低面积与低延迟开销的三节点翻转容忍锁存器设计
2023-10-17闫爱斌黄正峰
闫爱斌 申 震 崔 杰 黄正峰
①(安徽大学计算机科学与技术学院 合肥 230601)
②(合肥工业大学微电子学院 合肥 230601)
1 引言
随着CMOS技术的不断发展,重离子、中子、质子、α粒子和电子等高能辐射粒子的撞击会导致集成电路发生软错误,如单节点翻转(Single Node Upset, SNU)、双节点翻转(Double Node Upset,DNU)和3节点翻转(Triple Node Upset, TNU)[1]。软错误是瞬态错误,这意味着受影响的电路不会受到物理损坏,并且可以通过数据重新加载或抗辐射加固设计(Radiation Hardening By Design, RHBD)方法消除错误。据悉,在深亚微米和纳米技术中,单粒子多节点翻转对电路构成了严重威胁[2]。研究表明,电路越来越高度集成,相邻电路节点的逻辑状态就容易受到电荷共享机制下单个高能粒子的撞击的干扰。因此,不仅应考虑SNU和DNU,还应考虑TNU对电路的影响,而研究低面积与低延迟开销的3节点翻转容忍锁存器即变得越来越重要。
为了缓解现有锁存器加固主要存在的问题,本文基于RHBD方法,提出一种基于双联互锁存储单元 (Dual-Interlocked-storage-CEll, DICE)和C单元的TNU容忍锁存器,同时实现低面积与低延迟开销。本文所提锁存器主要包括两个用于存储逻辑值的SNU自恢复DICE单元和3个用于双级错误拦截(Dual-Level Error-Interception, DLEI)的C单元,为锁存器提供完备的TNU/DNU/SNU容忍性。由于使用了时钟门控(Clock-Gating, CG)技术和少量晶体管,所提锁存器在延迟、面积和延迟功耗面积积(Delay-Power-Area-Product, DPAP)方面的开销很小。仿真结果表明,与最先进的TNU容忍锁存器设计相比,所提出的锁存器具有TNU/DNU/SNU容忍性和低开销特性。
2 已有的加固结构
目前,国内外学者提出了许多基于RHBD方法的加固锁存器[3–6]。一类加固方法通过提高节点电容和晶体管尺寸增加节点的关键电荷,以提高锁存器容忍多节点翻转的能力,但其只能部分容忍多节点翻转;另一类加固方法通过修改锁存器的结构,以实现完全容忍,使得锁存器输出正确逻辑值[3]。注意到,基于C单元和DICE单元的第2类加固方法较为常用。一些常用的基本元件如图1所示。图1分别显示了双输入反相器、传输门、DICE单元和C单元的电路图。

