基于Apriori算法的海事事故中人为失误致因探讨
2023-11-22蔡源忠九江市港口航运管理局
◎ 蔡源忠 九江市港口航运管理局
近年来,随着海上经济的快速发展,海事事故的发生频次也在不断增加,据相关统计数据显示,多达90%以上的海事事故均为人为因素引发,及时掌握海事事故当中人为因素所带来的影响,是强化海事事故预防,降低事故影响的重点所在。通过关联规则当中的Apriori算法,能够较为直观地挖掘出人为失误与海事事故之间的相互关系,为海洋运输管理部门的有关举措提供更加客观准确的参考,使海事事故的预防方案能够进一步契合事故实际情况,保障海上运输业安全。
1.Apriori算法基本原理
Apriori算法是最为常见的一种关联规则挖掘算法,其主要运用逐层搜索的迭代方法对项集当中的关联性进行挖掘,进而形成关联规则。在海事事故致因分析过程中,可将事故案例作为事物集D,将导致事故发生的各项信息组成项集I,其中,I={i1,i2,i3,...,ik},项集当中的各项要素涵盖了事故信息、事故诱因等涉及海事事故致因分析工作的关键要点。将人为因素作为条件X,将事故信息作为结论Y,分析条件X至结论Y之间的强度则能够得到人为因素与海事事故之间的关联性,进而实现对事故致因的探讨[1]。
由于项集I当中涉及的事故信息较为复杂,给分析工作带来了一定难度。因此可选取典型性信息作为分析代表,并对其进行编码,设最小支持度为min_sup=20%,最小置信度为min_conf=70%,能够针对编码后的信息进行筛选,得到频繁项集。与此同时,按照上述支持度与置信度计算要求对项集内部信息进行多次迭代,并基于置信度公式对信息置信度进行验证。公式为:
待置信度验证完成后,能够明确频繁项集当中海事事故相关因素与事故影响之间的关联性特征,为实现针对海事事故的有效预防提供支持。
2.海事事故致因要素整合处理
在Apriori算法下,海事事故致因要素的分析更加严谨,为减少算法误差对分析精度造成的影响,在致因分析之前,需要对项集模型当中涉及的要素进行整合处理,使其能够符合Apriori算法分析要求。
2.1 布尔数据转化
作为一种单维布尔型的数据挖掘算法,在针对海事事故人为致因进行分析和研究的过程当中,应将多维要素进行转化,使数据挖掘结论更加全面。事故项集I当中的信息内容涵盖的布尔信息包括违规值班、能见度不良等等,在针对算法模型进行构建的同时,应当具备对信息数据形态进行辨识的功能,模型内部应将单维布尔型数据的属性值设定为1,将多维信息数据的属性值设定为0,使Apriori算法下不同事故致因要素在事物集D当中的比重能够较为直观地展现在模型当中。基于布尔数据转化过后的要素分析主要涉及组织管理、监督安全以及事故发生条件等三个层次。具体数据见表1至表3。
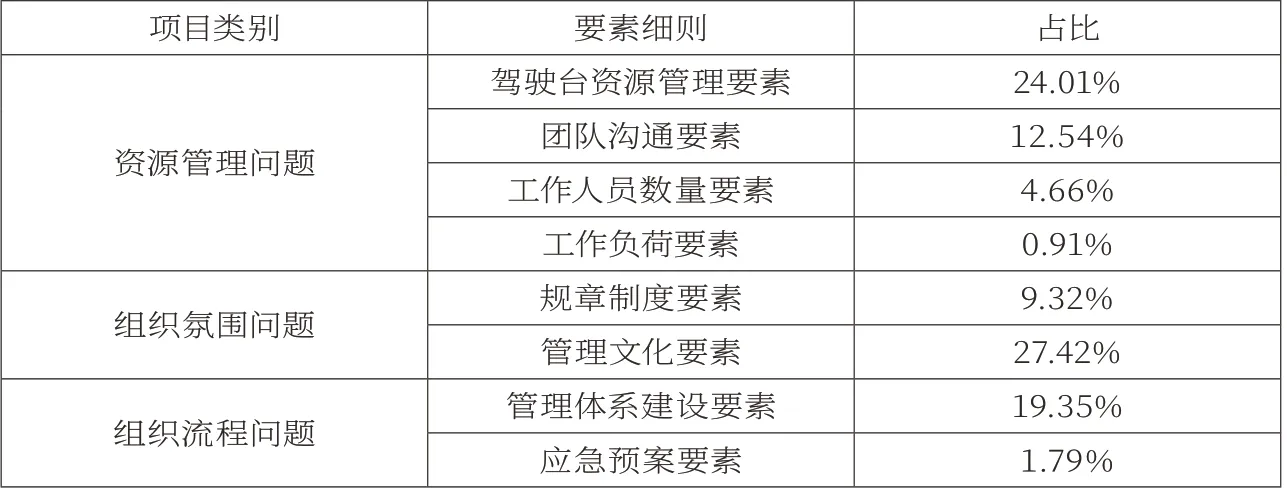
表1 组织管理层次在要素分析当中的占比
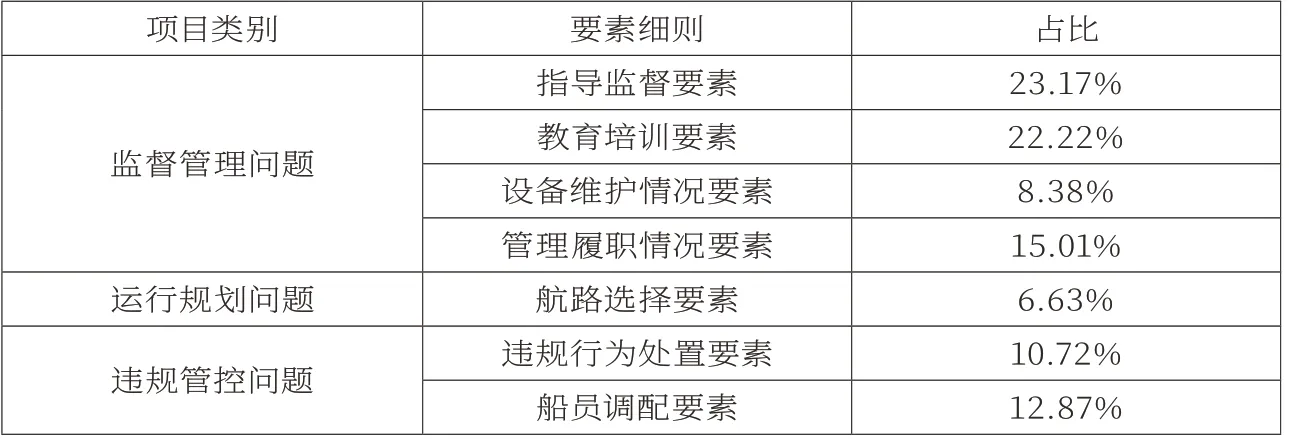
