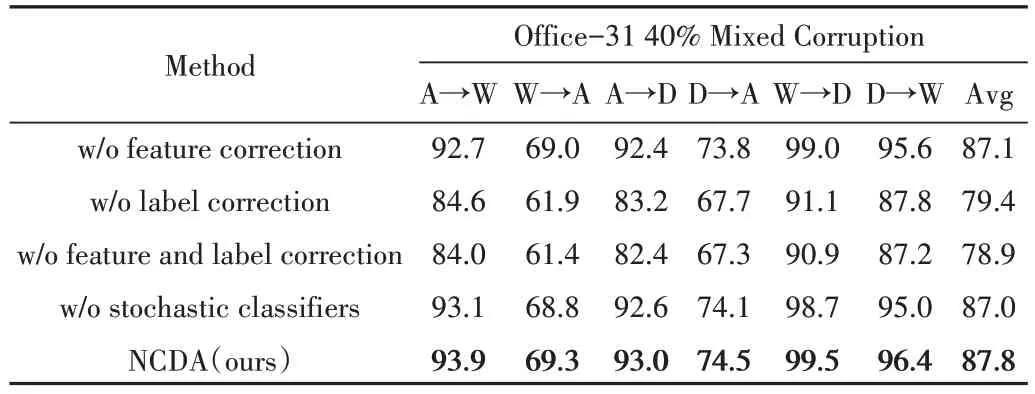
Table 3 Ablation study of NCDA表3 NCDA消融实验(%)
3.5 不同噪声水平下的实验
3.5.1 不同噪声水平下的噪声识别准确率
为了展示本文提出的对源域样本进行精确分类检测方式的有效性,在Office-31 数据集A→W 任务上做了不同噪声水平下的噪声识别实验,如图3 所示。从NCDA 方法检测出的标签噪声、特征噪声的准确度可以看出,经过精确分类检测出的两种噪声近八成是准确的,这说明了精确分类这一步的有效性,也为后续噪声矫正这一步打下了基础。
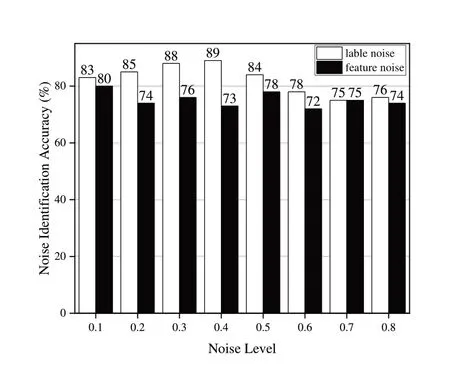
Fig.3 Accuracy of NCDA detecting noisy samples图3 NCDA识别噪声样本的准确率
3.5.2 不同噪声水平下各方法的目标域分类准确率
图4 展示了在不同噪声比例下Office-31 数据集的A→W 任务上,不同混合噪声比下各方法的性能。具体而言,噪声水平从0.0 到1.6,其中0.0 表示无噪声UDA 场景,1.6表示160%的混合噪声,即80%的标签噪声混合80%的特征噪声。从图4 可以看出,随着噪声水平的增加,所有方法的性能都会降低,尤其是DANN 和ResNet 这类没作噪声处理的方法。NCDA 的性能随着噪声水平的增加而更加稳定,并且优于其他方法。值得注意的是,当噪声水平为1.6时,NCDA 的性能比其他方法要好得多。原因可能是NCDA 在学习中矫正和回收噪声,从而可以充分利用数据,尤其是在高噪声的场景中。同时,NCDA 在噪声水平为0 时也实现了最佳性能,这证明本文方法也适用于标准UDA场景。

Fig.4 Accuracy of target domain detection图4 目标域识别准确率
3.6 t-SNT可视化特征分析
NCDA 方法及其主要对比方法在Pr→Rw 任务上40%混合噪声情境下的可视化特征比较如图5所示。
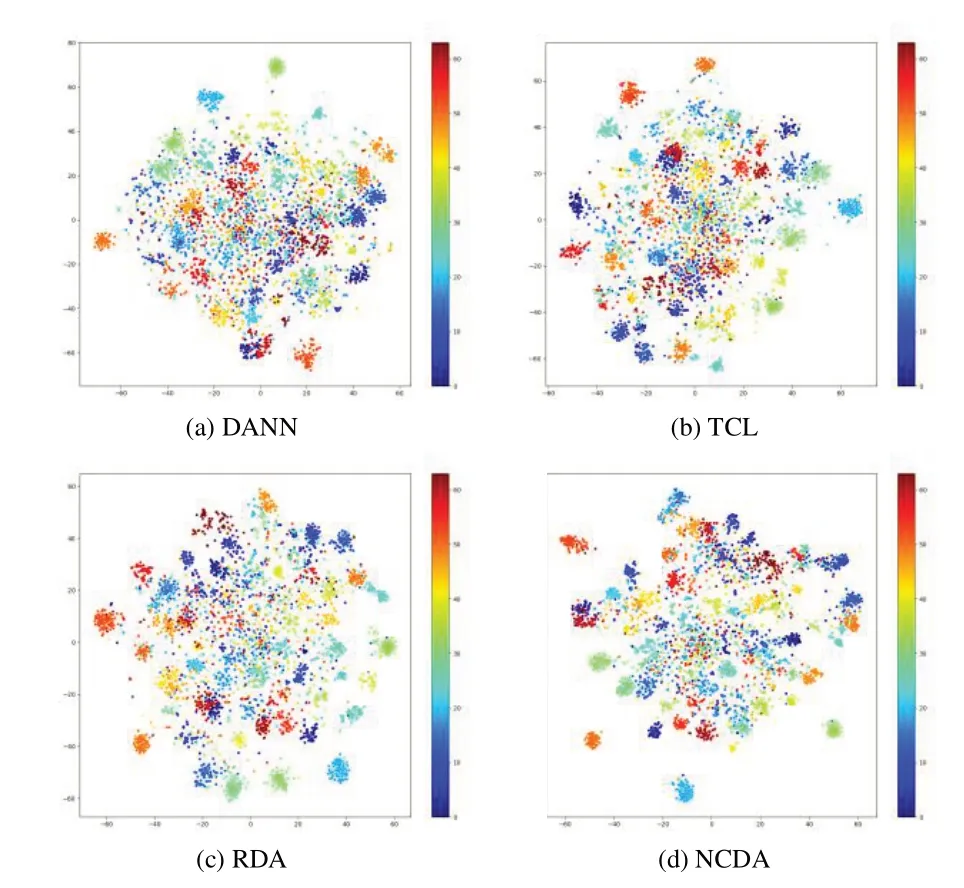
Fig.5 The t-SNE visualization feature comparison图5 t-SNE可视化特征比较
图5(a)-(d)展示了学习的目标特征分布,不同颜色表示不同的类别(彩图扫OSID 码可见)。可以看出,DANN 学得的不同类别的特征混合在一起,其他方法虽能对目标域数据有不错的分类效果,但是它们的类别边界非常模糊,而NCDA 对比其他方法能够更好地区分出类别边界,且能实现一定程度上的类内紧凑、类间分离的效果,因此可见NCDA 对噪声的处理非常有效。
4 结语
本文针对极具挑战的噪声域适应学习提出了简明有效的NCDA 方法。除标签噪声外,本文还关注到了特征噪声,提出了精确分类噪声并将其进行矫正的方式,这样回收样本的方式在高噪声环境下也能有效实现域迁移,且采用随机分类器思想的优化方式也能提升域适应的效果。实验结果表明,与现有的域适应和噪声处理技术相比,NCDA 方法实现了显著的性能改进。