图1 基本元件
图1(a)是双输入反相器的结构图,对传统反相器输入端进行了分离。图1(b)是传输门的结构图,即一个PMOS晶体管的栅极连接到反向时钟信号(Negative system ClocK, NCK),一个NMOS晶体管的栅极连接到时钟信号(system CLocK, CLK),它的作用相当于时钟信号的开关器件。图1(c)是DICE单元的结构图,DICE单元可以从任何SNU中自恢复,但是它仅能从部分DNU中自恢复。图1(d)分别是2输入、3输入C单元以及基于时钟门控(CG)的C单元结构图。当C单元的输入值相同时,输出值为输入值的相反值。但是,当其输入值变得不同时,C单元将进入高阻态,输出将暂时保持原先的值。这意味着,如果C单元输入端的值变化是由错误引起的,则C单元可以消除错误的影响,即输出端的值仍然暂时正确。下面介绍一些典型的锁存器加固设计方案。
图2(a)为反馈冗余SNU容忍(FEedback Redundant SNU-Tolerant, FERST)锁存器结构[7]。该结构由多个C单元组成,充分利用3个C单元消除锁存器内部粒子撞击造成的影响。该锁存器通过C单元建立反馈冗余机制,用冗余反馈线控制SNU,以达到容忍SNU的目的。然而,该锁存器不能容忍DNU及TNU。
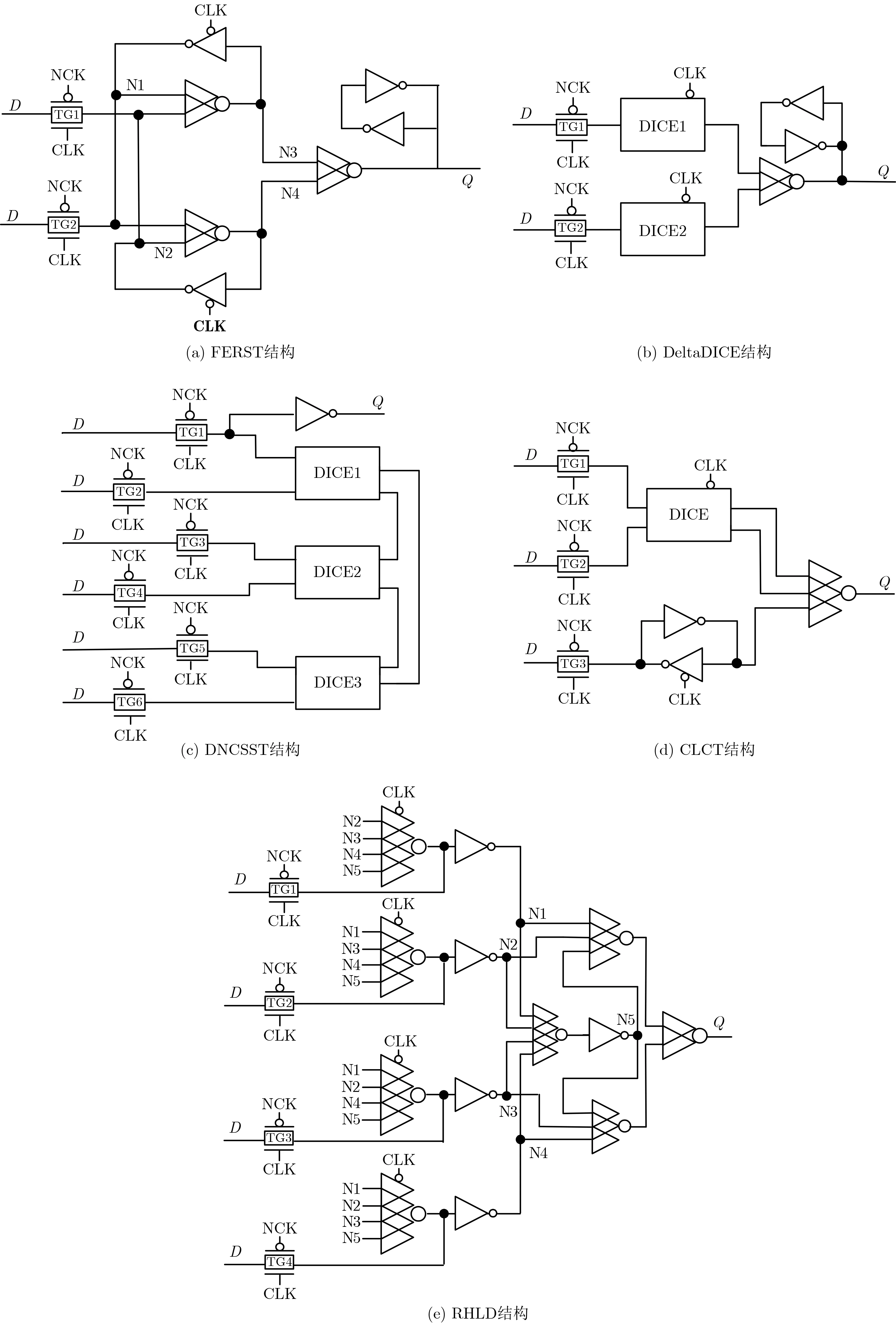
图2 已有的加固结构
图2(b)为三角形DICE (Delta Dual-Interlockedstorage-CEll, DeltaDICE)锁存器结构[8]。该结构不仅能实现SNU容忍,也能实现DNU容忍。该锁存器由3个DICE单元组成,通过提供足够的冗余结点来实现SNU容忍以及DNU容忍。然而,该锁存器使用多个DICE单元不仅使得面积增大,也造成较高的功耗,并且,该锁存器不能容忍TNU。
图2(c)为双节点电荷共享SEU容忍 (Double Node Charge Sharing SEU Tolerant, DNCSST)锁存器结构[9]。该结构由2个DICE单元、1个2输入C单元以及1个输出端电荷保持器组成。该锁存器能实现SUN容忍。若一个SNU影响任何一个DICE单元,其中储存的数据都不会发生改变,即该锁存器的输出端仍会保持正确的逻辑值,显然该锁存器能实现SNU容忍。该锁存器通过2个DICE单元和1个2输入C单元组合也可以实现DNU容忍。然而,该锁存器不能容忍TNU。