表2 监督安全层次在要素分析当中的占比

表3 事故发生条件层次在要素分析当中的占比
2.2 枚举数据处理
上文当中,主要针对海事事故发生过程当中涉及的布尔型数据进行了初步梳理,为了覆盖更加广泛的海上事故状况,提升海事事故预防工作成效,还需要从枚举角度对项集当中涉及的事故信息进行全面分析,使天气要素、人为失误要素等信息进一步细化,使Apriori算法的分析工作开展更加合理[2]。本文以人为因素为例进行论证。在海事事故人为失误致因要素当中,可分为人员因素与管理因素两类,其中人员因素涵盖了海上运输工作人员的适任性情况、工作人员的身心状态、对海上运输环境的感知、对运行风险的辨识判断与决策、风险处理过程当中的操作行为等,管理因素主要涵盖了船上资源管理、处置流程优化、安全氛围建设、风险行为监督、安全运行规划、违规行为处置等。针对枚举数据进行处理过后,能够使Apriori算法下的数据挖掘工作得到较为全面的内容支撑,保障数据挖掘价值。
2.3 数值数据离散
海洋运输业发展过程当中涉及的各项事故信息类别较为丰富,这就给数据之间非线性关系的描述和分析带来了一定的挑战。此外,事故信息项集内部可能存在的一些异常数据信息也会对最终的分析结果带来一定的负面影响。因此在运用Apriori算法进行海事事故信息数据整合处理的同时,还应当针对数值数据进行离散处理,使其能够回归自身属性值,进而摒弃异常数据对于算法分析结果产生的影响,确保致因分析的准确性。在基于Apriori算法针对海事事故数据信息进行挖掘的同时,主要涉及支持度、置信度两项指标,因此离散化处理的过程中也应当做好变量控制,使数据结论更加完善。
在离散分析之前,将项集内部有关于海事事故的信息要素的支持度阈值控制在20%,同时将置信度阈值控制在25%,进而对项集I内部各项信息要素与事故发生时的关联特性以及关联规则进行比对分析,并且在支持度阈值不变的前提下,针对项集I当中数据信息的置信度阈值进行调整,对最终获取到的信息关联规则进行排序,最终得到离散分析过后的关联规则。基于上述规则,能够进一步减少异常信息给致因分析结论造成的影响,实现对规则冗余的充分排除,为海事事故人为失误的致因分析提供支持。
3.基于Apriori算法的人为失误致因分析
3.1 信息来源
作为一项布尔型数据挖掘算法,Apriori算法需要大量数据作为基础和支持,在选择海事事故案例的过程当中,研究者应当遵循以下几方面原则。第一是时效性原则,为了使海事事故调查报告具备更加充分的参考价值,减少社会环境变化以及技术发展对项集内部信息产生的影响,应尽可能将案例选择的时间阈值控制在10年以内。第二是权威性原则,相关海事事故的调查报告必须来源于各国官方机构。第三是随机性原则,在针对海事事故调查报告进行筛选与整理的同时,应尽可能保障筛选过程的随机性,避免事故类别以及事故影响范围对研究造成的影响。第四是完整性原则,在基于Apriori算法对不同海事事故调查报告进行分析与梳理的过程中,应保障调查报告内容的全面完整,其内部应涵盖事故原因、事故影响、事故类别等多项关键性内容,使人为失误与海事事故之间的关联性得到进一步凸显[3]。