图2(d)为电路和布局组合技术 (Circuit and Layout Combination Technique, CLCT)锁存器结构[10]。该结构由1个时钟门控DICE单元、1个反馈环以及1个在输出端的3输入C单元组成。通过采用电路结构和布局相结合的方式,可增强多节点翻转容忍性。该锁存器中只有4个敏感节点对,可以较大程度地减少敏感节点对。通过调整布局位置,这些敏感节点对尽可能彼此分离,较好地解决了敏感节点对上的错误电荷收集问题。该锁存器不仅可以实现SNU容忍,也可以实现DNU容忍。然而,该锁存器的传输延迟和面积较大,故具有较大的开销,且并不能实现TNU容忍。
图2(e)为抗辐射加固锁存器(Radiation Hardened Latch Design, RHLD)结构[11]。该锁存器主要利用了C单元的错误拦截特性,通过多个C单元及传输门建立反馈连接,实现容忍3节点翻转的功能。但是,由于使用较多的C单元,电路内部节点可能会长时间保持高阻态,导致漏电流,并且该锁存器使用了80个以上数目的晶体管,具有较大的面积和功耗开销。
3 本文所提加固锁存器设计
3.1 电路结构及工作原理
本文所提锁存器设计的电路原理图如图3所示。
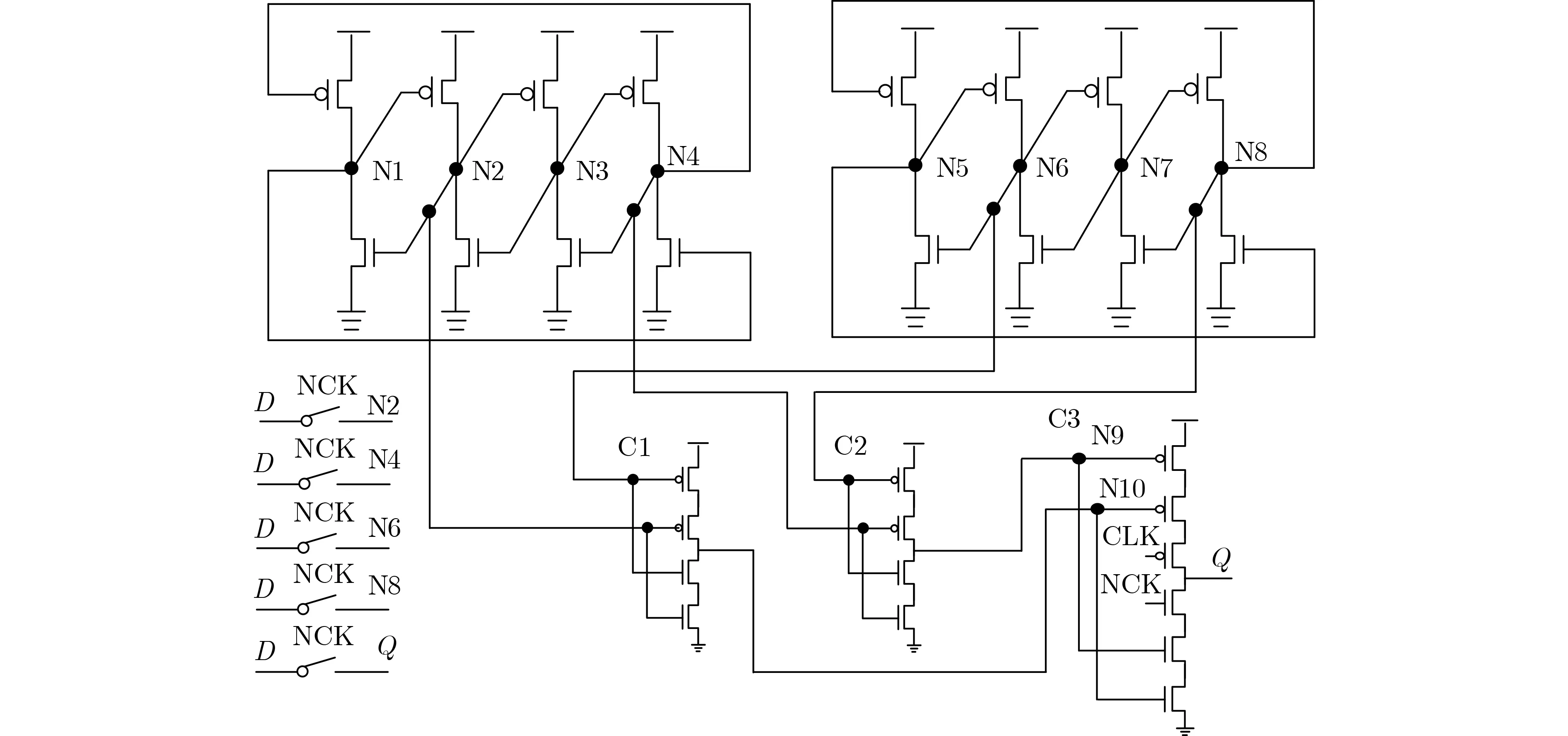
图3 本文所提锁存器原理图
可以看出,锁存器由2个DICE单元、2个2输入C单元(C1和C2)、1个基于CG的2输入C单元(C3)和5个传输门(TG)组成。其中,DICE用于存储值,C1和C2用于1级错误拦截,C3用于2级错误拦截,TG用于初始化锁存器的值。在锁存器中,D, Q,CLK和NCK分别是输入、输出、系统时钟和反向系统时钟信号。C3使用了钟控(见图3),即一个PMOS管连接到时钟信号,一个NMOS管连接到反向时钟信号,使该锁存器在透明期避免各器件同时向Q输出值所产生的电流竞争,降低了功耗和延迟。图4显示了所提出锁存器的版图设计。
当CLK=1且NCK=0时,5个传输门打开,锁存器在透明模式下工作。因此,输入信号D通过传输门将信号传输至内部节点N2, N4, N6, N8。随后,可以获得N1, N3, N5, N7, N9和N10的信号值。需要注意的是,Q是通过传输门而不是C3的输出确定的,因为C3的输出通过CLK和NCK信号被阻止,以减少透明模式下Q点的电流竞争和D到Q的传输延迟。
当CLK=0且NCK=1时,5个传输门关闭,锁存器切换到保持模式。此时传输门关闭,但钟控C单元被打开。因此,Q仅由N9和N10通过C3驱动,C3将存储值输出到Q。
3.2 容错原理
接下来,讨论保持模式下锁存器的SNU/DNU/TNU容错原理。
首先,考虑电路发生了SNU。某节点发生翻转,有两种可能,从0翻转到1和从1翻转为0。由于DICE本身具有SNU容忍性且能自恢复[12],因此锁存器发生SNU也是可以自恢复的,显然锁存器可以容忍SNU。
接下来,考虑该锁存器发生了DNU。由于DICE是对称构造的,因此只需要考虑以下情况:情况D1:没有任何DICE受到影响,关键节点对有
在(D1)的情况下,由于DICE没有错误,可以消除C3单元节点中的错误,即锁存器是DNU可恢复的。在(D2)的情况下,每个DICE都有一个SNU,但DICE是SNU可自恢复的。因此,可以消除DICE的错误,即在这种情况下,锁存器是DNU自恢复的。在(D3)的情况下,当N1,N2,N3和N4中的两个受到DNU的影响时,受影响的DICE中的所有节点都将被翻转为错误值,因为受影响的DICE在最坏的情况下无法提供DNU容忍性[12]。但是,由于C1和C2提供的错误拦截机制,错误的值可以被C1和C2屏蔽,即C1和C2仍然可以输出正确的值。因此,锁存器最终输出值Q依然是正确的。此外,当一个DICE的一个节点以及N9, N10和Q中的一个节点受到DNU的影响时,锁存器可以从错误中自恢复。这是因为,DICE是SNU自恢复的,然后可以消除C3单元节点的错误值以返回到正确的状态。总之,锁存器可以容忍任何可能的DNU。
最后,考虑电路发生了TNU。由于DICE是对称构造的,因此只需要考虑以下情况。情况T1:没有DICE受到影响,关键节点列表仅有
在(T1)的情况下,由于DICE没有错误,它们可以消除C3单元节点中的错误,即在这种情况下,锁存器是TNU自恢复的。在(T2)的情况下,如上所述,受影响的DICE在最坏的情况下无法提供DNU容忍性,因此受TNU影响的DICE中的所有节点都将翻转到错误的值。但是,错误的值可以被C1和C2屏蔽,即C1和C2仍然可以输出正确的值。因此,锁存器输出值Q依然是正确的。换言之,在这种情况下,锁存器可以容忍任何可能的TNU。在(T3)的情况下,如果节点列表包含N2和N6,则这种情况类似于(T2)的情况。否则,任何DICE中将只有1个节点受到影响。但是,由于任何DICE都可以从任何SNU自恢复,因此受影响的节点N2和N6(或N2和N7)可以首先从TNU自恢复,从而使DICE消除N9和Q上的错误。在这种情况下,锁存器可以容忍任何可能的TNU。总之,提出的锁存器可以容忍任何可能的TNU。
3.3 注错实验