为适应Apriori算法分析要求,满足上述信息来源与筛选原则,本次研究过程中基于各国海事事故调查报告选择了100个样本,具体案例如表4所示。

表4 海事事故调查报告样本
3.2 相关性分析
在基于Apriori算法针对人为失误与海事事故之间的关联性进行调查与研究的过程中,应依托上述筛选完成后的100个权威海事事故调查报告为例对其涉及的数据信息进行相关性分析,从而获取到人为失误与海事事故之间的关联性规则。
首先,基于上述海事事故调查报告设定事故事物集D,其中包括筛选完成的100个各国发布的典型性海事事故案例,同时,依托案例调查报告,将海事事故调查过程中所涉及的影响要素纳入项集I当中,本次研究涉及的人为失误共13类,事故影响要素共32类,因此项集I当中的要素总数为45个。与此同时,将A设定为海事事故当中人为失误集合,将B设定为事故影响要素集合。
其次,在依托Apriori算法进行关联分析的过程中,应明确各要素之间的支持度与可信度阈值。一般可采用经验法以及变量控制法两种方法对要素关联阈值进行设定,为了减少误差因素对于最终数据挖掘结果造成的影响,提升Apriori算法分析结论的可信性,本次研究当中采用了变量控制的策略对项集I当中各要素的支持度、可信度阈值进行设计,经迭代计算过后,最终确定支持度阈值为30.5%,可信度阈值为34.7%。
最后,基于迭代分析得到的信息支持度与可信度阈值,针对要素与事故之间的关联规则进行明确。计算公式为:
式中,s为海事事故致因分析过程当中的要素支持度,c为海事事故致因分析过程当中的要素可信度。最终的关联规则如表5所示。

表5 Apriori算法计算过后的要素关联规则
3.3 资料勘探
在不同阈值条件下,最终得到的分析结论也存在一定的差异,进而得到的人为失误与海事事故之间的关联性也存在相应区别。其中,在海洋运输航行过程当中,对于风险信息的处理能力、航道选择能力、航行知识经验、风险监督以及作业注意力等相关要素与海事事故之间的关联性较强,可能引发海事事故的概率较高。
4.海事事故预防建议
为了进一步降低海事事故发生概率,减少海事事故给海洋运输业以及海上经贸活动造成的影响,有关单位与从业者应分别基于内部环境与外部条件两方面做好事故预防工作。
4.1 内部环境预防
从内部环境来看,海上运输作业人员的能力与素质与海事事故的发生具有较为明确的关联性,因此有关企业与单位应当积极加强有关作业团队的选拔与培养工作,同时因地制宜做好运输作业监管,避免严重海上事故的发生[4]。
4.2 外部条件预防
从外部条件来看,在海上航行作业之前,应当加强对航行环境以及航行条件的监控,避免在恶劣环境或密集交通下进行作业,保障海上航行安全。
5.结论
综上所述,在海上航行作业过程中,人为失误对事故的发生具有重要影响。相关研究者可基于Apriori算法对人为失误与海事事故之间的关联特征进行分析和明确,力求规避海事事故造成的影响,为海事监管工作的正常开展奠定基础。