按照电路中同时发生翻转的节点数目,分别对SNU, DNU和TNU加以分析,并且使用HSPICE工具进行故障注入分析。仿真条件如下:锁存器采用22 nm CMOS工艺设计。电源电压设置为0.8 V并将仿真温度设定为室温。使用Synopsys HSPICE进行了仿真实验。对于故障注入,采用了双指数电流源模型,电流脉冲的上升和下降时间常数分别设置为0.1 ps和3.0 ps。事实上,该模型在此前的研究中已被广泛使用[3,13–17]。如文献[3]采用双指数电流源模拟高能粒子入射引起的瞬态电流,并将仿真时故障注入电荷量设置为15 fC,文献[17]将故障注入电荷量选择性设置为20 fC。本文注入的电荷高达25 fC,这足以考虑最坏的情况,从而验证所提出的锁存器的SNU, DNU和TNU容忍性,对所提锁存器的晶体管尺寸进行了优化,使得PMOS晶体管的W/L为32/22 nm而NMOS晶体管的W/L为28/22 nm。
图5显示了该锁存器无注错情况下的仿真结果。从中可以看出,当CLK=1时,D上的信号可以传播到Q;当CLK=0时,D的状态可以存储在锁存器中,即该锁存器可正常工作。
图6显示了考虑所有关键SNU节点情况下的仿真结果。当Q=0时,在这些节点上注入SNU的时刻分别为0.30 ns, 0.70 ns, 1.10 ns, 3.70 ns, 4.20 ns和4.70 ns;当Q=1时,在这些节点上注入SNU的时刻分别为1.70 ns, 2.20 ns, 2.70 ns, 5.70 ns, 6.20 ns和6.70 ns。从图6可以看出,该锁存器可以从任何可能的SNU中自恢复。因此,该锁存器具有SNU容忍性和自恢复性。

图6 SNU注错实验
图7显示了所有关键节点对
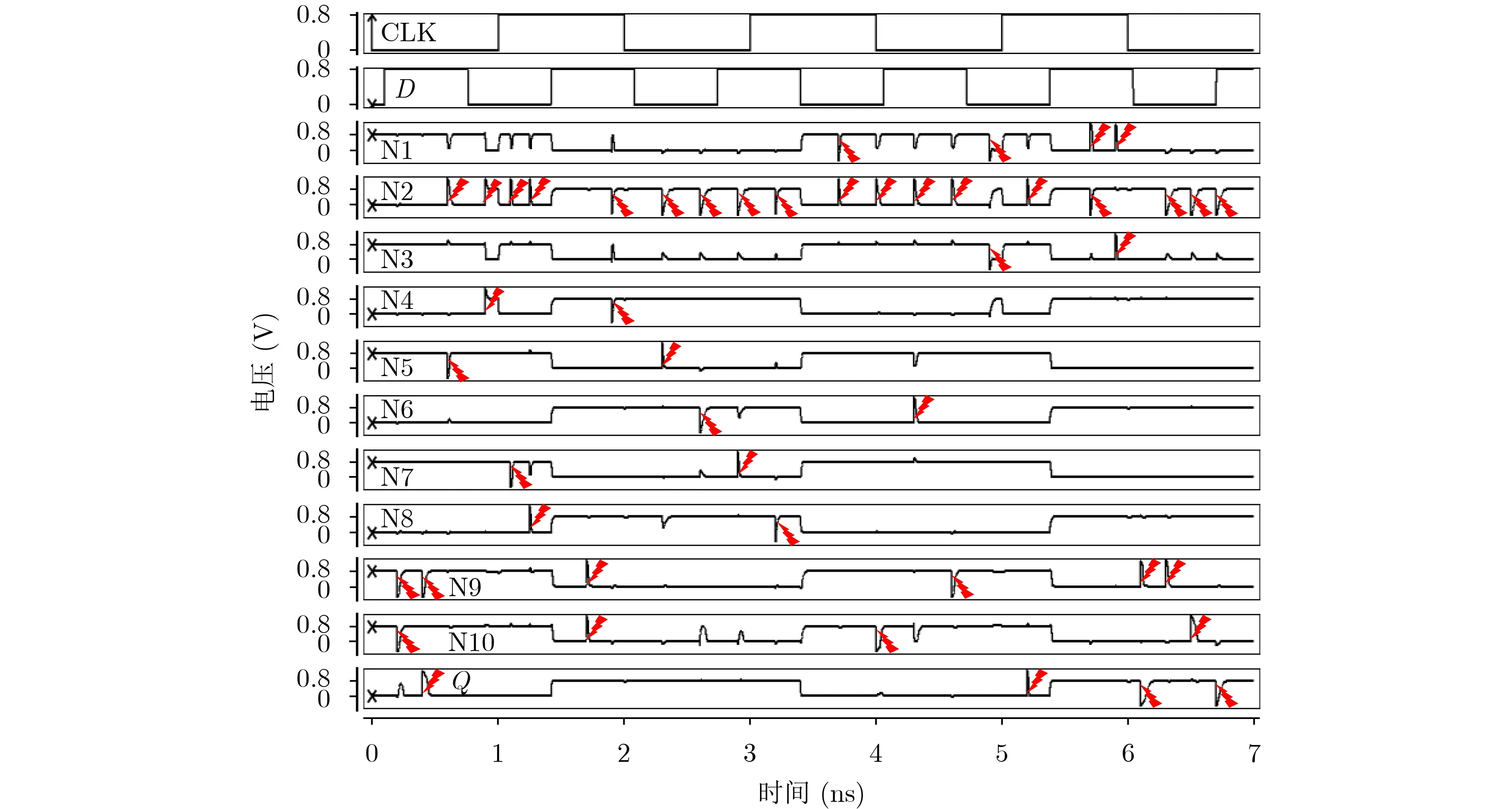
图7 DNU注错实验
图8显示了TNU注错实验的仿真结果,考虑了关键节点列表
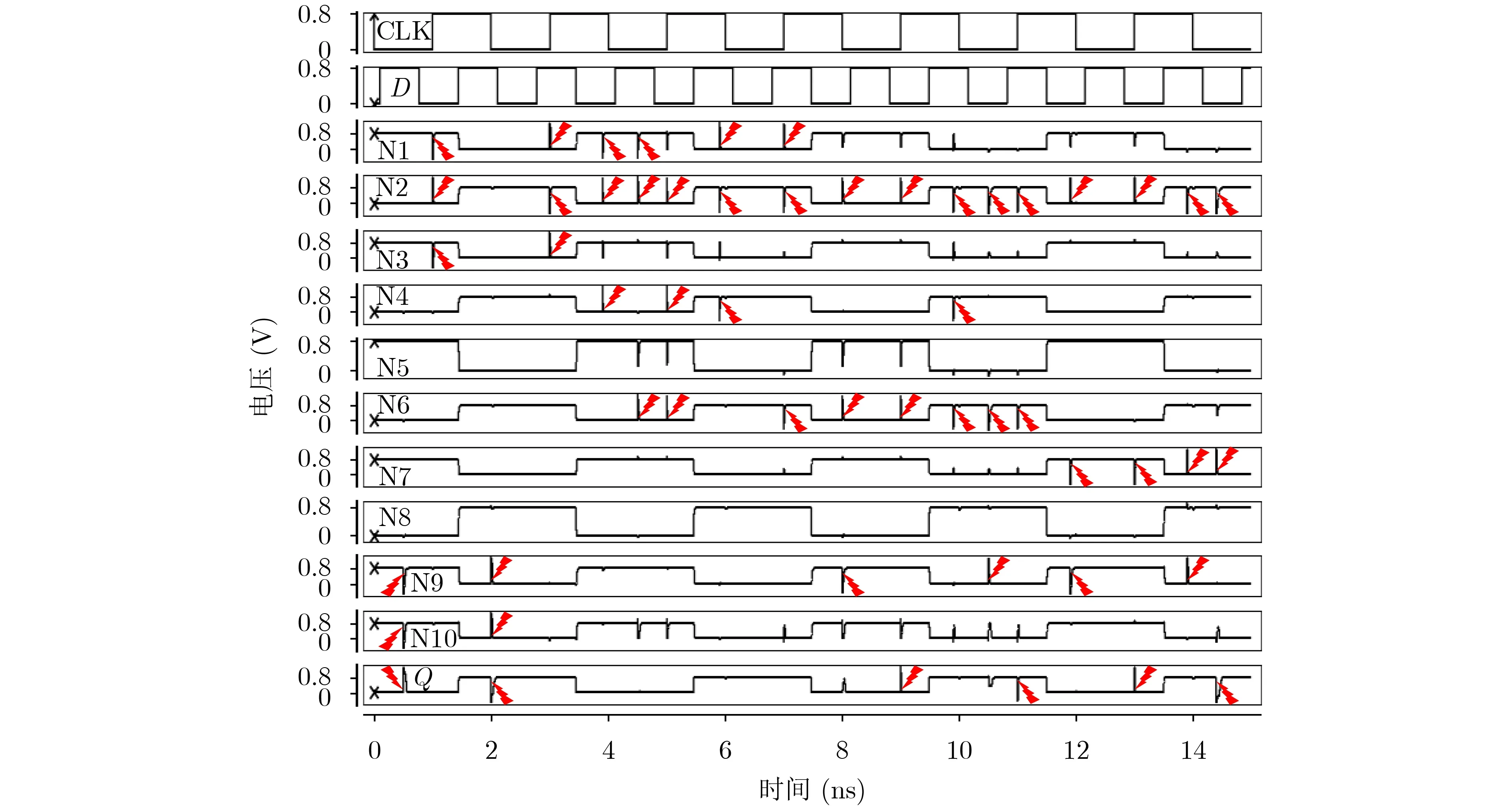
图8 TNU注错实验
4 锁存器比较
4.1 可靠性比较
为了公平比较,将典型的锁存器,如FERST、双节点翻转恢复(Double Node Upset resilient,DNUR)锁存器[18]、互锁软错误加固锁存器(Interlocking Soft Error Hardened Latch, ISEHL)[19]、三模冗余(Triple Modular Redundancy, TMR)锁存器[20]、高度可靠单粒子翻转加固(Highly Reliable SEU/SET hardened, HRUT)锁存器[21]、三节点翻转容忍锁存器( Triple Node Upset Tolerant Latch,TNUTL)[22]、RHLD、低开销三节点翻转完全容忍(Low Cost and TNU-completely Tolerant, LCTNUT)锁存器和三节点翻转自恢复锁存器(Triple-Node-Upset self-Recoverable Latch, TNURL),包括未加固的锁存器(即传统的静态D锁存器),使用与所提锁存器相同的参数进行了设计。
这些锁存器的节点翻转容忍能力比较结果如表1所示。可以看出,未加固的锁存器不具有SNU,DNU或TNU容忍性。FERST, ISEHL, TMR和HRUT锁存器具有SNU容忍性。但是,它们不能容忍DNU或TNU。DNUR锁存器具有DNU容忍性,但是不能容忍TNU。TNUTL, RHLD, LCTNUT,TNUHL, TNURL锁存器和本文锁存器可以提供完备的TNU容忍性,因此它们属于同一类型。但是,TNUTL锁存器无法长时间存储值,因为它没有任何反馈回路。对于其他同类型锁存器,它们要么具有较大的开销,要么在其存储模块中具有较高的电荷共享发生概率(易发生多节点翻转)。
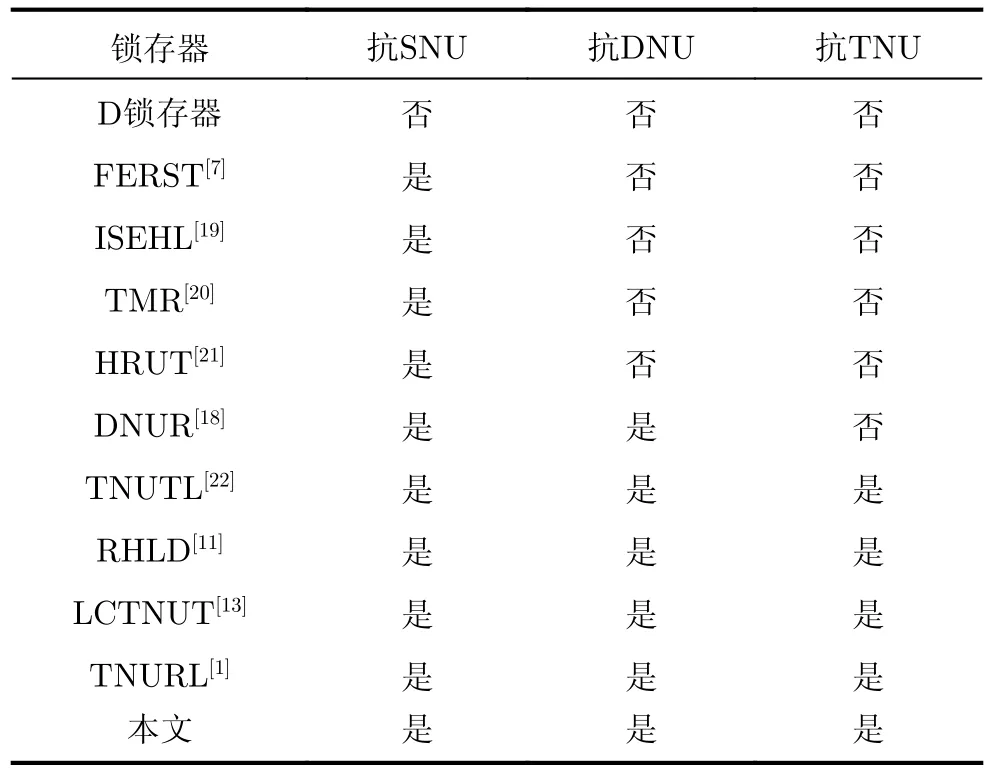
表1 锁存器可靠性对比结果
4.2 开销比较
表2分别显示了锁存器的D至Q传输延迟、平均功耗(动态和静态)、硅面积和DPAP的开销比较结果,其中面积是由文献[13]提出的经典模型计算的。
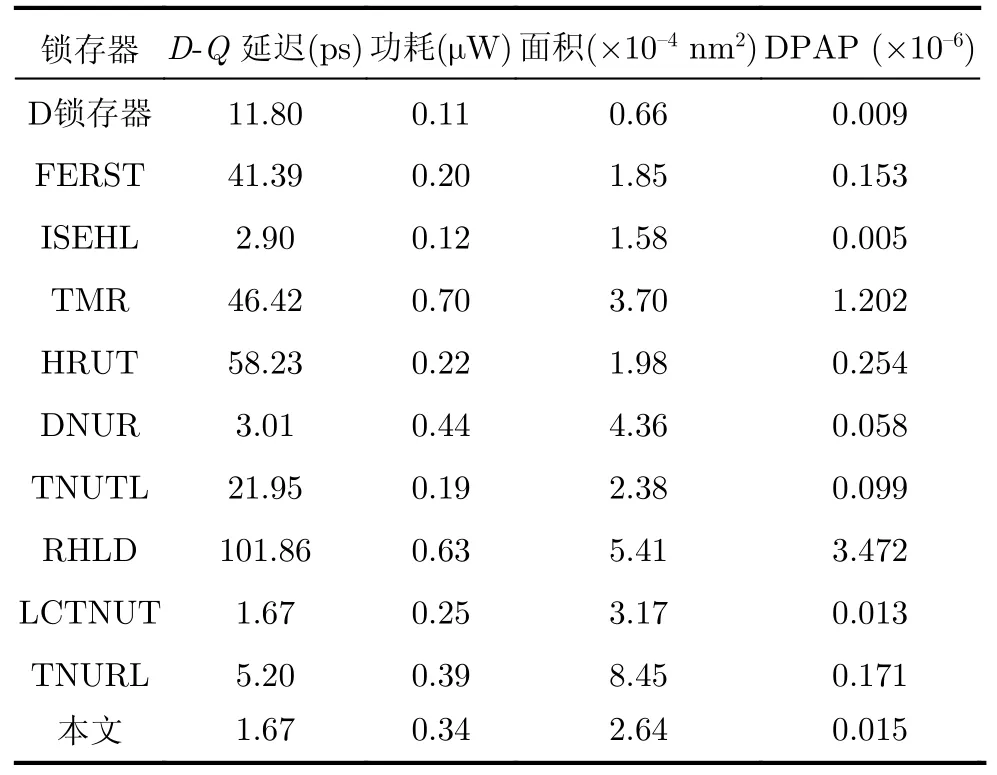
表2 锁存器性能参数对比结果
从表2可以看出,RHLD锁存器的D-Q延迟最大。这主要是由于使用多级错误拦截(MLEI)机制为锁存器提供TNU容错能力所导致的。尽管FERST,TMR, HRUT和TNUTL锁存器(包括未加固的锁存器)未采用MLEI机制,但由于从D到Q存在许多单元器件,或者在Q处存在保持器,它们的延迟仍然很大。ISEHL, DNUR, LCTNUT和TNURL锁存器的延迟(包括本文提出的锁存器)很小,因为它们使用了从D到Q的高速路径。部分锁存器(如TMR,DNUR, RHLD和TNURL)的功耗很大,主要是因为它们的硅面积大或结构中有较多的电流竞争。事实上,与这些锁存器相比,我们提出锁存器的功耗也较低。
从表2还可以看出,TNURL锁存器具有最大的硅面积,因为它采用最多数目的晶体管来保证TNU容忍性。与TNURL锁存器相比,我们提出的锁存器的硅面积更小,因为本文使用更少的C单元来创建DLEI机制,这足以提供TNU容忍性。虽然其他锁存器具有相当的或更小的硅面积,但是其中一些锁存器并不能提供完备的TNU容忍性,这意味着大多数锁存器以不可或缺的硅面积开销为代价来提供高可靠性。
此外,从表2可以看出,RHLD锁存器的DPAP最大,这主要是由于其最大的硅面积和延迟。TMR锁存器的DPAP仍然很大,这主要是由于其较大的延迟、功耗和硅面积。ISEHL锁存器的DPAP最小,这主要是由于其较小的延迟和硅面积。但是,该锁存器仅能容忍SNU。为了进行定量比较,本文计算了提出锁存器与其他TNU容忍锁存器相比的开销改进比率(Ratios of Overhead Improvements,ROI)
延迟ROI= [(本文所提锁存器的延迟–已有锁存器的延迟)/已有锁存器的延迟]×100% (1)式(1)显示了延迟ROI的计算公式,从而可以得到延迟ROI的平均值。同样,可以得到功耗、硅面积和DPAP的ROI计算公式。
如表3所示,可以计算得出,与最先进的TNU容忍锁存器TNURL相比,提出的锁存器分别节省了67.88%的延迟、12.82%的功耗、68.76%的面积和91.23%的DPAP。这表明,与TNURL锁存器相比,提出的锁存器具有更小的开销。与LCTNUT锁存器相比,提出锁存器的面积减少了16.72%。同样,与TNU容忍锁存器RHLD相比,可以计算出所提锁存器节省了98.36%的延迟、46.03%的功耗、51.20%的面积和99.57%的DPAP。此外,与TNU容忍锁存器TNUTL相比,可以计算出所提出的锁存器,使用了额外的78.95%的功耗和10.92%的面积,但是节省了92.39%的延迟和84.85%的DPAP。总体而言,与经典的TNU容忍锁存器相比,所提出的锁存器虽然功耗增加了14.03%,但是平均分别节省了64.65%的延迟、31.44%的面积和65.07%的DPAP开销,这表明了所提出锁存器的低延迟与低面积开销特性。表4显示了抗TNU锁存器的静态功耗和动态功耗。
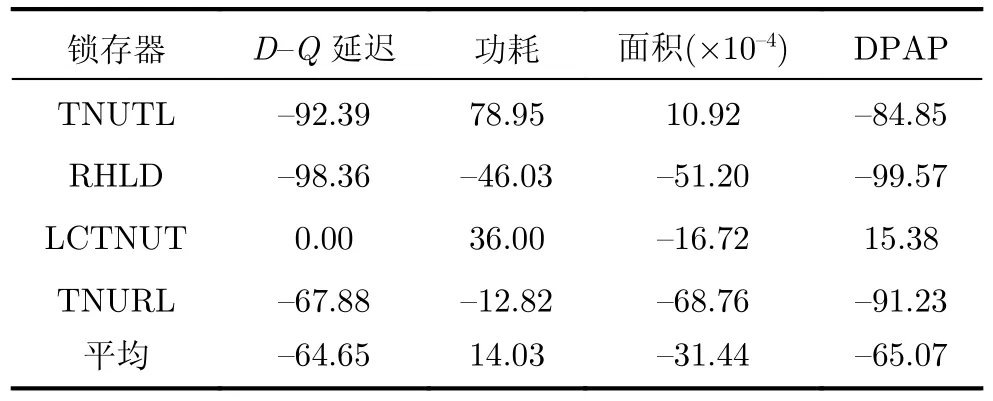
表3 抗TNU锁存器的相对开销比较(%)

表4 抗TNU锁存器的静态功耗和动态功耗(μW)
4.3 PVT分析
随着工艺不断改进,晶体管尺寸迅速缩小,温度/电压/工艺波动对纳米集成电路的可靠性影响日益严重。因此,本文对能容忍3点翻转的加固锁存器(TNURL,TNUTL,RHLD,LCTNUT以及本文所提锁存器)在温度/电压/工艺波动下的延迟与功耗进行了评估。图9显示了锁存器的温度和电源电压变化对延迟与功耗的影响。锁存器的正常电源电压设定为0.8V,电源电压变化范围为0.75~1.25V,正常温度设定为25°C,温度变化范围为–20~120°C。图9(a)和图9(b)分别为温度波动对锁存器延迟与功耗的影响,图9(c)和图9(d)分别为电压波动对锁存器延迟与功耗的影响。
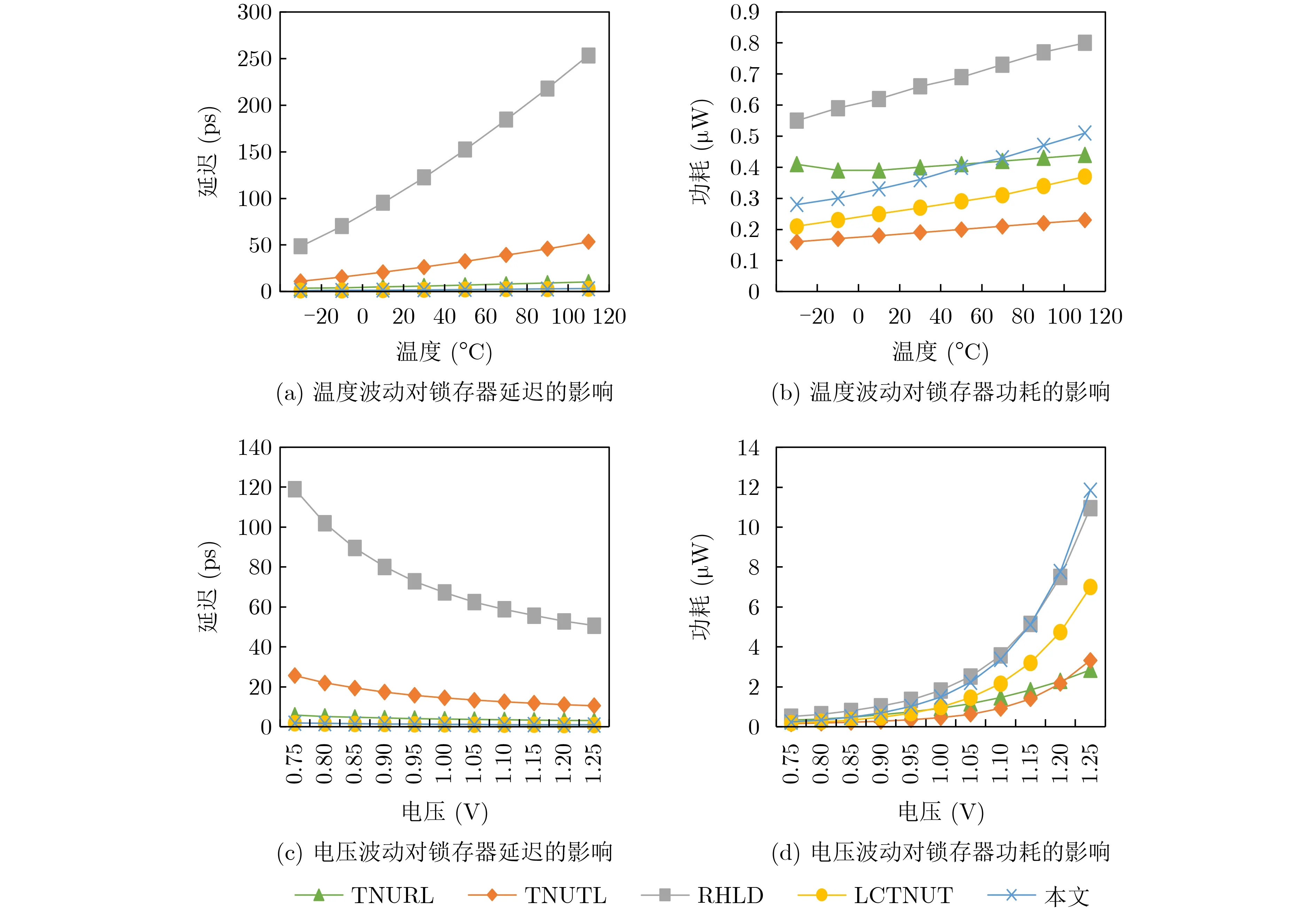
图9 温度和电压变化对锁存器延迟和功耗的影响
由图9(a)和图9(c)可以看出,RHLD锁存器的延迟对温度和电压变化都具有最大的敏感性,因为该锁存器采用多级C单元来拦截TNU。而TNURL,LCTNUT以及本文提出的锁存器的延迟对温度和电压变化的敏感性低,因为它们均采用了从输入D直接到输出Q的高速路径。由图9(b)可知,本文所提锁存器的功耗对温度变化的敏感度较高。由图9(d)可以看出,RHLD和本文锁存器的功耗对电源电压变化的敏感度较高。
图10显示了锁存器的工艺变化对延迟与功耗的影响。工艺变化包括阈值电压波动和工艺尺寸波动等。阈值电压相对变化由1~10表示;工艺尺寸波动范围为22~30 nm。图10(a)和图10(b)分别显示了阈值电压波动对锁存器延迟和功耗的影响。从图10(a)可以看出,本文锁存器的延迟受影响程度较小。由图10(b)可知,本文锁存器的功耗对阈值电压变化的敏感度较高。图10(c)和图10(d)分别显示了工艺尺寸波动对锁存器延迟和功耗的影响。从图10(c)可以看出,本文锁存器的延迟对工艺尺寸波动的敏感性低。由图10(d)可知,本文锁存器的功耗对工艺尺寸波动的敏感度较高。总之,所提锁存器具有适当的PVT敏感度,尤其是延迟对PVT波动的敏感度更低。
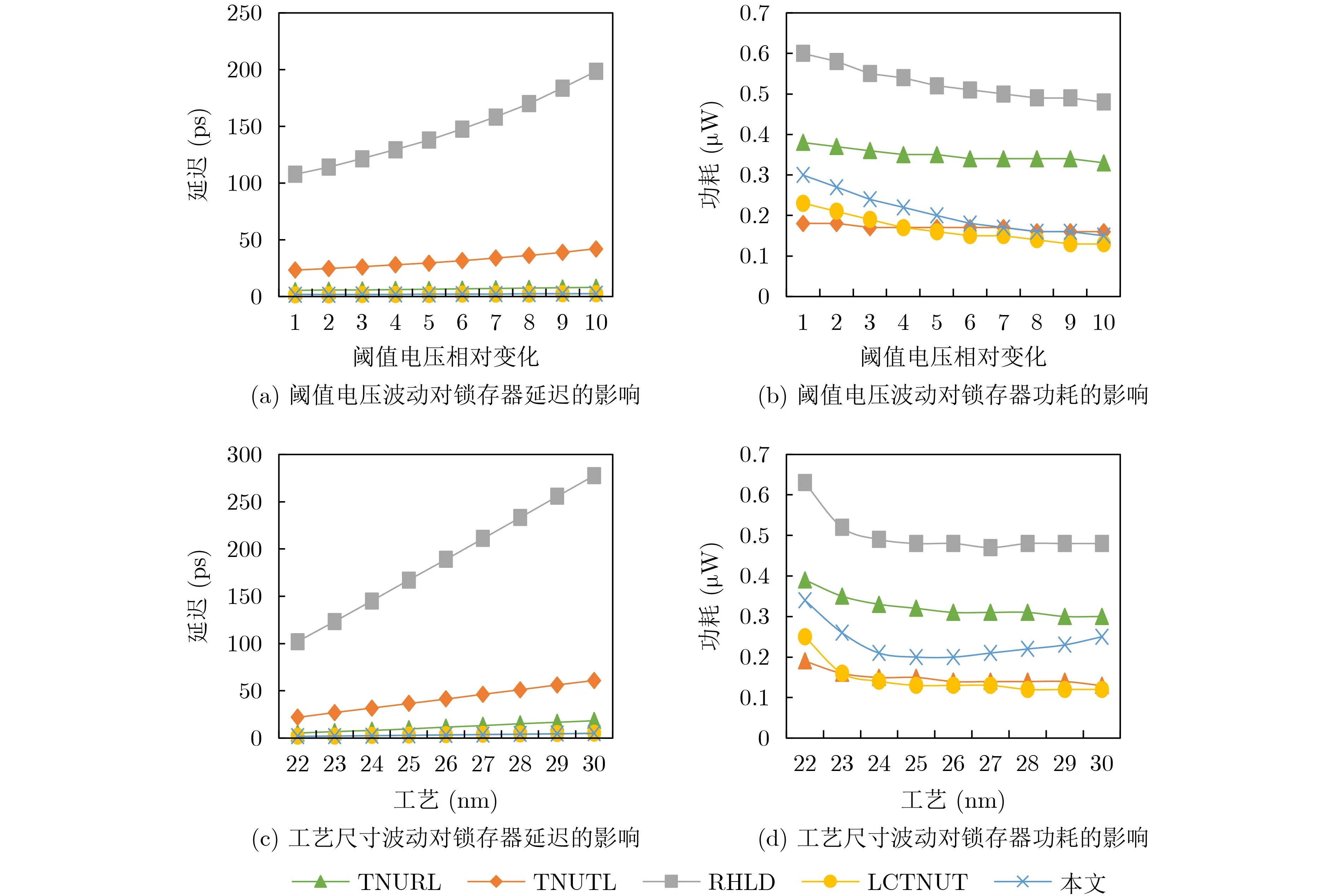
图10 晶体管工艺变化对锁存器延迟和功耗的影响
5 结束语
本文基于RHBD方法,提出一种新颖的基于双DICE和双输入C单元的3节点翻转容忍的锁存器。本锁存器可以容忍任何可能的单节点翻转、双节点翻转及3节点翻转。该锁存器在D-Q延迟、功耗、硅面积和延迟功耗面积积方面的开销较低。仿真结果表明,与先进的锁存器设计相比,所提锁存器在较低的延迟与面积开销的情况下,能容忍3节点翻转,并且具有适当的PVT敏感度。
关于未来工作,会将该锁存器集成到一定规模的电路中,对整体电路的抗辐照能力进行评估,对时序、性能、面积及功耗等方面进行优化,并分析所设计的锁存器对降低电路总体故障概率的贡献。目前,已经尝试将锁存器电路放入ISCAS89电路中,这将是未来持续推进的工作。
